
AI艺术‘美丑’不可控?试试 AI 美学评分器~
社区推荐过非常多的 AI艺术创作工具,但用这些工具有一个很大的麻烦,创作者无法有效把控生成作品的质量,AI本身似乎也不清楚人类关于 “美丑” 的标准。
#
对......我用Disco Diffusion、Midjourney等等工具时经常生成一些很 “惊悚” 与 “过于抽象” 的图片......
看来 AI创作工具需要美学评估模型的过滤器
#
社区有成员推荐一个美学评估模型与数据集,大家可以去了解下~

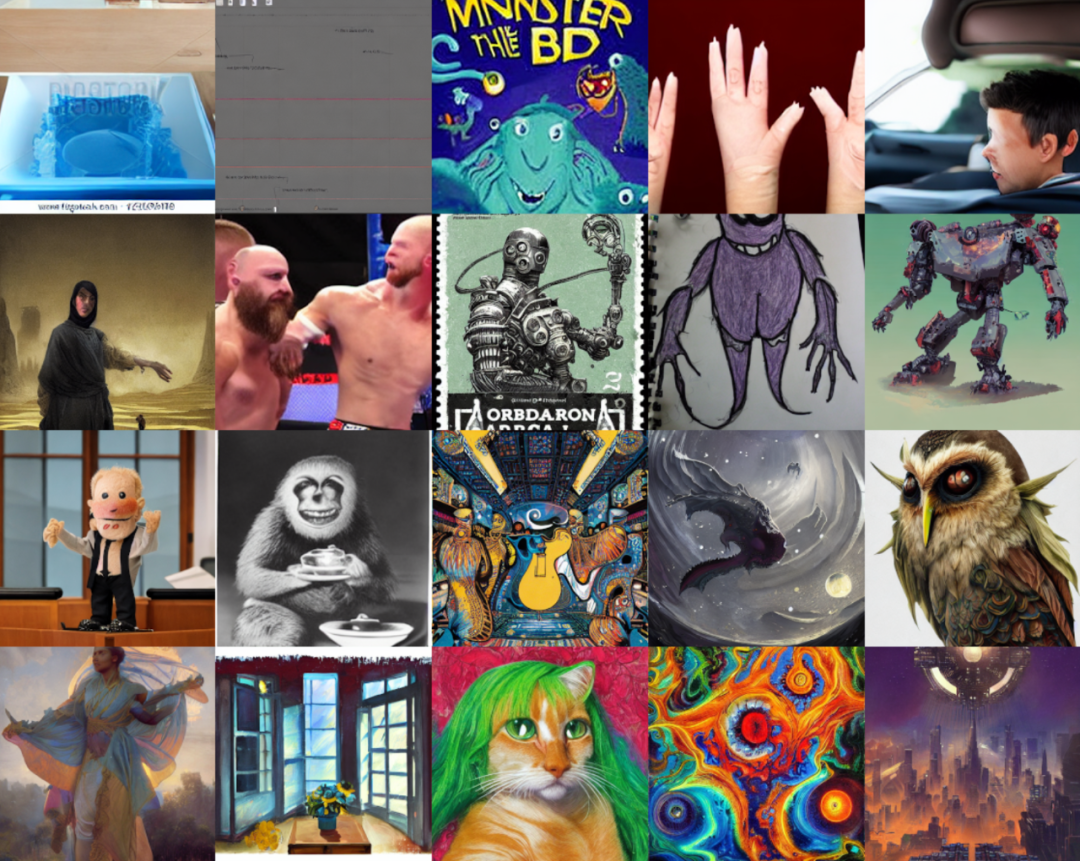 模型排序网格
模型排序网格

小杜
需要强调的是,训练该模型所用的数据集是对AI生成艺术图像的美学评估,所以模型无法进行通用图片的美学评估。
就上述的对比:人类 VS AI 的美学评估结果来看,只有最“丑”的两张图片有评估偏差,此模型还是有很实用的应用价值的。
Mixlab
我对训练此模型所用的数据集更感兴趣。既然所用数据集能训练美学评估排序模型,那也可以用来指导AI生成更“美”的作品咯~
小杜
对的,数据集可以训练不同功能的模型。Simulacra Aesthetic Captions 数据集是一个包含 238000 多张图像的数据集,这些图像由 CompVis latent GLIDE 和 Stable Diffusion 等 AI 模型从超过 4 万个用户提交的提示中生成。
用户根据图像的审美价值从 1 到 10 进行评级,以创建标题、图像和评级三元组数据集。

此数据集拥有超过 176000 个评级的高质量免版税数据,可用于以下模型训练:
过滤数据集 Filtering Datasets
指导生成模型 Guiding Generative Models
训练提示生成器 Training A Prompt Generator
提取关键短语(“artstation 趋势”等)
Extracting vitamin phrases ("trending on artstation", etc)
对齐研究 Alignment Research
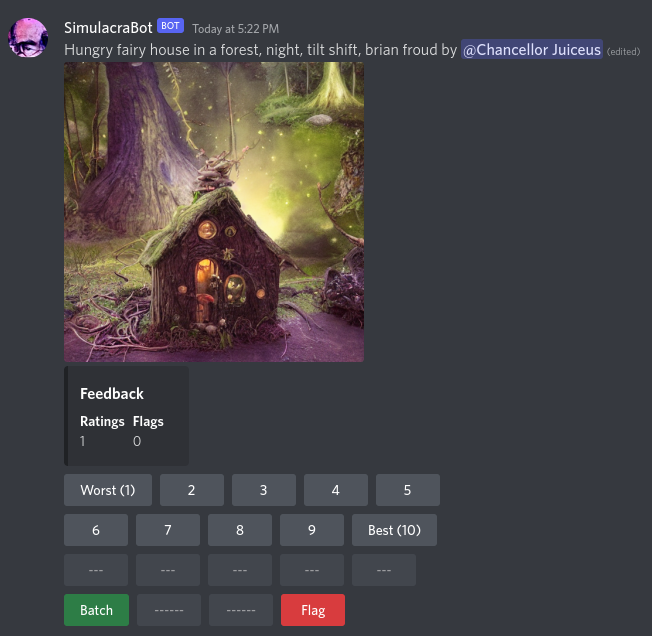 使用 Discord 机器人收集的用户对AI生成图片的评分数据
使用 Discord 机器人收集的用户对AI生成图片的评分数据
小杜
研究团队收集用户对自己运用AI创作生成的画作进行评分来制作数据集,很难避免进行评分的用户群体特征与认知偏见造成的 “主观偏差”,无法保证数据集的 “绝对客观性”。
在制作数据集时团队认为,既然无法通过事先提示避免偏见的方式强制要求用户做出违反直觉(违反主观偏见)的打分,那便一开始通过20个问题来记录下用户潜在的偏见。通过这二十个统一的打分来获悉用户对具体图像打分时可能存在的偏见。

统一评分所用的20个图片集
Simulacra Aesthetic Captions 的初始设计要求将所有评分收集到一个匿名池中。然而,在数据收集过程中,一些用户会客观地贬低画得好的图片,因为它们 “吓人”,或者有他们不喜欢的公众人物。一些用户还会忽略评级说明,忽略了水印和其他不易察觉的不明噪点影响画面质量评级。
于是团队决定尊重人的直觉,并进行了一项审美调查,记录用户在审美判断中影响客观判断的因素。该调查目前包括 20 个问题,以 1-10 级固定手选图像的评分形式组成,每个问题代表人类审美判断的推测成分或数据集用户希望在分析过程中能够处理的偏见。
该调查数据提高了使用 Simulacra Aesthetic Captions 对人类审美偏好进行一般研究的可能性。
小杜
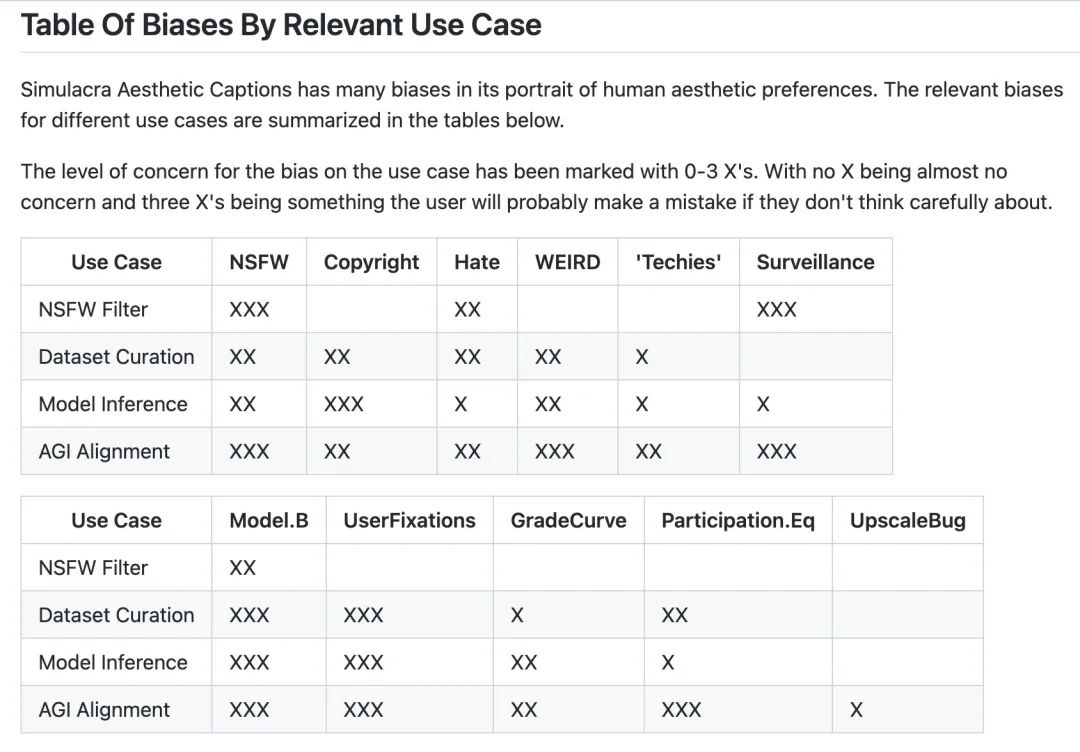
团队整合了在描绘人类审美偏好方面存在的偏见。下表总结了不同用例的相关偏差。对用例偏差的关注程度已用 0-3 X 标记。没有 X 几乎没有偏见问题,三个 X 是用户如果不仔细考虑可能会犯偏见评估错误。
Mixlab
总结下该数据集的制作过程与使用特点、局限-
1. 使用通过该数据集训练的模型来评估数据集里面没有的数据,直接不评分,没有数据点,连0都没有。
2.用户评分制数据集无法避免偏见的产生,也无法避免因群体特征的喜好局限影响数据集的通用性。
3.该数据集来源于AI创作爱好者,采用该数据集训练的模型最合适的应用场景也应是在AI创作者群体中用于评估、删选、指导、提取关键词等
github.com/crowsonkb/simulacra-aesthetic-models
github.com/JD-P/simulacra-aesthetic-captions#list-of-biases-with-explanations
这个好棒 可以准备 pytorch 炼丹了
#
偏见,数据集本身不够客观,评分制的数据集也无法避免主观因素,可能制作数据集就已经按照制作者自己的审美和判断来制作了
审美与偏见我觉得分不开啊,审美本来就是主观评价,数据集够大也能八九不离十地进行美学评估吧。
#
我还是相信 美学评估数据集能较高程度反映 “大众审美” ,我就想我的作品尽量贴近大众审美,这样才有利作品传播,增强影响力。
我倒是想用这个数据集训练能帮我提取生成关键词的模型,灵感枯竭时让AI帮我想想好点子。
......
小杜
最近我接到一个兴趣诗社社团的诗刊封面设计的任务,主旨是 “四时之声”——所有事物都在一个轮回之中,即便在一个轮回之中我们依然会有惊喜和幸福,依然会有值得记录的东西。
我给ai的任务是画 “一支钢笔上长出了大树 树上结满了春夏秋冬四季的果实。” 寓意落笔生花,妙语结果,四时流转之景皆由文笔描绘生成。
最后我用 Disco Diffusion 设计了5张封面,在了解这个模型之前我个人先进行了“美学评估”,并选定一张进行封面设计。对AI美学评估感兴趣的朋友正好用这个模型帮我估估分,哈哈。


我喜欢这张线条的质感,画面布局排布与虚实关系也很有味道。
#排名3

我喜欢这张的色调,但主视觉的形态与整体画面布局相较于前两张来说有点平庸。
#排名4

这张感觉有点平庸,布局与画面元素没有抓人的亮点
#排名5

这张属于 “丑” 的范围了,整体画面显得很凌乱,色调也很杂乱。
小杜
最后我根据个人的审美偏好制作了诗刊封面,运用 AI 进行评估的结果是怎样的呢?这个悬念留给大家探索啦~

社区工作招募链接