
DDD之模块、工厂和资源库
模块
在DDD中,模型中的模块表示了一个命名的容器,用于存放领域中内聚在一起的类。将类放在不同模块中的目的在于达到松耦合性。我们可以把DDD中的模块理解成一个功能单元的抽象,它的边界范围应该是在聚合之上的。
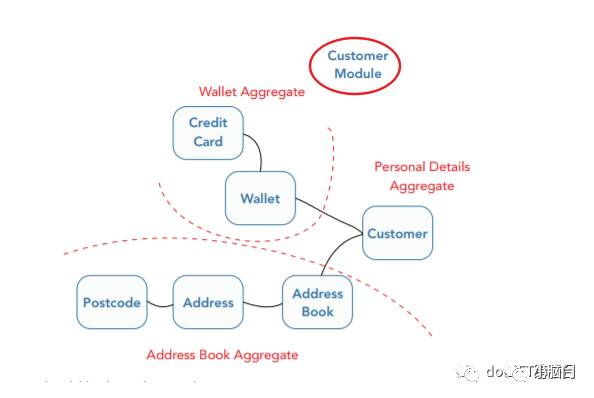
通过电商实例来理解:
对于顾客来说,一般需要维护顾客的个人信息、收货地址、支付方式。这些信息是紧密相关的,不可独立存在。我们可以抽象出三个简单的聚合Customer、AddressBook和 Wallet。那这些类该如何存放呢?是为每一个聚合创建一个文件夹存放还是放在同一个文件夹?我想答案不言而喻。
这三个聚合就是一个模块,一个客户模块。通过定义一个Customer文件夹,来将相关联的领域对象组合起来。而这个文件夹体现在C#中就是命名空间的概念。
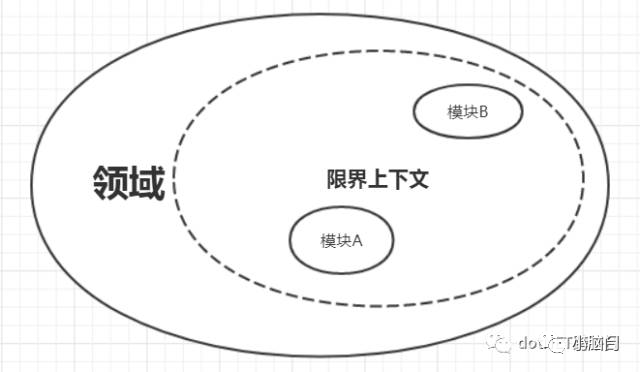
在复杂的领域模型中,为了对领域模型中进行准确建模,需要将领域模型拆分成多个子域,每个子域对应一个或多个限界上下文。在限界上下文中,可以将限界上下文中具体的领域概念分解成不同的模块。所以,从子域到限界上下文再到模块,应该是依次包含关系。
信息来源:https://mp.weixin.qq.com/s/VOnUjxpz1TB1VAjz2EoxxQ
对于模块的设计应具备以下几个要素:
模块内容应具备领域概念,不是简单的按照功能或者领域工具(聚合、工厂、实体、值对象等)进行分类存储,它应该代表这一些列领域工具所抽象出的那个领域概念。
使用通用语言来命名模块,这种命名方式的好处是能够更加凸显领域概念。
模块间要具有高内聚、松耦合性
在针对大型的复杂领域进行建模时,聚合、实体和值对象之间的依赖关系可能会变得十分复杂。在某个对象中为了确保其依赖对象的有效实例被创建,需要深入了解对象实例化逻辑,我们可能需要加载其他相关对象,且可能为了保持其他对象的领域不变性增加了额外的业务逻辑,这样即打破了领域的单一责任原则(SRP),又增加了领域的复杂性。这个时候采用模型工程就能有效的解决聚合的复杂性。说白了使用工厂来创建对象的目的就是为了降低聚合的复杂性,而工厂生产的对象虽然属于模型,但不承担该模型的任何指责。
对象创建不是一个领域的关注点,但它确实存在于应用程序的领域层中。通过使用工厂可以有效的保证领域模型的干净整洁,以确保领域模型的对现实的准确表达。使用工厂具有以下好处:
工厂将领域对象的使用和创建分离。
通过使用工厂类,可以隐藏创建复杂领域对象的业务逻辑。
工厂类可以根据调用者的需要,创建相应的领域对象。
工厂方法可以封装聚合的内部状态。
资源库是对资源访问的抽象。不局限于数据库、文件、网络存储。接口需要不依赖于具体的数据存储和ORM实现框架。其实,就是聚合的访问抽象入口,有点类似日常开发中的facade层,只不过它是针对聚合中实体的操作。每一种聚合类型都将拥有一个资源库,通常来说,聚合类型和资源库是一对一的关系,然而有时,当两个或多个聚合位于同一个对象层级中时,他们可以共享同一个资源库。
资源库分为两种,一种是基于集合的,一种是基于持久化的。顾名思义,基于集合的资源库具有编程语言中集合的特征。举个例子,Java中的List,我们从一个List中取出一个元素,在对该元素进行修改之后,我们并不用显式地将该元素重新保存到List里面。因此,面向集合的资源库并不存在save()方法。比如,对于上文中的User,其资源库可以设计为:
public interface CollectionOrientedUserRepository {public void add(User user);public User userById(String userId);public List allUsers(); public void remove(User user);}
对于面向持久化的资源库来说,在对聚合进行修改之后,我们需要显式地调用sava()方法将其更新到资源库中。依然是User,此时的资源库如下:
public interface PersistenceOrientedUserRepository {public void save(User user);public User userById(String userId);public List<User> allUsers();public void remove(User user);}
在以上两种方式所实现的资源库中,虽然只是将add()方法改成了save()方法,但是在使用的时候却是不一样的。在使用面向集合资源库时,add()方法只是用来将新的聚合加入资源库;而在面向持久化的资源库中,save()方法不仅用于添加新的聚合,还用于显式地更新既有聚合。