
不用一行代码,就写了个爬虫!这款谷歌插件已经打包好了!
公众号关注 “GitHubDaily”
设为 “星标”,每天带你逛 GitHub!

前言
前几天发现了一个比较有用的谷歌插件,大家看标题也许已经知道它有啥用了。下面给大家介绍一下这款插件的用法,文末也提供了下载链接。
使用
首先简单介绍一下是个啥插件: 如图所示确保安装成功插件后,我们就可以愉快的玩耍了。
如图所示确保安装成功插件后,我们就可以愉快的玩耍了。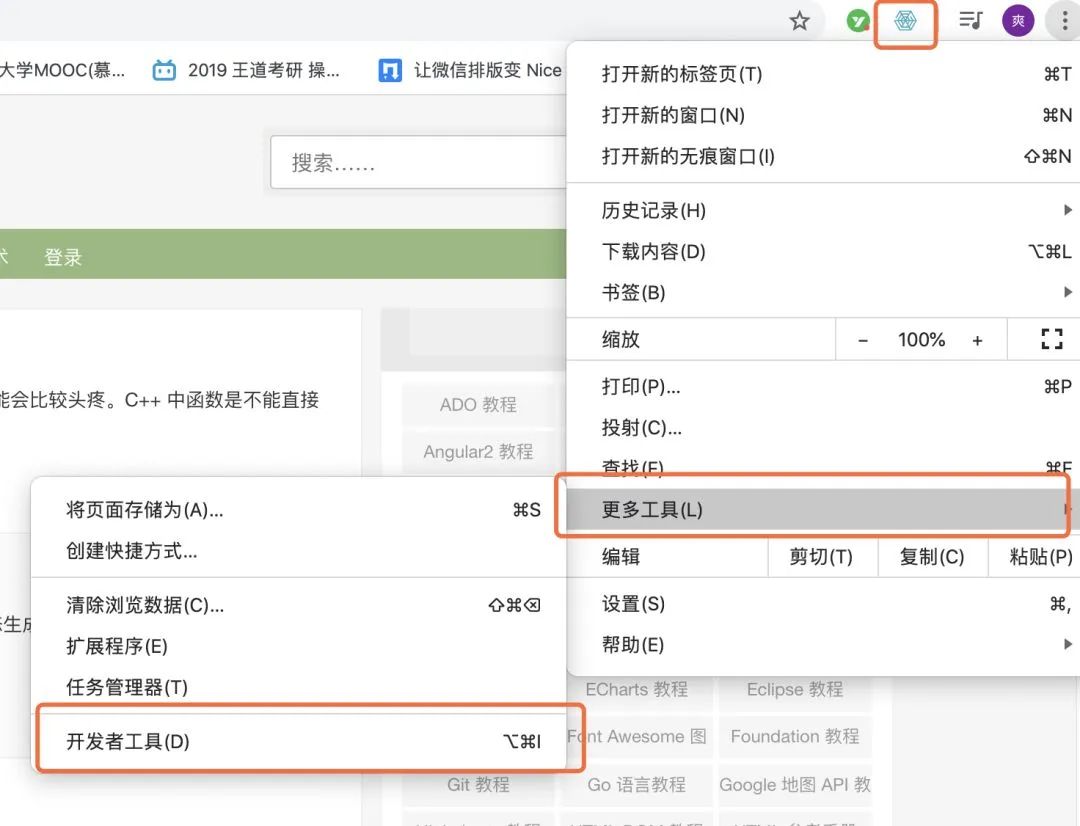 第一步,打开熟悉的开发者工具。
第一步,打开熟悉的开发者工具。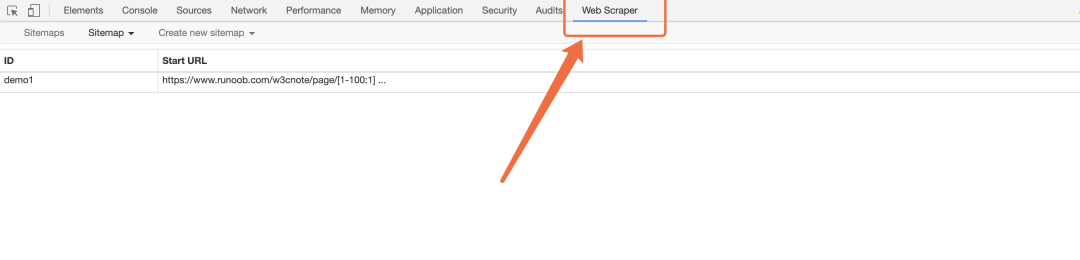 可以看到,最右边多了一个 Web Scraper 的选项栏。找到地方后,我们找个网站来爬爬。
可以看到,最右边多了一个 Web Scraper 的选项栏。找到地方后,我们找个网站来爬爬。 我这里找的是菜鸟笔记的网站,地址扔给大家,大家可以先拿它练练手。
我这里找的是菜鸟笔记的网站,地址扔给大家,大家可以先拿它练练手。https://www.runoob.com/w3cnote接下来怎么做呢?
 点击
点击Create Sitemap创建一个项目。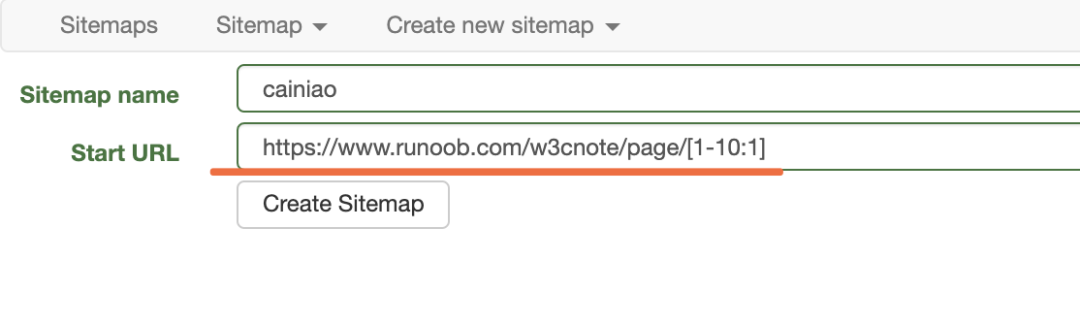 填写相关信息,在开始url那个框里,可能大家注意到后面加了个
填写相关信息,在开始url那个框里,可能大家注意到后面加了个[1-10:1]这代表着我要爬取前十页的数据。这里也是对url进行了一个简单的分析。 创建完成,增加一个选择器。由于,我这里只是简单的给大家操作一下怎么爬取,所以我这里就爬取前十篇文章中的标题,插件了也有很多的爬取方式,大家可以试一试。
创建完成,增加一个选择器。由于,我这里只是简单的给大家操作一下怎么爬取,所以我这里就爬取前十篇文章中的标题,插件了也有很多的爬取方式,大家可以试一试。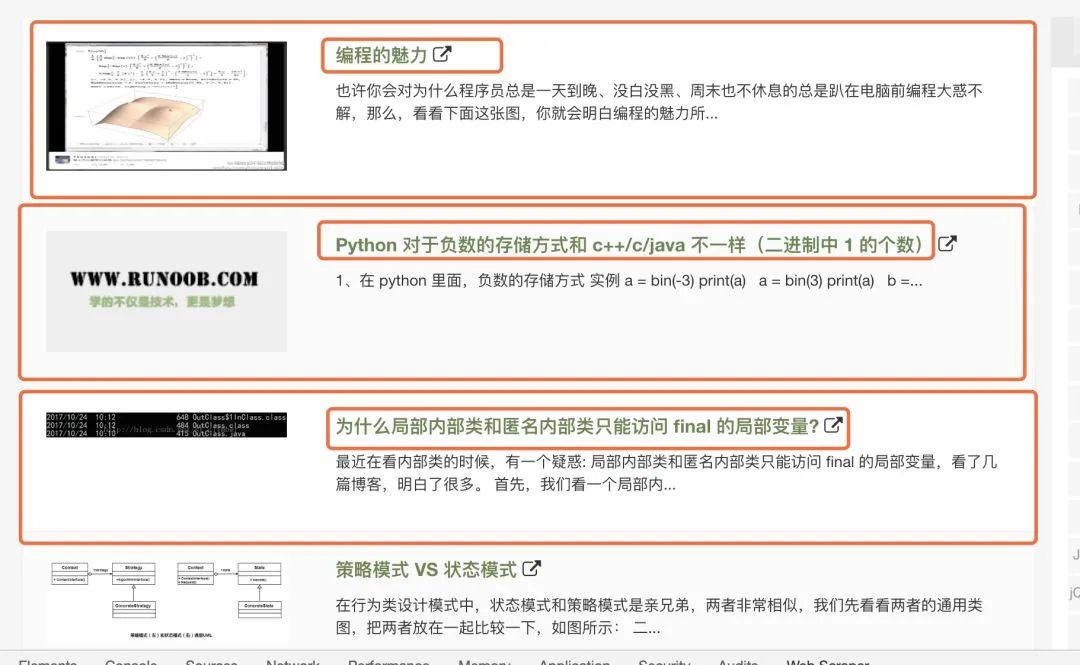 首先我们锁定外面的红框
首先我们锁定外面的红框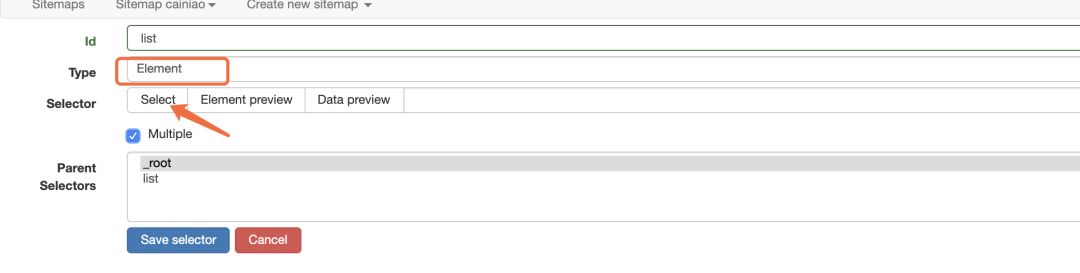
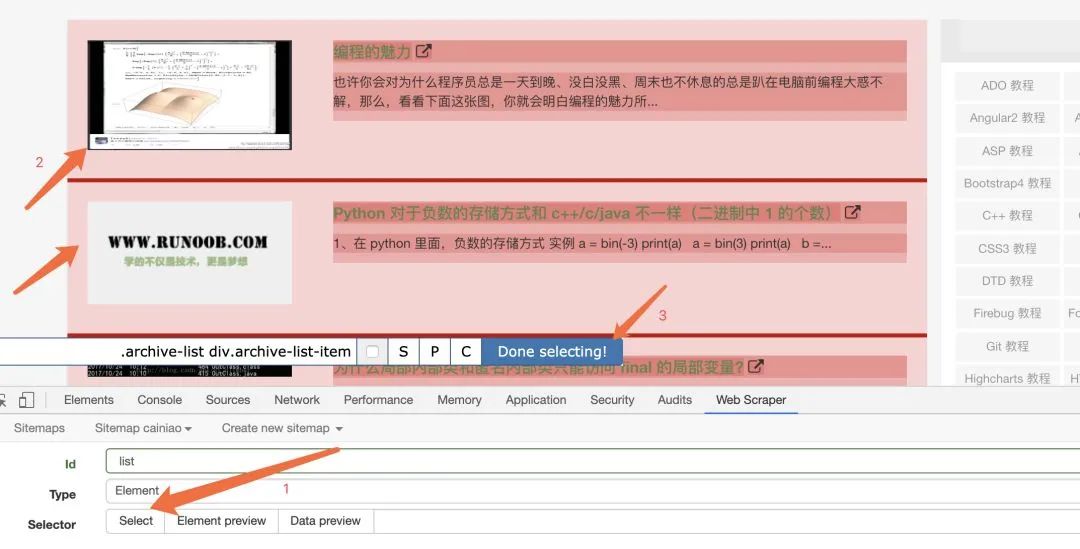 大家按照我的图片上操作,选择自己要爬取的元素。
大家按照我的图片上操作,选择自己要爬取的元素。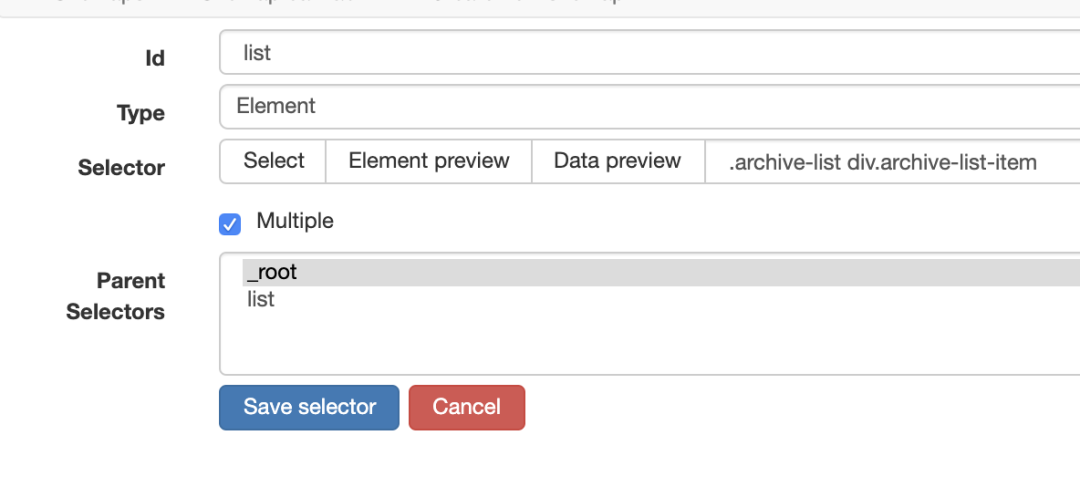 保存之后
保存之后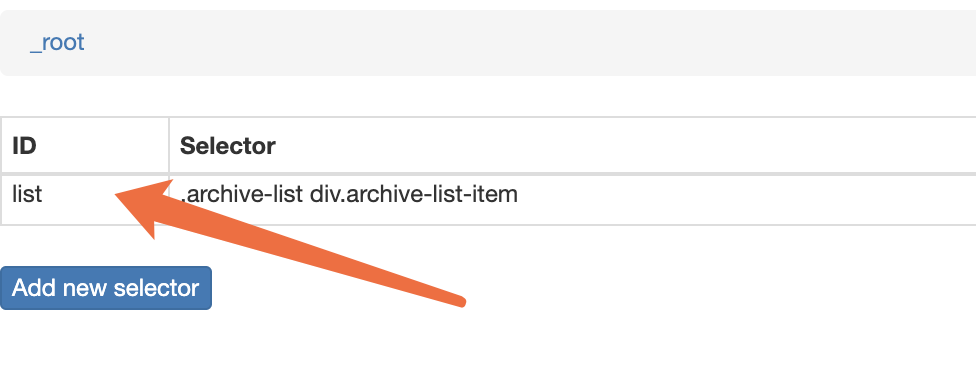 点击id,进行下一步选定爬取元素。
点击id,进行下一步选定爬取元素。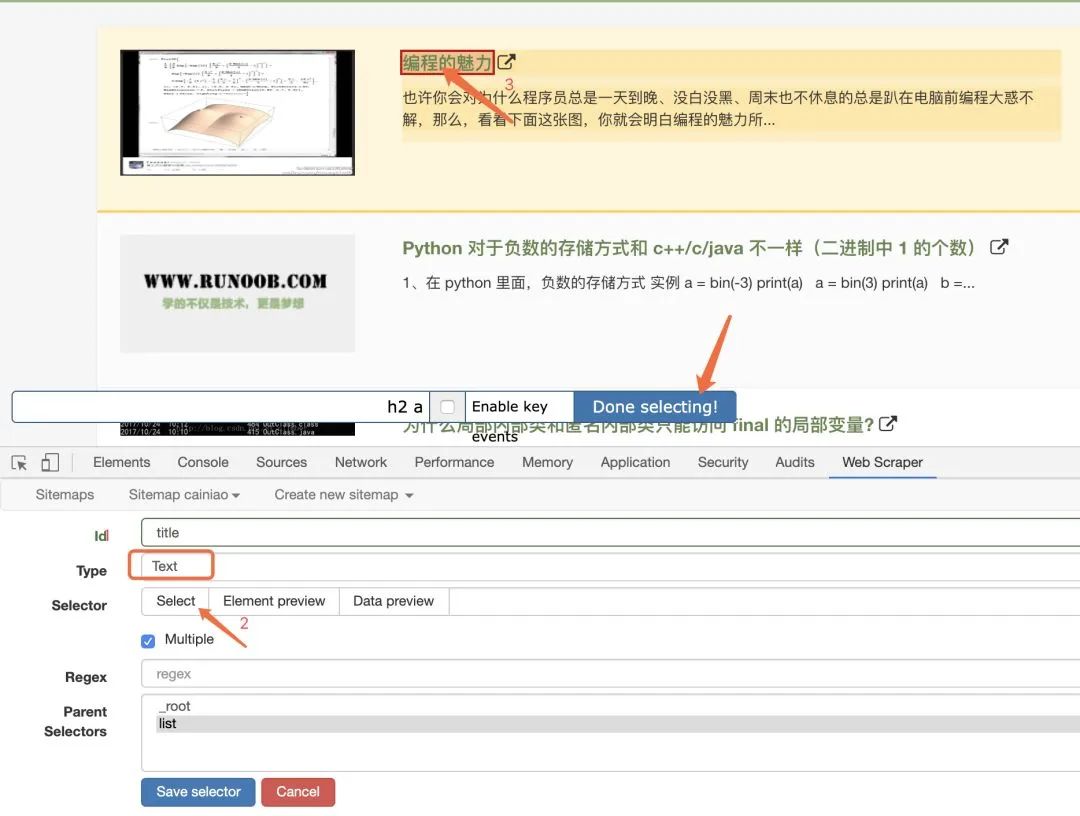
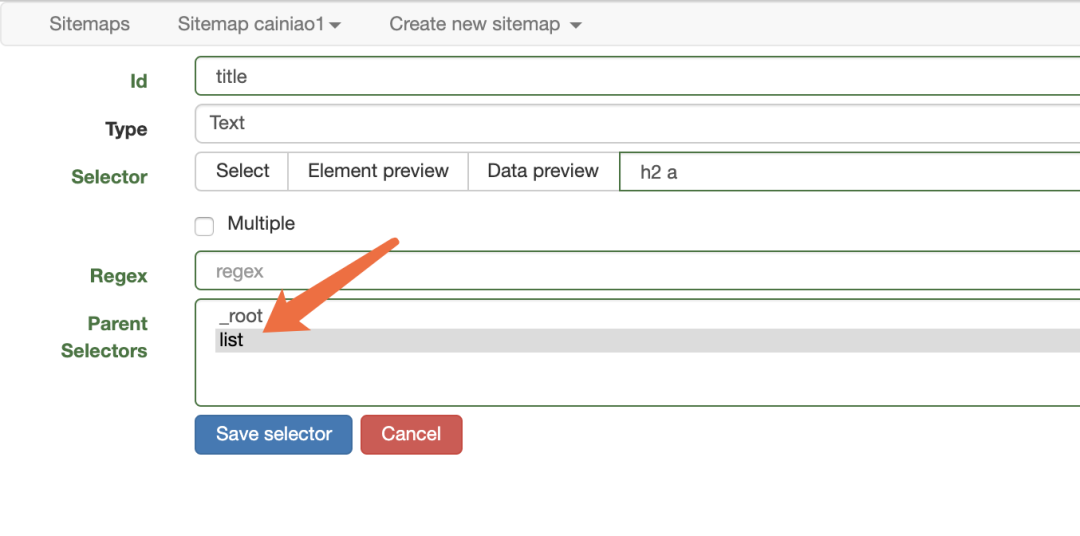 选定标题后,记得选择父节点,保存。完事之后,我们就可以愉快的运行了!
选定标题后,记得选择父节点,保存。完事之后,我们就可以愉快的运行了!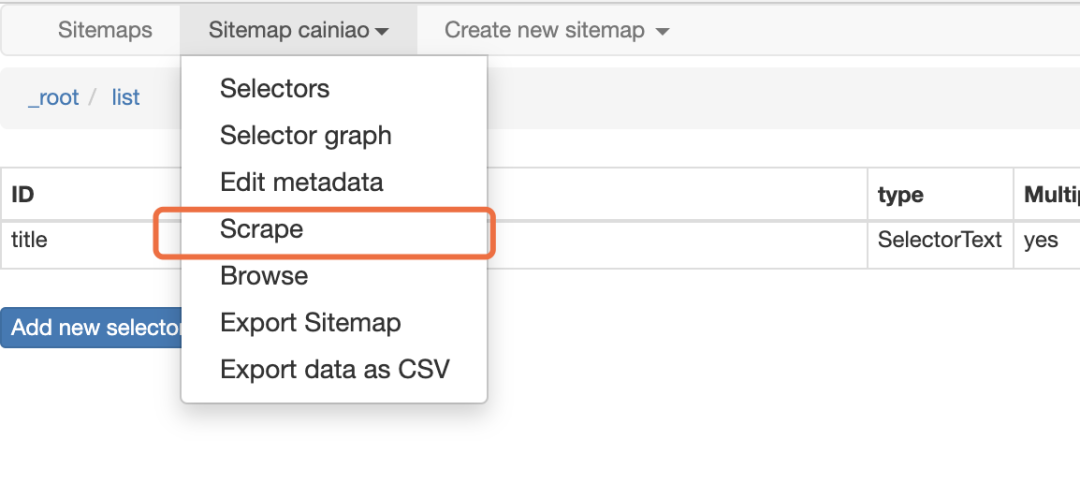 点击爬取。等待它自动爬取。
点击爬取。等待它自动爬取。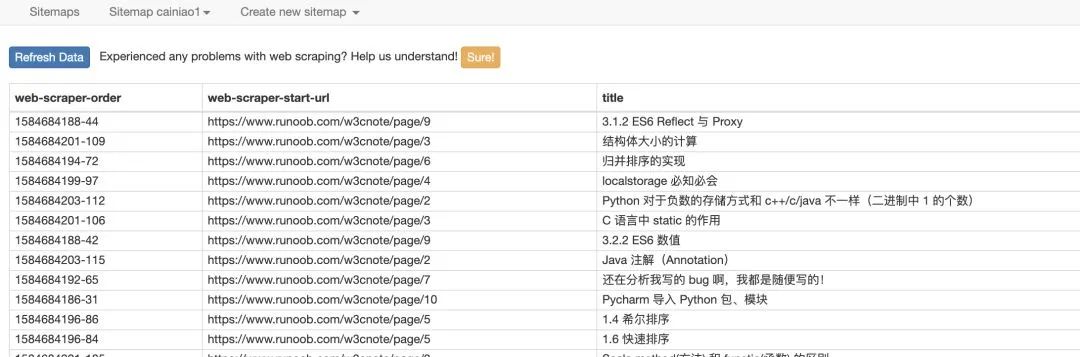 过一小会就可以看到数据了,
过一小会就可以看到数据了,数据支持导出!总结
这个插件对于一些简单的静态爬虫还是处理的很不错的。不用写一行代码,可以节省我们的时间,直接点几下鼠标就能写个简单的爬虫,所以推荐给大家。获取方式
① 可以去谷歌拓展程序商城下载② 我也给大家打包好了,直接在公众号后台发送爬虫即可领取。推荐阅读
1
2
如何用 GitHub Actions 写出高质量的 Python代码?
3
4
评论