关注涛涛CV,设置星标,更新不错过
用AI写作是NLP文本生成的经典应用实例,本文采用https://github.com/EssayKillerBrain/EssayKiller_V2的算法进行写作,大家有兴趣可以自己去试试。线上点击即可使用demo,高考作文生成AIhttps://colab.research.google.com/github/EssayKillerBrain/EssayKiller_V2/blob/master/colab_online.ipynb这里选择了【2022年全国乙卷】和【2022年新高考全国I卷】作文题进行实验。双奥之城,闪耀世界。两次奥运会,都显示了中国体育发展的新高度,展示了中国综合国力的跨越式发展,也见证了你从懵懂儿童向有为青年的跨越。亲历其中,你能感受到体育的荣耀和国家的强盛;未来前行,你将融入民族复兴的澎湃春潮。卓越永无止境,跨越永不停歇。请结合以上材料,以“跨越,再跨越”为主题写一篇文章,体现你的感受与思考。
现在AI对主题的提炼还有待改善,所以我们需要自己概括文章主题送入文章生成器。“本手、妙手、俗手”是围棋的三个术语。本手是指合乎棋理的正规下法;妙手是指出人意料的精妙下法;俗手是指貌似合理,而从全局看通常会受损的下法。对于初学者而言,应该从本手开始,本手的功夫扎实了,棋力才会提高。一些初学者热衷于追求妙手,而忽视更为常用的本手。本手是基础,妙手是创造。一般来说,对本手理解深刻,才可能出现妙手;否则,难免下出俗手,水平也不易提升。以上材料对我们颇具启示意义。请结合材料写一篇文章,体现你的感悟与思考。
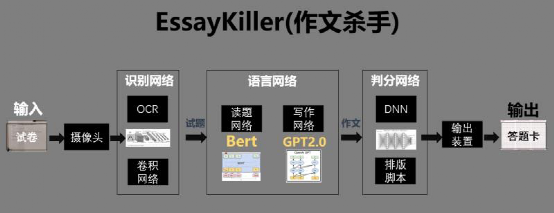
EssayKiller是基于OCR、NLP领域的最新模型所构建的生成式文本创作AI框架,目前第一版finetune模型针对高考作文(主要是议论文),可以有效生成符合人类认知的文章,多数文章经过测试可以达到正常高中生及格作文水平。 基于EAST、CRNN、Bert和GPT-2语言模型的高考作文生成AI 支持bert tokenizer,当前版本基于clue chinese vocab 17亿参数多模块异构深度神经网络,超2亿条预训练数据 线上点击即用的文本生成效果demo:17亿参数作文杀手 端到端生成,从试卷识别到答题卡输出一条龙服务整个框架分为EAST、CRNN、Bert、GPT-2、DNN 5个模块,每个模块的网络单独训练,参数相互独立。infer过程使用pipeline串联,通过外接装置直接输出到答题卡。OpenCV 的EAST文本检测器是一个深度学习模型,它能够在 720p 的图像上以13帧/秒的速度实时检测任意方向的文本,并可以获得很好的文本检测精度。https://github.com/ooooverflow/chinese-ocr下载训练集:共约364万张图片,按照99: 1划分成训练集和验证集数据利用中文语料库(新闻 + 文言文),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成。包含汉字、英文字母、数字和标点共5990个字符,每个样本固定10个字符,字符随机截取自语料库中的句子,图片分辨率统一为280x32。BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder。模型的主要创新点在pre-train方法上,用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。https://github.com/imcaspar/gpt2-ml/预训练语料来自 THUCNews 以及 nlp_chinese_corpus,清洗后总文本量约 15G。Finetune语料来自历年满分高考作文、优质散文集以及近现代散文作品,约1000篇。这部分直接调用百度API。有现成的模型就不重复造轮子了,具体实现方式百度没有开源,这里简单描述一下语言模型的概念:语言模型是通过计算给定词组成的句子的概率,从而判断所组成的句子是否符合客观语言表达习惯。通常用于机器翻译、拼写纠错、语音识别、问答系统、词性标注、句法分析和信息检索等。标题
基于EAST、CRNN、Bert和GPT-2语言模型的高考作文生成AI 支持bert tokenizer,当前版本基于clue chinese vocab 17亿参数多模块异构深度神经网络,超2亿条预训练数据 线上点击即用的文本生成效果demo:17亿参数作文杀手 端到端生成,从试卷识别到答题卡输出一条龙服务整个框架分为EAST、CRNN、Bert、GPT-2、DNN 5个模块,每个模块的网络单独训练,参数相互独立。infer过程使用pipeline串联,通过外接装置直接输出到答题卡。OpenCV 的EAST文本检测器是一个深度学习模型,它能够在 720p 的图像上以13帧/秒的速度实时检测任意方向的文本,并可以获得很好的文本检测精度。https://github.com/ooooverflow/chinese-ocr下载训练集:共约364万张图片,按照99: 1划分成训练集和验证集数据利用中文语料库(新闻 + 文言文),通过字体、大小、灰度、模糊、透视、拉伸等变化随机生成。包含汉字、英文字母、数字和标点共5990个字符,每个样本固定10个字符,字符随机截取自语料库中的句子,图片分辨率统一为280x32。BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder。模型的主要创新点在pre-train方法上,用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。https://github.com/imcaspar/gpt2-ml/预训练语料来自 THUCNews 以及 nlp_chinese_corpus,清洗后总文本量约 15G。Finetune语料来自历年满分高考作文、优质散文集以及近现代散文作品,约1000篇。这部分直接调用百度API。有现成的模型就不重复造轮子了,具体实现方式百度没有开源,这里简单描述一下语言模型的概念:语言模型是通过计算给定词组成的句子的概率,从而判断所组成的句子是否符合客观语言表达习惯。通常用于机器翻译、拼写纠错、语音识别、问答系统、词性标注、句法分析和信息检索等。标题
复用BERT_SUM生成Top3的NER粒度token作为标题
模型 | 参数量 | 下载链接 | 备注 |
EAST | <
0.1 Billion | GoogleDrive | 检测模型 |
CRNN | <
0.1 Billion | 网盘链接 提取码:vKeD | 识别模型 |
BERT | 0.1
Billion | GoogleDrive | 摘要模型 |
GPT-2 | 1.5
Billion | GoogleDrive | 生成模型 |
整个AI的参数量分布不均匀,主要原因在于,这是一个语言类AI,99%的参数量集中在语言网络中,其中GPT-2(15亿)占88%,BERT(1.1亿)占7%,其他的识别网络和判分网络共占5%。
总结:
10年机器视觉网站,5年人工智能网站
2019经历总结,2018视觉总结
项目感悟,赚钱思路,项目视频
课程:
《机器视觉:应用讲解》,一总体概述,二相机篇,三镜头篇,四光源篇,五光学系统选型,六视觉开发软件,七相机标定技术,八项目案例解析,九视觉公司分析,十产业发展情况
笔记:
《智能革命》《人工智能》《AI•未来》《好好赚钱》《韭菜的自我修养》读书笔记
行业:
服务机器人公司,机器视觉公司,自动驾驶公司,ADAS公司总结, 防疫机器人发展,腾讯未来交通
SLAM:
Vslam方案+源码,语义SLAM与深度相机,SLAM和导航避障,视觉SLAM总结
秦学英《三维物体的识别与跟踪》,章国锋《视觉SLAM》,申抒含《基于图像的三维建模》,姜翰青《RGB -D SLAM》记录笔记
视觉SLAM的建图课件3,课件2,课件1
机器视觉:
毫米波雷达,雷达视觉融合,2021视觉研讨会,2020上海研讨会,双目和激光的三维重建,2021视觉市场研究,太阳能行业应用
机器视觉基本概念笔记,记录五,记录四,记录三,记录二,记录一
图像处理:
图像处理基本概念笔记,记录八,记录七,记录六 ,记录五,记录四 ,记录三,记录二 ,记录二,记录一
欢迎支持,点击在看,分享