
Avro之序列化
Avro是Hadoop中的一个子项目,其是一个数据序列化系统。这里我们主要介绍下其在序列化方面的应用。与其它序列化方式相比,其一方面具备与编程语言无关的特性,另一方面序列化后的数据文件体积较小

POM
首先,在POM文件中添加Avro依赖
<!-- Avro -->
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.8.2</version>
</dependency>
Avro通过schema文件来定义类信息,进一步地可通过编译schema文件自动生成相应的类文件。故在POM文件中继续添加、配置avro-maven-plugin插件来方便我们后续编译schema文件
<build>
<plugins>
<!-- Avro -->
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.8.2</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<!-- 配置schema文件目录 -->
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<!-- 配置schema文件编译后的生成目录 -->
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
Schema文件
前面我们提到Avro使用schema文件(文件类型后缀.avsc)来描述类信息。具体地,通过JSON来进行定义,且支持原始类型(null, boolean, int, long, float, double, bytes, string)、复杂类型(record, enum, array, map, union, fixed)等多种数据类型。下面即是一个record类型的Schema文件示例
{
"type": "record", // 数据类型: record
"namespace": "com.aaron.Avro.POJO", // 包名
"name": "User", // 类名
// 属性名
"fields": [
{"name": "name", "type": "string", "doc": "姓名"},
{"name": "age", "type": ["int", "null"],"doc": "年龄"},
{"name": "sex", "type": ["string", "null"],"doc": "性别"}
]
}
IDEA下,我们可将schema文件(文件类型后缀.avsc)关联为JSON文件类型,实现语法颜色高亮
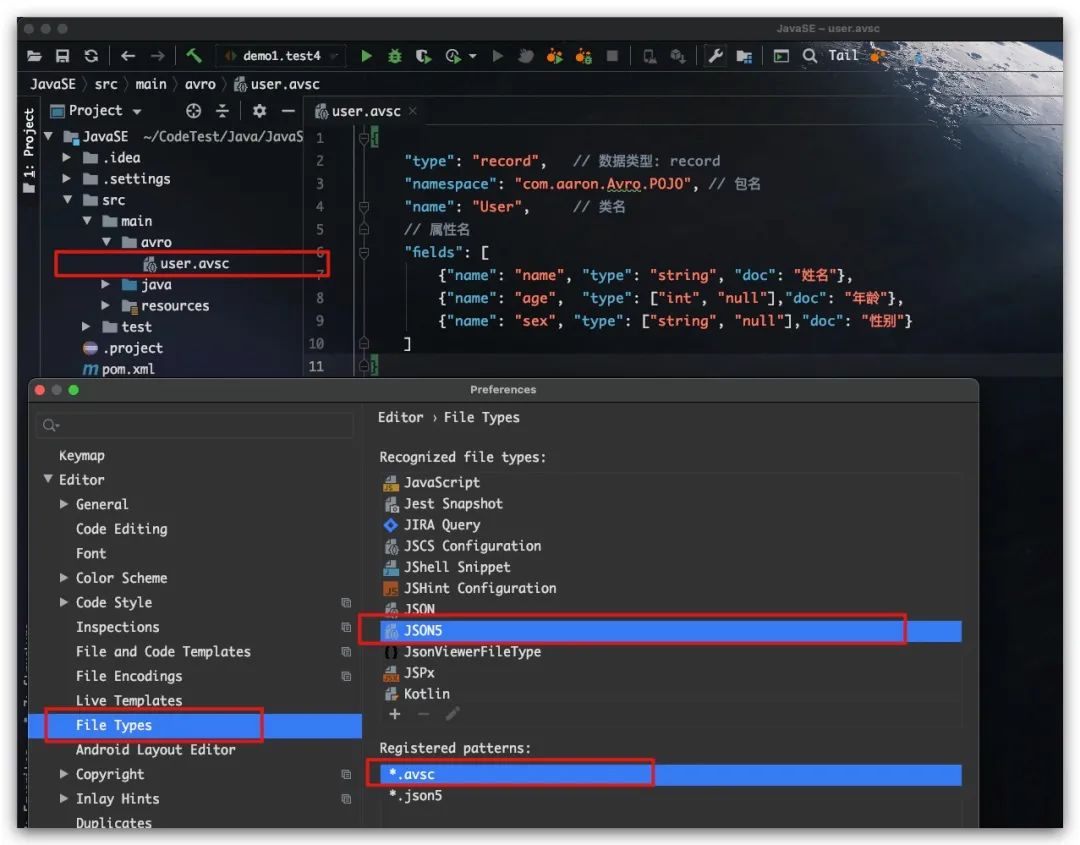
现在我们点击Maven的compile,即可进行schema文件的编译。可以看到在com.aaron.Avro.POJO包下生成了一个名为User的Java类
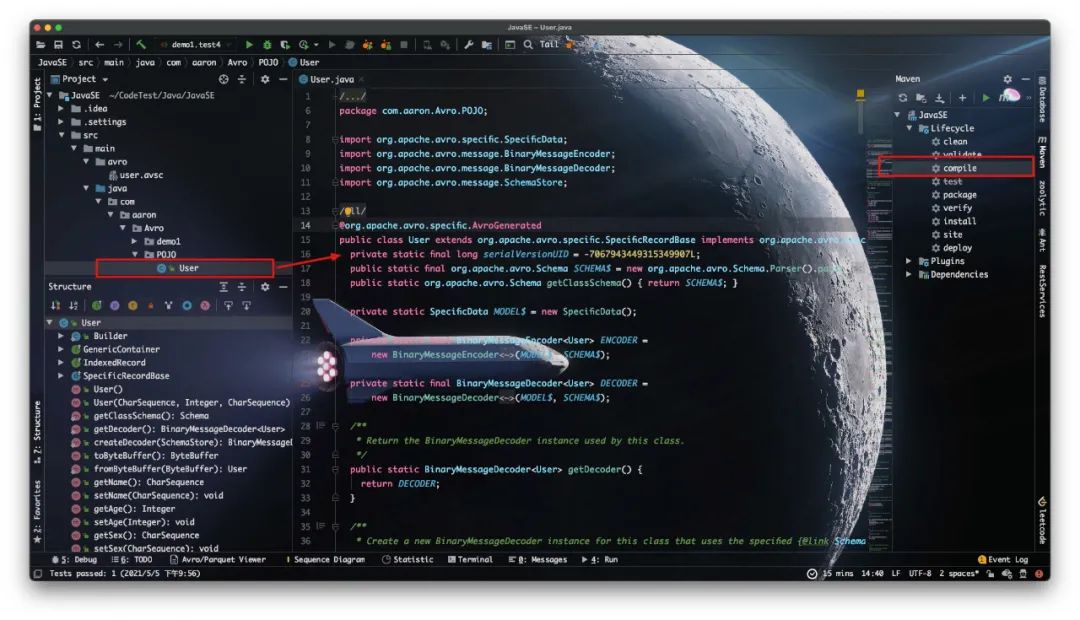
基于编译生成的类文件
前面我们通过编译Schema生成了User类,这样我们就可以直接使用该类进行序列化、反序列化
序列化到文件及反序列化
测试代码如下
public class demo1 {
/**
* 对象序列化到文件
* @throws IOException
*/
@Test
public void test1() throws IOException {
DatumWriter<User> datumWriter = new SpecificDatumWriter<>(User.class);
DataFileWriter<User> dataFileWriter = new DataFileWriter<>(datumWriter);
Schema schema = User.getClassSchema();
String fileName = "userData.avro";
dataFileWriter.create( schema, new File( fileName ) );
List<User> list = getUserList();
for (User user : list) {
dataFileWriter.append(user);
}
dataFileWriter.close();
}
private List<User> getUserList() {
List<User> list = new LinkedList<>();
list.add( new User("Aaron", 25, "男") );
list.add( new User("Bob", 27, "女") );
list.add( new User("Tony", 18, null) );
return list;
}
}
IDEA下可利用Avro and Parquet Viewer插件来查看Avro序列化后的数据文件,这里将userData.avro文件拖入框中即可很方便的查看该文件的Schema及数据内容,如下图所示
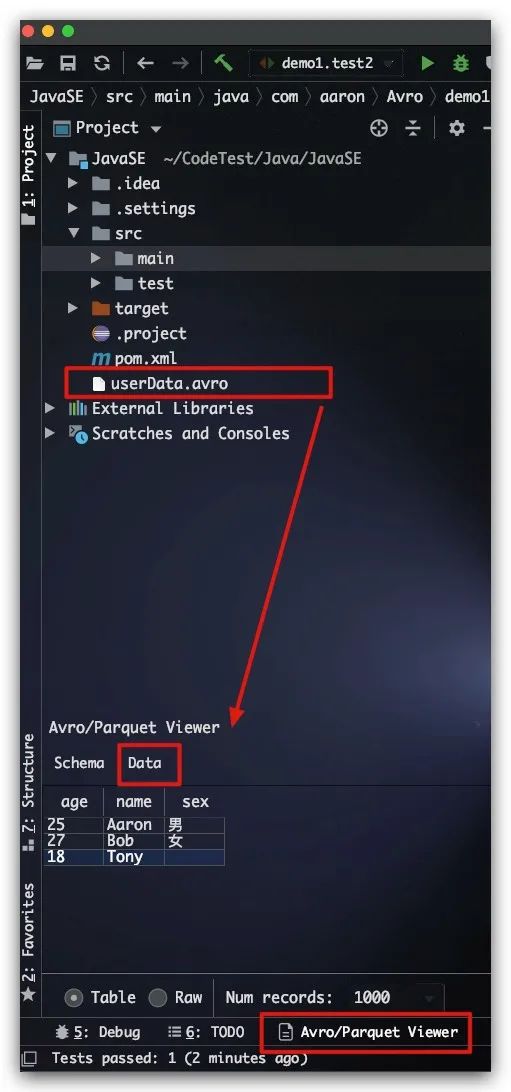
好了,现在我们利用该数据文件进行反序列化
public class demo1 {
/**
* 从文件中反序列化为对象
* @return
*/
@Test
public void test2() throws IOException {
String fileName = "userData.avro";
DatumReader<User> datumReader = new SpecificDatumReader<>( User.class );
DataFileReader<User> dataFileReader = new DataFileReader<>( new File(fileName), datumReader);
while ( dataFileReader.hasNext() ) {
User user = dataFileReader.next();
System.out.println(user);
}
}
}
结果如下所示,符合预期
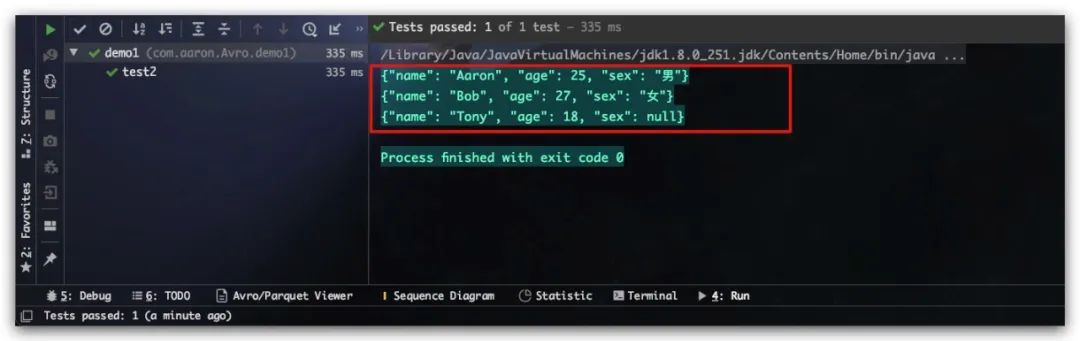
序列化为字节数组及反序列化
如果期望序列化为字节数组,操作也是类似地。示例代码如下所示
public class demo1 {
/**
* 对象序列化为字节数组及反序列化
*/
@Test
public void test3() throws IOException {
System.out.println("--------------- 对象序列化为字节数组 ---------------");
DatumWriter<User> datumWriter = new SpecificDatumWriter<>(User.class);
DataFileWriter<User> dataFileWriter = new DataFileWriter<>(datumWriter);
Schema schema = User.getClassSchema();
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
dataFileWriter.create( schema, byteArrayOutputStream );
List<User> list = getUserList();
for (User user : list) {
dataFileWriter.append(user);
}
dataFileWriter.close();
// 序列化后的字节数组
byte[] byteArray = byteArrayOutputStream.toByteArray();
System.out.println("--------------- 字节数组反序列化为对象 ---------------");
SeekableByteArrayInput seekableByteArrayInput = new SeekableByteArrayInput(byteArray);
DatumReader<User> datumReader = new SpecificDatumReader<>( User.class );
DataFileReader<User> dataFileReader = new DataFileReader<>( seekableByteArrayInput, datumReader );
while ( dataFileReader.hasNext() ) {
User user = dataFileReader.next();
System.out.println(user);
}
}
}
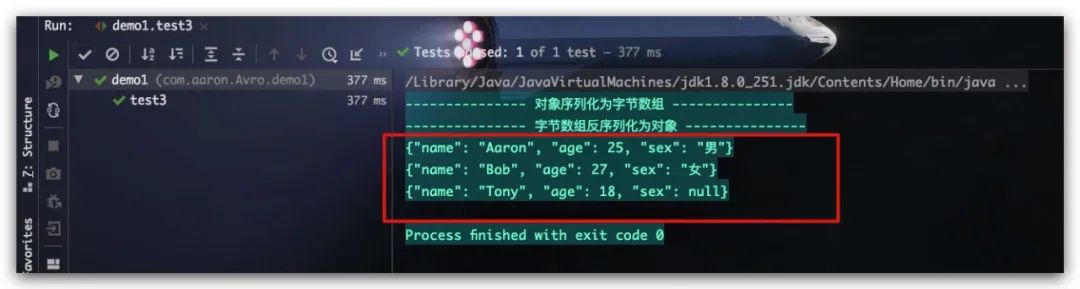
测试结果如下,符合预期
直接基于Schema文件
事实上,编译scheam文件生成类文件,这一步并不是必须的。对于简单的业务处理,我们也可以直接利用schema文件进行序列化及反序列化
public class demo1 {
/**
* 序列化为字节数组及反序列化
* @throws IOException
*/
@Test
public void test4() throws IOException {
System.out.println("--------------- 序列化为字节数组 ---------------");
String path = System.getProperty("user.dir") + "/src/main/avro/";
String fileName = "user.avsc";
Schema schema = new Schema.Parser().parse( new File(path, fileName) );
GenericRecord user1 = new GenericData.Record(schema);
user1.put("name", "刘备");
user1.put("age", 33);
user1.put("sex", "男");
GenericRecord user2 = new GenericData.Record(schema);
user2.put("name", "孙尚香");
user2.put("age", 46);
user2.put("sex", "女");
GenericRecord user3 = new GenericData.Record(schema);
user3.put("name", "曹操");
user3.put("age", 146);
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<>(datumWriter);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
dataFileWriter.create(schema, byteArrayOutputStream);
dataFileWriter.append( user1 );
dataFileWriter.append( user2 );
dataFileWriter.append( user3 );
dataFileWriter.close();
// 序列化后的字节数组
byte[] byteArray = byteArrayOutputStream.toByteArray();
System.out.println("--------------- 字节数组反序列化 ---------------");
SeekableByteArrayInput seekableByteArrayInput = new SeekableByteArrayInput(byteArray);
DatumReader<GenericRecord> datumReader = new GenericDatumReader<>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<>(seekableByteArrayInput, datumReader);
while (dataFileReader.hasNext()) {
GenericRecord user = dataFileReader.next();
System.out.println(user);
}
}
}
测试结果如下,符合预期

参考文献
Kafka权威指南 Neha Narkhede/Gwen Shapira/Todd Palino著