
MySQL千万大表优化实践
点击上方蓝色字体,选择“设为星标”




前段时间笔者遇到一个复杂的慢查询,今天有空便进行了整理,以便日后回顾。举一个相似的业务场景的例子。以文章评论为例,查询20191201~20191231日期间发表的经济科技类别的文章,同时需要显示这些文章的热评数目
涉及到的四张表结构如下所示
文章表结构和索引信息如下,文章表中存储了200万数据


评论表结构和索引信息如下,评论表存储了1000万数据


文章分类表结构如下,这张表数据比较少,仅仅存储了300条数据

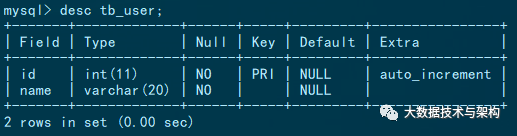
用户表结构如下,该表存储了100万数据
其中涉及到的慢查询语句如下所示,这个查询语句性能非常慢,执行时间接近60s
SELECT
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
FROM
tb_article
LEFT JOIN tb_cmt ON tb_article.`id` = tb_cmt.`article_id`
INNER JOIN tb_user on tb_article.`userid` = tb_user.`id`
WHERE
tb_article.`type` IN (
SELECT code
FROM tb_category
WHERE code like '12%' or code like '13%'
)
AND tb_cmt.`upvote` > 100
AND tb_cmt.`len` BETWEEN 10 AND 30
AND tb_article.`create_time` BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
GROUP BY
tb_cmt.`article_id`使用explain分析慢查询的执行流程

Mysql执行流程如下,首先mysql以tb_category作为驱动表,看到这,有没有感到很奇怪,tb_category在整个查询中只是作为一个子查询存在,tb_category怎么成为驱动表了呢?如果读者了解mysql的in子查询原理的话就很好理解了,mysql会将in查询改写为semi-join关联查询,explain涉及到的start temporary和end temporary用于semi-join的去重。我们可以使用explain extended和show warnings查看mysql改写的的查询语句,mysql改写后的查询语句如下所示

Mysql为什么选择tb_category作为驱动表呢?原因是tb_category的表最小,只有300条数据,mysql查询优化器通常情况下都会以小表作为驱动表。
随后,tb_category和tb_article进行关联计算,关联计算的列是tb_article的type列,mysql使用了tb_article表上的type_time_idx的索引,这个过程mysql使用了Batched Key Access进行了优化以达到减少索引回表查找的IO次数,随后关联tb_cmt表,这次关联中,mysql使用了tb_cmt的article_id_idx字段。经过上述关联,mysql生成了一个结果集,mysql再在结果集上对upvote,type和len字段进行where条件筛选,最后进行了一次group by操作。
优化的核心思路仍然是减少扫描的行数,从上述的explain结果上看,扫描的rows行数好像不是很多,但是tb_category,tb_article,tb_cmt,tb_user四张表关联之后生成的结果集非常的庞大,笔者使用如下代码进行以一次计算
SELECT
count(*)
FROM
tb_article
LEFT JOIN tb_cmt ON tb_article.`id` = tb_cmt.`article_id`
INNER JOIN tb_user on tb_article.`userid` = tb_user.`id`
WHERE
tb_article.`type` IN (
SELECT code
FROM tb_category
WHERE code like '12%' or code like '13%'
)结果如下
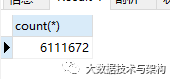
四张表的关联结果集有611万数据
如果读者了解Mysql关联查询原理的话,读者便会知道mysql的关联查询之后,如果再进行条件筛选是无法使用非驱动表索引的(换一句话讲,mysql关联查询只会使用驱动表的索引进行条件筛选),也就是说下面几个条件都是无法使用索引的

在611万结果集上进行upvote,len,create_time条件筛选和group by操作性能可想而知很慢了。笔者希望在执行关联查询的时候可以尽量多的使用索引,比如upvote_len_idx,create_time_idx索引,所以驱动表一定不能是tb_category。和1000万数据量的tb_cmt表相比,笔者更希望以只有200万数据量的tb_article表作为驱动表。
步骤一:避免semi-join
如果笔者希望以tb_article作为驱动表,那么一定要避免in的关联子查询,因为mysql在执行in关联子查询的时候,会将其转化为semi-join,因为tb_category数据量少,mysql查询优化器会使用tb_category作为驱动表。
避免semi-join的关键是避免in子查询,笔者将上述查询语句拆分为两个查询语句,在应用服务层首先执行如下语句选出经济,科技类型文章的编码
SELECT code
FROM tb_category
WHERE code like '12%' or code like '13%'然后再将上述结果代入到原来查询中,查询语句修改如下
SELECT
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
FROM
tb_article
LEFT JOIN tb_cmt ON tb_article.`id` = tb_cmt.`article_id`
INNER JOIN tb_user on tb_article.`userid` = tb_user.`id`
WHERE
tb_article.`type` IN (
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)
AND tb_cmt.`upvote` > 100
AND tb_cmt.`len` BETWEEN 10 AND 30
AND tb_article.`create_time` BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
GROUP BY
tb_cmt.`article_id`优化之后查询耗时18s,性能有了非常大的提升,我们再看一下优化后的explain结果

我们看到,mysql以tb_article作为驱动表,并且查询不再涉及semi-join,达到了当前步骤的优化目的
步骤二:尽力使用索引
当前的查询语句以tb_article作为驱动表,同时使用了tb_article上的type_time_idx索引过滤tb_article表,然后关联tb_cmt表,这个关联过程只会使用tb_cmt一个索引article_id,而tb_cmt存储有1000万数据,即使使用了article_id这个索引,最终会生成一个134万的结果集,在134万的结果集上进行如下条件过滤和group by mysql的性能仍然会非常差。
tb_cmt.`upvote` > 100
tb_cmt.`len` BETWEEN 10 AND 30
GROUP BY
tb_cmt.`article_id`笔者希望tb_article仅仅和热门评论进行关联,扫描的数据就大大减少。利用这个思路笔者重新编写sql语句如下
select
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
from tb_article
LEFT JOIN (
SELECT article_id FROM tb_cmt
WHERE tb_cmt.upvote > 100
AND tb_cmt.len BETWEEN 10 AND 30
) t
on t.article_id=tb_article.id
INNER JOIN tb_user ON tb_article.userid = tb_article.userid
AND tb_article.create_time BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
AND tb_article.type IN(
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)
GROUP BY article_id为了使用tb_cmt上的upvote_len_idx索引,笔者延迟了tb_cmt关联,先对tb_cmt进行了筛选。虽然这个查询会生成一个临时表t,但是临时表t比较小,数据量不足10万,所以这个临时表也不会造成太大的性能负担。但是tb_cmt的子查询却无法使用upvote_len_idx索引,我们还得对范围查询进行优化
步骤三:范围查询优化
笔者让tb_article和筛选过的评论表即热评表t进行关联,但是发现评论的子查询表仍然不使用upvote_len_idx索引,原因是tb_cmt.upvote > 100是一个范围查询,而tb_cmt.len BETWEEN 10 AND 30也是一个范围查询,mysql不支持松散索引扫描,无法在同一个索引上使用两个范围查询。优化思路是将两个范围查询优化为一个范围查询,将tb_cmt.len BETWEEN 10 AND 30优化为散列值,同时删除原来的upvote_len_idx,创建len_upvote_idx索引,目的是将需要范围扫描的upvote字段置为组合索引的尾部。
优化之后代码如下所示
SELECT
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
from tb_article
LEFT JOIN (
SELECT article_id FROM tb_cmt
WHERE tb_cmt.upvote > 100
AND tb_cmt.len in (10 ,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29, 30 )
) t
on t.article_id=tb_article.id
INNER JOIN tb_user ON tb_user.id = tb_article.userid
AND tb_article.create_time BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
AND tb_article.type IN(
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)
GROUP BY article_id在这一步优化之后,笔者再次执行查询,发现性能变得更差了,原本18秒可以运行结束的查询,现在需要40s。原因是什么呢?因为t表的生成过程完全走在索引上,所以t表的生成过程不是性能瓶颈所在,所以笔者猜测是引入的t表和tb_article表左关联时候性能太差的原因,于是笔者注释掉生成t表的子查询以验证笔者的猜想,注释后的代码如下所示
SELECT
tb_article.`title`,
tb_user.`name`,
count( 1 ) AS `total`
from tb_article
-- LEFT JOIN (
-- SELECT article_id FROM tb_cmt
-- WHERE tb_cmt.upvote > 100
-- AND tb_cmt.len in (10 ,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29, 30 )
-- ) t
-- on t.article_id=tb_article.id
INNER JOIN tb_user ON tb_user.id = tb_article.userid
AND tb_article.create_time BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
AND tb_article.type IN(
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)
GROUP BY tb_article.id上述查询耗时5.26秒,验证了笔者的上述猜想,但是笔者也没有太好的办法解决这个问题,笔者在尝试group by优化时意外找到了优化方案
步骤四 group by优化
仔细观察这个sql语句,我们可以发现GROUP BY这个操作既可以放在临时表t中,又可以放在关联后的结果集上进行,我们如何选择呢?group by无法使用索引,只能使用临时表,所以我们应该让需要被group by的数据尽量的少,而tb_article和tb_cmt是左关联,所以应该将group by操作放在tb_cmt子查询内部进行。除此之外,group by 优化还有一个小技巧,mysql在执行group by的时候,默认会进行排序,在当前业务中,笔者并不需要进行排序,于是笔者在group by 末尾追加order by null ,最终优化的sql结果为
SELECT
tb_article.`title`,
tb_user.`name`,
`total`
from tb_article
LEFT JOIN (
SELECT article_id ,count( 1 ) AS `total` FROM tb_cmt
WHERE tb_cmt.upvote > 100
AND tb_cmt.len in (10 ,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29, 30 )
GROUP BY article_id
ORDER BY null
) t
on t.article_id=tb_article.id
INNER JOIN tb_user ON tb_user.id = tb_article.userid
AND tb_article.create_time BETWEEN '2019-12-01 00:00:00' AND '2019-12-31 23:59:59'
AND tb_article.type IN(
'1213331',
'1374609',
'1389750',
'1204526',
'1382565',
'1239054',
'1321189',
'1292666'
)整个查询耗时1.3秒,和原查询耗时60秒相比,已经有了近60倍性能提升。我们再看一下Explain分析

可以看到在将group by放在子查询内部的时候,生成的临时表t好像出现了一个索引


版权声明:
文章不错?点个【在看】吧! ?