
盘点csv文件中工作经验列工作年限数字正则提取的四个方法
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是Python进阶者。
一、前言
前几天在Python黄金交流群有个叫【安啦!】的粉丝问了一个Python正则表达式提取数字的问题,这里拿出来给大家分享下,一起学习下。

代码截图如下:
 可能有的粉丝不明白,这里再补充下。下图是她的原始数据列,关于【工作经验】列的统计。
可能有的粉丝不明白,这里再补充下。下图是她的原始数据列,关于【工作经验】列的统计。
 现在她的需求是将工作年限提取出来,用于后面的多元回归分析。
现在她的需求是将工作年限提取出来,用于后面的多元回归分析。
二、解决过程
这里提供四个解决方法,感谢【Python进阶者】和【月神】提供的方法。前面两种是【Python进阶者】的,后面两个是【月神】提供的,一起来学习下吧!
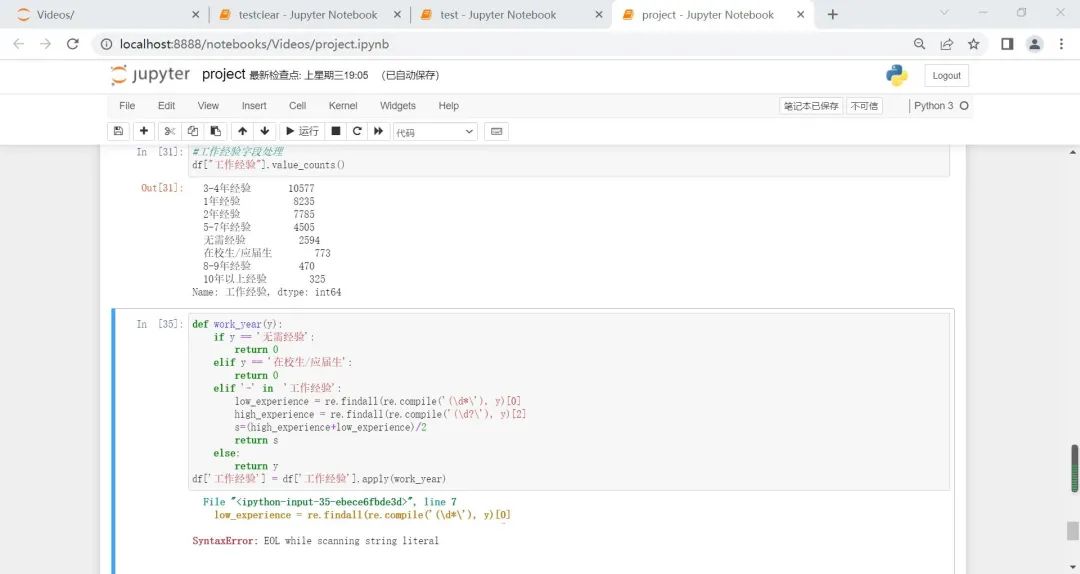
方法一
代码如下:
def work_year(y):
y = y.strip()
if y == '无需经验':
return 0
elif y == '在校生/应届生':
return 0
elif '-' in y and '年经验' in y:
low_experience = re.findall(re.compile('(\d*\.?\d+)'), y)[0]
high_experience = re.findall(re.compile('(\d?\.?\d+)'), y)[1]
s = round((float(low_experience) + float(high_experience)) / 2, 0)
return s
elif '年经验' in y or '年以上经验' in y:
year = re.findall(re.compile('^(\d+)'), y)[0]
return year
else:
return y
df['new']=df['工作经验'].apply(work_year)
df.head()
运行结果如下图所示:

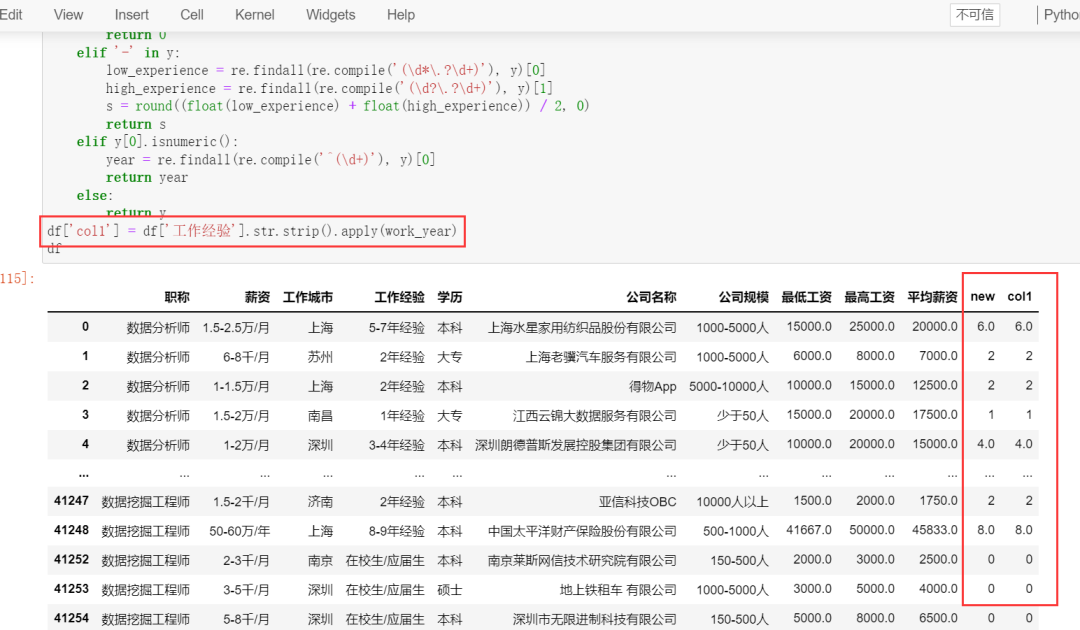
方法二
代码如下:
def work_year(y):
if y == '无需经验':
return 0
elif y == '在校生/应届生':
return 0
elif '-' in y:
low_experience = re.findall(re.compile('(\d*\.?\d+)'), y)[0]
high_experience = re.findall(re.compile('(\d?\.?\d+)'), y)[1]
s = round((float(low_experience) + float(high_experience)) / 2, 0)
return s
elif y[0].isnumeric():
year = re.findall(re.compile('^(\d+)'), y)[0]
return year
else:
return y
df['col1'] = df['工作经验'].str.strip().apply(work_year)
df

运行结果如下图所示:
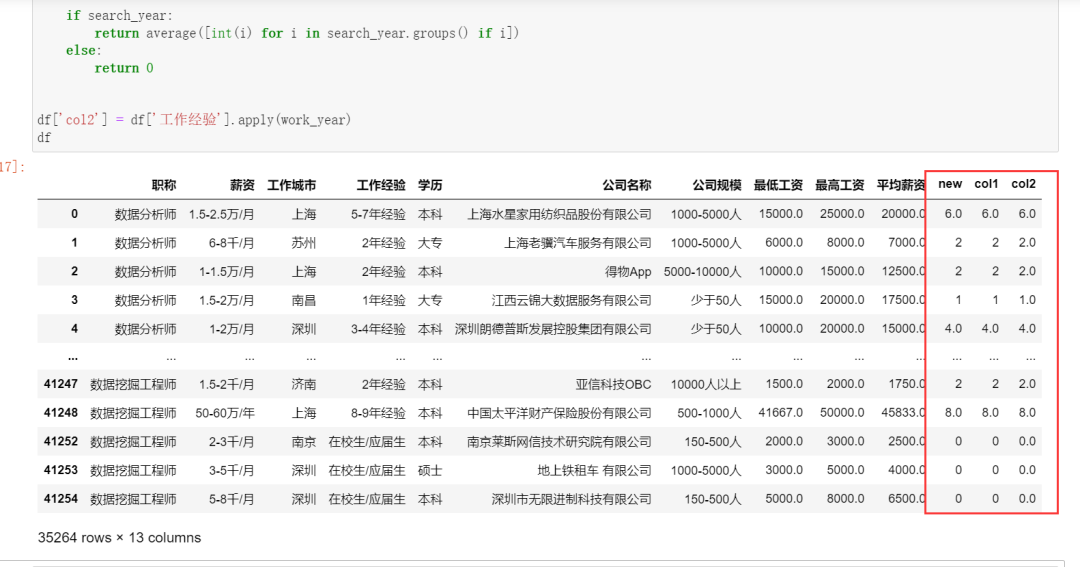
方法三
代码如下:
def work_year(y):
search_year = re.search(r'(\d+)?-?(\d+)', y)
def average(args):
x = tuple(args)
length = len(x)
return round(sum(x) / length, 0)
if search_year:
return average([int(i) for i in search_year.groups() if i])
else:
return 0
df['new1'] = df['工作经验'].apply(work_year)
这里只需要写一个正则表达式就行了,如果取到值就对取到的值求平均,没有就返回0。
运行结果如下图所示:
方法四
代码如下:
df['new2'] = df['工作经验'].str.extract(r'(\d+)?-?(\d+)').astype(float).mean(axis=1).fillna(0).round(0)
这个是用str.extract提取正则,正则表达式和上面一样,用了很多的链式方法,运行结果如下图所示:
所以代码简单了,但是可能不太好懂。
三、总结
大家好,我是Python进阶者。这篇文章基于粉丝提问,盘点了csv文件中工作经验列工作年限数字正则提取的三个方法,代码非常实用,可以举一反三,文中针对该问题给出了具体的解析和代码演示,帮助粉丝顺利解决了问题。
最后感谢粉丝【安啦!】提问,感谢【Python进阶者】、【月神】给出的具体解析和代码演示,感谢粉丝【dcpeng】、【win7】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何Python问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行