
【秋招求职之路】「阿里智能事业群-达摩院」秋招面试复盘总结【文...
往期精彩文章推荐
阿里智能事业群-达摩院-机器智能技术部
一面
自我介绍
聊实习经历
主要工作内容,比如申请前端小组组长,与项目负责人沟通,完成模块发布工具前端框架。每日完成工作进度汇报,前端工作主要是表格页面渲染,比如树形表格,分组表格结合等,实现基本的增删改查功能...
项目中有用到SSR,说说对SSR的理解,目前为什么要用SSR?
页面的渲染流程
- 浏览器通过请求得到一个HTML文本
- 渲染进程解析HTML文本,构建DOM树
- 解析HTML的同时,如果遇到内联样式或者样式脚本,则下载并构建样式规则(stytle rules),若遇到JavaScript脚本,则会下载执行脚本。
- DOM树和样式规则构建完成之后,渲染进程将两者合并成渲染树(render tree)
- 渲染进程开始对渲染树进行布局,生成布局树(layout tree)
- 渲染进程对布局树进行绘制,生成绘制记录
- 渲染进程的对布局树进行分层,分别栅格化每一层,并得到合成帧
- 渲染进程将合成帧信息发送给GPU进程显示到页面中
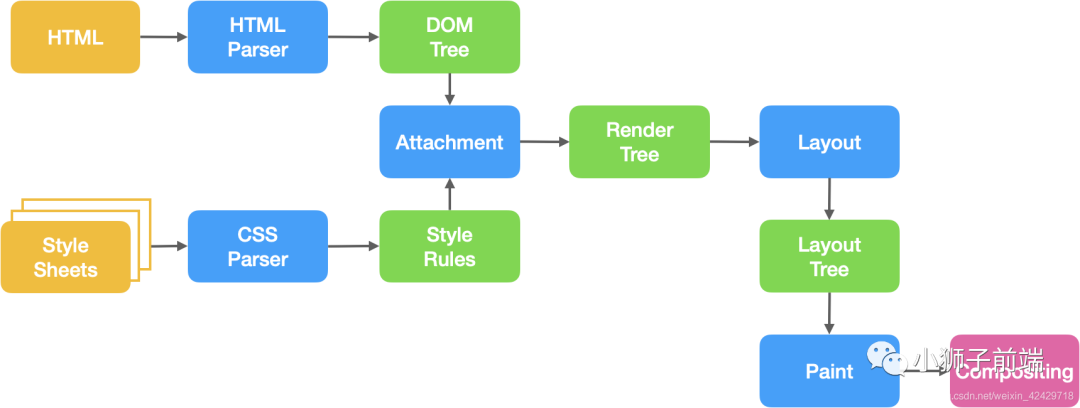
可以看到,页面的渲染其实就是「浏览器将HTML文本转化为页面帧」的过程。而如今我们大部分WEB应用都是使用 JavaScript 框架(Vue、React、Angular)进行页面渲染的,也就是说,在执行 JavaScript 脚本的时候,「HTML页面已经开始解析并且构建DOM树」了,JavaScript 脚本只是动态的改变 DOM 树的结构,使得页面成为希望成为的样子,这种渲染方式叫动态渲染,也可以叫客户端渲染(client side rende)。
那么什么是服务端渲染(server side render)?顾名思义,服务端渲染就是在浏览器请求页面URL的时候,服务端「将我们需要的HTML文本组装好」,并返回给浏览器,这个HTML文本被浏览器解析之后,「不需要经过 JavaScript 脚本」的执行,即可直接构建出希望的 DOM 树并展示到页面中。这个服务端组装HTML的过程,叫做服务端渲染。
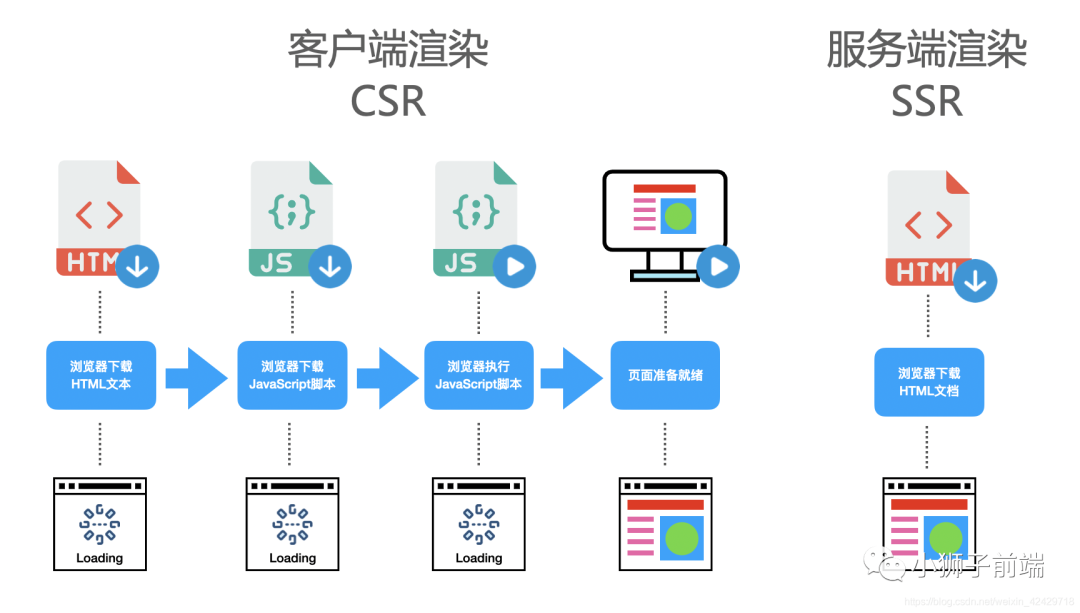
服务端渲染的由来
「Web1.0」
在没有AJAX的时候,也就是web1.0时代,几乎所有应用都是服务端渲染(此时服务器渲染非现在的服务器渲染),那个时候的页面渲染大概是这样的,浏览器请求页面URL,然后服务器接收到请求之后,到数据库查询数据,将「数据丢到后端的组件模板(php、asp、jsp等)中,并渲染成HTML片段」,接着服务器在组装这些HTML片段,组成一个完整的HTML,最后返回给浏览器,这个时候,浏览器已经拿到了一个完整的被服务器动态组装出来的HTML文本,然后将HTML渲染到页面中,过程没有任何JavaScript代码的参与。
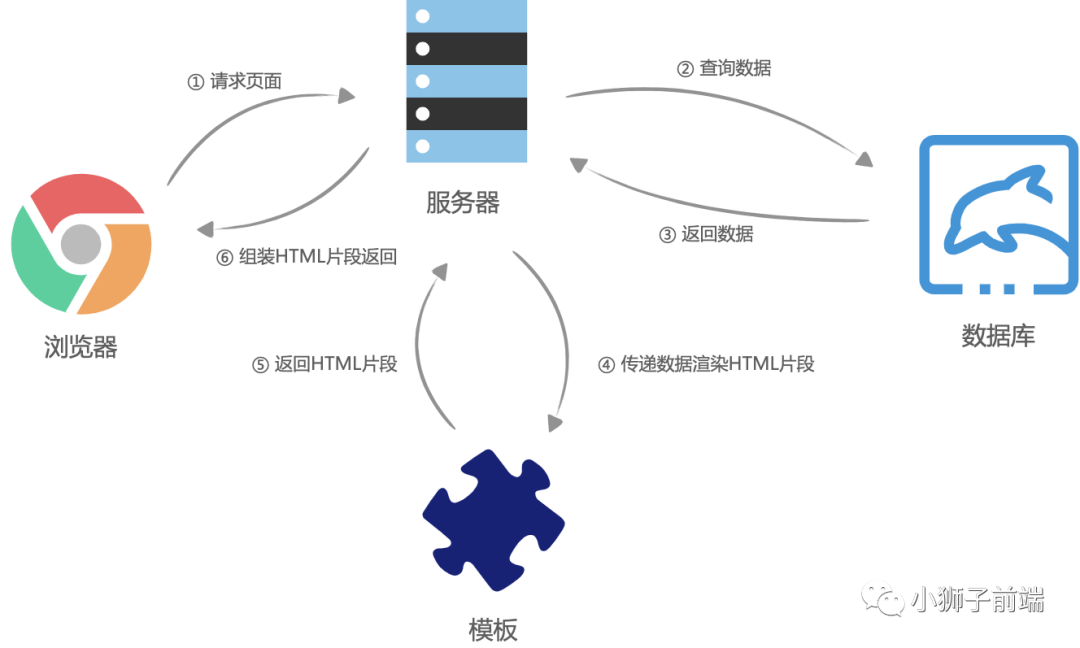 「客户端渲染」
「客户端渲染」
在WEB1.0时代,服务端渲染看起来是一个当时的最好的渲染方式,但是随着业务的日益复杂和后续AJAX的出现,也渐渐开始暴露出了WEB1.0服务器渲染的缺点。
- 每次更新页面的一小的模块,都需要重新请求一次页面,重新查一次数据库,重新组装一次HTML
- 前端JavaScript代码和后端(jsp、php、jsp)代码混杂在一起,使得日益复杂的WEB应用难以维护
而且那个时候,根本就没有前端工程师这一职位,前端js的活一般都由后端同学 jQuery 一把梭。但是随着前端页面渐渐地复杂了之后,后端开始发现js好麻烦,虽然很简单,但是坑太多了,于是让公司招聘了一些专门写js的人,也就是前端,这个时候,前后端的鄙视链就出现了,后端鄙视前端,因为后端觉得js太简单,无非就是写写页面的特效(JS),切切图(CSS),根本算不上是真正的程序员。
随之 nodejs 的出现,前端看到了翻身的契机,为了摆脱后端的指指点点,前端开启了一场前后端分离的运动,希望可以脱离后端独立发展。前后端分离,表面上看上去是代码分离,实际上是为了前后端人员分离,也就是前后端分家,前端不再归属于后端团队。
前后端分离之后,网页开始被当成了独立的应用程序(SPA,Single Page Application),前端团队接管了所有页面渲染的事,后端团队只负责提供所有数据查询与处理的API,大体流程是这样的:首先浏览器请求URL,前端服务器直接返回一个空的静态HTML文件(不需要任何查数据库和模板组装),这个HTML文件中加载了很多渲染页面需要的 JavaScript 脚本和 CSS 样式表,浏览器拿到 HTML 文件后开始加载脚本和样式表,并且执行脚本,这个时候脚本请求后端服务提供的API,获取数据,获取完成后将数据通过JavaScript脚本动态的将数据渲染到页面中,完成页面显示。
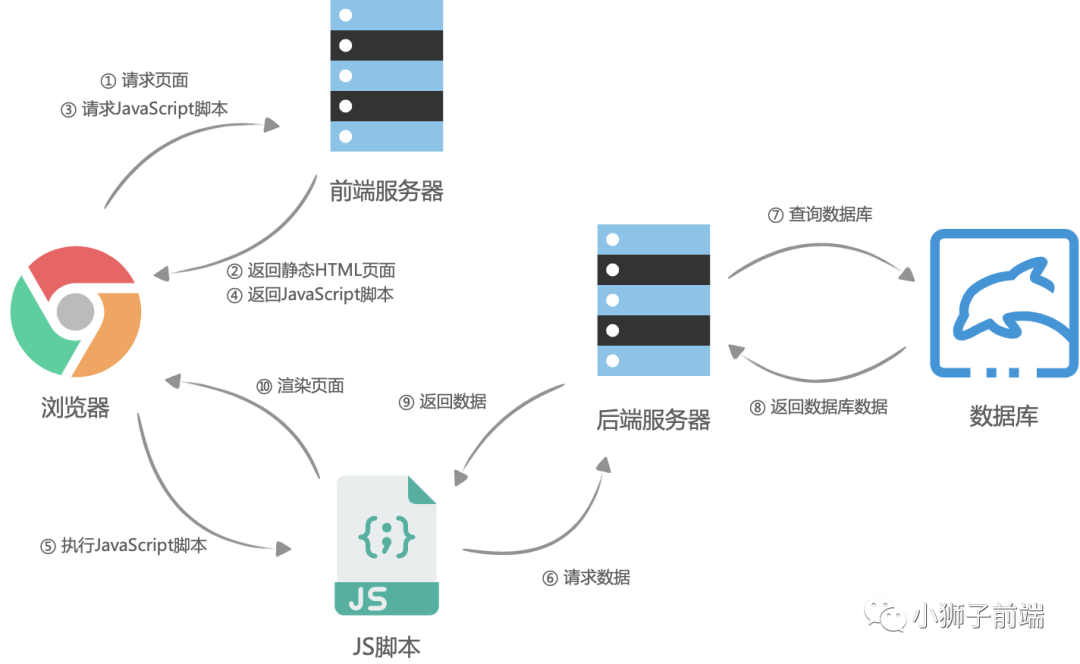 这一个前后端分离的渲染模式,也就是
这一个前后端分离的渲染模式,也就是客户端渲染(CSR)。
「服务端渲染」
随着单页应用(SPA)的发展,程序员们渐渐发现SEO(Search Engine Optimazition,即搜索引擎优化)出了问题,而且随着应用的复杂化,JavaScript 脚本也不断的臃肿起来,使得「首屏渲染」相比于 Web1.0时候的服务端渲染,也慢了不少。
自己选的路,跪着也要走下去。于是前端团队选择了使用 nodejs 在服务器进行页面的渲染,进而再次出现了服务端渲染。大体流程与客户端渲染有些相似,首先是浏览器请求URL,前端服务器接收到URL请求之后,根据不同的URL,前端服务器向后端服务器请求数据,请求完成后,前端服务器会组装一个携带了具体数据的HTML文本,并且返回给浏览器,浏览器得到HTML之后开始渲染页面,同时,「浏览器加载并执行 JavaScript 脚本,给页面上的元素绑定事件,让页面变得可交互」,当用户与浏览器页面进行交互,如跳转到下一个页面时,浏览器会执行 JavaScript 脚本,向后端服务器请求数据,获取完数据之后再次执行 JavaScript 代码动态渲染页面。
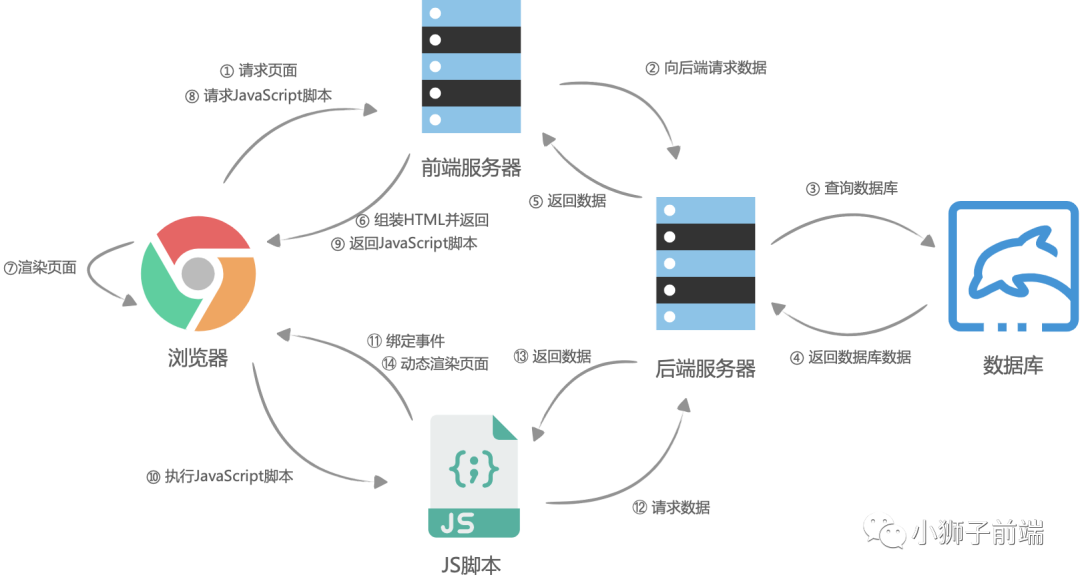 参考:【万字长文警告】从头到尾彻底理解服务端渲染SSR原理
参考:【万字长文警告】从头到尾彻底理解服务端渲染SSR原理
参考:为什么现在又流行服务端渲染html?
Vue.js 服务器端渲染指南
服务端渲染的利弊
「利于SEO」
有利于SEO,其实就是有利于爬虫来爬你的页面,然后在别人使用搜索引擎搜索相关的内容时,你的网页排行能靠得更前,这样你的流量就有越高。那为什么服务端渲染更利于爬虫爬你的页面呢?其实,爬虫也分低级爬虫和高级爬虫。
- 低级爬虫:只请求URL,URL返回的HTML是什么内容就爬什么内容。
- 高级爬虫:请求URL,加载并执行JavaScript脚本渲染页面,「爬JavaScript渲染后的内容」。
也就是说,低级爬虫对客户端渲染的页面来说,简直无能为力,因为返回的HTML是一个空壳,它需要执行 JavaScript 脚本之后才会渲染真正的页面。而目前像百度、谷歌、微软等公司,有一部分年代老旧的爬虫还属于低级爬虫,使用服务端渲染,对这些低级爬虫更加友好一些。
「白屏时间更短」
相对于客户端渲染,服务端渲染在浏览器请求URL之后已经得到了一个带有数据的HTML文本,浏览器只需要解析HTML,直接构建DOM树就可以。而客户端渲染,需要先得到一个空的HTML页面,这个时候页面已经进入白屏,之后还需要经过加载并执行 JavaScript、请求后端服务器获取数据、JavaScript 渲染页面几个过程才可以看到最后的页面。特别是在复杂应用中,由于需要加载 JavaScript 脚本,「越是复杂的应用,需要加载的 JavaScript 脚本就越多、越大,这会导致应用的首屏加载时间非常长,进而降低了体验感。」
服务端渲染缺点
并不是所有的WEB应用都必须使用SSR,这需要开发者自己来权衡,因为服务端渲染会带来以下问题:
- 「代码复杂度增加」。为了实现服务端渲染,应用代码中需要兼容服务端和客户端两种运行情况,而一部分依赖的外部扩展库却只能在客户端运行,需要对其进行特殊处理,才能在服务器渲染应用程序中运行。
- 「需要更多的服务器负载均衡」。由于服务器增加了渲染HTML的需求,使得原本只需要输出静态资源文件的nodejs服务,新增了数据获取的IO和渲染HTML的CPU占用,如果流量突然暴增,有可能导致服务器down机,因此需要使用响应的缓存策略和准备相应的服务器负载。
- 涉「及构建设置和部署的更多要求」。与可以部署在任何静态文件服务器上的完全静态单页面应用程序 (SPA) 不同,服务器渲染应用程序,需要处于 Node.js server 运行环境。
所以在使用服务端渲染SSR之前,需要开发者考虑投入产出比,比如大部分应用系统都不需要SEO,而且首屏时间并没有非常的慢,如果使用SSR反而小题大做了。
同构
在服务端渲染中,有两种页面渲染的方式:
- 前端服务器通过请求后端服务器获取数据并组装HTML返回给浏览器,浏览器直接解析HTML后渲染页面
- 浏览器在交互过程中,请求新的数据并动态更新渲染页面
这两种渲染方式有一个不同点就是,一个是在服务端中组装html的,一个是在客户端中组装html的,运行环境是不一样的。所谓「同构」,就是让一份代码,「既可以在服务端中执行,也可以在客户端中执行,并且执行的效果都是一样的」,都是完成这个html的组装,正确的显示页面。也就是说,一份代码,既可以客户端渲染,也可以服务端渲染。
「同构的条件」
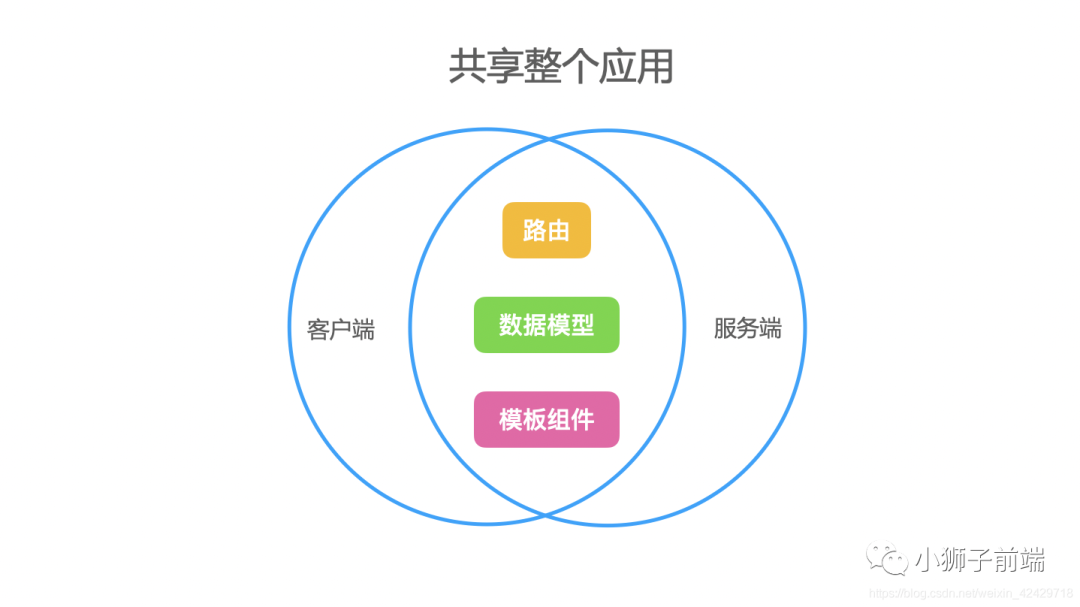
为了实现同构,我们需要满足什么条件呢?
首先,我们思考一个应用中一个页面的组成,假如我们使用的是Vue.js,当我们打开一个页面时,首先是打开这个页面的URL,这个URL,可以通过应用的路由匹配,找到具体的页面,不同的页面有不同的视图,那么,视图是什么?从应用的角度来看,「视图 = 模板 + 数据」,那么在 Vue.js 中, 模板可以理解成组件,数据可以理解为数据模型,即响应式数据。所以,对于同构应用来说,我们「必须实现客户端与服务端的路由、模型组件、数据模型的共享」。
总结
「浏览器渲染」
单页应用用的基本都是浏览器渲染。优点很明确,后端只提供数据,前端做视图和交互逻辑,「分工明确」。服务器只提供接口,路由以及渲染都丢给前端,服务器计算压力变轻了。但是弱点就是「用户等待时间变长」了,尤其在请求数多而且有一定先后顺序的时候。
客户端渲染路线:1. 请求一个html -> 2. 服务端返回一个html -> 3. 浏览器下载html里面的js/css文件 -> 4. 等待js文件下载完成 -> 5. 等待js加载并初始化完成 -> 6. js代码终于可以运行,由js代码向后端请求数据( ajax/fetch ) -> 7. 等待后端数据返回 -> 8. 客户端从无到完整地,把数据渲染为响应页面
「服务器渲染」
服务器接到用户请求之后,计算出用户需要的数据,然后将数据更新成视图(也就是一串dom字符)发给客户端,客户端直接将这串字符塞进页面即可。这样做的好处是「响应很快,用户体验会比较好」,另外对于搜索引擎来说也是友好的,「有SEO优化」。nodejs层的服务器渲染,还有一个明显的好处就是「前端性能优化更顺手了,可操作的空间大」了。但是缺点也很明显,如果不是增加一个node层的话,前后端责任分工不明,不能很好的并行开发。另外也增加了服务器计算压力(虽然可以做渲染缓存,但毕竟是多做了计算)。
服务端渲染路线:2. 请求一个html -> 2. 服务端请求数据( 内网请求快 ) -> 3. 服务器初始渲染(服务端性能好,较快) -> 4. 服务端返回已经有正确内容的页面 -> 5. 客户端请求js/css文件 -> 6. 等待js文件下载完成 -> 7. 等待js加载并初始化完成 -> 8. 客户端把剩下一部分渲染完成( 内容小,渲染快 )
对CDN的理解
github 里面有做cdn仓库,于是扯到了cdn,之后挂钩上http缓存,浏览器缓存相关,回源那一块。
说一个最近刷的印象比较深刻的 leetcode 题目,讲讲思路
leetcode 200 岛屿问题 讲了怎么dfs 沉岛
大学里面学的一些课程哪门最熟悉?
算法、数据结构、计算机网络、操作系统
选了计算机网络,毕竟是班主任教的(orz)
说说五层、七层 计算机网络模型
参考:详解 四层、五层、七层 计算机网络模型
举例传输层和应用层
传输层:TCP / UDP
应用层:HTTP / HTTPS 、FTP、SMTP等
HTTP1.0 和 HTTP2.0区别有了解吗?
简要概括一下 HTTP 的特点?HTTP 有哪些缺点?
「HTTP 特点」
灵活可扩展
主要体现在两个方面。一个是语义上的自由,只规定了基本格式,比如空格分隔单词,换行分隔字段,其他的各个部分都没有严格的语法限制。另一个是传输形式的多样性,不仅仅可以传输文本,还能传输图片、视频等任意数据,非常方便。可靠传输
HTTP 基于 TCP/IP,因此把这一特性继承了下来。请求-应答
也就是一发一收、有来有回, 当然这个请求方和应答方不单单指客户端和服务器之间,如果某台服务器作为代理来连接后端的服务端,那么这台服务器也会扮演请求方的角色。无状态
这里的状态是指「通信过程的上下文信息」,而每次 http 请求都是独立、无关的,默认不需要保留状态信息。
「HTTP 缺点」
- 无状态
所谓的优点和缺点还是要分场景来看的,对于 HTTP 而言,最具争议的地方在于它的「无状态」。
在「需要长连接」的场景中,需要保存大量的上下文信息,以免传输大量重复的信息,那么这时候无状态就是 http 的缺点了。
但与此同时,另外一些应用仅仅只是为了获取一些数据,不需要保存连接上下文信息,无状态反而减少了网络开销,成为了 http 的优点。
- 明文传输
即协议里的报文(主要指的是「头部」)不使用二进制数据,而是「文本形式」。这当然对于调试提供了便利,但同时也让 HTTP 的报文信息暴露给了外界,给攻击者也提供了便利。WIFI陷阱就是利用 HTTP 明文传输的缺点,诱导你连上热点,然后疯狂抓你所有的流量,从而拿到你的敏感信息。
- 队头阻塞问题
当 http 开启长连接时,共用一个 TCP 连接,同一时刻只能处理一个请求,那么当前请求耗时过长的情况下,其它的请求只能处于阻塞状态,也就是著名的「队头阻塞」问题。
参考:三元大佬(建议精读)HTTP灵魂之问,巩固你的 HTTP 知识体系
HTTP1.1 如何解决 HTTP 的队头阻塞问题?
「什么是 HTTP 队头阻塞?」
HTTP 传输是基于请求-应答的模式进行的,报文必须是一发一收,但值得注意的是,里面的任务被放在一个任务队列中串行执行,一旦队首的请求处理太慢,就会阻塞后面请求的处理。这就是著名的HTTP队头阻塞问题。
- 并发连接
对于一个域名允许分配多个长连接,那么相当于增加了任务队列,不至于一个队伍的任务阻塞其它所有任务。在RFC2616规定过客户端最多并发 2 个连接,不过事实上在现在的浏览器标准中,这个上限要多很多,「Chrome 中是 6 个」。
但其实,即使是提高了并发连接,还是不能满足人们对性能的需求。
- 域名分片
一个域名不是可以并发 6 个长连接吗?那我就多分几个域名。
比如 content1.sanyuan.com 、content2.sanyuan.com。
这样一个sanyuan.com域名下可以分出非常多的二级域名,而它们都指向同样的一台服务器,能够并发的长连接数更多了,事实上也更好地解决了队头阻塞的问题。
HTTP/2 有哪些改进?
由于 HTTPS 在安全方面已经做的非常好了,HTTP 改进的关注点放在了性能方面。对于 HTTP/2 而言,它对于性能的提升主要在于两点:
- 头部压缩
- 多路复用
当然还有一些颠覆性的功能实现:
- 设置请求优先级
- 服务器推送
这些重大的提升本质上也是为了解决 HTTP 本身的问题而产生的。接下来我们来看看 HTTP/2 解决了哪些问题,以及解决方式具体是如何的。
「头部压缩」
在 HTTP/1.1 及之前的时代,「请求体」一般会有响应的压缩编码过程,通过Content-Encoding头部字段来指定,但你有没有想过头部字段本身的压缩呢?当请求字段非常复杂的时候,尤其对于 GET 请求,请求报文几乎全是请求头,这个时候还是存在非常大的优化空间的。HTTP/2 针对头部字段,也采用了对应的压缩算法——HPACK,对请求头进行压缩。
HPACK 算法是专门为 HTTP/2 服务的,它主要的亮点有两个:
- 首先是在服务器和客户端之间建立哈希表,将用到的字段存放在这张表中,那么在传输的时候对于之前出现过的值,只需要把「索引」(比如0,1,2,...)传给对方即可,对方拿到索引查表就行了。这种「传索引」的方式,可以说让请求头字段得到极大程度的精简和复用。
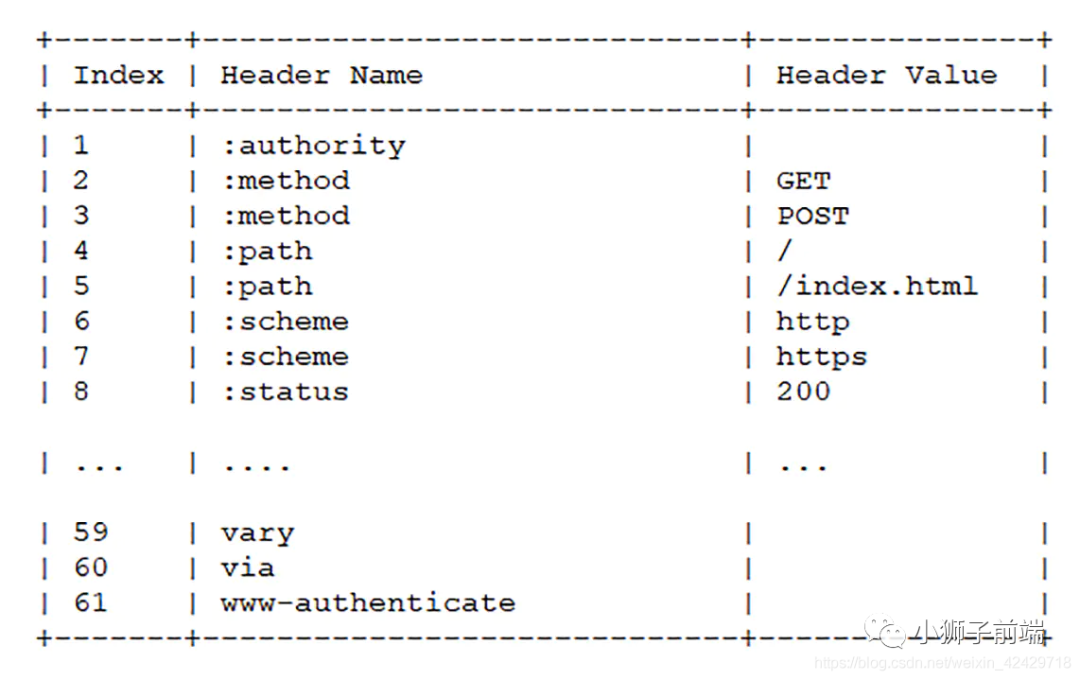
HTTP/2 当中废除了起始行的概念,将起始行中的请求方法、URI、状态码转换成了头字段,不过这些字段都有一个":"前缀,用来和其它请求头区分开。
- 其次是对于整数和字符串进行「哈夫曼编码」,哈夫曼编码的原理就是先将所有出现的字符建立一张索引表,然后让出现次数多的字符对应的索引尽可能短,传输的时候也是传输这样的「索引序列」,可以达到非常高的压缩率。
「多路复用」
我们之前讨论了 HTTP 队头阻塞的问题,其根本原因在于HTTP 基于请求-响应的模型,在同一个 TCP 长连接中,前面的请求没有得到响应,后面的请求就会被阻塞。
后面我们又讨论到用「并发连接」和「域名分片」的方式来解决这个问题,但这并没有真正从 HTTP 本身的层面解决问题,只是增加了 TCP 连接,分摊风险而已。而且这么做也有弊端,多条 TCP 连接会竞争「有限的带宽」,让真正优先级高的请求不能优先处理。
而 HTTP/2 便从 HTTP 协议本身解决了队头阻塞问题。注意,这里并不是指的TCP队头阻塞,而是HTTP队头阻塞,两者并不是一回事。TCP 的队头阻塞是在数据包层面,单位是数据包,前一个报文没有收到便不会将后面收到的报文上传给 HTTP,而HTTP 的队头阻塞是在 HTTP 请求-响应层面,前一个请求没处理完,后面的请求就要阻塞住。两者所在的层次不一样。
那么 HTTP/2 如何来解决所谓的队头阻塞呢?
「二进制分帧」
首先,HTTP/2 认为「明文传输对机器而言太麻烦」了,不方便计算机的解析,因为对于文本而言会有多义性的字符,比如回车换行到底是内容还是分隔符,在内部需要用到状态机去识别,效率比较低。于是 HTTP/2 干脆把报文全部换成二进制格式,全部传输01串,方便了机器的解析。
原来Headers + Body的报文格式如今被拆分成了一个个二进制的帧,用「Headers帧」存放头部字段,「Data帧」存放请求体数据。分帧之后,服务器看到的不再是一个个完整的 HTTP 请求报文,而是一堆「乱序的二进制帧」。这些二进制帧不存在先后关系,因此也就不会排队等待,也就没有了 HTTP 的队头阻塞问题。
通信双方都可以给对方发送二进制帧,这种二进制帧的「双向传输的序列」,也叫做流(Stream)。HTTP/2 用流来在「一个 TCP 连接上来进行多个数据帧的通信」,这就是多路复用的概念。
可能你会有一个疑问,既然是乱序首发,那最后如何来处理这些乱序的数据帧呢?
首先要声明的是,所谓的乱序,指的是不同 ID 的 Stream 是乱序的,但同一个 Stream ID 的帧一定是按顺序传输的。二进制帧到达后对方会将 Stream ID 相同的二进制帧组装成完整的请求报文和响应报文。当然,在二进制帧当中还有其他的一些字段,实现了优先级和流量控制等功能,我们放到下一节再来介绍。
「服务器推送」
另外值得一说的是 HTTP/2 的服务器推送(Server Push)。在 HTTP/2 当中,服务器已经不再是完全被动地接收请求,响应请求,它「也能新建 stream 来给客户端发送消息」,当 TCP 连接建立之后,比如浏览器请求一个 HTML 文件,服务器就可以在返回 HTML 的基础上,将 HTML 中引用到的其他资源文件一起返回给客户端,减少客户端的等待。
「总结」
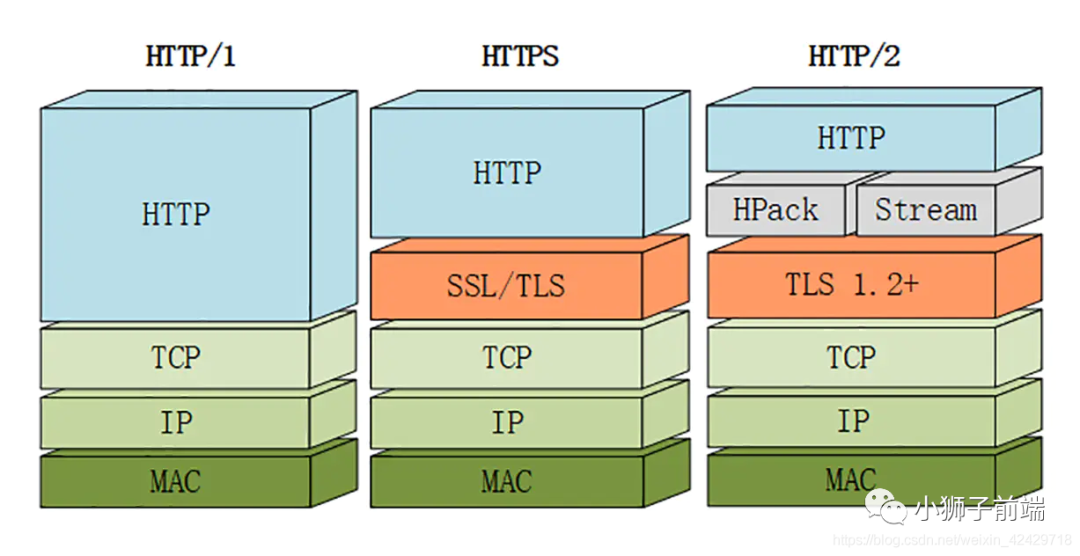
当然,HTTP/2 新增那么多的特性,是不是 HTTP 的语法要重新学呢?不需要,HTTP/2 完全兼容之前 HTTP 的语法和语义,如「请求头、URI、状态码、头部字段」都没有改变,完全不用担心。同时,在安全方面,HTTP 也支持 TLS,并且现在主流的浏览器都公开只支持加密的 HTTP/2, 因此你现在能看到的 HTTP/2 也基本上都是跑在TLS 上面的了。最后放一张分层图给大家参考:
HTTP/2 中的二进制帧是如何设计的?
「帧结构」
HTTP/2 中传输的帧结构如下图所示: 每个帧分为「帧头」和「帧体」。先是三个字节的帧长度,这个长度表示的是
每个帧分为「帧头」和「帧体」。先是三个字节的帧长度,这个长度表示的是帧体的长度。
然后是帧类型,大概可以分为「数据帧」和「控制帧」两种。数据帧用来存放 HTTP 报文,控制帧用来管理流的传输。
接下来的一个字节是「帧标志」,里面一共有 8 个标志位,常用的有 「END_HEADERS」表示头数据结束,「END_STREAM」表示单方向数据发送结束。
后 4 个字节是Stream ID, 也就是流标识符,有了它,接收方就能从乱序的二进制帧中选择出 ID 相同的帧,按顺序组装成请求/响应报文。
「流的状态变化」
从前面可以知道,在 HTTP/2 中,所谓的流,其实就是二进制帧的「双向传输的序列」。那么在 HTTP/2 请求和响应的过程中,流的状态是如何变化的呢?HTTP/2 其实也是借鉴了 TCP 状态变化的思想,根据帧的标志位来实现具体的状态改变。这里我们以一个普通的请求-响应过程为例来说明:
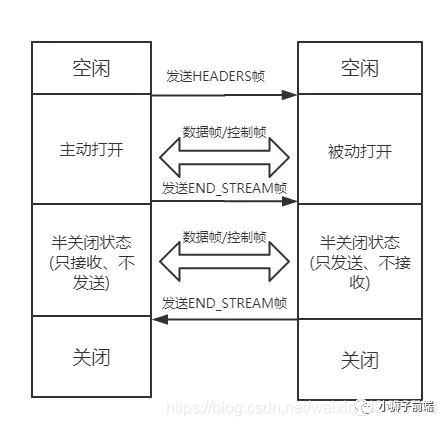 最开始两者都是空闲状态,当客户端发送
最开始两者都是空闲状态,当客户端发送Headers帧后,开始分配Stream ID, 此时「客户端的流打开」, 「服务端接收之后服务端的流也打开」,两端的流都打开之后,就可以互相传递数据帧和控制帧了。
当客户端要关闭时,向服务端发送END_STREAM帧,进入「半关闭状态」, 这个时候客户端只能接收数据,而不能发送数据。
服务端收到这个END_STREAM帧后也进入半关闭状态,不过此时服务端的情况是「只能发送数据,而不能接收数据」。随后服务端也向客户端发送END_STREAM帧,表示「数据发送完毕,双方进入关闭状态」。
如果下次要开启新的流,流 ID 需要自增,直到上限为止,到达上限后开一个新的 TCP 连接重头开始计数。由于流 ID 字段长度为 4 个字节,最高位又被保留,因此范围是 0 ~ 2的 31 次方,大约 21 亿个。
「流的特性」
刚刚谈到了流的状态变化过程,这里顺便就来总结一下流传输的特性:
- 并发性。一个 HTTP/2 连接上可以同时发多个帧,这一点和 HTTP/1 不同。这也是实现「多路复用」的基础。
- 自增性。流 ID 是不可重用的,而是会按顺序递增,达到上限之后又新开 TCP 连接从头开始。
- 双向性。客户端和服务端都可以创建流,互不干扰,双方都可以作为
发送方或者接收方。 - 可设置优先级。可以设置数据帧的优先级,让服务端先处理重要资源,优化用户体验。
自己搭的博客目的是什么?主要写的内容是?
爱折腾,搭建了一个美化版的博客,主要整合前端相关知识点
询问了大学里面图像处理课程
博客专栏里面有图像处理相关博文,问到了这个点
如何学习前端(或者说是如何学习计算机领域知识)
先学好本科基础知识,锻炼思维,然后经常逛一些博客网站,例如掘金,学习优秀的人是怎样学习的,看一些书籍,比如js红宝书。另外,常逛一些b站学习一些老师教授的课程。
对未来的职业规划
热爱前端,干到退休(苦笑)往架构方向发展,然后面试官提到了是否未来会参与算法、人工智能相关领域。我非常赞同,也提了nodejs目前比较火热,后续也会继续学习 koa、egg框架,总之,懂的越多,不懂得更多,一直学习~
有什么问题可以询问
了解部门主要业务工作,了解部门规模
结果
小狮子有话说感受:问题能想起来的暂时这么多,一面体验还是不错的,又增加了一些知识,还能和面试官交流一下大学学习课程,挺好的。但最后还是因为知识掌握程度与岗位匹配度,主要是岗位匹配度吧,达摩院大家懂得都懂...
我是小狮子团队的【一百个Chocolate】,全网同名,周更的前端博主,分享一些前端技术干货与程序员生活日常,欢迎各位小伙伴的持续关注,一起变优秀~
本次给大家带来一波小福利,关注公众号【小狮子前端】后台回复 0612 即可参与,现在参与人数也不多,中奖几率特别大!确定不来参与嘛?
学如逆水行舟,不进则退
点击【在看】红包福利就多一次~