
推荐工程系统架构演进
1. 前言
2. 到家推荐工程框架- V.1.0
2.1. 框架雏型
2.2. 存在问题
3. 到家推荐工程框架- V.2.0
4. 到家推荐工程框架- V.3.0
4.1. 配置服务端与客户端
4.2. ab判断能力
4.3. 召回服务
4.4. 预测服务
5. 展望
1、前言
推荐现在已经成为电商最核心的竞争力,也是电商平台的重要流量入口之一。近年来推荐场景逐渐的多样化,覆盖到各流量入口,几乎所有页面都可以进行商品推荐:首页、详情页、购物车页面、下单成功页、错误页等等。而不同的页面,推荐的侧重点也会不尽相同。
推荐系统的价值,对于用户来说,能大幅提升使用体验,使用户感到满足。轻松购买到自己的想要的商品。但对于企业来说,推荐系统不仅能解决长尾效应和马太效应,同时能够提升产品用户体验,增强用户黏性,更好的创造产品价值,进一步扩大产品盈利。
到家推荐系统随着业务的增长和算法能力的提升,目前经历了三个架构版本的演进:
V.1.0采用了一种简单的策略+工厂的设计思路,在推荐项目启动之初,满足了业务的快速迭代上线; V.2.0按照业务场景做了垂直拆分,按照推荐流程的固有阶段对系统进行水平分成,使系统更贴切业务,框架更为合理清晰 V.3.0按照到家业务对每个推荐阶段抽象整合,将推荐系统平台化,提高系统的扩散性、伸缩性、稳定性
2、到家推荐工程架构- V.1.0
2.1、框架雏型
到家商品系统创建之初,为了把推荐算法的能力通过api的方法提供给到家各个业务方使用,设计并且上线了推荐工程1.0系统。
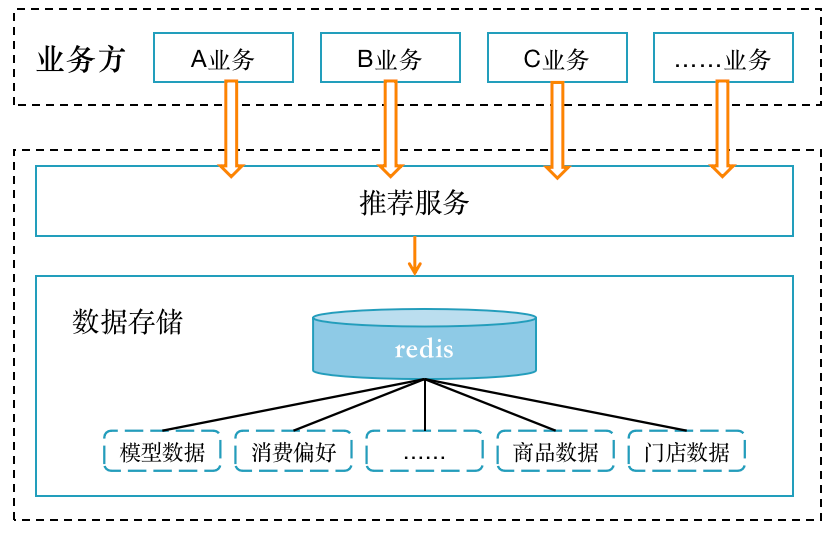
2.2、存在问题
在这个设计中,可对外快速输出推荐的服务,但也存在较大的风险:
1、一个推荐服务支持所有上游的业务,导致系统故障隔离性差。多业务逻辑在一个JVM中,系统资源分配困难。线程资源枯竭,异步化逻辑相互影响。系统的可伸缩性差,无法针对某个业务进行扩容,只能对整个应用扩容;
2、随着业务迅速发展,增加了系统的复杂性。如果继续使用简单的策略+工厂模式,将成为开发效率提升的阻碍,亟待解决。在经历了大量迭代,发现推荐存在鲜明的阶段性逻辑,按照推荐阶段进行抽象模块化,可以提升开发效率。
3、召回的瓶颈,召回采用直连的方式,在有限的时间内,单点从Redis获取数据是有限的,已经成为增加召回数据、提高性能的瓶颈。到家召回主要是基于商品,存在很高的相似度,是可以进一步抽象合并的,但通过直连Redis的方式,很难做到抽象合并。
4、推荐系统所有数据储存在一个Redis集群里,如果某一业务持续高并发请求,会导致其他业务受影响。虽然可以通过横向扩容分片来解决燃眉之急,但是随着数据量级的不断增长,Redis单集群的风险也越来越大。
3、到家推荐工程架构- V.2.0
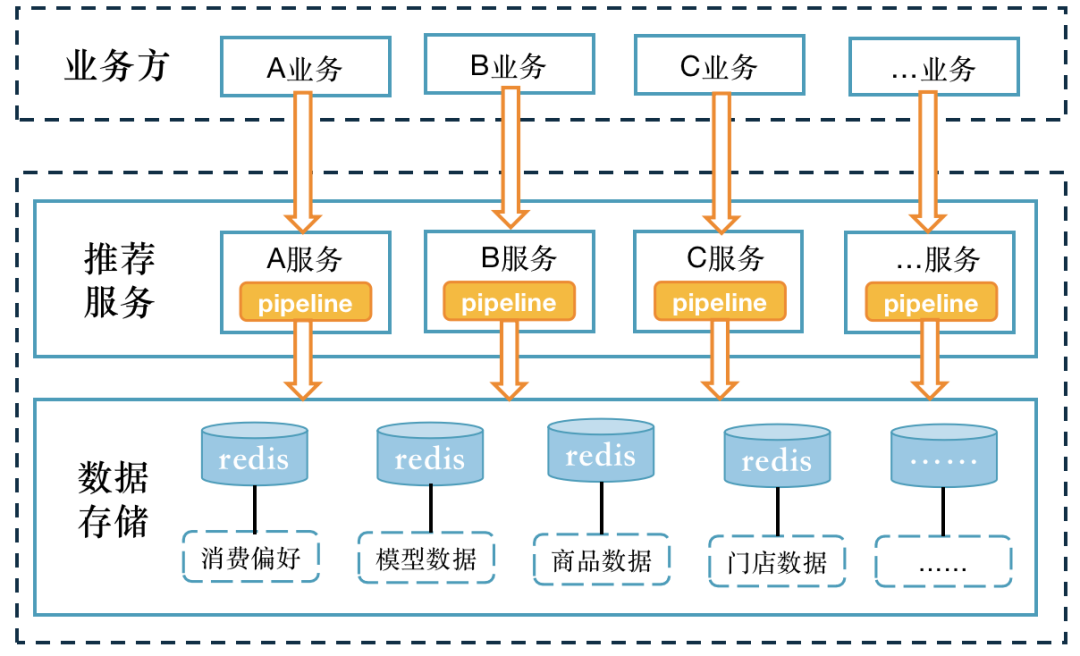
推荐接入的业务场景与日俱增,系统维护渐渐显露了框架1.0中的几大风险,首先做的第一个拆分方式,就是按业务做了垂直拆分逻辑,将应用1分为N,存储1分为N,做业务隔离。
按照业务场景,把聚合的服务拆分成N个推荐场景。基于不同的推荐场景对系统进行垂直拆分,使系统故障可以有效的隔离,避免一个接口的异常错影响到整个服务性能,甚至瘫痪。拆分后的应用服务可按需分配资源,资源利用最大化。
Redis是推荐系统的一个重要基石,会重度使用Redis存放核心的数据,保障redis高可用、高扩展、高性能是至关重要的。本次重构将一个大的Reids集群拆分成N个小集群,将不同的数据源均匀的分配到各个集群里,均摊了Redis集群宕机的风险,面对突发情况小集群更容易扩容。
第二个拆分是对工程框架,降低系统的复杂性,更好的面向推荐业务开发。拆分后的系统在代码上存在非常高的冗余,因推荐有阶段性先后逻辑。在解决这个问题上,我们采用了一种Pipeline流程调度的方案;将业务进行模块化分解,细化各阶段逻辑,比如:召回、过滤、粗排、合并、精排、干预、打散等。模块化后,针对某一个推荐模块,业务迭代会更加明确,代码耦合度更低。根据业务将不同的推荐模块配置到配置文件里,pipeline调度器通过配置文件,执行推荐流程,形成了2.0配置化推荐框架。
Pipeline流程调度设计,如图:
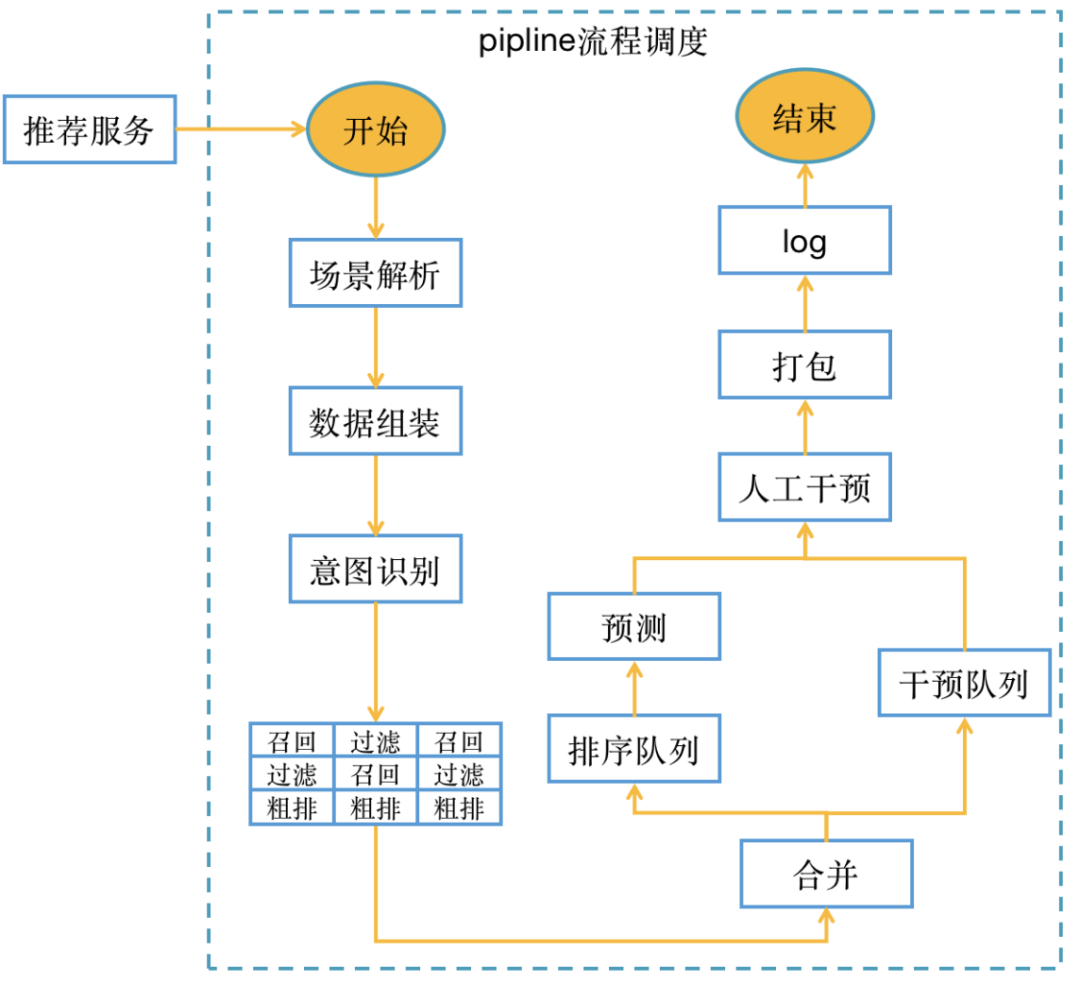
2.0版本的迭代,很好的解决了推荐在开发效率、系统稳定及系统性能瓶颈的问题。但是在推荐精细化运营中,慢慢也体现出了这套设计的不足,不能很好的做到业务精细化。实验的变更、局部特征值调整、或者想动态增加召回通路,都会有较大的产研测的投入,不适合推荐这样小步迭代,快速试错的场景。如何在推荐流程的关键阶段、容易变更节点,可根据业务诉求或算法迭代进行动态调整,减少开发成本和上线周期,成为我们下一个版本的演变萌芽。
4、到家推荐工程架构- V.3.0
在这个版本的研发中,主要演进方向是pipeline流程动态配置化,将推荐A、B、C业务场景中共性的部分独立,并能独立设置相关属性,做到业务之间代码共享且属性设置隔离。据此我们演变出了一个配置服务,该服务的主要职责是管理业务应用程序里的pipeline执行流程中的细节和实验信息。同时将计算密集型的模型预测、IO密集型的召回从应用程序里拆分出来,独立成两个服务,使应用程序中的资源集中在业务处理上。
3.0采用配置服务端与客户端,动态配置集中管理的方式,来实现配置化pipeline推荐流程。配置服务端可以动态修改推荐流程和执行属性。配置客户端部署在推荐应用服务器上,与服务端保持心跳,更新配置服务端的流程配置。当推荐应用服务器接收到用户请求,会交给配置客户端,客户端根据入参找到需要执行的推荐流程,动态生成执行过程,并且在执行过程中使用执行属性,依赖拆解出来的召回服务、预测服务,完成推荐业务流程。面对多样化的推荐场景,这个版本都会表现得游刃有余。
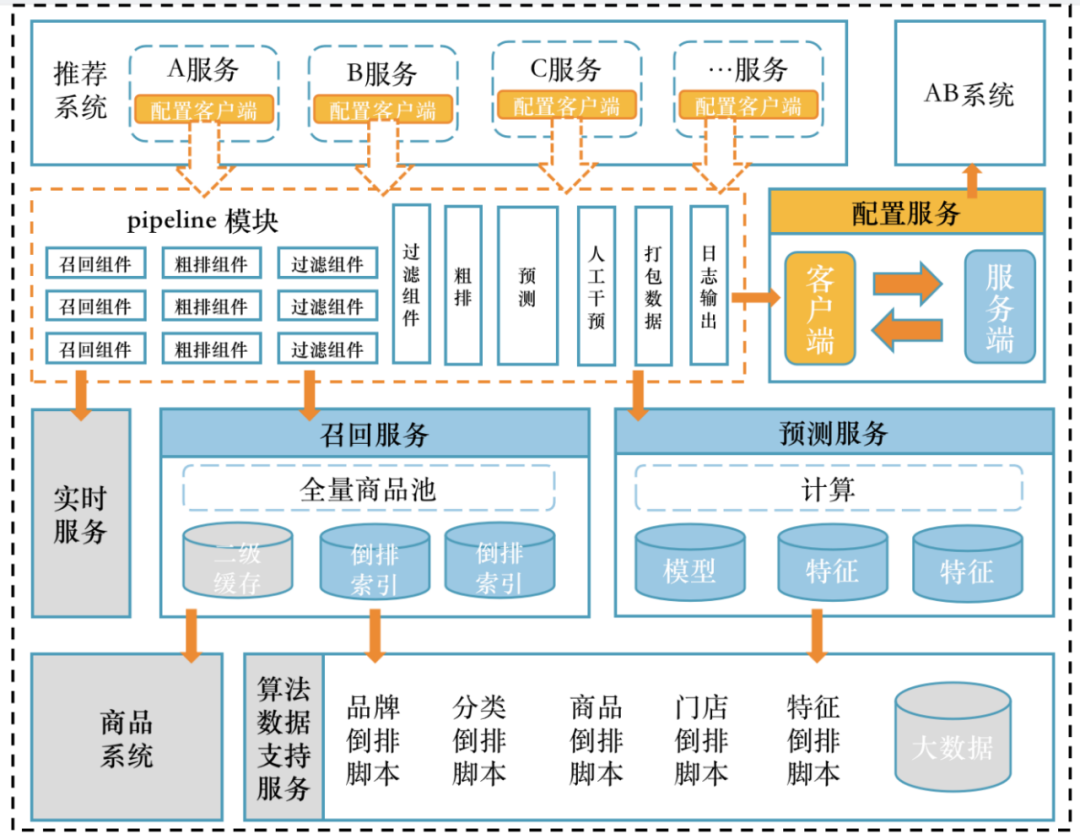
1、配置服务端与客户端
2、配置系统具备ab判断的能力
3、构建全量商品召回池
4、模型预测服务化
4.1、配置服务端与客户端
总体设计
推荐配置系统主要含两个端:服务端、客户端。服务端主要功能是配置推荐流程的各个节点。客户端主要功能是拉取服务端配置,在用户请求过程中生成推荐执行流程。具体交互方式见图
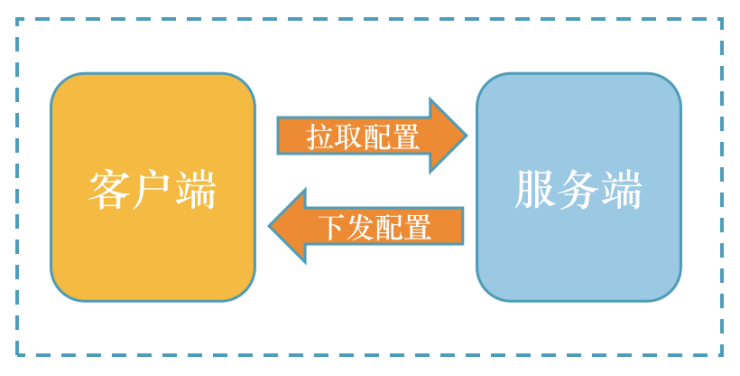
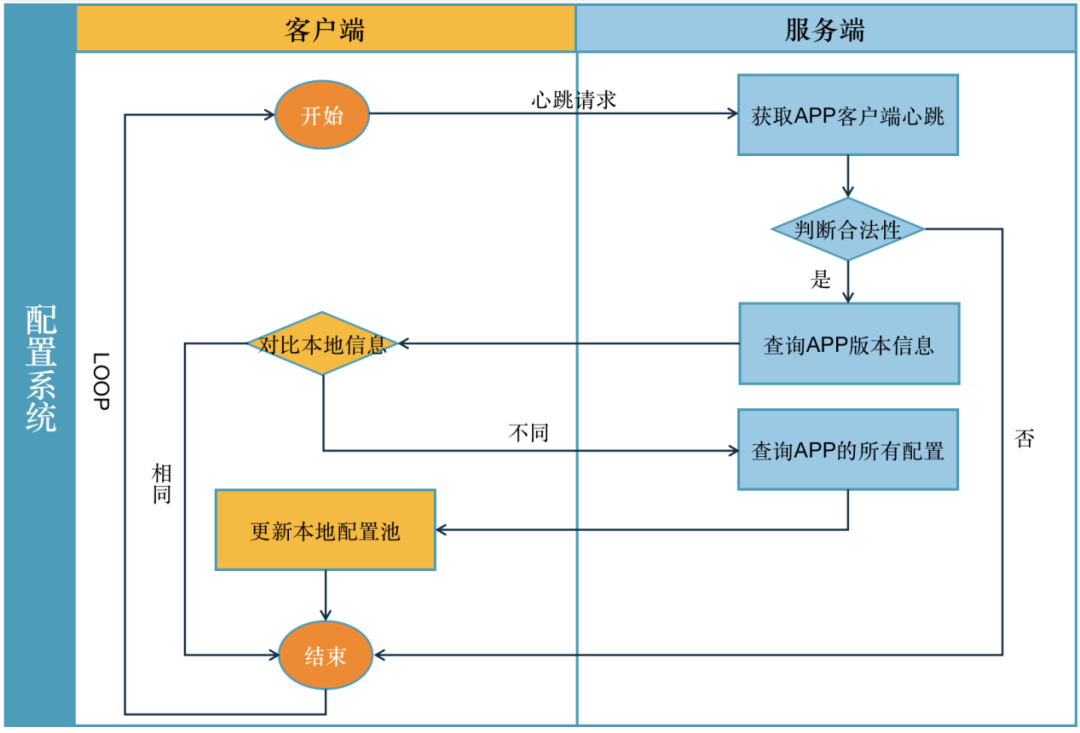
客户端定时轮询请求服务端上传心跳信息,并请求服务端APP应用的版本,服务端接收到请求之后,对比客户端请求合法性,返回相关版本数据。
客户端根据返回的版本信息对比本地的配置版本,相同等待下次心跳,不同发起拉取配置请求。
当服务端接收到客户端的配置请求时,查询当前服务的所有有效配置,组合相应的数据结构,返回给客户端。客户端根据返回的配置更新本地配置,等待用户请求服务,生成业务请求链条。
流程设计,如图
服务端
服务端基础架构如图主要含两大块:对外服务接口和配置管理。
设计,如图
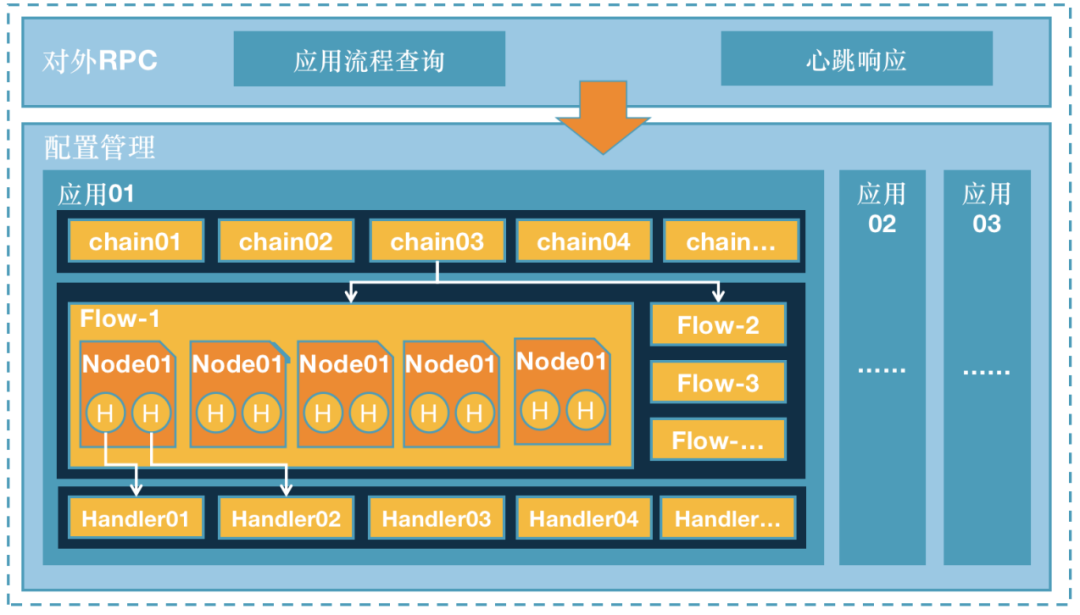
1、对外服务:
RPC对外服务接口的主要职责是:响应各应用机器的心跳信息及下发应用下的所有满足要求的配置:主要含心跳响应接口、应用流程查询接口。
2、配置管理:
统一管理到家所有推荐场景的配置,通过在线修改配置可以实时改变推荐策略。比如feed应用系统,包含了多个场景的feed流,每个feed流可配置属于自己的多版本推荐流程,根据业务可以动态切换。每个推荐流程又可以自由组合召回、粗排、精排、打散、干预等推荐模块。结合不同类型的推荐模块和到家业务特点,为模块提供固化的专属配置,方便在线进行业务调整和功能迭代。
客户端
客户端的设计思想源于对推荐实际业务流程的规范化,推荐的业务流程是固化的且是有规律的。客户端的流程会按推荐业务的规律化信息,从服务端拉取相关配置后存储在本地。等待用户请求相关业务后,会根据用户的常规属性(手机型号、经纬度等等)、基础属性、上下文特征、业务方需要的实验信息等,动态的组合一组handler执行单元,然后执行该组单元,完成业务的请求,返回相关业务数据。
客户端通过与服务端保持心跳,同步服务端最新的配置变更,并验证变更配置是否正确。如果正确在下一次用户请求时会被执行,如果错误则忽略这次变更。
客户端主要含有七大模块,其中底层模块两个:核心基础模块、基础扩展模块;业务模块5个:启动模块、服务配置模块、业务解析模块、单元组合模块、执行器模块。
设计,如图
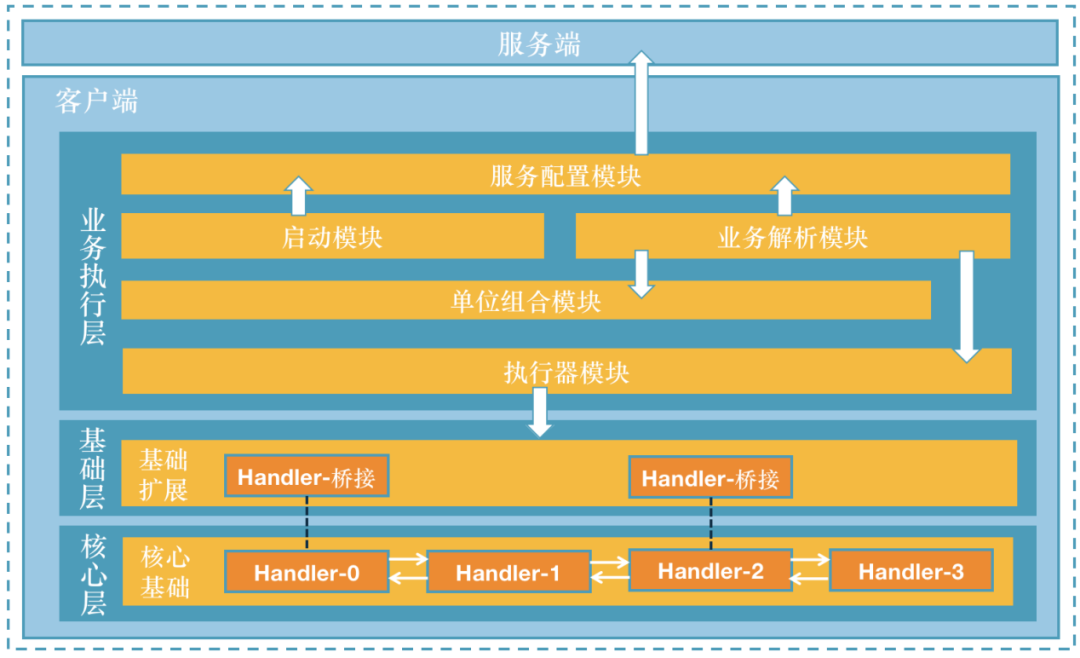
1、核心层
我们推荐的业务执行是一个阶段到下一个阶段的过程。比如:从召回->粗排->精排->打散->干预->打包,这个过程是很少会改变的,而且几乎每个业务流程都是如此。
核心基础模块是一个与业务无关的抽象,根据上面描述的特点。将整个执行逻辑形势抽象成了一个链表,将推荐的各个阶段抽象成了链表上的一个节点(Handler)。
2、基础层
因为核心基础模块是不支持在节点中执行多个业务的。但是我们的实际业务是需要这样的功能。比如召回节点,它是需要多路召回的,所以需要对节点进行这方面的扩展。
3、业务执行层
解析配置里的内容,将其组装成可执行的业务链,执行按照业务链顺序执行返回推荐结果。
4.2、ab判断能力
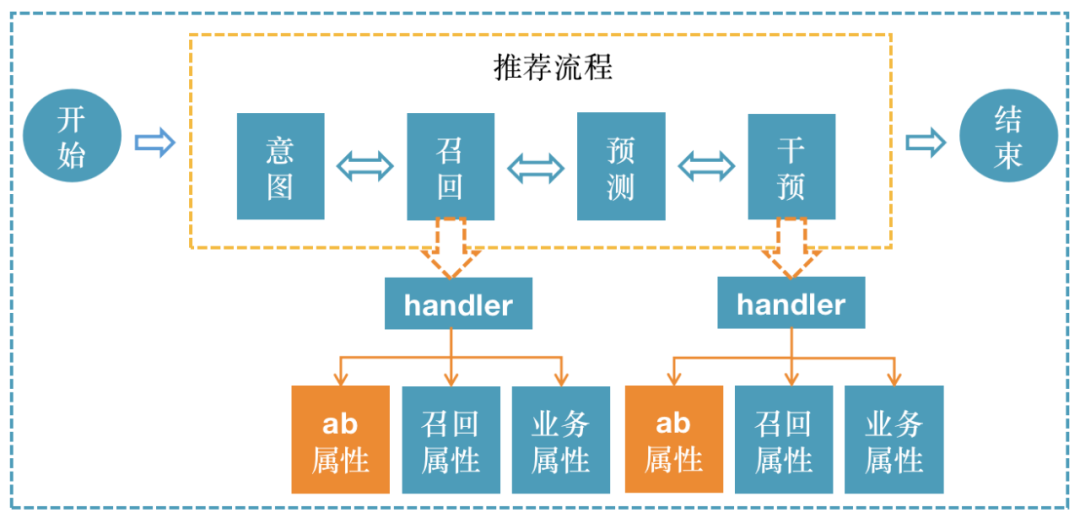
ab实验是推荐系统流量的分流核心,推荐迭代必备的度量衡,在推荐系统里的每个阶段使用,并且会不定时做出调整。在本次重构设计中,把ab属性的能力添加到推荐执行最小单的handler上。配置服务端可在handler上配置ab实验及策略,客户端执行中会根据handler所配置的ab策略选择是否执行业务代码。这样可以带来以下收益:
1、handler进一步和业务解藕,只需要关注单一业务点;
2、减少因为ab实验调整,带来的代码变动和上线次数,可以根据业务和策略实时做出调整。
4.3、召回服务
召回作为到家推荐重要的一环,除了召回商品也可以给其他推荐环节提供基础特征。是每次业务需求重点关注的环节。构建一套全量的商品召回池,可以避免面向业务点对点的开发。将原来分散存储在Redis里的商品数据进行整理和扩展,集中存储在ES数据库里。在召回阶段通过配置对商品进行召回。。
数据集中管理后,同时也解决了商品实时状态信息(如价格、售罄、下架等)不能及时更新问题。使用MQ队列与商品系统对接,商品系统发出变更消息,根据变更对ES里的商品进行修改,更新后会对全部召回通路生效。
4.4、预测服务
将模型预测服务化,可以使预测服务具备在线支持多种模型,多版本的能力。在预测阶段通过配置选择多种排序方式,根据业务需求可以随时进行调整。预测服务化后,还提高了系统性能和伸缩性,通过扩容机器提高服务的吞吐量,使用更复杂的模型预测。
5、展望