↑↑↑点击上方蓝字,回复资料,10个G的惊喜
转载于:作者:Criss,来源:机器学习与生成对抗网络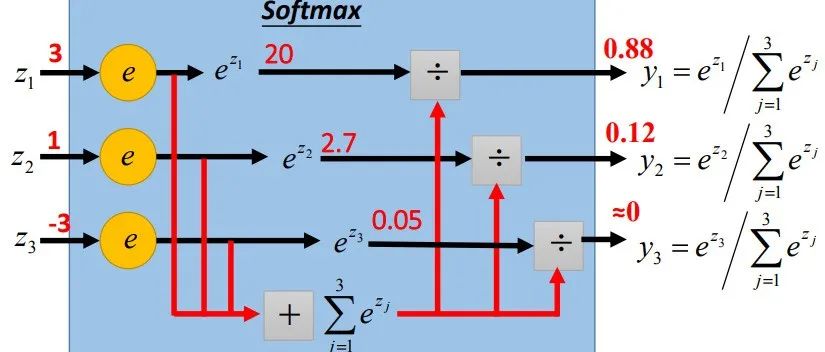
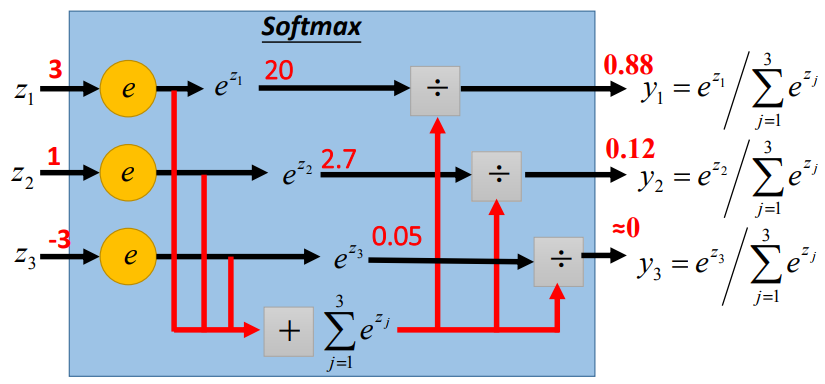
1.1 derivative of softmax一般来说,分类模型的最后一层都是softmax层,假设我们有一个 分类问题,那对应的softmax层结构如下图所示(一般认为输出的结果 即为输入 属于第i类的概率):假设给定训练集 ,分类模型的目标是最大化对数似然函数 ,即通常来说,我们采取的优化方法都是gradient based的(e.g., SGD),也就是说,需要求解 。而我们只要求得 ,之后根据链式法则,就可以求得 ,因此我们的核心在于求解 ,即 由上式可知,我们只需要知道各个样本 的 ,即可通过求和求得 ,进而通过链式法则求得 。因此下面省略样本下标j,仅讨论某个样本 。
实际上对于如何表示 属于第几个类,有两种比较直观的方法:一种是直接法(i.e., 用 来表示x属于第3类),则 ,其中 为指示函数;
另一种是one-hot法(i.e., 用 来表示x属于第三类),则 ,其中 为向量 的第 个元素。
p.s., 也可以将one-hot法理解为直接法的实现形式,因为one-hot向量实际上就是 。
为了方便,本文采用one-hot法。于是,我们有:再补充一下softmax与sigmoid的联系。当分类问题是二分类的时候,我们一般使用sigmoid function作为输出层,表示输入 属于第1类的概率,即乍一看会觉得用sigmoid做二分类跟用softmax做二分类不一样:但实际上,用sigmoid做二分类跟用softmax做二分类是等价的。我们可以让sigmoid的output维数跟类的数量一致,并且在形式上逼近softmax。通过上述变化,sigmoid跟softmax已经很相似了,只不过sigmoid的input的第二个元素恒等于0(i.e., intput为 ),而softmax的input为 ,下面就来说明这两者存在一个mapping的关系(i.e., 每一个 都可以找到一个对应的 来表示相同的softmax结果。不过值得注意的是,反过来并不成立,也就是说并不是每个 仅仅对应一个 )。
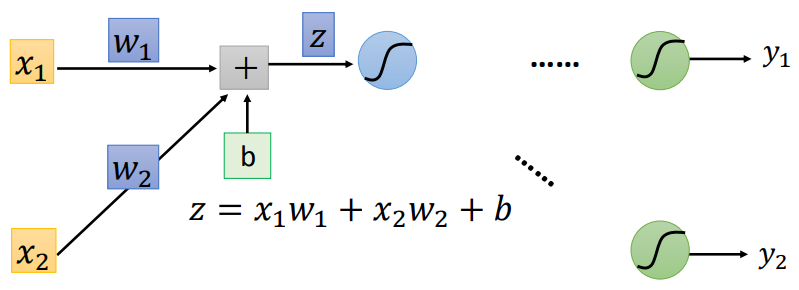
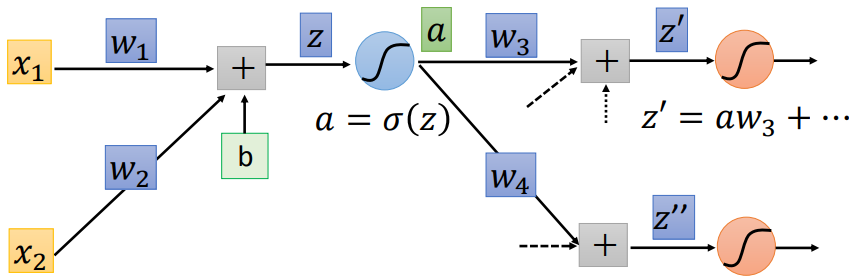
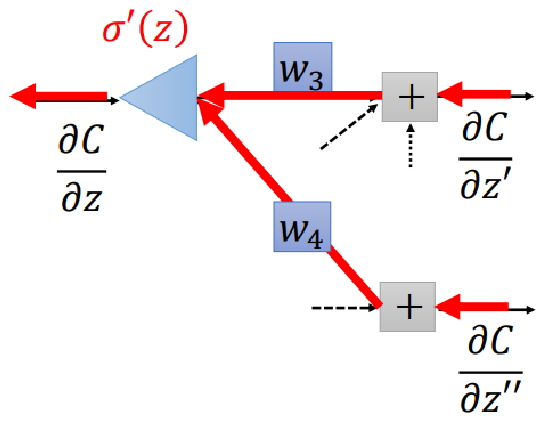
因此,用sigmoid做二分类跟用softmax做二分类是等价的。一般来说,在train一个神经网络时(i.e., 更新网络的参数),我们都需要loss function对各参数的gradient,backpropagation就是求解gradient的一种方法。假设我们有一个如上图所示的神经网络,我们想求损失函数 对 的gradient,那么根据链式法则,我们有而我们可以很容易得到上述式子右边的第二项,因为 ,所以有我们很容易得到上式右边第二项,因为 ,而激活函数 (e.g., sigmoid function)是我们自己定义的,所以有 和 的值是已知的,因此,我们离目标 仅差 和 了。接下来我们采用动态规划(或者说递归)的思路,假设下一层的 和 是已知的,那么我们只需要最后一层的graident,就可以求得各层的gradient了。而通过softmax的例子,我们知道最后一层的gradient确实可求,因此只要从最后一层开始,逐层向前,即可求得各层gradient。因此我们求 的过程实际上对应下图所示的神经网络(原神经网络的反向神经网络):综上,我们先通过神经网络的正向计算,得到 以及 ,进而求得 和 ;然后通过神经网络的反向计算,得到 和 ,进而求得 ;然后根据链式法则求得 。这整个过程就叫做backpropagation,其中正向计算的过程叫做forward pass,反向计算的过程叫做backward pass。具体来说,如下图所示,没有连线的表示对应的w为0: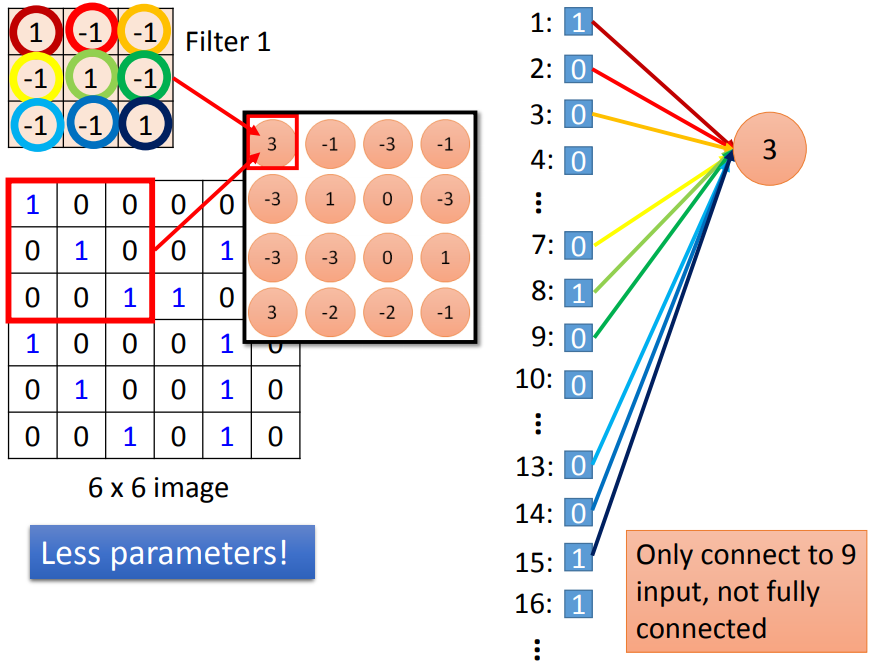

因此,我们可以把loss function理解为 ,然后求导的时候,根据链式法则,将相同w的gradient加起来就好了,即
在求各个 时,可以把他们看成是相互独立的 ,那这样就跟普通的全连接层一样了,因此也就可以用backpropagation来求。RNN按照时序展开之后如下图所示(红线表示了求gradient的路线):
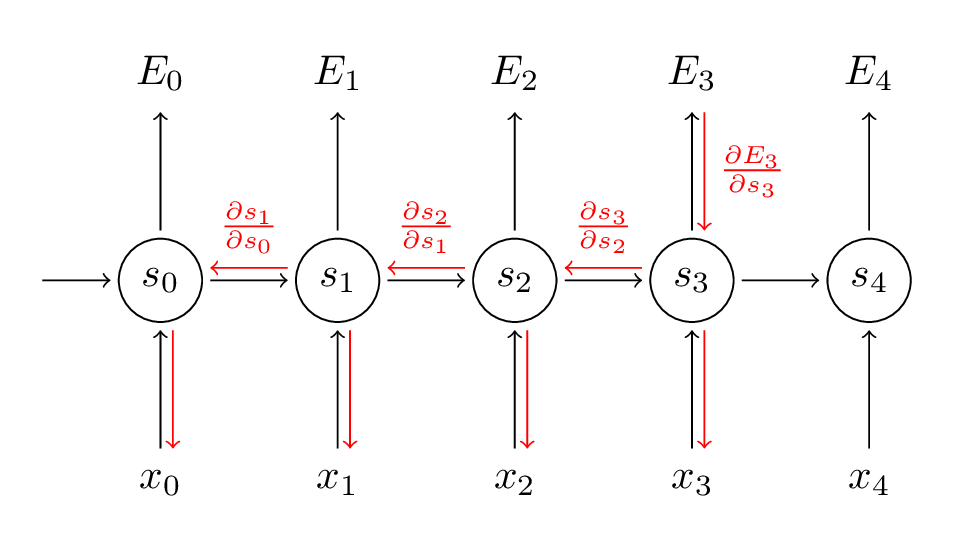
跟处理卷积层的思路一样,首先将loss function理解为 ,然后把各个w看成相互独立,最后根据链式法则求得对应的gradient,即
由于这里是将RNN按照时序展开成为一个神经网络,所以这种求gradient的方法叫Backpropagation Through Time(BPTT)。05 derivative of max pooling
一般来说,函数 是不可导的,但假如我们已经知道哪个自变量会是最大值,那么该函数就是可导的(e.g., 假如知道y是最大的,那对y的偏导为1,对其他自变量的偏导为0)。而在train一个神经网络的时候,我们会先进行forward pass,之后再进行backward pass,因此我们在对max pooling求导的时候,已经知道哪个自变量是最大的,于是也就能够给出对应的gradient了。http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/