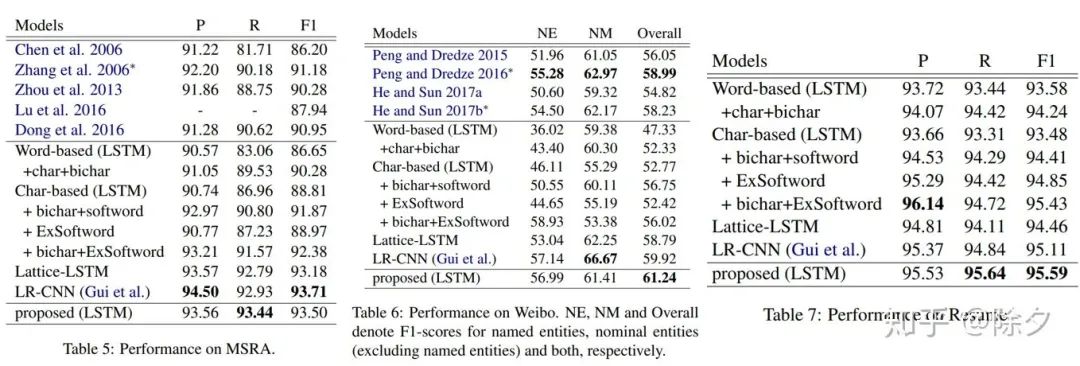
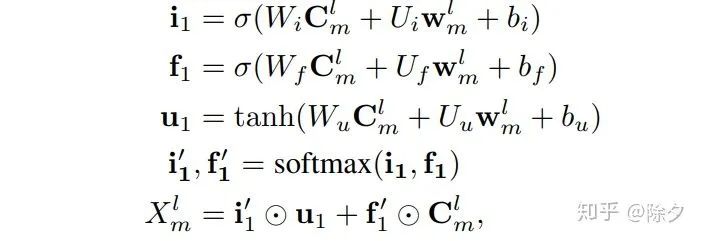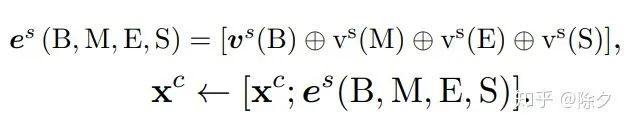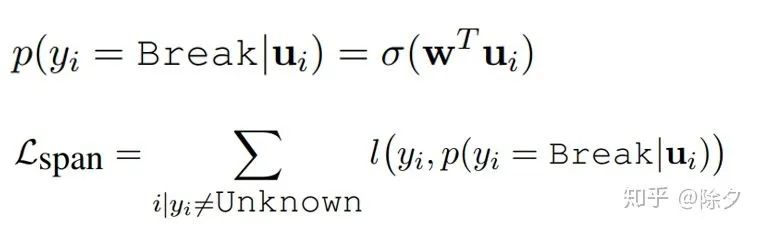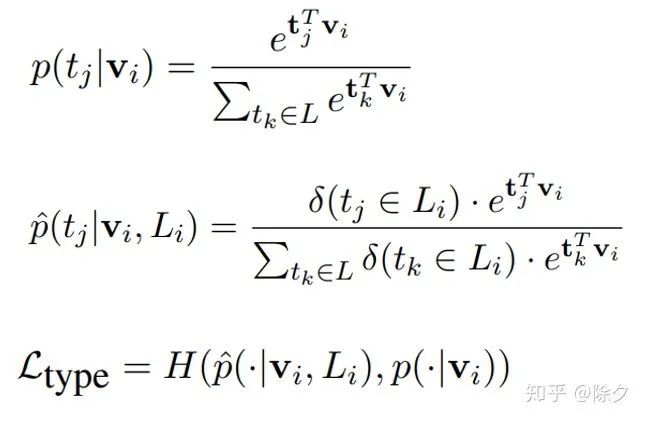对于第一种思路,我们可以分别对词的边界和词的类别做领域迁移。对于词的类别,比如我们想标注娱乐明星,体育明星和企业名人的数据,可以先用模型识别出人名,再把获得的人名去进一步区分它所归属的领域,可以大大减小标注工作量。对于词的边界,比如武器、战斗机型号。Hanlp 的做法是先用词法分析器对序列做词性标注,再把其中的某几个词合并成目标词。米格/nr -/w 17/m PF/nx可以变成[米格/nr -/w 17/m PF/nx]对于第二种远程监督的思路,我们主要讲一下 AutoNER。论文:Learning Named Entity Tagger using Domain-Specific Dictionary我们如何用领域词表来生成标注数据呢?一种方法是直接的词典匹配来标注数据。但这会遇到两个问题:
词典无法覆盖所有实体,匹配会有误召回,存在噪音
无法解决相同实体对应多个类别的情况,还有未知类型的情况
为此,论文提出了一种 Tie or Break 的标注方案,来让噪音尽可能地少。
若当前词与上一个词在同一个实体内 Tie (O)
若其中一个词属于一个未知类型的实体短语,则该词的前后都是 Unknown (U)
其它情况都默认 Break (I)
某个实体类型未知 None (N)
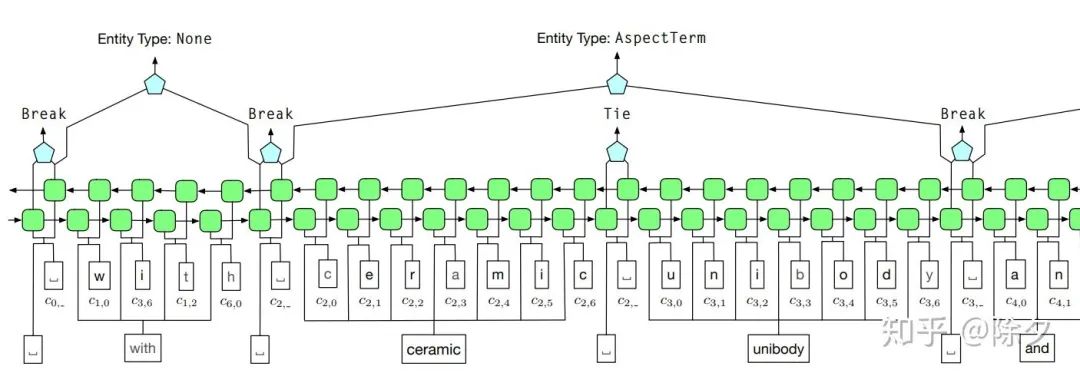
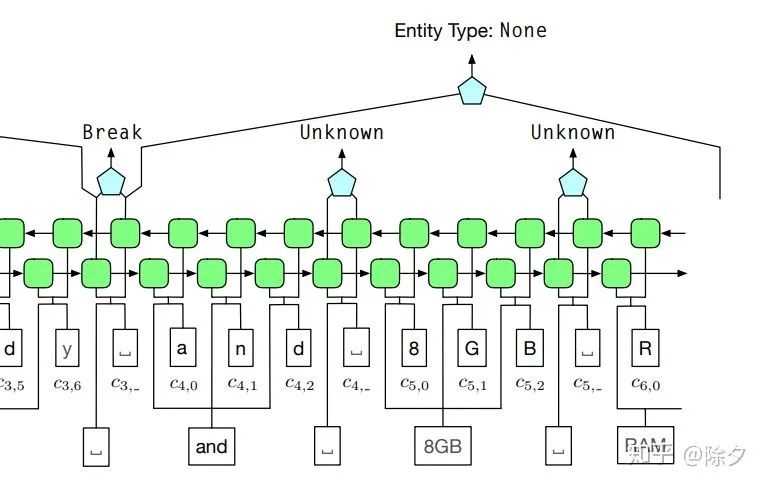
假如我们词典中只有 "银行" 这个词,而要识别的机构实体是 "浙商银行"。如果我们用 IOBES 的方案去做远程监督,效果如下:输入文本:浙 商 银 行 企 业 信 贷 部 真实标签:B-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG I-ORG E-ORG 远程监督:O O B-ORG E-ORG O O O O O这会出现一个问题,即"银行"的边界真实标签会与远程监督得到的标签不一致。这里的银行的两个 "I",一个标注成了 "B",一个标注成了 "E"。输入文本:浙 商 银 行 企 业 信 贷 部 真实标签:I O O O O O O O O 远程监督:I I I O I I I I I在以上例子中,Tie or Break 模式能保证 Tie 所在的位置一定是正确的,即在领域核心词典中“银行”的"行"字,一定是和前面的"银"字是合起来的。而剩下未知的 Break,模型会自动学到是否要 Tie。对于 Unknown 的词,它不会作为监督信息计算损失更新模型的权重。模型只会从正确标签中确定的信息计算损失,来从领域词典中学到必要的标注规则。再把这些规则泛化到周边未知边界和类别的词。在 AutoNER 中,实体边界的远程监督信息和实体类别的远程监督信息是分开来计算的。这是为了能充分利用非领域词典——高质量短语词表中的词的边界信息。在原论文中,ceramic unibody 是在领域词典中,只有一个类别的词。所以它们组成的实体的类别是可以 100% 确定的。可是实际中领域词典往往不会很全,提供的监督信息是有限的。像 8GB RAM 是一个在高质量短语词表中的短语。我们虽然不知道它的类别,但它可以给我们提供词的边界信息。它们边界的标签被标记为 Unknow,且不参与 span prediction 的损失计算。这样做的好处是,它排除了许多要预测边界的字。若没有高质量短语词表,这些字都会被默认为Break,带来边界信息上的噪音,拿来给模型做监督会让表现下降。基于领域词典的远程监督标注能保证 非 Unknow 标签的正确,模型能够根据这些正确标签学到泛化的知识,迁移预测这些 Unknow 标签是 Tie 还是 Break。模型使用的是一个用 Highway network 优化的 BiLSTM 来做 span prediction。Highway network 的优势是能够让 BiLSTM 训练起来更容易。其讲解可以参照以下博客。https://zhuanlan.zhihu.com/p/38130339span model 会把序列标注好它的实体边界, 下游的 type model 就可以利用它来预测划定好边界实体的类别。它会对所有的字,包括 None 类型的标注字都预测类别。对于可能有多种类别的实体。type model 会对每一个可能的类型都计算交叉熵训练。预测时,会从这些候选类型中选出概率最高的。总结:这些笔记是近日工作上的汇总,把做 NER 的传统方法和机器学习方法都概括地过了一遍。重点在如何把词典信息融入模型和如何用领域词典去做远程监督上面。自然语言处理在工程上的实践要远大于理论。下一期会详解图神经网络在 NER 上的做法。Reference:
何晗. 2019.《自然语言处理入门》. 中国工信出版社
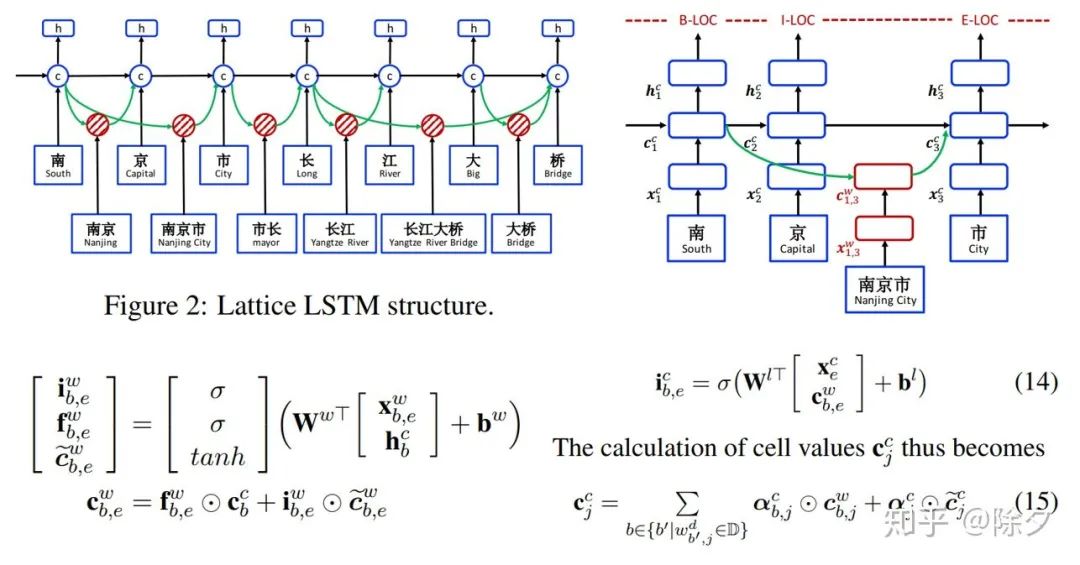
Yue Zhang and Jie Yang. 2018. Chinese ner using lattice lstm. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), 1554-1564.
Tao Gui, Ruotian Ma, Qi Zhang, Lujun Zhao, Yu-Gang Jiang, and Xuanjing Huang. Cnn-based chinese ner with lexicon rethinking.
Minlong Peng, Ruotian Ma, Qi Zhang, Xuanjing Huang. Simplify the Usage of Lexicon in Chinese NER.
Jingbo Shang, Liyuan Liu, Xiaotao Gu, Xiang Ren, Teng Ren, Jiawei Han. Learning Named Entity Tagger using Domain-Specific Dictionary.

 !
!

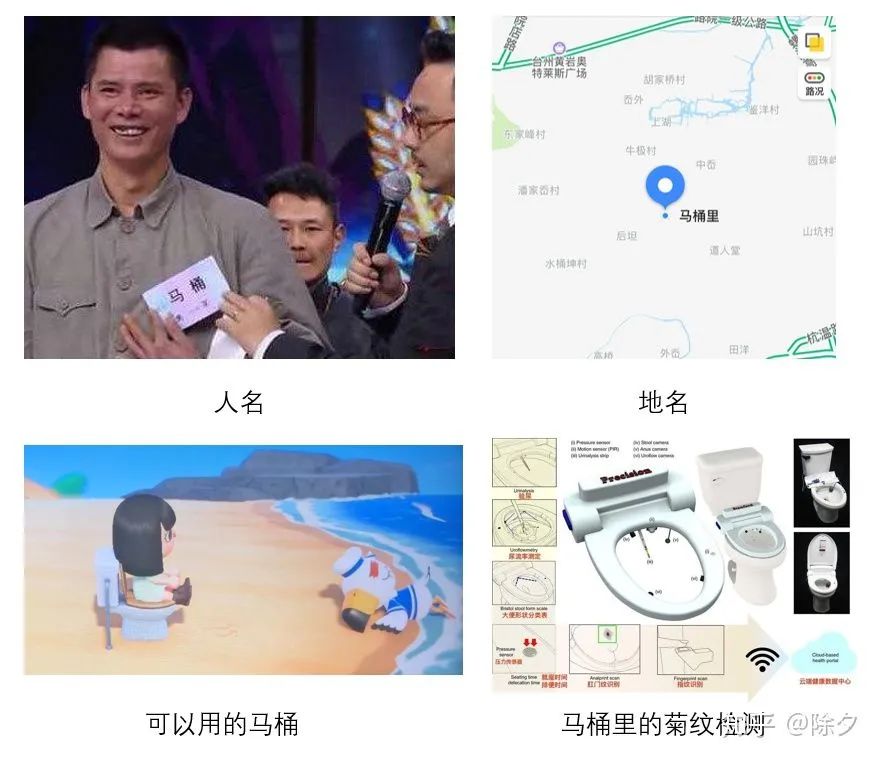

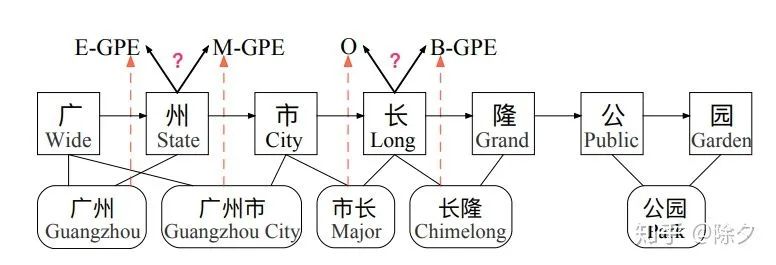
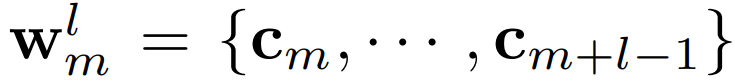
 = 马桶,
= 马桶,  =马桶里。
=马桶里。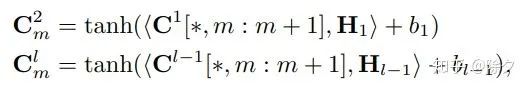
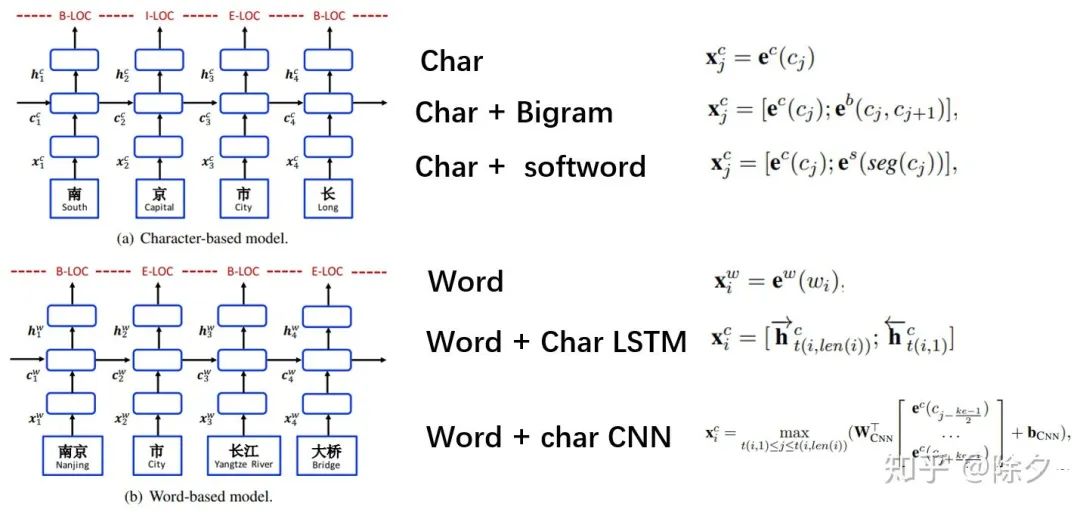
 ,而层层叠加起来的CNN也可以为每个字编码出一个l-gram的特征嵌入
,而层层叠加起来的CNN也可以为每个字编码出一个l-gram的特征嵌入  。为了能让词表特征更高效地融入,论文用了一个可并行计算的 Vector-based Attention,计算方式如下。
。为了能让词表特征更高效地融入,论文用了一个可并行计算的 Vector-based Attention,计算方式如下。