
【数据分析】数据缺失影响模型效果?是时候需要missingno工具包来帮你了!
数据探索和预处理是任何数据科学或机器学习工作流中的重要步骤。在使用教程或训练数据集时,可能会出现这样的情况:这些数据集的设计方式使其易于使用,并使所涉及的算法能够成功运行。然而,在现实世界中,数据是混乱的!它可能有错误的值、不正确的标签,并且可能会丢失部分内容。
丢失数据可能是处理真实数据集时最常见的问题之一。数据丢失的原因很多,包括传感器故障、数据过时、数据管理不当,甚至人为错误。丢失的数据可能以单个值、一个要素中的多个值或整个要素丢失的形式出现。
重要的是,在进行数据分析或机器学习之前,需要我们对缺失的数据进行适当的识别和处理。许多机器学习算法不能处理丢失的数据,需要删除整行数据,其中只有一个丢失的值,或者用一个新值替换(插补)。
根据数据的来源,缺失值可以用不同的方式表示。最常见的是NaN(不是数字),但是,其他变体可以包括“NA”、“None”、“999”、“0”、“ ”、“-”。如果丢失的数据是由数据帧中的非NaN表示的,那么应该使用np.NaN将其转换为NaN,如下所示。
df.replace('', np.NaN)
missingno 库
Missingno 是一个优秀且简单易用的 Python 库,它提供了一系列可视化,以了解数据帧中缺失数据的存在和分布。这可以是条形图、矩阵图、热图或树状图的形式。
从这些图中,我们可以确定缺失值发生的位置、缺失的程度以及是否有缺失值相互关联。通常,缺失的值可能被视为没有贡献任何信息,但如果仔细分析,可能有潜在的故事。
missingno库可以使用pip命令安装:
pip install missingno
数据集
在本教程中,我们将使用 Xeek and FORCE 2020举办的机器学习竞赛中公开可用数据集的一个子集。竞赛的目的是根据现有的标记数据预测岩性。数据集包括来自挪威海的118口井。
这些数据包含了测井仪器采集的一系列电测量数据。测量结果用于描述地下地质特征和确定合适的油气藏。本文的数据和笔记本可以在 GitHub 中找到
https://github.com/andymcdgeo/missingno_tutorial
导入库和加载数据
该过程的第一步是导入库。在本文中,我们将使用 pandas 来加载和存储我们的数据,并使用 missingno 来可视化数据完整性。
将pandas导入为 pd
import pandas as pd
import missingno as msno
df = pd.read_csv('xeek_train_subset.csv')
Pandas 快速分析
在使用 missingno 库之前,pandas库中有一些特性可以让我们初步了解丢失了多少数据。
第一种是使用.descripe()方法。这将返回一个表,其中包含有关数据帧的汇总统计信息,例如平均值、最大值和最小值。在表的顶部是一个名为counts的行。在下面的示例中,我们可以看到数据帧中的每个特性都有不同的计数。这提供了并非所有值都存在的初始指示。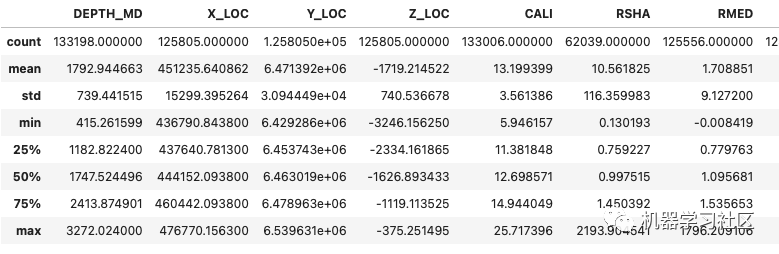
我们可以进一步使用.info()方法。这将返回数据帧的摘要以及非空值的计数。
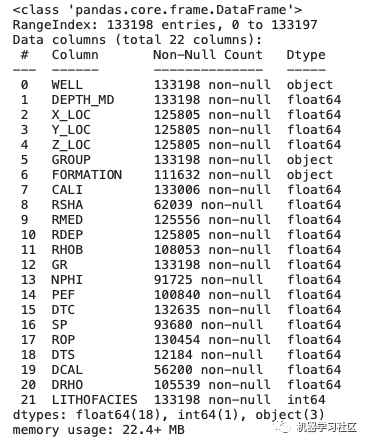
从上面的例子中我们可以看出,我们对数据的状态和数据丢失的程度有了更简明的总结。
我们可以使用的另一种快速方法是:
df.isna().sum()
这将返回数据帧中包含了多少缺失值的摘要。isna()部分检测dataframe中缺少的值,并为dataframe中的每个元素返回一个布尔值。sum()部分对真值的数目求和。
此行返回以下信息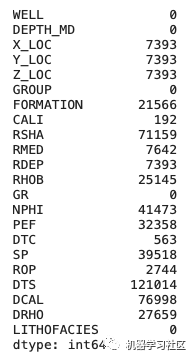 从这个总结中,我们可以看到许多列,即WELL、DEPTH、GROUP、GR 和 LITHOFACIES 没有空值。所有其他的都有大量不同程度的缺失值。
从这个总结中,我们可以看到许多列,即WELL、DEPTH、GROUP、GR 和 LITHOFACIES 没有空值。所有其他的都有大量不同程度的缺失值。
使用 missingno 识别缺失数据
在missingno库中,有四种类型的图用于可视化数据完整性:条形图、矩阵图、热图和树状图。在识别缺失数据方面,每种方法都有自己的优势。
让我们依次看一下这些。
条形图
条形图提供了一个简单的绘图,其中每个条形图表示数据帧中的一列。条形图的高度表示该列的完整程度,即存在多少个非空值。它可以通过调用:
msno.bar(df)
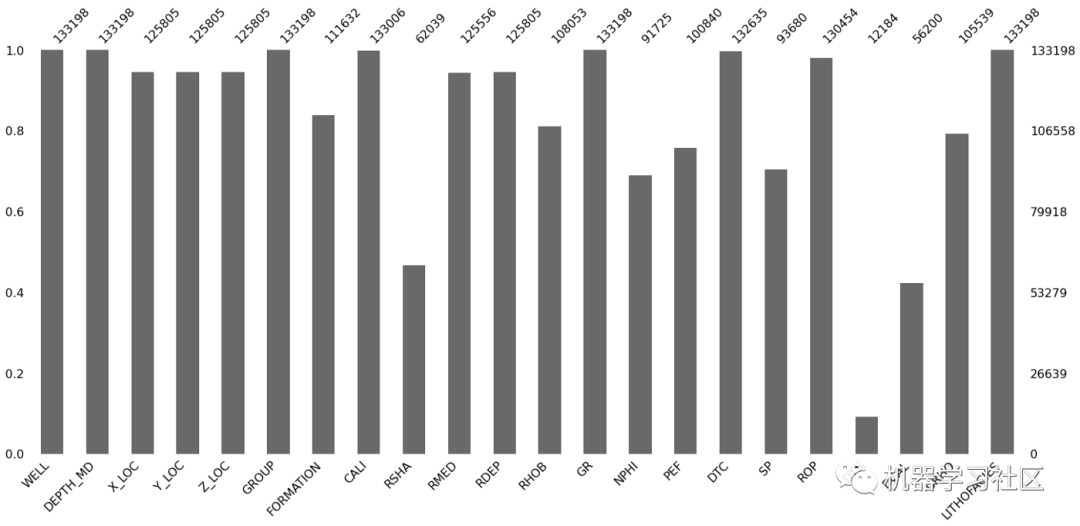
在绘图的左侧,y轴比例从0.0到1.0,其中1.0表示100%的数据完整性。如果条小于此值,则表示该列中缺少值。
在绘图的右侧,用索引值测量比例。右上角表示数据帧中的最大行数。
在绘图的顶部,有一系列数字表示该列中非空值的总数。
在这个例子中,我们可以看到许多列(DTS、DCAL和RSHA)有大量的缺失值。其他列(如WELL、DEPTH_MD和GR)是完整的,并且具有最大的值数。
矩阵图
如果使用深度相关数据或时间序列数据,矩阵图是一个很好的工具。它为每一列提供颜色填充。有数据时,绘图以灰色(或您选择的颜色)显示,没有数据时,绘图以白色显示。
通过调用以下命令可以生成矩阵图:
msno.matrix(df)
 如结果图所示,DTS、DCAL和RSHA列显示了大量缺失数据。这是在条形图中确定的,但附加的好处是您可以「查看丢失的数据在数据框中的分布情况」。
如结果图所示,DTS、DCAL和RSHA列显示了大量缺失数据。这是在条形图中确定的,但附加的好处是您可以「查看丢失的数据在数据框中的分布情况」。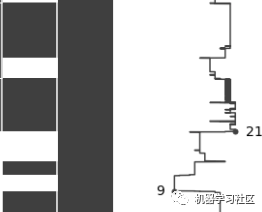 绘图的右侧是一个迷你图,范围从左侧的0到右侧数据框中的总列数。上图为特写镜头。当一行的每列中都有一个值时,该行将位于最右边的位置。当该行中缺少的值开始增加时,该行将向左移动。
绘图的右侧是一个迷你图,范围从左侧的0到右侧数据框中的总列数。上图为特写镜头。当一行的每列中都有一个值时,该行将位于最右边的位置。当该行中缺少的值开始增加时,该行将向左移动。
热图
热图用于确定不同列之间的零度相关性。换言之,它可以用来标识每一列之间是否存在空值关系。
接近正1的值表示一列中存在空值与另一列中存在空值相关。
接近负1的值表示一列中存在空值与另一列中存在空值是反相关的。换句话说,当一列中存在空值时,另一列中存在数据值,反之亦然。
接近0的值表示一列中的空值与另一列中的空值之间几乎没有关系。
有许多值显示为<-1。这表明相关性非常接近100%负。
热图可由以下代码生成:
msno.heatmap(df)
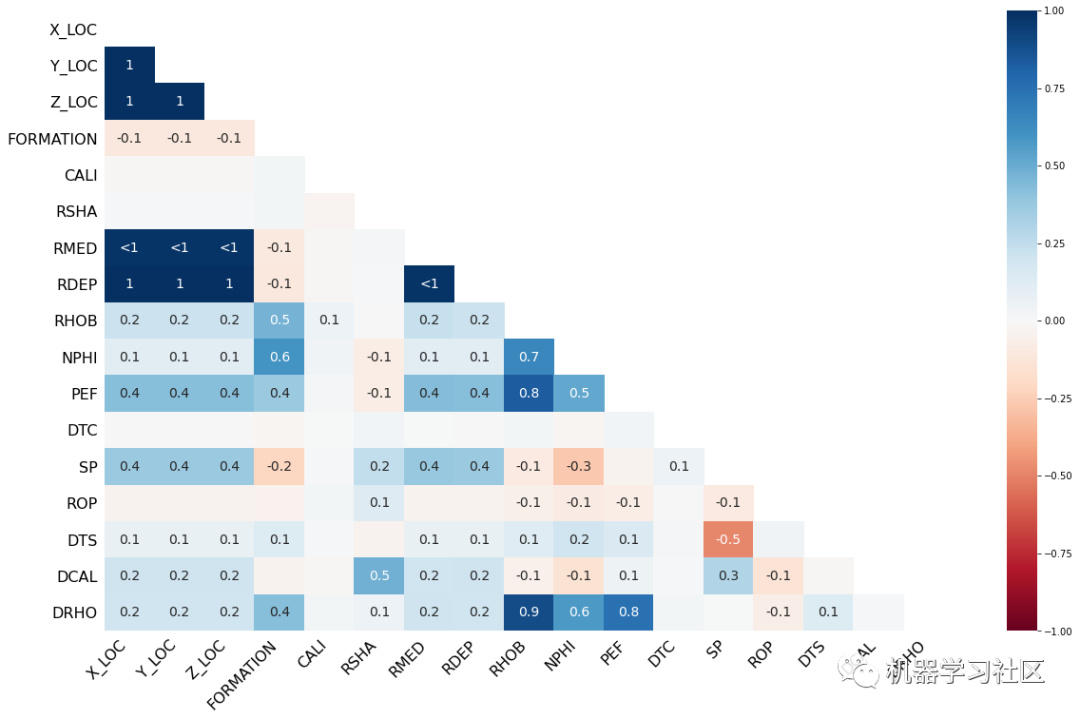
在这里我们可以看到ROP柱与RHOB、NPHI和PEF柱呈轻微的负相关,与RSHA呈轻微的正相关。如果我们看一下DRHO,它的缺失与RHOB、NPHI和PEF列中的缺失值高度相关。
热图方法更适合于较小的数据集。
树状图
树状图提供了一个通过层次聚类生成的树状图,并将空相关度很强的列分组在一起。
如果在零级将多个列组合在一起,则其中一列中是否存在空值与其他列中是否存在空值直接相关。树中的列越分离,列之间关联null值的可能性就越小。
树状图可通过以下方式生成:
msno.dendrogram(df)
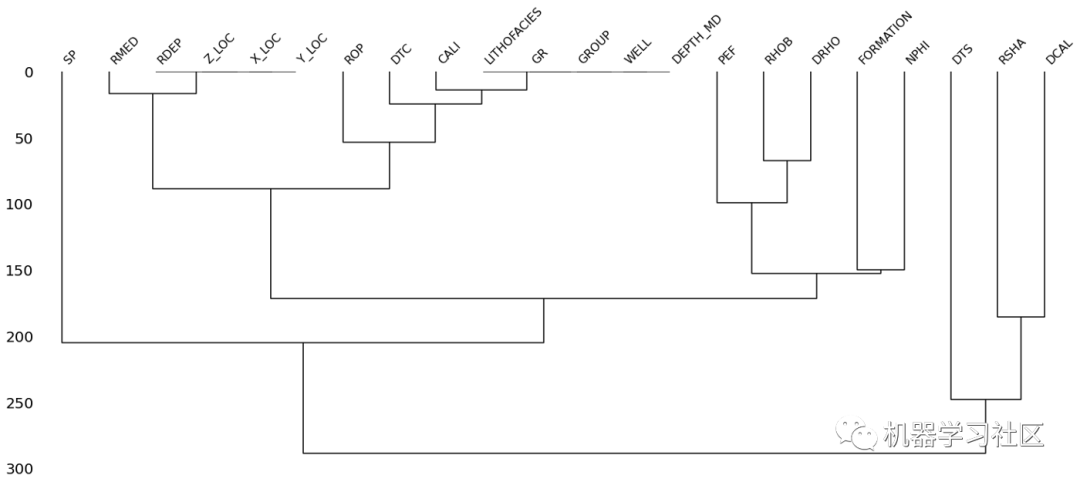
在上面的树状图中,我们可以看到我们有两个不同的组。第一个是在右侧(DTS、RSHA和DCAL),它们都具有高度的空值。第二列在左边,其余的列比较完整。
LITHOFACIES, GR, GROUP, WELL, 和 DEPTH_MD 都归为零,表明它们是完整的。
RDEP、ZïLOC、XïLOC和YïLOC组合在一起,接近于零。RMED位于同一个较大的分支中,这表明该列中存在的一些缺失值可以与这四列相关联。
摘要
在应用机器学习之前识别缺失是数据质量工作的一个关键组成部分。这可以通过使用missingno库和一系列可视化来实现,以了解有多少缺失数据存在、发生在哪里,以及不同数据列之间缺失值的发生是如何关联的。
往期精彩回顾 本站qq群851320808,加入微信群请扫码: