
基于Transformer对透明物体进行分割
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


摘要
本研究提出了一个新的细粒度透明对象分割数据集,称为Trans10Kv2,扩展了Trans10K-v1,第一个大规模透明对象分割数据集。不像Trans10K-v1只有两个有限的类别,作者的新数据集有几个吸引人的好处。(1)它有11个细粒度的透明对象类别,通常发生在人类的家庭环境中,使它更适合于现实世界的应用。(2) Trans10K-v2对现有的高级分割方法带来了比以前版本更多的挑战。此外,提出了一种新的基于变压器的分割管道Trans2Seg。首先,Trans2Seg的变压器编码器相对于CNN的局部接受场提供了全局接受场,这显示了相对于纯CNN架构的优异优势。其次,作者将语义分割制定为一个字典查找问题,设计了一组可学习的原型作为Trans2Seg s变压器解码器的查询,每个原型学习整个数据集中一个类别的统计信息。作者对20多种最新的语义分割方法进行了评测,结果表明Trans2Seg算法的性能明显优于所有基于cnn的方法,表明了本文提出的算法在解决透明对象分割问题上的潜在能力。
开源代码:https://github.com/xieenze/Trans2Seg
本文贡献
作者提出了最大的玻璃分割数据集(Trans10K-v2),包含11种不同场景和高分辨率的细粒度玻璃图像类别。所有的图片都用精细的遮罩和面向功能的分类精心标注。
提出了一种基于变压器的透明物体分割网络,该网络采用变压器编解码结构。该方法提供了一个全局的接受域,在掩模预测中具有更强的动态性,具有很好的优越性。
作者在Trans10K-v2上评估了20多种语义分割方法,作者的Trans2Seg显著优于这些方法。此外,作者还表明,这一任务在很大程度上尚未解决。因此需要更多的研究。
框架结构
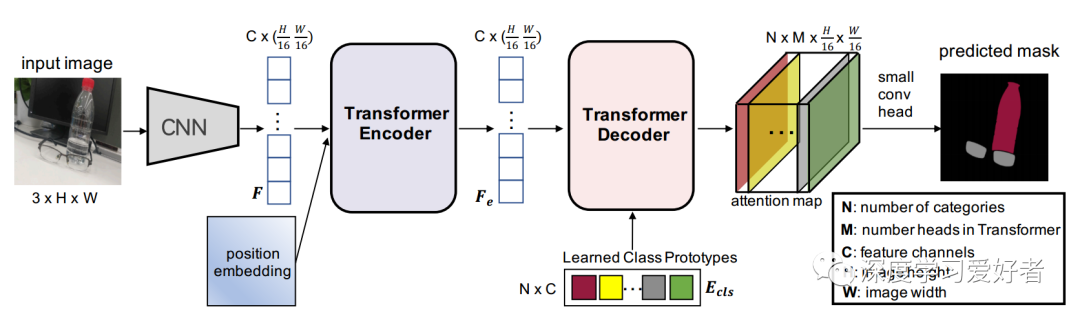
作者的CNN-Transformer混合架构。首先,将输入图像输入到CNN,提取特征F。其次,对于变压器编码器,将特征和位置嵌入平滑后馈给Transformer进行自我注意,并从变压器编码器输出特征(Fe)。第三,针对Transforme解码器,作者专门定义了一组可学习类原型嵌入(Ecls)作为查询,Fe作为键,并利用Ecls和Fe计算注意图。每个类的原型嵌入对应一个最终预测的类别。作者还添加了一个小的conv头来融合来自CNN骨干的注意力地图和Res2特征。变压器解码器和小锥头详见图4。最后,通过对注意图进行像素级argmax,得到预测结果。例如,在这个图中,两个类别(瓶子和眼镜)的分割掩模对应着两个相同颜色的类原型。
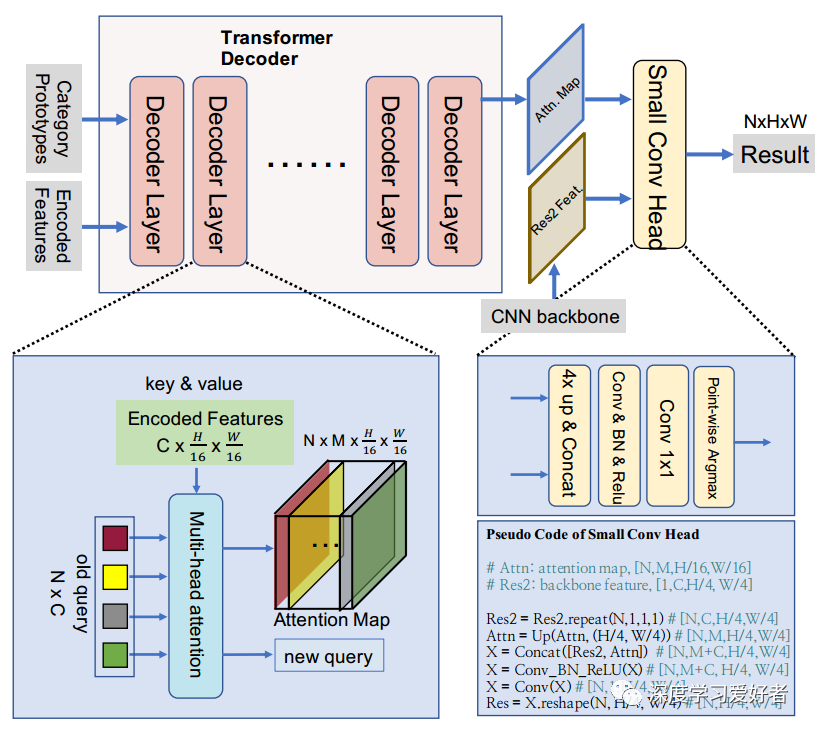
Transformer解码器详细图。输入:可学习的类别原型作为查询,从Transformer编码器的特性作为键和值。输入被馈送到变压器解码器,它由几个解码器层组成。最后一个解码器层的注意图和CNN骨干网的Res2特征相结合,并馈给一个小的conv头,得到最终的预测结果。为了更好的理解,作者还提供了小锥头的伪代码。输入:可学习的类别原型作为查询,从变压器编码器的特性作为键和值。输入被馈送到Transformer解码器,它由几个解码器层组成。最后一个解码器层的注意图和CNN骨干网的Res2特征相结合,并馈给一个小的conv头,得到最终的预测结果。
实验结果
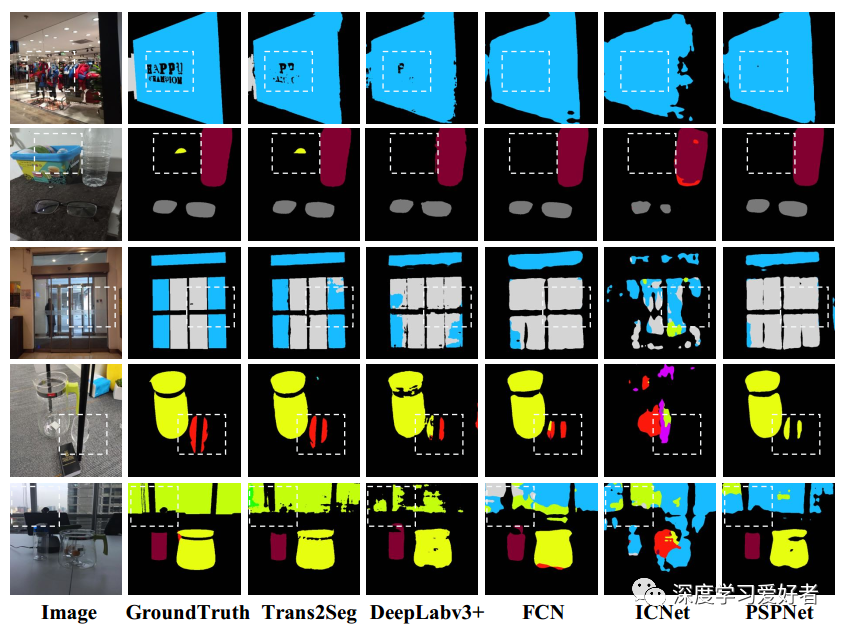
Trans2Seg与其他基于CNN的语义分割方法的视觉比较。输入:可学习的类别原型作为查询,从变压器编码器的特性作为键和值。输入被馈送到Transformer解码器,它由几个解码器层组成。最后一个解码器层的注意图和CNN骨干网的Res2特征相结合,并馈给一个小的conv头,得到最终的预测结果。为了更好的理解,作者还提供了小锥头的伪代码。Trans2Seg的整体感受场和注意机制,特别是在dash区域,明显优于其他组。放大以获得最佳视野。更多可视化结果请参考补充材料。
结论
在本文中,作者提出了一个新的细粒度透明对象分割数据集,包含11个常见类别,称为Trans10K-v2,其中数据是基于之前的Trans10K。输入:可学习的类别原型作为查询,从Transformer编码器的特性作为键和值。输入被馈送到Transformer解码器,它由几个解码器层组成。最后一个解码器层的注意图和CNN骨干网的Res2特征相结合,并馈给一个小的conv头,得到最终的预测结果。为了更好的理解,作者还提供了小锥头的伪代码。作者也讨论了提出的数据集的挑战性和实用性。此外,作者提出了一种基于变压器的管道,称为Trans2Seg,以解决这一具有挑战性的任务。在Trans2Seg中,Transformer编码器提供了全局接收域,这是透明对象分割的必要条件。在transformer解码器中,作者将分割建模为使用一组可学习查询的字典查找,其中每个查询代表一个类别。最后,作者评估了超过20种主流的语义分割方法,并表明作者的Trans2Seg明显优于这些基于CNN的分割方法。
在未来,作者有兴趣探索作者的Transformer编码器-解码器设计的一般分割任务,如城市景观和PASCAL VOC。作者也会投入更多的精力来解决透明对象的分割任务。
论文链接:https://arxiv.org/pdf/2101.08461.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目31讲
在「小白学视觉」公众号后台回复:Python视觉实战项目31讲,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
下载4:leetcode算法开源书
在「小白学视觉」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~