
Mysql表有近千万数据,CRUD如何优化?
点击上方"Java后端编程", 右上角选择“设为星标”
精品技术文章准时送上!
MySQL 数据库某张表近千万的数据,CRUD比较慢,如何优化?
说实话,这个数据量级, MySQL 单库单表支撑起来完全没有问题的,所以首先还是考虑数据库本身的优化。
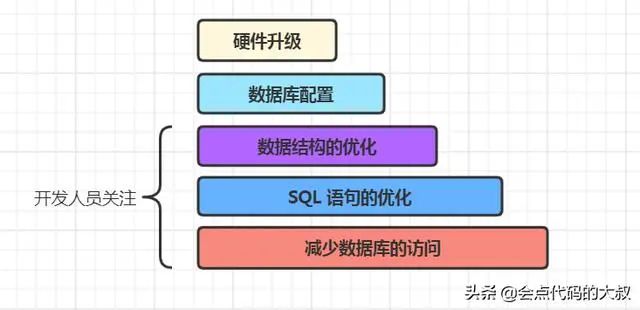
从上图可以看到,数据库优化通常可以通过以上几点来实现:
硬件升级:也就是花更多的钱,升级我们数据库硬件配置,包括 CPU、内存、磁盘、网络等等,但是这个方案成本高,而且不一定能起到非常好的效果。
数据库配置:修改数据库的配置,有可能让我们的 CRUD 操作变得更快,不过我也不建议大家把经历放在这一点上面;首先,数据库的配置通常由专业的 DBA 来负责;第二,大部分时候,默认的数据库配置在大多数情况下已经是最优配置了。
对于开发人员来说,我们需要把注意力放在后面三点:
数据结构的优化,也就是表结构的优化
数据类型的选择:选用合适的数据结构。什么叫做"合适的数据结构",比如性别字段,M表示男F表示女,那么一个 char(1) 就足够了,如果存储人的年龄,那么就没有必要使用 INT 这么大范围的字段了;
适当的拆分:千万不要试图把所有的字段放在一张表中,因为这会非常影响性能,通常一张表的字段最好不要超过 30 个;
适当的冗余:如果一些常用的字段,可能会用在不同的维度,那么我们可以把这些字段设计在多张表中,因为这样可能会减少表关联;
字段尽量设置成 not Null,尽量带有默认值。
SQL 语句的优化
优化 SQL 语句执行速度的方法有很多,比如:
尽量使用索引,尽量避免全表扫描,提高查询速度;
当然你不能无限制地建立索引;维护索引也会影响性能,会降低 DML 操作的速度;
注意 SQL 语句的书写,有一些错误的写法可能会导致索引失效;
尽量避免在 where 子句中对字段进行 Null 值判断(当然我们在表设计中,直接建议不要有 Null);
条件值多的情况下,尽量不要使用 in 和 not in ;
select 的时候,使用具体的字段代替 * 号
避免返回大量数据,增加分页;
减少数据库的访问
我们可以通过增加本地缓存或分布式缓存的方式,将热点数据存储到缓存中,以减少数据库的访问;
终极大招,如果是一个不合理的需求,我们可以拒绝做这个需求,这样也算是"减少了数据库访问"。
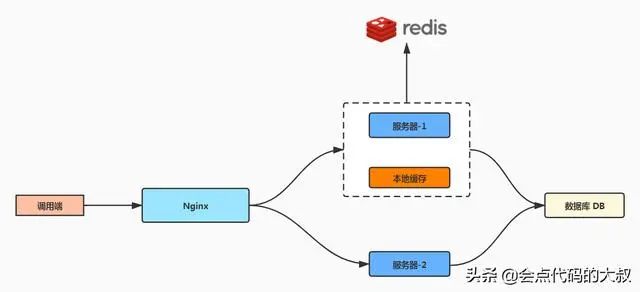
说完了 MySQL 本身的优化,如果数据量进一步增大的话,我们还有什么优化的方案呢?
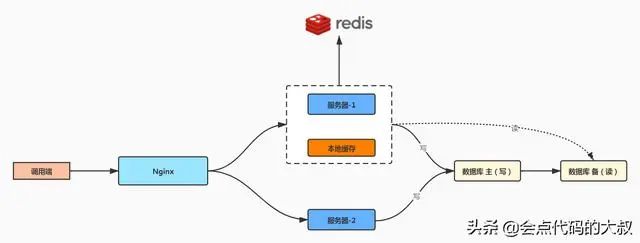
读写分离
主库用于写,从库用于读,将读写分散在不同的数据库上,利用多台机器的资源,来提高数据库的可用性和性能。
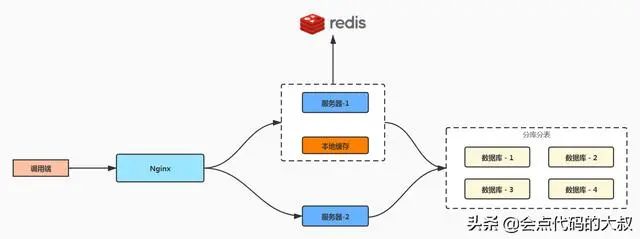
分库分表
如果数据持续增多,超过了单台 MySQL 的支撑上限,那么只能用【分库分表】这一招了;我们可以采用一定的路由规则,将数据保存到不同的数据库中。
当然,如果不是“迫不得已”,我是不太建议分库分表的,因为这样极大地增加了系统的复杂程度,并且会带来更多的问题需要开发人员解决。
以上就是常用的 MySQL 优化方案,如果是千万级数据量,优化 MySQL 本身即可。
推荐阅读:
最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
明天见(。・ω・。)ノ♡