
Python 爬虫进阶必备 | 某新闻网正文图片 data-src 解密逻辑分析
点击上方“咸鱼学Python”,选择“加为星标”
第一时间关注Python技术干货!
 图源:网络
图源:网络
今日网站
aHR0cHM6Ly93d3cuc29odS5jb20vYS82MTA5ODU2NDZfMTIxMzMzNzQz
抓包分析
像新闻站点的反爬一般都比较简单,可能就是加个签,对爬虫相对友好,毕竟为了自来水的流量也不能整一些花里胡哨的东西
打开目标站点,通过请求可以看到 response 中是由新闻内容的

但是新闻里的图片都是加密的,没办法直接看到源链接
加密定位与分析
可以看到,所以的图片都是 src 属性的内容
所以网页在加载的时候需要操作图片的src属性,所以我们搜索的重点就是他
直接搜索 src 可以得到下面的内容

进入 js 继续搜索,找到下面的位置
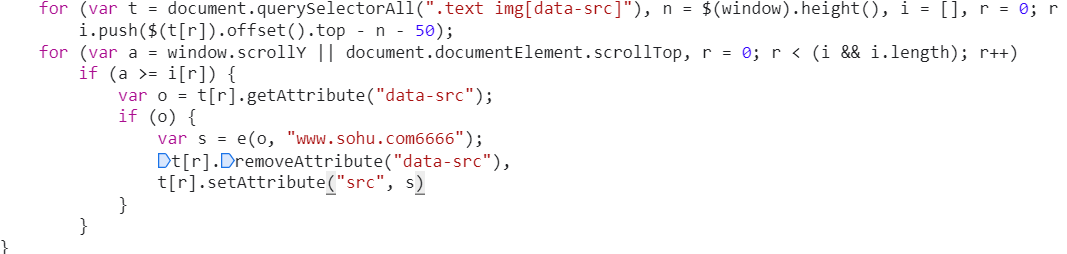
可以看到这里获取了 src 的值,然后这个属性进行了一些操作,这样的操作就很可疑了
打上断点再刷新

这里的 o 就是加密图片的值
然后运行到 xx.setAttribute 的位置的时候,就已经变成明文的图片链接了

所以关键的逻辑就是 var s = e(o,"www.xxx66.com") 这一行
我们重新刷新,然后单步到 e 的逻辑当中

单步进去之后代码就很简洁了,具体的操作就是一个 AES 解密的操作
我们找到AES 三元素就可以直接用自己的代码复现出来了
首先是 key , 这里的 key 就是 e 方法传入的参数2,"www.sox66.com"
因为使用的是 ECB 模式所以不需要 IV,填充方式为 pkcs7
有了上面的内容,就可以直接复现了
代码示例
import base64
from Crypto.Cipher import AES
def decrypt_img_data(data):
html = base64.b64decode(data)
key = b'www.xxx.xxx6666'
aes = AES.new(key=key, mode=AES.MODE_ECB)
decrypt_data = aes.decrypt(html).decode()
print(decrypt_data)
return decrypt_data
if __name__ == '__main__':
decrypt_img_data(
"ZqqdApMA/yaR/foHptBuz+jwr47D8luFD15aBAmwHoobnaVtAoRWQQuxZXM7etE5f2ZbwA1UQPJ05kM4QYMzT9NbmrugZ7Ix0rwjLtstEHg=")
运行结果

End.
以上就是全部的内容了,咱们下次再会~
备注【咸鱼666】,入群交流
我是没有更新就在摸鱼的咸鱼
收到请回复~
我们下次再见。
 咸鱼:来都来了,再不点赞就不礼貌了!
咸鱼:来都来了,再不点赞就不礼貌了!
评论