
神经网络基础知识总结
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

导读
人工神经网络通常通过一个基于数学统计学类型的学习方法得以优化,本文详细的介绍了神经网络的定义以及相关运算模型的知识点。
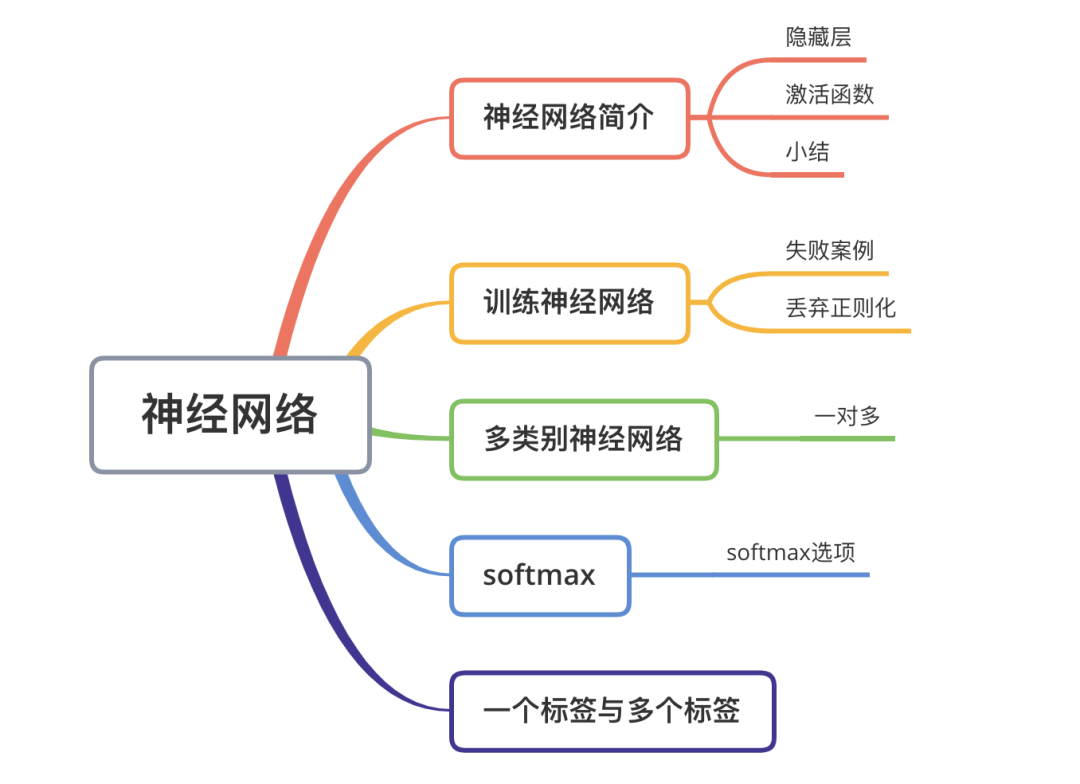
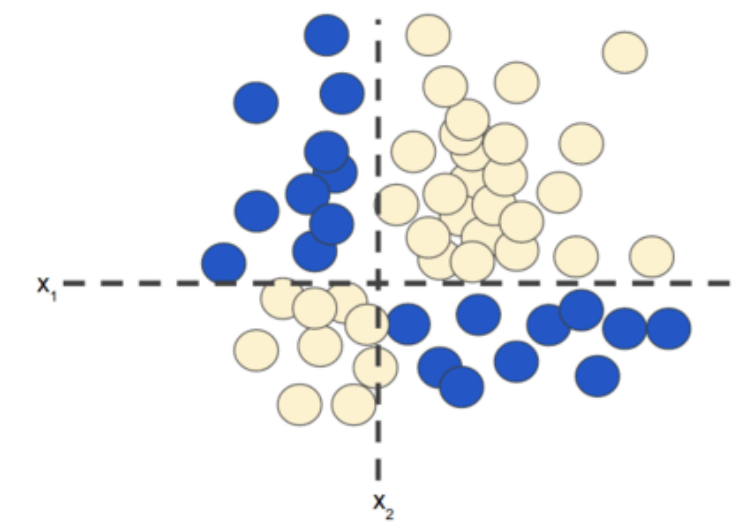
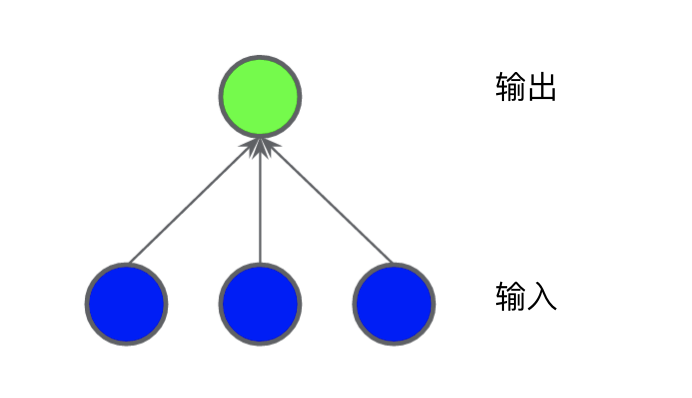
1.1 隐藏层
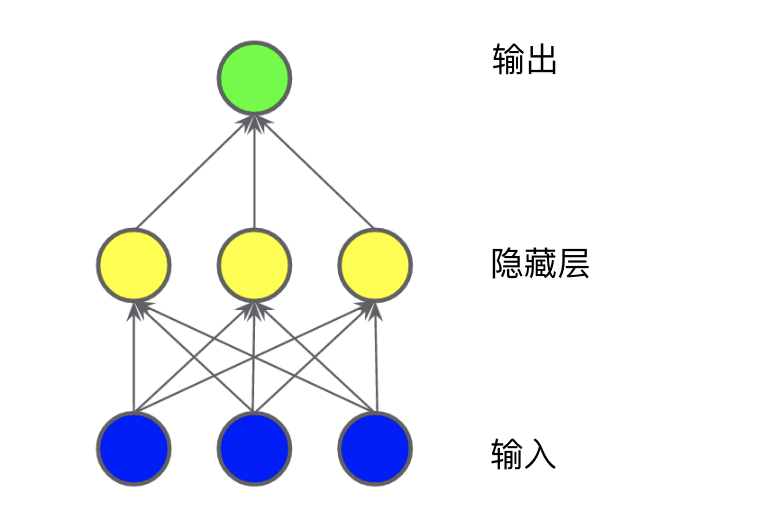
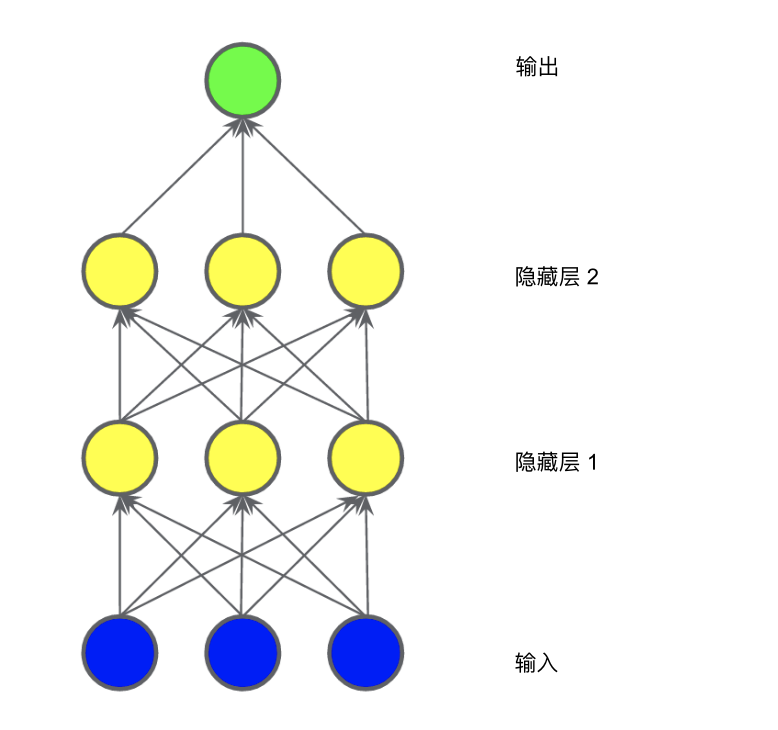
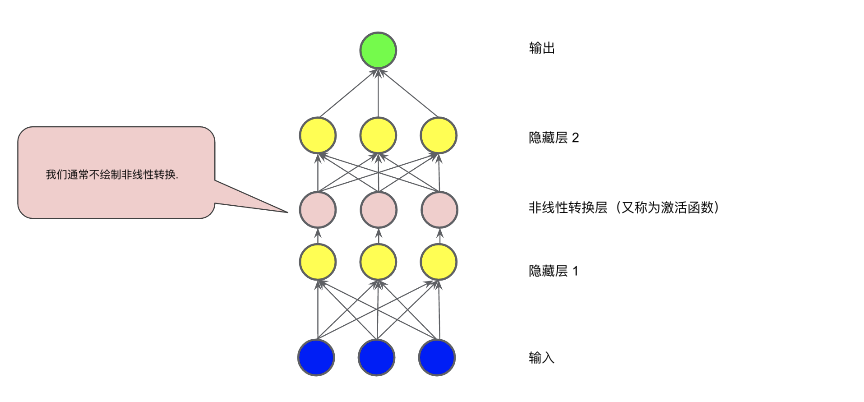
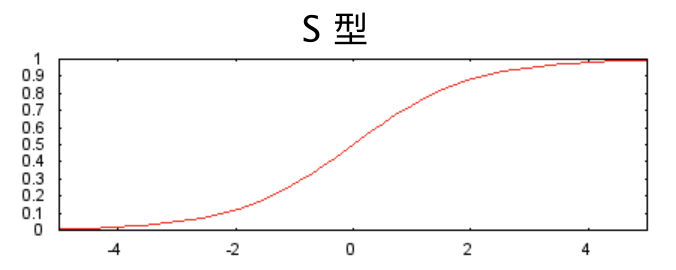
1.2 激活函数
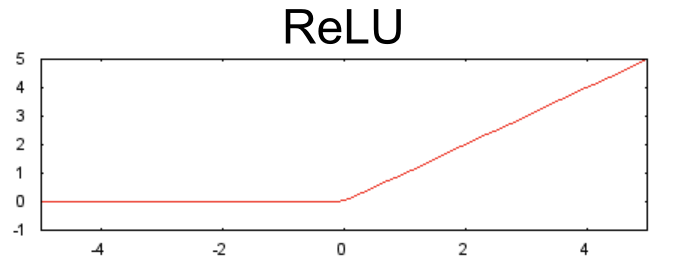
1.3 小结
一组节点,类似于神经元,位于层中。 一组权重,表示每个神经网络层与其下方的层之间的关系。下方的层可能是另一个神经网络层,也可能是其他类型的层。 一组偏差,每个节点一个偏差。 一个激活函数,对层中每个节点的输出进行转换。不同的层可能拥有不同的激活函数。
2.1 失败案例
2.2 丢弃正则化
0.0 = 无丢弃正则化。 1.0 = 丢弃所有内容。模型学不到任何规律。
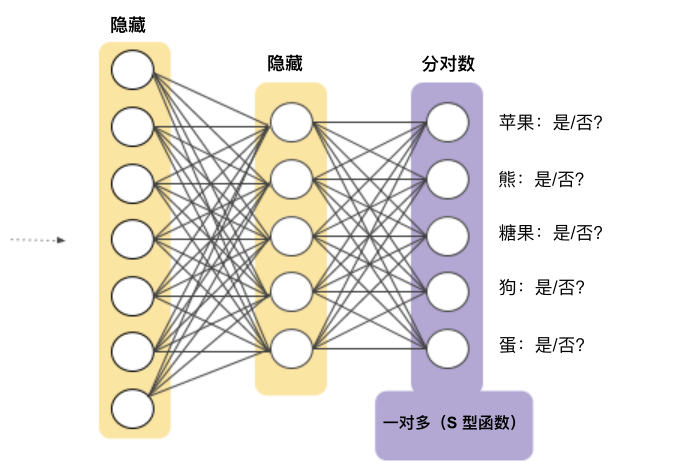
3.1 一对多(OnevsAll)
这是一张苹果的图片吗?不是。 这是一张熊的图片吗?不是。 这是一张糖果的图片吗?不是。 这是一张狗狗的图片吗?是。 这是一张鸡蛋的图片吗?不是。

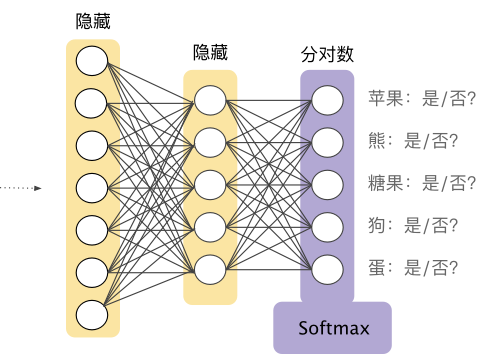
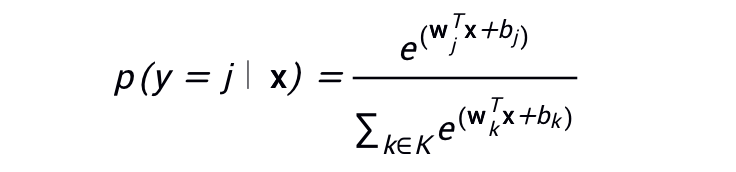
4.1 Softmax 选项
完整 Softmax 是我们一直以来讨论的 Softmax;也就是说,Softmax 针对每个可能的类别计算概率。 候选采样指 Softmax 针对所有正类别标签计算概率,但仅针对负类别标签的随机样本计算概率。例如,如果我们想要确定某个输入图片是小猎犬还是寻血猎犬图片,则不必针对每个非狗狗样本提供概率。
你不能使用 Softmax。 你必须依赖多个逻辑回归。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论