
干货 | tensorflow模型导出与OpenCV DNN中使用
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|OpenCV学堂
OpenCV DNN模块
Deep Neural Network - DNN 是OpenCV中的深度神经网络模块,支持基于深度学习模块前馈网络运行、实现图像与视频场景中的
图像分类
对象检测
图像分割
其模型导入与加载的相关API支持以下深度学习框架
tensorflow - readNetFromTensorflow
caffe - readNetFromCaffe
pytorch - readNetFromTorch
darknet - readNetFromDarknet
OpenCV3.4.1以上版本支持tensorflow1.11版本以上的对象检测框架(object detetion)模型导出使用,当前支持的模型包括以下:
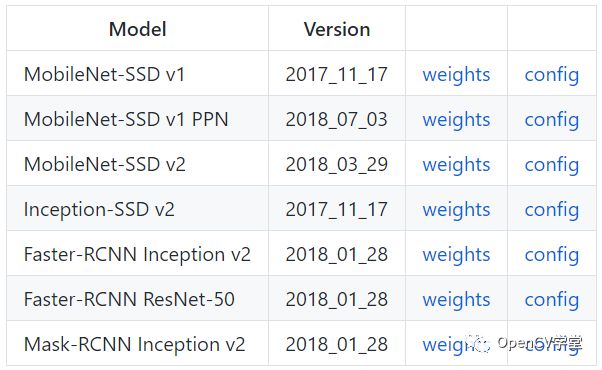
也就是说通过tensorflow object detection API框架进行迁移学习训练模型,导出预测图之后,可以通过OpenCV3.4.1以上版本提供几个python脚本导出graph配置文件,然后就可以在OpenCV DNN模块中使用tensorflow相关的模型了。感觉十分方便,下面就按照操作走一波!
使用tensorflow模型
根据tensorflow中迁移学习或者下载预训练模型不同,OpenCV DNN 模块提供如下可以使用脚本生成对应的模型配置文件
tf_text_graph_ssd.py
tf_text_graph_faster_rcnn.py
tf_text_graph_mask_rcnn.py
这是因为,OpenCV DNN需要根据text版本的模型描述文件来解析tensorflow的pb文件,实现网络模型加载。对SSD对象检测模型,生成模型描述文件运行以下命令行即可(在一行执行):
python tf_text_graph_ssd.py
--input /path/to/model.pb
--config /path/to/example.config
--output /path/to/graph.pbtxt
以MobileNet-SSD v2版本为例,首先下载该模型,解压缩以后会发现里面有一个frozen_inference_graph.pb文件,使用tensorflow加载预测图进行预测的代码如下:
import tensorflow as tf
import cv2 as cv
# Read the graph.
model_dir = 'D:/tensorflow/ssd_mobilenet_v2_coco_2018_03_29/frozen_inference_graph.pb'
with tf.gfile.FastGFile(model_dir, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Session() as sess:
# Restore session
sess.graph.as_default()
tf.import_graph_def(graph_def, name='')
# Read and preprocess an image.
img = cv.imread('D:/images/objects.jpg')
rows = img.shape[0]
cols = img.shape[1]
inp = cv.resize(img, (300, 300))
inp = inp[:, :, [2, 1, 0]] # BGR2RGB
# Run the model
out = sess.run([sess.graph.get_tensor_by_name('num_detections:0'),
sess.graph.get_tensor_by_name('detection_scores:0'),
sess.graph.get_tensor_by_name('detection_boxes:0'),
sess.graph.get_tensor_by_name('detection_classes:0')],
feed_dict={'image_tensor:0': inp.reshape(1, inp.shape[0], inp.shape[1], 3)})
# Visualize detected bounding boxes.
num_detections = int(out[0][0])
for i in range(num_detections):
classId = int(out[3][0][i])
score = float(out[1][0][i])
bbox = [float(v) for v in out[2][0][i]]
if score > 0.3:
x = bbox[1] * cols
y = bbox[0] * rows
right = bbox[3] * cols
bottom = bbox[2] * rows
cv.rectangle(img, (int(x), int(y)), (int(right), int(bottom)), (125, 255, 51), thickness=2)
cv.imshow('TensorFlow MobileNet-SSD', img)
cv.waitKey()
运行结果如下:

基于frozen_inference_graph.pb生成graph.pbtxt模型配置文件,命令行运行截图如下:
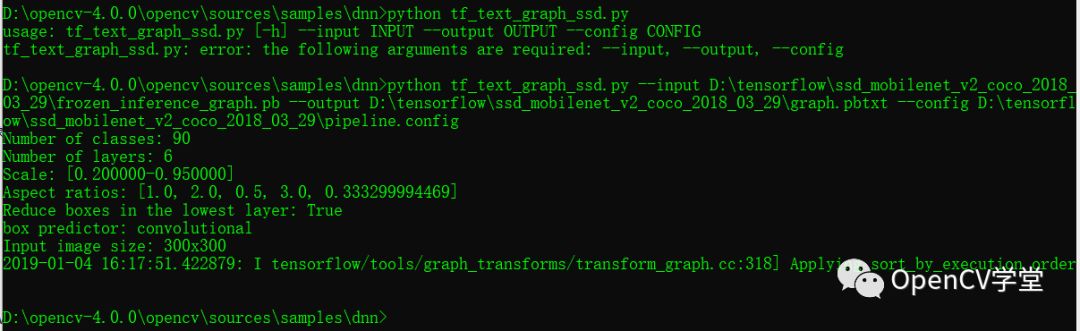
使用OpenCV DNN模块加载tensorflow模型(frozen_inference_graph.pb与graph.pbtxt),实现预测图使用的代码如下(注意此时不需要依赖tensorflow):
import cv2 as cv
model_path = 'D:/tensorflow/ssd_mobilenet_v2_coco_2018_03_29/frozen_inference_graph.pb'
config_path = 'D:/tensorflow/ssd_mobilenet_v2_coco_2018_03_29/graph.pbtxt'
net = cv.dnn.readNetFromTensorflow(model_path, config_path)
frame = cv.imread('D:/images/objects.jpg')
rows = frame.shape[0]
cols = frame.shape[1]
net.setInput(cv.dnn.blobFromImage(frame, size=(300, 300), swapRB=True, crop=False))
cvOut = net.forward()
print(cvOut)
for detection in cvOut[0,0,:,:]:
score = float(detection[2])
if score > 0.3:
left = detection[3] * cols
top = detection[4] * rows
right = detection[5] * cols
bottom = detection[6] * rows
cv.rectangle(frame, (int(left), int(top)), (int(right), int(bottom)), (23, 230, 210), thickness=2)
cv.imshow('opencv-dnn-ssd-detect', frame)
cv.waitKey()
运行结果如下(跟tensorflow中的运行结果完全一致,OpenCV DNN果然靠谱):
OpenCV DNN 行人检测
本人尝试了基于tensorflow object detection API使用MobileNet-SSD v2迁移学习实现自定义数据集训练,导出预测图之后,使用OpenCV DNN模块的python脚本生成对象的图配置文件graph.pbtxt,通过OpenCV加载模型使用,实时预测,最后上一张运行结果图:

OpenCV DNN调用代码如下
import cv2 as cv
inference_pb = "D:/pedestrian_data/export_pb/frozen_inference_graph.pb";
graph_text = "D:/pedestrian_data/export_pb/graph.pbtxt";
# load tensorflow model
net = cv.dnn.readNetFromTensorflow(inference_pb, graph_text)
image = cv.imread("D:/python/Pedestrian-Detection/test_images/3600.jpg")
h = image.shape[0]
w = image.shape[1]
# 获得所有层名称与索引
layerNames = net.getLayerNames()
lastLayerId = net.getLayerId(layerNames[-1])
lastLayer = net.getLayer(lastLayerId)
print(lastLayer.type)
# 检测
net.setInput(cv.dnn.blobFromImage(image, size=(300, 300), swapRB=True, crop=False))
cvOut = net.forward()
for detection in cvOut[0,0,:,:]:
score = float(detection[2])
if score > 0.5:
left = detection[3]*w
top = detection[4]*h
right = detection[5]*w
bottom = detection[6]*h
# 绘制
cv.rectangle(image, (int(left), int(top)), (int(right), int(bottom)), (0, 255, 0), thickness=2)
cv.putText(image, "Pedestrian", (int(left), int(top-10)), cv.FONT_HERSHEY_PLAIN, 1.0, (0, 0, 255), 1)
cv.imshow('pedestrain_demo', image)
cv.imwrite("D:/Pedestrian.png", image)
cv.waitKey(0)
cv.destroyAllWindows()
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~