
Netty 应该这样使用,最佳实践!
来源 | https://urlify.cn/3eAZBj
最近很多同学给我发邮件或者微博私信我,咨询推送服务相关的问题。
问题五花八门,在帮助大家答疑解惑的过程中,我也对问题进行了总结,大概可以归纳为如下几类:
Netty 是否可以做推送服务器? 如果使用 Netty 开发推送服务,一个服务器最多可以支撑多少个客户端? 使用 Netty 开发推送服务遇到的各种技术问题。
由于咨询者众多,关注点也比较集中,我希望通过本文的案例分析和对推送服务设计要点的总结,帮助大家在实际工作中少走弯路。
1.2. 推送服务
移动互联网时代,推送 (Push) 服务成为 App 应用不可或缺的重要组成部分,推送服务可以提升用户的活跃度和留存率。我们的手机每天接收到各种各样的广告和提示消息等大多数都是通过推送服务实现的。
随着物联网的发展,大多数的智能家居都支持移动推送服务,未来所有接入物联网的智能设备都将是推送服务的客户端,这就意味着推送服务未来会面临海量的设备和终端接入。
1.3. 推送服务的特点
移动推送服务的主要特点如下:
使用的网络主要是运营商的无线移动网络,网络质量不稳定,例如在地铁上信号就很差,容易发生网络闪断; 海量的客户端接入,而且通常使用长连接,无论是客户端还是服务端,资源消耗都非常大; 由于谷歌的推送框架无法在国内使用,Android 的长连接是由每个应用各自维护的,这就意味着每台安卓设备上会存在多个长连接。即便没有消息需要推送,长连接本身的心跳消息量也是非常巨大的,这就会导致流量和耗电量的增加; 不稳定:消息丢失、重复推送、延迟送达、过期推送时有发生; 垃圾消息满天飞,缺乏统一的服务治理能力。
为了解决上述弊端,一些企业也给出了自己的解决方案,例如京东云推出的推送服务,可以实现多应用单服务单连接模式,使用 AlarmManager 定时心跳节省电量和流量。
2. 智能家居领域的一个真实案例
2.1. 问题描述
智能家居 MQTT 消息服务中间件,保持 10 万用户在线长连接,2 万用户并发做消息请求。程序运行一段时间之后,发现内存泄露,怀疑是 Netty 的 Bug。其它相关信息如下:
MQTT 消息服务中间件服务器内存 16G,8 个核心 CPU; Netty 中 boss 线程池大小为 1,worker 线程池大小为 6,其余线程分配给业务使用。该分配方式后来调整为 worker 线程池大小为 11,问题依旧; Netty 版本为 4.0.8.Final。
2.2. 问题定位
首先需要 dump 内存堆栈,对疑似内存泄露的对象和引用关系进行分析,如下所示:
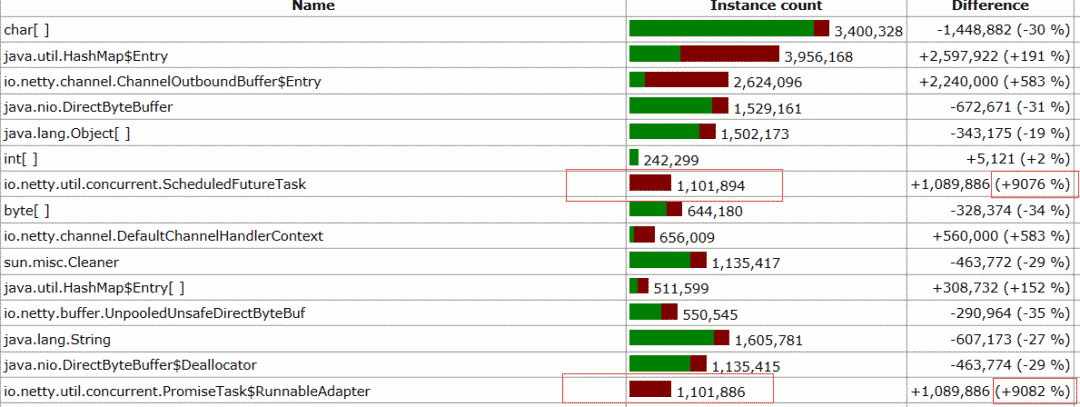
我们发现 Netty 的 ScheduledFutureTask 增加了 9076%,达到 110W 个左右的实例,通过对业务代码的分析发现用户使用 IdleStateHandler 用于在链路空闲时进行业务逻辑处理,但是空闲时间设置的比较大,为 15 分钟。
Netty 的 IdleStateHandler 会根据用户的使用场景,启动三类定时任务,分别是:ReaderIdleTimeoutTask、WriterIdleTimeoutTask 和 AllIdleTimeoutTask,它们都会被加入到 NioEventLoop 的 Task 队列中被调度和执行。
由于超时时间过长,10W 个长链接链路会创建 10W 个 ScheduledFutureTask 对象,每个对象还保存有业务的成员变量,非常消耗内存。用户的持久代设置的比较大,一些定时任务被老化到持久代中,没有被 JVM 垃圾回收掉,内存一直在增长,用户误认为存在内存泄露。
事实上,我们进一步分析发现,用户的超时时间设置的非常不合理,15 分钟的超时达不到设计目标,重新设计之后将超时时间设置为 45 秒,内存可以正常回收,问题解决。
2.3. 问题总结
如果是 100 个长连接,即便是长周期的定时任务,也不存在内存泄露问题,在新生代通过 minor GC 就可以实现内存回收。正是因为十万级的长连接,导致小问题被放大,引出了后续的各种问题。
事实上,如果用户确实有长周期运行的定时任务,该如何处理?对于海量长连接的推送服务,代码处理稍有不慎,就满盘皆输,下面我们针对 Netty 的架构特点,介绍下如何使用 Netty 实现百万级客户端的推送服务。
3. Netty 海量推送服务设计要点
作为高性能的 NIO 框架,利用 Netty 开发高效的推送服务技术上是可行的,但是由于推送服务自身的复杂性,想要开发出稳定、高性能的推送服务并非易事,需要在设计阶段针对推送服务的特点进行合理设计。
3.1. 最大句柄数修改
百万长连接接入,首先需要优化的就是 Linux 内核参数,其中 Linux 最大文件句柄数是最重要的调优参数之一,默认单进程打开的最大句柄数是 1024,通过 ulimit -a 可以查看相关参数,示例如下:
[root@lilinfeng ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 256324
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
...... 后续输出省略
当单个推送服务接收到的链接超过上限后,就会报“too many open files”,所有新的客户端接入将失败。
通过 vi /etc/security/limits.conf 添加如下配置参数:修改之后保存,注销当前用户,重新登录,通过 ulimit -a 查看修改的状态是否生效。
* soft nofile 1000000
* hard nofile 1000000
需要指出的是,尽管我们可以将单个进程打开的最大句柄数修改的非常大,但是当句柄数达到一定数量级之后,处理效率将出现明显下降,因此,需要根据服务器的硬件配置和处理能力进行合理设置。如果单个服务器性能不行也可以通过集群的方式实现。
3.2. 当心 CLOSE_WAIT
从事移动推送服务开发的同学可能都有体会,移动无线网络可靠性非常差,经常存在客户端重置连接,网络闪断等。
在百万长连接的推送系统中,服务端需要能够正确处理这些网络异常,设计要点如下:
客户端的重连间隔需要合理设置,防止连接过于频繁导致的连接失败(例如端口还没有被释放); 客户端重复登陆拒绝机制; 服务端正确处理 I/O 异常和解码异常等,防止句柄泄露。
最后特别需要注意的一点就是 close_wait 过多问题,由于网络不稳定经常会导致客户端断连,如果服务端没有能够及时关闭 socket,就会导致处于 close_wait 状态的链路过多。close_wait 状态的链路并不释放句柄和内存等资源,如果积压过多可能会导致系统句柄耗尽,发生“Too many open files”异常,新的客户端无法接入,涉及创建或者打开句柄的操作都将失败。
下面对 close_wait 状态进行下简单介绍,被动关闭 TCP 连接状态迁移图如下所示:
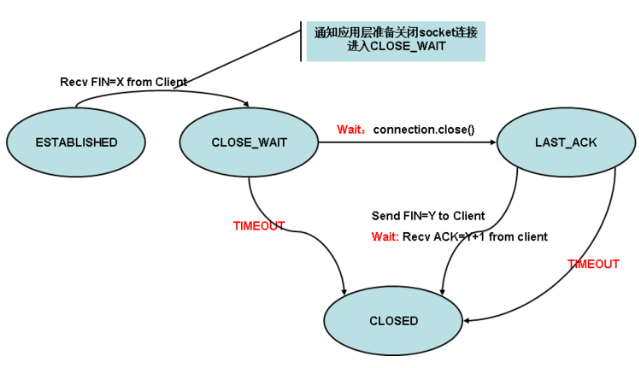
close_wait 是被动关闭连接是形成的,根据 TCP 状态机,服务器端收到客户端发送的 FIN,TCP 协议栈会自动发送 ACK,链接进入 close_wait 状态。但如果服务器端不执行 socket 的 close() 操作,状态就不能由 close_wait 迁移到 last_ack,则系统中会存在很多 close_wait 状态的连接。通常来说,一个 close_wait 会维持至少 2 个小时的时间(系统默认超时时间的是 7200 秒,也就是 2 小时)。如果服务端程序因某个原因导致系统造成一堆 close_wait 消耗资源,那么通常是等不到释放那一刻,系统就已崩溃。
导致 close_wait 过多的可能原因如下:
程序处理 Bug,导致接收到对方的 fin 之后没有及时关闭 socket,这可能是 Netty 的 Bug,也可能是业务层 Bug,需要具体问题具体分析; 关闭 socket 不及时:例如 I/O 线程被意外阻塞,或者 I/O 线程执行的用户自定义 Task 比例过高,导致 I/O 操作处理不及时,链路不能被及时释放。
下面我们结合 Netty 的原理,对潜在的故障点进行分析。
设计要点 1:不要在 Netty 的 I/O 线程上处理业务(心跳发送和检测除外)。Why? 对于 Java 进程,线程不能无限增长,这就意味着 Netty 的 Reactor 线程数必须收敛。Netty 的默认值是 CPU 核数 * 2,通常情况下,I/O 密集型应用建议线程数尽量设置大些,但这主要是针对传统同步 I/O 而言,对于非阻塞 I/O,线程数并不建议设置太大,尽管没有最优值,但是 I/O 线程数经验值是 [CPU 核数 + 1,CPU 核数 *2 ] 之间。
假如单个服务器支撑 100 万个长连接,服务器内核数为 32,则单个 I/O 线程处理的链接数 L = 100/(32 * 2) = 15625。假如每 5S 有一次消息交互(新消息推送、心跳消息和其它管理消息),则平均 CAPS = 15625 / 5 = 3125 条 / 秒。这个数值相比于 Netty 的处理性能而言压力并不大,但是在实际业务处理中,经常会有一些额外的复杂逻辑处理,例如性能统计、记录接口日志等,这些业务操作性能开销也比较大,如果在 I/O 线程上直接做业务逻辑处理,可能会阻塞 I/O 线程,影响对其它链路的读写操作,这就会导致被动关闭的链路不能及时关闭,造成 close_wait 堆积。
设计要点 2:在 I/O 线程上执行自定义 Task 要当心。Netty 的 I/O 处理线程 NioEventLoop 支持两种自定义 Task 的执行:
普通的 Runnable: 通过调用 NioEventLoop 的 execute(Runnable task) 方法执行; 定时任务 ScheduledFutureTask: 通过调用 NioEventLoop 的 schedule(Runnable command, long delay, TimeUnit unit) 系列接口执行。
为什么 NioEventLoop 要支持用户自定义 Runnable 和 ScheduledFutureTask 的执行,并不是本文要讨论的重点,后续会有专题文章进行介绍。本文重点对它们的影响进行分析。
在 NioEventLoop 中执行 Runnable 和 ScheduledFutureTask,意味着允许用户在 NioEventLoop 中执行非 I/O 操作类的业务逻辑,这些业务逻辑通常用消息报文的处理和协议管理相关。它们的执行会抢占 NioEventLoop I/O 读写的 CPU 时间,如果用户自定义 Task 过多,或者单个 Task 执行周期过长,会导致 I/O 读写操作被阻塞,这样也间接导致 close_wait 堆积。
所以,如果用户在代码中使用到了 Runnable 和 ScheduledFutureTask,请合理设置 ioRatio 的比例,通过 NioEventLoop 的 setIoRatio(int ioRatio) 方法可以设置该值,默认值为 50,即 I/O 操作和用户自定义任务的执行时间比为 1:1。
我的建议是当服务端处理海量客户端长连接的时候,不要在 NioEventLoop 中执行自定义 Task,或者非心跳类的定时任务。
设计要点 3:IdleStateHandler 使用要当心。很多用户会使用 IdleStateHandler 做心跳发送和检测,这种用法值得提倡。相比于自己启定时任务发送心跳,这种方式更高效。但是在实际开发中需要注意的是,在心跳的业务逻辑处理中,无论是正常还是异常场景,处理时延要可控,防止时延不可控导致的 NioEventLoop 被意外阻塞。例如,心跳超时或者发生 I/O 异常时,业务调用 Email 发送接口告警,由于 Email 服务端处理超时,导致邮件发送客户端被阻塞,级联引起 IdleStateHandler 的 AllIdleTimeoutTask 任务被阻塞,最终 NioEventLoop 多路复用器上其它的链路读写被阻塞。
对于 ReadTimeoutHandler 和 WriteTimeoutHandler,约束同样存在。
3.3. 合理的心跳周期
百万级的推送服务,意味着会存在百万个长连接,每个长连接都需要靠和 App 之间的心跳来维持链路。合理设置心跳周期是非常重要的工作,推送服务的心跳周期设置需要考虑移动无线网络的特点。
当一台智能手机连上移动网络时,其实并没有真正连接上 Internet,运营商分配给手机的 IP 其实是运营商的内网 IP,手机终端要连接上 Internet 还必须通过运营商的网关进行 IP 地址的转换,这个网关简称为 NAT(NetWork Address Translation),简单来说就是手机终端连接 Internet 其实就是移动内网 IP,端口,外网 IP 之间相互映射。
GGSN(GateWay GPRS Support Note) 模块就实现了 NAT 功能,由于大部分的移动无线网络运营商为了减少网关 NAT 映射表的负荷,如果一个链路有一段时间没有通信时就会删除其对应表,造成链路中断,正是这种刻意缩短空闲连接的释放超时,原本是想节省信道资源的作用,没想到让互联网的应用不得以远高于正常频率发送心跳来维护推送的长连接。以中移动的 2.5G 网络为例,大约 5 分钟左右的基带空闲,连接就会被释放。
由于移动无线网络的特点,推送服务的心跳周期并不能设置的太长,否则长连接会被释放,造成频繁的客户端重连,但是也不能设置太短,否则在当前缺乏统一心跳框架的机制下很容易导致信令风暴(例如微信心跳信令风暴问题)。具体的心跳周期并没有统一的标准,180S 也许是个不错的选择,微信为 300S。
在 Netty 中,可以通过在 ChannelPipeline 中增加 IdleStateHandler 的方式实现心跳检测,在构造函数中指定链路空闲时间,然后实现空闲回调接口,实现心跳的发送和检测,代码如下:
public void initChannel({@link Channel} channel) {
channel.pipeline().addLast("idleStateHandler", new {@link IdleStateHandler}(0, 0, 180));
channel.pipeline().addLast("myHandler", new MyHandler());
}
拦截链路空闲事件并处理心跳:
public class MyHandler extends {@link ChannelHandlerAdapter} {
{@code @Override}
public void userEventTriggered({@link ChannelHandlerContext} ctx, {@link Object} evt) throws {@link Exception} {
if (evt instanceof {@link IdleStateEvent}} {
// 心跳处理
}
}
}
3.4. 合理设置接收和发送缓冲区容量
对于长链接,每个链路都需要维护自己的消息接收和发送缓冲区,JDK 原生的 NIO 类库使用的是 java.nio.ByteBuffer, 它实际是一个长度固定的 Byte 数组,我们都知道数组无法动态扩容,ByteBuffer 也有这个限制,相关代码如下:
public abstract class ByteBuffer
extends Buffer
implements Comparable
{
final byte[] hb; // Non-null only for heap buffers
final int offset;
boolean isReadOnly;
容量无法动态扩展会给用户带来一些麻烦,例如由于无法预测每条消息报文的长度,可能需要预分配一个比较大的 ByteBuffer,这通常也没有问题。但是在海量推送服务系统中,这会给服务端带来沉重的内存负担。假设单条推送消息最大上限为 10K,消息平均大小为 5K,为了满足 10K 消息的处理,ByteBuffer 的容量被设置为 10K,这样每条链路实际上多消耗了 5K 内存,如果长链接链路数为 100 万,每个链路都独立持有 ByteBuffer 接收缓冲区,则额外损耗的总内存 Total(M) = 1000000 * 5K = 4882M。内存消耗过大,不仅仅增加了硬件成本,而且大内存容易导致长时间的 Full GC,对系统稳定性会造成比较大的冲击。
实际上,最灵活的处理方式就是能够动态调整内存,即接收缓冲区可以根据以往接收的消息进行计算,动态调整内存,利用 CPU 资源来换内存资源,具体的策略如下:
ByteBuffer 支持容量的扩展和收缩,可以按需灵活调整,以节约内存; 接收消息的时候,可以按照指定的算法对之前接收的消息大小进行分析,并预测未来的消息大小,按照预测值灵活调整缓冲区容量,以做到最小的资源损耗满足程序正常功能。
幸运的是,Netty 提供的 ByteBuf 支持容量动态调整,对于接收缓冲区的内存分配器,Netty 提供了两种:
FixedRecvByteBufAllocator:固定长度的接收缓冲区分配器,由它分配的 ByteBuf 长度都是固定大小的,并不会根据实际数据报的大小动态收缩。但是,如果容量不足,支持动态扩展。动态扩展是 Netty ByteBuf 的一项基本功能,与 ByteBuf 分配器的实现没有关系; AdaptiveRecvByteBufAllocator:容量动态调整的接收缓冲区分配器,它会根据之前 Channel 接收到的数据报大小进行计算,如果连续填充满接收缓冲区的可写空间,则动态扩展容量。如果连续 2 次接收到的数据报都小于指定值,则收缩当前的容量,以节约内存。
相对于 FixedRecvByteBufAllocator,使用 AdaptiveRecvByteBufAllocator 更为合理,可以在创建客户端或者服务端的时候指定 RecvByteBufAllocator,代码如下:
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.RCVBUF_ALLOCATOR, AdaptiveRecvByteBufAllocator.DEFAULT)
如果默认没有设置,则使用 AdaptiveRecvByteBufAllocator。
另外值得注意的是,无论是接收缓冲区还是发送缓冲区,缓冲区的大小建议设置为消息的平均大小,不要设置成最大消息的上限,这会导致额外的内存浪费。通过如下方式可以设置接收缓冲区的初始大小:
/**
* Creates a new predictor with the specified parameters.
*
* @param minimum
* the inclusive lower bound of the expected buffer size
* @param initial
* the initial buffer size when no feed back was received
* @param maximum
* the inclusive upper bound of the expected buffer size
*/
public AdaptiveRecvByteBufAllocator(int minimum, int initial, int maximum)
对于消息发送,通常需要用户自己构造 ByteBuf 并编码,例如通过如下工具类创建消息发送缓冲区:
3.5. 内存池
推送服务器承载了海量的长链接,每个长链接实际就是一个会话。如果每个会话都持有心跳数据、接收缓冲区、指令集等数据结构,而且这些实例随着消息的处理朝生夕灭,这就会给服务器带来沉重的 GC 压力,同时消耗大量的内存。
最有效的解决策略就是使用内存池,每个 NioEventLoop 线程处理 N 个链路,在线程内部,链路的处理时串行的。假如 A 链路首先被处理,它会创建接收缓冲区等对象,待解码完成之后,构造的 POJO 对象被封装成 Task 后投递到后台的线程池中执行,然后接收缓冲区会被释放,每条消息的接收和处理都会重复接收缓冲区的创建和释放。如果使用内存池,则当 A 链路接收到新的数据报之后,从 NioEventLoop 的内存池中申请空闲的 ByteBuf,解码完成之后,调用 release 将 ByteBuf 释放到内存池中,供后续 B 链路继续使用。
使用内存池优化之后,单个 NioEventLoop 的 ByteBuf 申请和 GC 次数从原来的 N = 1000000/64 = 15625 次减少为最少 0 次(假设每次申请都有可用的内存)。
下面我们以推特使用 Netty4 的 PooledByteBufAllocator 进行 GC 优化作为案例,对内存池的效果进行评估,结果如下:
垃圾生成速度是原来的 1/5,而垃圾清理速度快了 5 倍。使用新的内存池机制,几乎可以把网络带宽压满。
Netty4 之前的版本问题如下:每当收到新信息或者用户发送信息到远程端,Netty 3 均会创建一个新的堆缓冲区。这意味着,对应每一个新的缓冲区,都会有一个 new byte[capacity]。这些缓冲区会导致 GC 压力,并消耗内存带宽。为了安全起见,新的字节数组分配时会用零填充,这会消耗内存带宽。然而,用零填充的数组很可能会再次用实际的数据填充,这又会消耗同样的内存带宽。如果 Java 虚拟机(JVM)提供了创建新字节数组而又无需用零填充的方式,那么我们本来就可以将内存带宽消耗减少 50%,但是目前没有那样一种方式。
在 Netty 4 中实现了一个新的 ByteBuf 内存池,它是一个纯 Java 版本的 jemalloc (Facebook 也在用)。现在,Netty 不会再因为用零填充缓冲区而浪费内存带宽了。不过,由于它不依赖于 GC,开发人员需要小心内存泄漏。如果忘记在处理程序中释放缓冲区,那么内存使用率会无限地增长。
Netty 默认不使用内存池,需要在创建客户端或者服务端的时候进行指定,代码如下:
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
使用内存池之后,内存的申请和释放必须成对出现,即 retain() 和 release() 要成对出现,否则会导致内存泄露。
值得注意的是,如果使用内存池,完成 ByteBuf 的解码工作之后必须显式的调用 ReferenceCountUtil.release(msg) 对接收缓冲区 ByteBuf 进行内存释放,否则它会被认为仍然在使用中,这样会导致内存泄露。
3.6. 当心“日志隐形杀手”
通常情况下,大家都知道不能在 Netty 的 I/O 线程上做执行时间不可控的操作,例如访问数据库、发送 Email 等。但是有个常用但是非常危险的操作却容易被忽略,那便是记录日志。
通常,在生产环境中,需要实时打印接口日志,其它日志处于 ERROR 级别,当推送服务发生 I/O 异常之后,会记录异常日志。如果当前磁盘的 WIO 比较高,可能会发生写日志文件操作被同步阻塞,阻塞时间无法预测。这就会导致 Netty 的 NioEventLoop 线程被阻塞,Socket 链路无法被及时关闭、其它的链路也无法进行读写操作等。
以最常用的 log4j 为例,尽管它支持异步写日志(AsyncAppender),但是当日志队列满之后,它会同步阻塞业务线程,直到日志队列有空闲位置可用,相关代码如下:
synchronized (this.buffer) {
while (true) {
int previousSize = this.buffer.size();
if (previousSize < this.bufferSize) {
this.buffer.add(event);
if (previousSize != 0) break;
this.buffer.notifyAll(); break;
}
boolean discard = true;
if ((this.blocking) && (!Thread.interrupted()) && (Thread.currentThread() != this.dispatcher)) // 判断是业务线程
{
try
{
this.buffer.wait();// 阻塞业务线程
discard = false;
}
catch (InterruptedException e)
{
Thread.currentThread().interrupt();
}
}
类似这类 BUG 具有极强的隐蔽性,往往 WIO 高的时间持续非常短,或者是偶现的,在测试环境中很难模拟此类故障,问题定位难度非常大。这就要求读者在平时写代码的时候一定要当心,注意那些隐性地雷。
3.7. TCP 参数优化
常用的 TCP 参数,例如 TCP 层面的接收和发送缓冲区大小设置,在 Netty 中分别对应 ChannelOption 的 SO_SNDBUF 和 SO_RCVBUF,需要根据推送消息的大小,合理设置,对于海量长连接,通常 32K 是个不错的选择。
另外一个比较常用的优化手段就是软中断,如图所示:如果所有的软中断都运行在 CPU0 相应网卡的硬件中断上,那么始终都是 cpu0 在处理软中断,而此时其它 CPU 资源就被浪费了,因为无法并行的执行多个软中断。
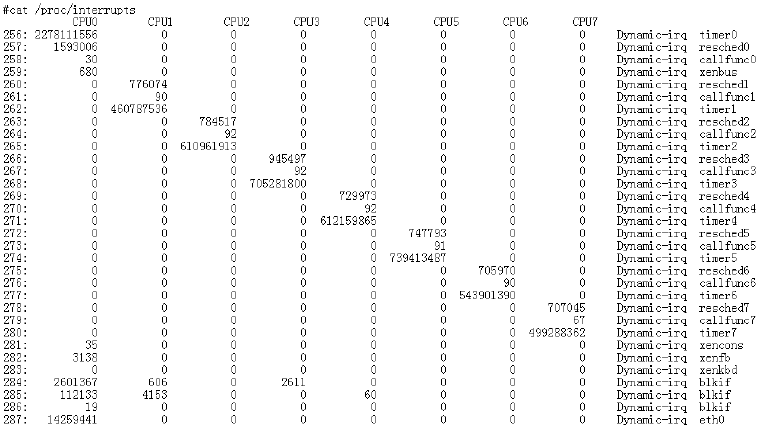
图 3-3 中断信息
大于等于 2.6.35 版本的 Linux kernel 内核,开启 RPS,网络通信性能提升 20% 之上。RPS 的基本原理:根据数据包的源地址,目的地址以及目的和源端口,计算出一个 hash 值,然后根据这个 hash 值来选择软中断运行的 cpu。从上层来看,也就是说将每个连接和 cpu 绑定,并通过这个 hash 值,来均衡软中断运行在多个 cpu 上,从而提升通信性能。
3.8. JVM 参数
最重要的参数调整有两个:
-Xmx:JVM 最大内存需要根据内存模型进行计算并得出相对合理的值; GC 相关的参数: 例如新生代和老生代、永久代的比例,GC 的策略,新生代各区的比例等,需要根据具体的场景进行设置和测试,并不断的优化,尽量将 Full GC 的频率降到最低。
END

