
【NLP】创建强大聊天机器人的初学者指南
作者 | Louis Teo
编译 | VK
来源 | Towards Data Science

你是否面临着太多来自客户的标准要求和问题,并且难以应对?你是否在寻找一种既不增加成本又扩大客户服务的方法?
在这篇文章中,我将向你展示如何轻松创建一个强大的聊天机器人来处理1)你不断增长的客户请求和查询,2)使用不同语言进行交流。
我还将向你展示如何使用Flask将聊天机器人部署到web应用程序中。
动机
Covid-19大流行给世界带来了沉重打击。由于许多业务受到了重大控制而遭受了锁定/损失。为了度过这段艰难时期,许多公司被迫将业务转移到网上。
在线企业主面临的一个主要的、常见的问题是必须对客户提出的大量问题和要求作出回应。对于那些人力资源有限的人来说,不可能及时处理所有的请求。
为了解决这个问题,许多企业主开始使用聊天机器人来为他们的客户服务。
什么是聊天机器人
聊天机器人是一种人工智能驱动的智能软件,它能够与人类对话并执行类似人类的任务。聊天机器人存在于许多智能设备(如Siri(iOS)、Google Assistant(Android)、Cortana(微软)、Alexa(亚马逊))、网站和应用程序中。
为什么要用聊天机器人
根据HubSpot进行的一项研究,71%的用户愿意使用快速响应的聊天应用程序来获得客户帮助,许多人这样做是因为他们希望自己的问题能够得到快速解决(当然,也是高效的)。
一个聊天机器人,如果配置智能化,确实可以通过保持相同水平的客户满意度,同时允许人力资源集中在关键操作上,为企业释放巨大的价值。
如何创建聊天机器人
多亏了Python中的ChatterBot库,创建chatbot不再像以前那样是一项艰巨的机器学习任务。
现在,让我们开始创建
(1) 安装ChatterBot库
我们将从安装ChatterBot库开始。安装命令如下:
pip install chatterbot
ChatterBot文本语料库(由大量结构化文本组成的语言资源)分布在Python包中,因此需要单独安装:
pip install chatterbot_corpus
如果你以前没有安装spaCy(一个用于高级自然语言处理的开源库),请现在安装,因为ChatterBot库需要spaCy库来工作:
pip install spacy
安装spaCy库后安装spaCy English(“en”)模型:
python -m spacy download en
(2) 创建聊天机器人实例
在将整个聊天机器人打包成可执行的Python脚本之前,我们将使用Jupyter Notebook开发聊天机器人。让我们从导入需要的模块开始:
from chatterbot import ChatBot
我们将创建一个chatbot实例,将bot命名为Buddy,然后指定几个参数。我们需要指定的参数是:
「storage_adapter」:数据库的“connector”类型(如果使用SQL数据库,则使用'chatterbot.storage.SQLStorageAdapter';对于MongoDB,使用'chatterbot.storage.MongoDatabaseAdapter’). 在这种情况下,我们将使用SQL数据库。 「database_uri」:数据库名称 「logic_adapters」:ChatterBot如何选择对给定输入语句的响应的逻辑。我们将使用BestMatch—一个逻辑适配器,它根据与输入语句最接近的匹配项的已知响应返回响应。 「read_only」:我们将设置为真,因为我们只想让聊天机器人从我们的训练数据中学习。
如果不指定任何参数,则名为「db.sqlite3」的数据库将被创建,并且默认为你选择最佳匹配逻辑。
bot = ChatBot('Buddy',
storage_adapter='chatterbot.storage.SQLStorageAdapter',
database_uri='sqlite:///database.sqlite3_eng',
logic_adapters = ['chatterbot.logic.BestMatch'],
read_only = True)
(3) 训练聊天机器人
是时候训练我们的聊天机器人了……(什么,就这样?是的,这不是开玩笑!)
我们将使用ChatterBot中可用的模块来训练聊天机器人。训练只是将对话输入到聊天机器人的数据库中。
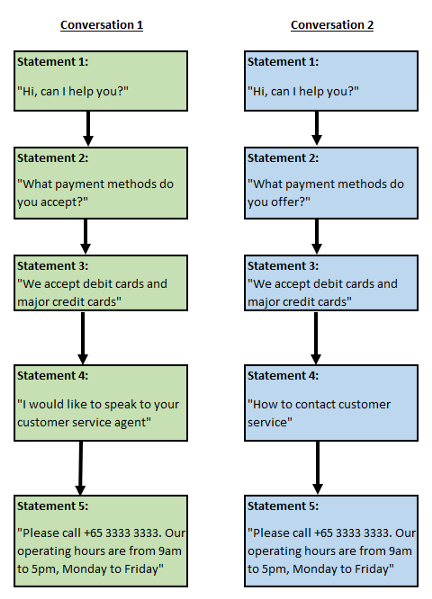
一旦给聊天机器人一个数据集,它就会在聊天机器人“知识图”中生成必要的条目,以正确的顺序表示输入和输出。
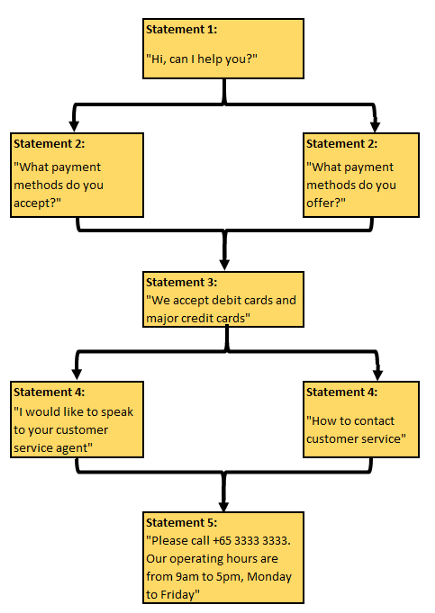
让我们训练我们的聊天机器人能够与我们进行基本的对话。
我们导入ListTrainer模块,通过传递chatbot对象(Buddy)并调用train()方法传递句子列表来实例化它。
from chatterbot.trainers import ListTrainer
trainer = ListTrainer(bot)
trainer.train([
"Hi, can I help you",
"Who are you?",
"I am your virtual assistant. Ask me any questions...",
"Where do you operate?",
"We operate from Singapore",
"What payment methods do you accept?",
"We accept debit cards and major credit cards",
"I would like to speak to your customer service agent",
"please call +65 3333 3333. Our operating hours are from 9am to 5pm, Monday to Friday"
])
聊天机器人测试
让我们用一个input语句给机器人测试一下。
response = bot.get_response ('payment method')
print(response)
我们还可以使用while循环和get_response()方法让聊天机器人连续响应我们的每个查询。当我们收到用户的“Bye”语句时,我们结束循环并停止程序。
name = input('Enter Your Name: ')
print ('Welcome to Chatbot Service! Let me know how can I help you')
while True:
request = input(name+':')
if request=="Bye" or request=='bye':
print('Bot: Bye')
break
else:
response=bot.get_response(request)
print('Bot: ', response)

你刚刚创建了你的第一个聊天机器人!
语料库数据训练
当然,你会希望你的聊天机器人能够在我们刚刚输入的内容的基础上进行更多的对话(!)-在这种情况下,我们需要进一步训练我们的聊天机器人。
幸运的是,我们简化了这项任务。我们可以使用语料库数据和实用程序模块快速训练聊天机器人进行通信。在撰写本文时,ChatterBot独立支持世界上22种主要语言——英语、汉语、西班牙语、印地语、法语等。
这里我们将使用英语语料库数据来训练聊天机器人用英语进行交流。
注意:如果你在运行语料库训练时遇到问题,请将此chatterbot_corpus文件夹(https://github.com/gunthercox/chatterbot-corpus/tree/master/chatterbot_corpus)复制到错误消息中指定的文件目录中
from chatterbot.trainers import ChatterBotCorpusTrainer
trainer = ChatterBotCorpusTrainer(bot)
trainer.train('chatterbot.corpus.english')
让我们测试一下我们的聊天机器人是否变得更聪明了…。
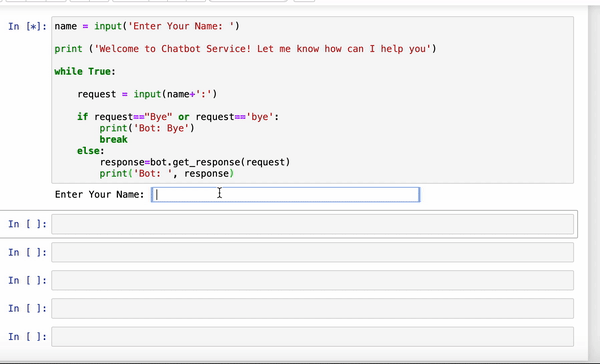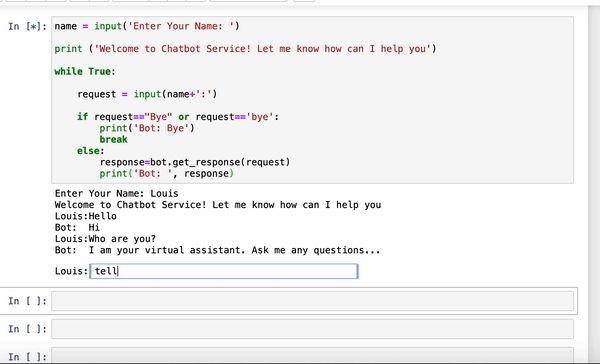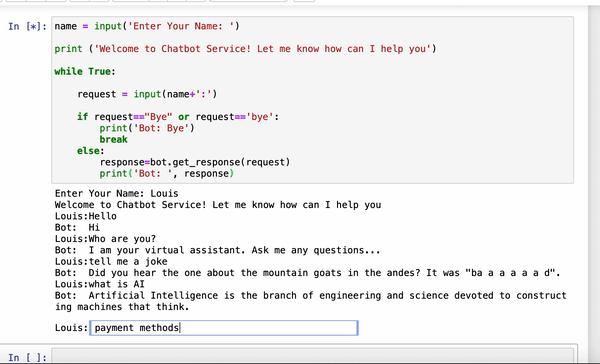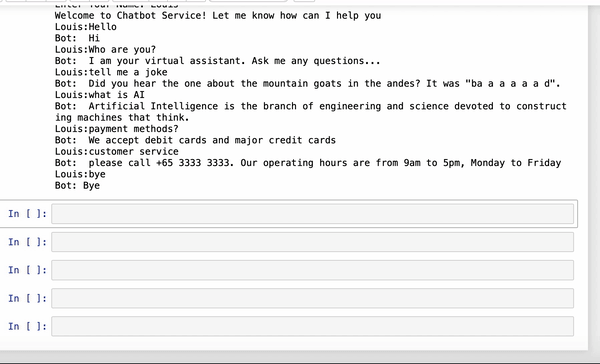
对!它变得更聪明了-它现在可以告诉你一个笑话…
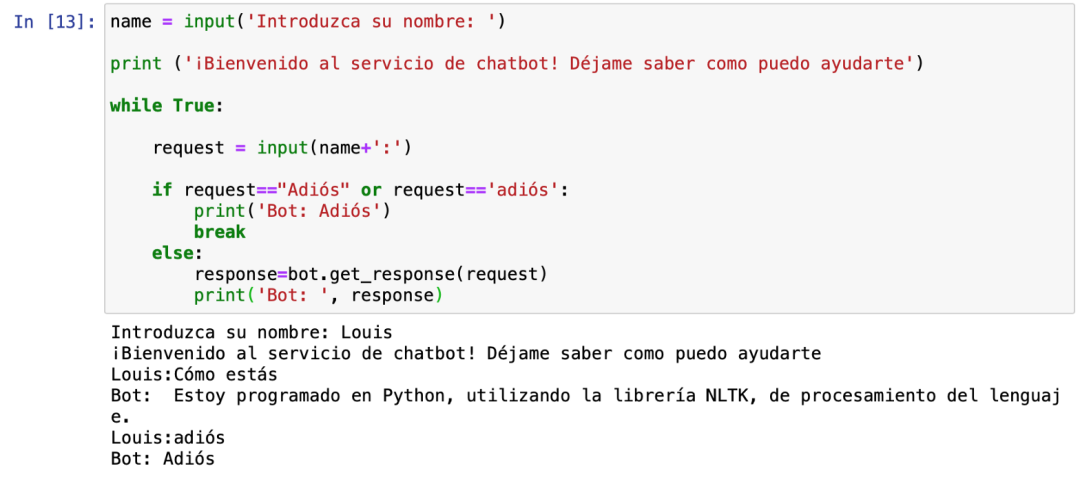
关于训练聊天机器人使用不同语言的重要说明
要训练聊天机器人使用另一种语言,你需要用新名称创建一个新的聊天机器人实例,打开一个新的SQL数据库,并进行新的训练
你不能训练同一个聊天机器人说多种语言-这会混淆聊天机器人。聊天机器人只能用一种语言交流。
预处理输入
ChatterBot提供了几个内置的预处理器,允许我们在bot的逻辑适配器处理语句之前清理输入语句。
清理使我们的输入语句更易读,更容易被聊天机器人分析。它从输入语句中删除可能干扰文本分析的“噪音”,例如额外的空格、Unicode字符和转义的html字符。
bot = ChatBot('Buddy',
storage_adapter='chatterbot.storage.SQLStorageAdapter',
database_uri='sqlite:///database.sqlite3_eng',
logic_adapters = ['chatterbot.logic.BestMatch'],
read_only = True,
preprocessors=['chatterbot.preprocessors.clean_whitespace', 'chatterbot.preprocessors.unescape_html', 'chatterbot.preprocessors.convert_to_ascii'])
在包含了预处理器函数之后,重新运行chatbot,你可以看到对于「who are you」和「whó are yóu」.,我们得到了相同的响应。
低置信度的情况
除此之外,我们还可以通过将logic adapter的属性设置为:
默认回答:“对不起,我不明白。我还在学习。请联系abc@xxx.com寻求进一步的帮助
最大相似度阈值:0.9
maximum_similarity_threshold:停止搜索过程之前,两个语句之间所需的最大相似度。匹配语句的搜索将继续,直到找到相似度大于或等于的语句或搜索集用尽为止。默认为0.95。
bot = ChatBot('Buddy',
storage_adapter='chatterbot.storage.SQLStorageAdapter',
database_uri='sqlite:///database.sqlite3_eng',
logic_adapters = [
{
'import_path': 'chatterbot.logic.BestMatch',
'default_response': 'I am sorry, I do not understand. I am still learning. Please contact abc@xxx.com for further assistance.',
'maximum_similarity_threshold': 0.90
}
],
read_only = True,
preprocessors=['chatterbot.preprocessors.clean_whitespace',
'chatterbot.preprocessors.unescape_html',
'chatterbot.preprocessors.convert_to_ascii'])
让我们尝试从一个意外的输入中获取响应-我们的聊天机器人将在不理解语句时使用「default_response」进行响应。
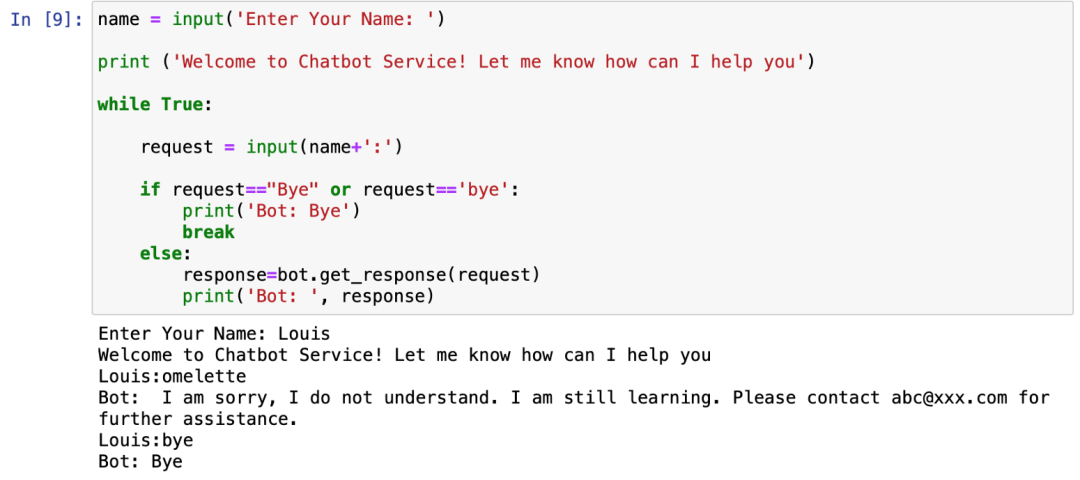
这是这个项目的Github链接。你可以下载可执行的Python脚本,你可以马上用它来训练你的聊天机器人!请下载训练数据文件夹并编辑对话文件以满足你的需要:https://github.com/louisteo9/Chatbot
完整的代码和运行说明
在把所有代码放在一起之后,让我们使用可执行脚本来训练我们的聊天机器人,看看我们的聊天机器人在行动中…!
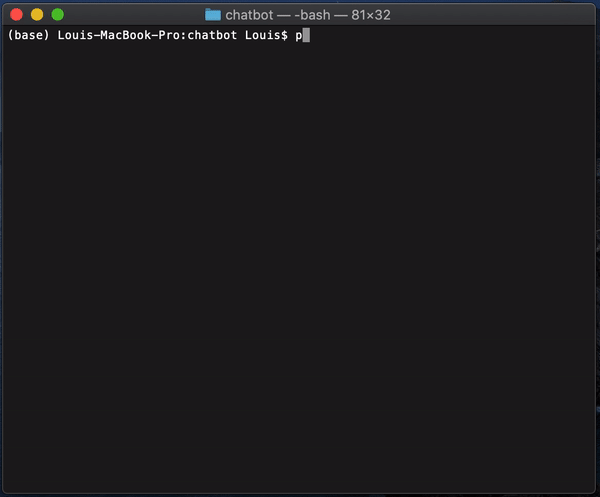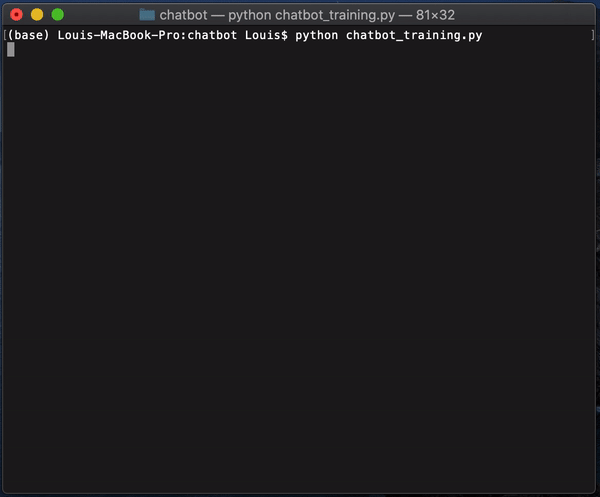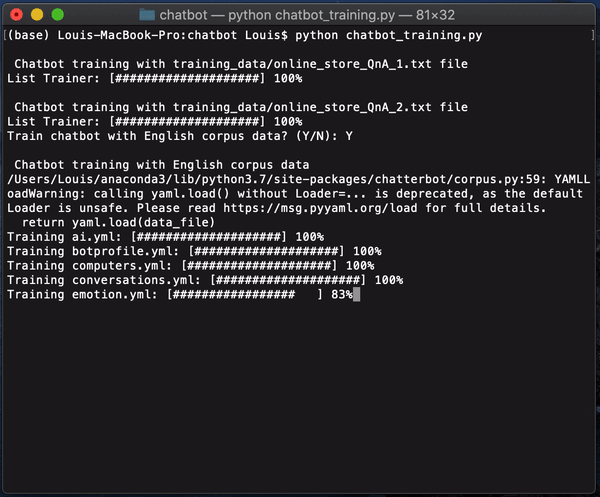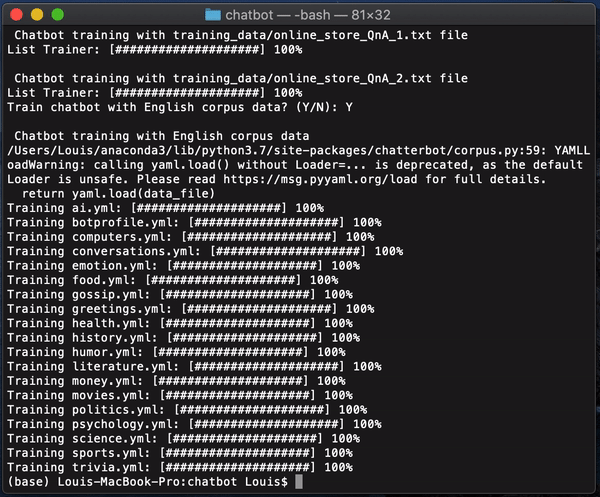
创建一个「training_data」文件夹,并将要训练的所有对话存储在文本文件中。训练脚本将读取文件夹中的所有文本文件。
运行「chatbot_training.py」. 如果你想用英语语料库来训练聊天机器人,你会被要求选择Y或N。
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
from chatterbot.trainers import ChatterBotCorpusTrainer
import os
# 创建聊天机器人实例
bot = ChatBot('Buddy',
storage_adapter='chatterbot.storage.SQLStorageAdapter',
database_uri='sqlite:///database.sqlite3_eng',
logic_adapters=[
'chatterbot.logic.MathematicalEvaluation',
'chatterbot.logic.BestMatch',
{
'import_path': 'chatterbot.logic.BestMatch',
'default_response': 'I am sorry, but I do not understand.',
'maximum_similarity_threshold': 0.90
}],
read_only = True,
preprocessors=['chatterbot.preprocessors.clean_whitespace',
'chatterbot.preprocessors.unescape_html',
'chatterbot.preprocessors.convert_to_ascii']
)
# 定位训练文件夹
directory = 'training_data'
for filename in os.listdir(directory):
if filename.endswith(".txt"): # only pick txt file for training
print('\n Chatbot training with '+os.path.join(directory, filename)+' file')
training_data = open(os.path.join(directory, filename)).read().splitlines()
trainer = ListTrainer(bot) # bot training
trainer.train(training_data)
else:
continue
# 用户选择是否使用英语语料库数据进行训练
decision = input('Train chatbot with English corpus data? (Y/N): ')
if decision == 'Y':
print('\n Chatbot training with English corpus data')
trainer_corpus = ChatterBotCorpusTrainer(bot)
trainer_corpus.train('chatterbot.corpus.english')
然后,运行「chatbot.py」启动聊天机器人。
from chatterbot import ChatBot
bot = ChatBot('Buddy',
storage_adapter='chatterbot.storage.SQLStorageAdapter',
database_uri='sqlite:///database.sqlite3_eng',
logic_adapters=[
'chatterbot.logic.MathematicalEvaluation',
'chatterbot.logic.BestMatch',
{
'import_path': 'chatterbot.logic.BestMatch',
'default_response': 'I am sorry, but I do not understand.',
'maximum_similarity_threshold': 0.90
}],
read_only = True,
preprocessors=['chatterbot.preprocessors.clean_whitespace',
'chatterbot.preprocessors.unescape_html',
'chatterbot.preprocessors.convert_to_ascii']
)
# 运行并获得用户的响应。
name = input('Enter Your Name: ')
print ('Welcome to Chatbot Service! Let me know how can I help you')
while True:
request = input(name+': ')
if request=="Bye" or request=='bye':
print('Bot: Bye')
break
else:
response=bot.get_response(request)
print('Bot: ', response)
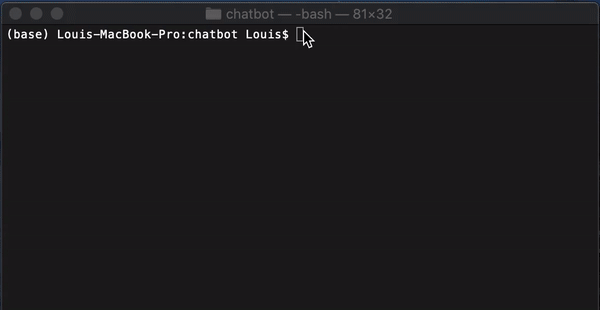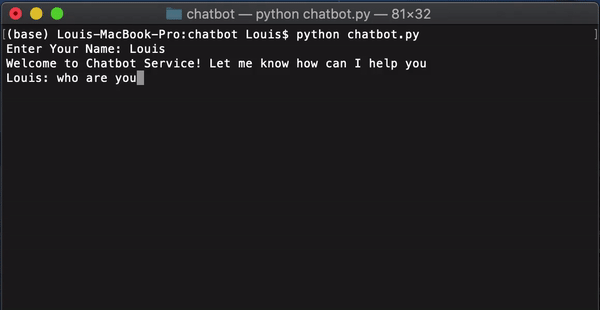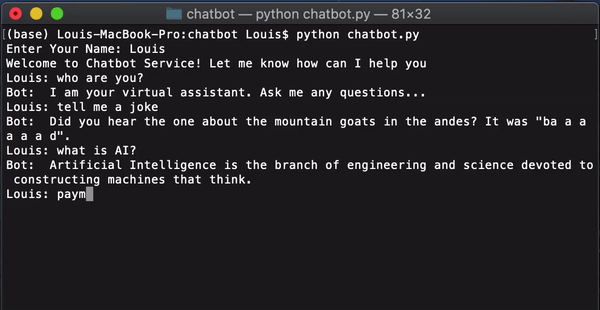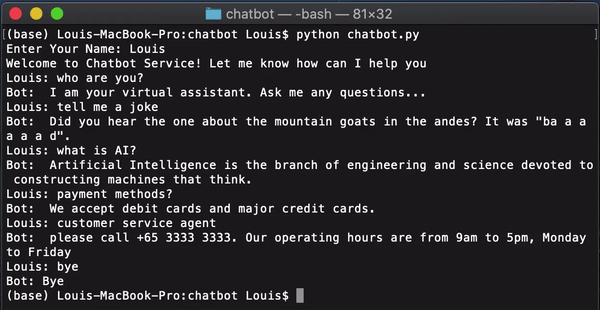
你已经完成了聊天机器人训练并在终端上运行。
使用Flask将聊天机器人部署为web应用程序
下一步是什么?我们将把我们的聊天机器人部署到一个web应用程序中,这样客户就可以使用它了。
要在web应用程序上运行chatbot,我们需要找到一种方法让应用程序接收传入的数据并返回数据。我们可以用我们想要的任何方式来实现这一点—HTTP请求、web套接字等
在ChatterBot FAQ(https://chatterbot.readthedocs.io/en/stable/faq.html)页面上有一些现有的例子向我们展示了如何做到这一点。我将向你展示如何使用Flask部署web应用程序。
从我的github下载示例代码,然后根据需要编辑static和template文件夹中的文件:https://github.com/louisteo9/chatbot
之后,让我们运行「web_app.py」.
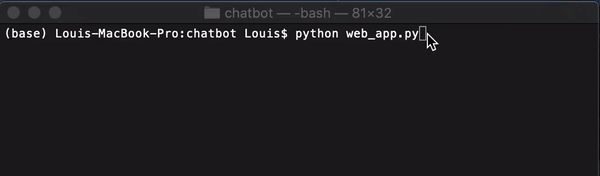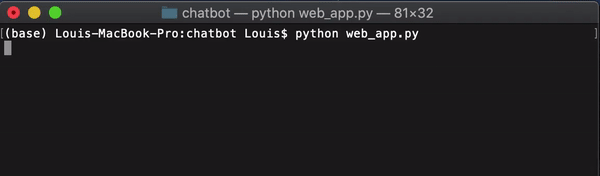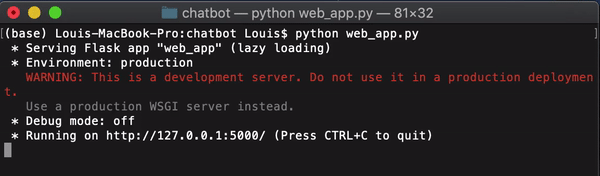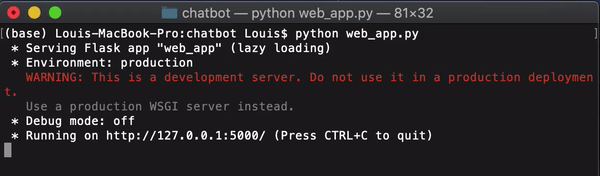
这将把我们的聊天机器人部署到http://127.0.0.1:5000/
启动你的web浏览器,然后转到上面的URL启动我们的聊天机器人。

下一步
再次祝贺你!你已经成功地构建了第一个聊天机器人,并使用Flask将其部署到一个web应用程序中。我希望聊天机器人在回答一些你训练过的标准商务问题方面做得很好。
为了进一步提高聊天机器人的性能,你可以做的一件事是编制一份迄今为止由客户发布的常见问题解答列表,提供常见问题解答,然后在聊天机器人上对他们进行训练。
为什么有些聊天机器人没有达到预期?有些聊天机器人之所以失败,仅仅是因为对企业提出的标准问题和要求没有得到充分的分析,结果聊天机器人没有得到所需的训练。
训练和改进你的聊天机器人在一开始是一个持续的过程,类似于人类学习新技能和知识的方式。一旦学习到这些技能,它们就被构建在聊天机器人中,聊天机器人不需要再接受训练,除非你的业务发展壮大。
接下来,你可以考虑将你的聊天机器人部署到PaaS,它可以完全从云端托管和运行web应用程序。你可以考虑的一个流行的免费PaaS是Heroku。
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: