
盘点Pandas中csv文件读取的方法所带参数usecols知识
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python最强王者群有个叫【老松鼠】的粉丝问了一个关于Pandas中csv文件读取的方法所带参数usecols知识问题,这里拿出来给大家分享下,一起学习。
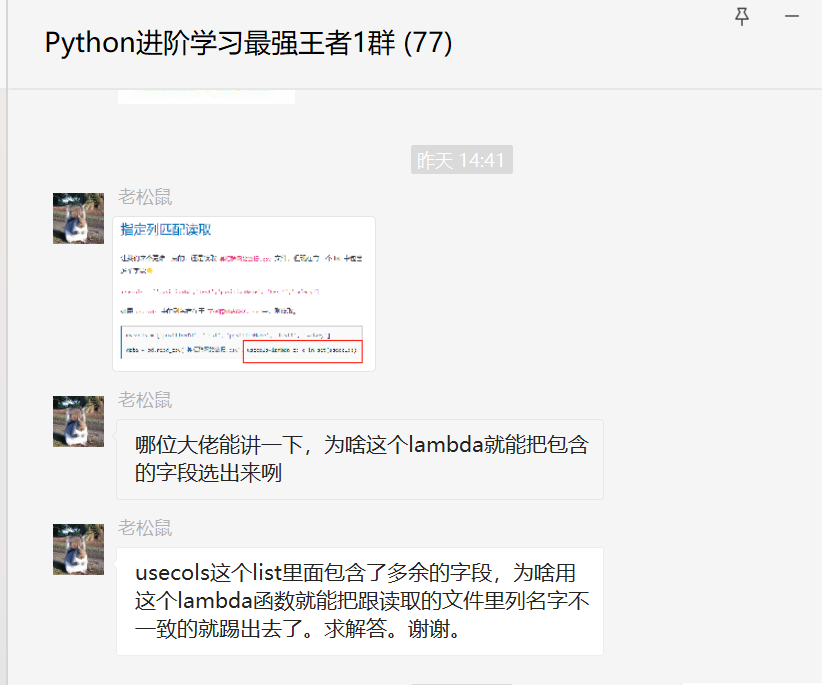
其实usecols参数是指定列读取。
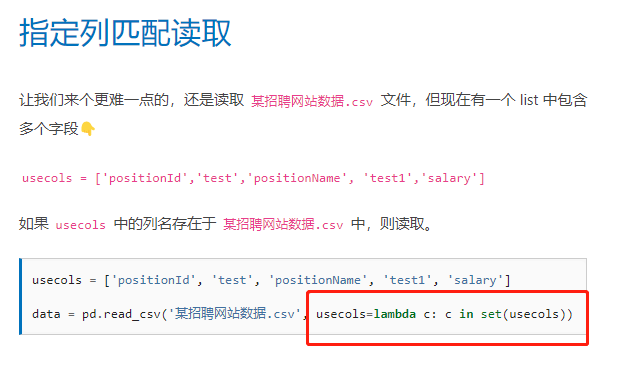
二、解决过程
下面是【德善堂小儿推拿-瑜亮老师】大佬解答:
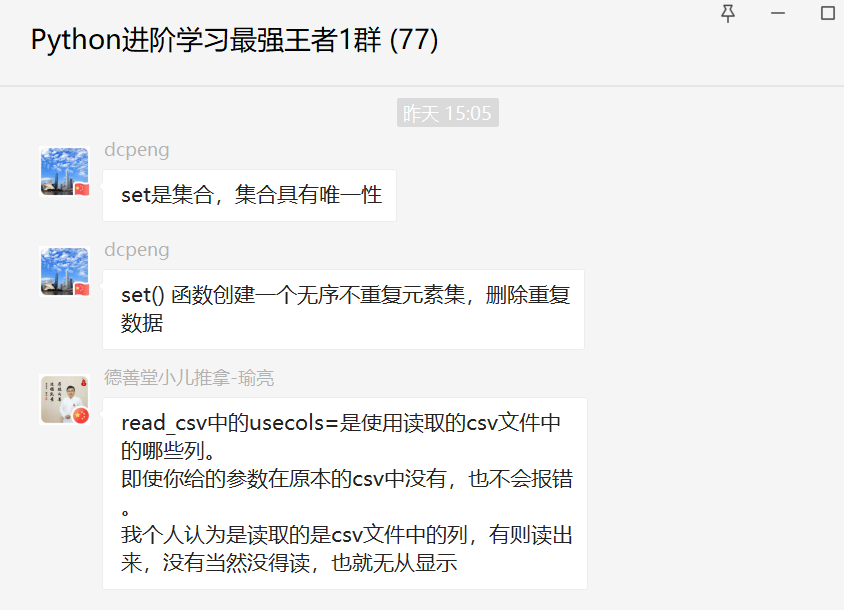
举个栗子,就像你手中只有常见的人民币面值,让你把面值等于5元,10元,10000元的拿出来。你是不是只能拿出来5元的和10元的。读取,那不是有啥就拿出来啥,手中没有,当然就不用给了。
后来【月神】给补充了一些知识,不知道你有没有注意到usecols这个参数其实是有返回值的?大部分小伙伴是没有注意到的。
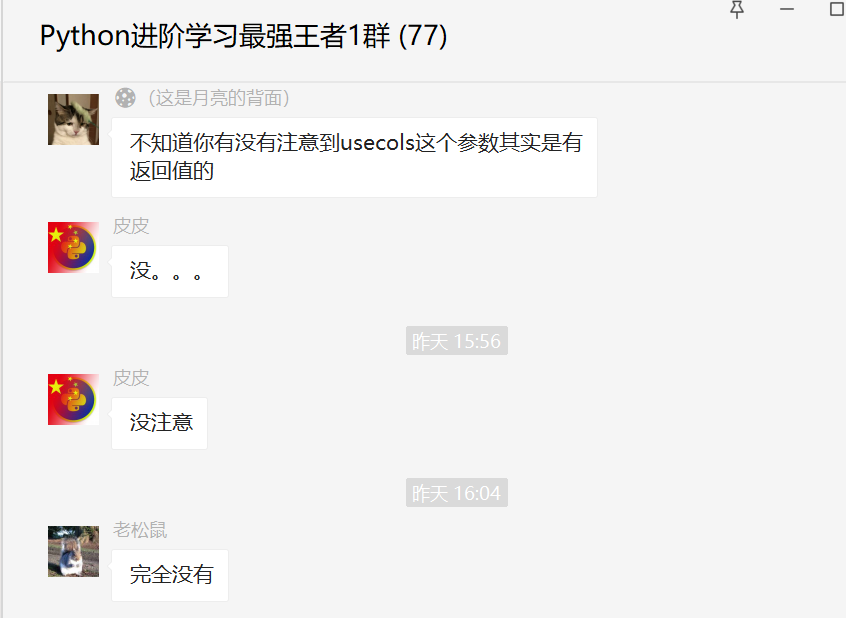
usecols是先从读取到的数据判断出当前的列名并作为返回值,类似于列表,使用函数调用时,例如lambda x:各个元素都会被使用到,类似于map(lambda x: x, iterable), iterable就是usecols的返回值,lambda x与此处一致,再将结果传入至read_csv中,返回指定列的数据框。
对应这个例子中就是lambda c: c in iterable,其实不管iterable是列表还是集合,两者中包含的元素是一样的,那取出来的列都是一样的;而这里面的 c 就是usecols的返回值,可以尝试打印出这个c,就是你要读取的csv文件的所有列的列名
后面有拓展一些关于列表推导式的内容,可以学习下。

还有一个更秀的。
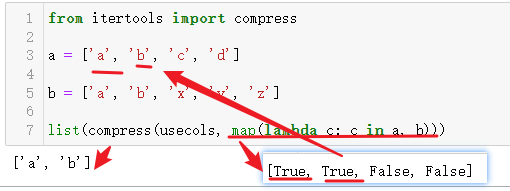 compress()函数帮助列表能够实现布尔索引的函数。
compress()函数帮助列表能够实现布尔索引的函数。
不过话说回来,我一般都是直接全部导入的,一把梭哈。
三、总结
大家好,我是皮皮。这篇文章基于粉丝提问,针对Pandas中csv文件读取的方法所带参数usecols知识,给出了具体说明和演示,顺利地帮助粉丝解决了问题!当然了,在实际工作中,大部分情况还是直接全部导入的。
此外,read_csv有几个比较好的参数,会用的多,一个限制内存,一个分块,这个网上有一大堆的讲解,这里就没有涉猎了。
最后感谢粉丝【老松鼠】提问,感谢【德善堂小儿推拿-瑜亮老师】、【🌑(这是月亮的背面)】和【dcpeng】大佬给出的示例和代码支持,感谢粉丝【Zhang Zhiyu】、【冫马讠成】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行