
分割冠军 | 超越Swin v2、PvT v2等模型,ViT-Adaptiver实现ADE20K冠军60.5mIoU

与最近将视觉特定的归纳偏差引入
Vision Transformer架构不同,ViT由于缺乏图像的先验信息,在密集预测任务上的性能较差。为了解决这个问题,本文提出了一种Vision Transformer适配器(ViT-Adapter),ViT-Adapter可以通过额外的架构引入归纳偏差来弥补ViT的缺陷并实现与视觉特定模型相当的性能。具体来说,
ViT-Adapter中的Backbone是一个普通的Transformer,可以用多模态数据进行预训练。在对下游任务进行微调时,使用特定于模态的适配器将数据和任务的先验信息引入模型,使其适用于这些任务。作者验证了
ViT-Adapter在多个下游任务上的有效性,包括目标检测、实例分割和语义分割。尤其,使用HTC++时,ViT-Adapter-L得到了60.1 和52.1 ,在COCO test-dev上,超过 Swin-L 1.4 和1.0 。对于语义分割,ViT-Adapter-L在ADE20K val上建立了一个新的mIoU 60.5%,比SwinV2-G高0.6%。开源地址:https://github.com/czczup/ViT-Adapter
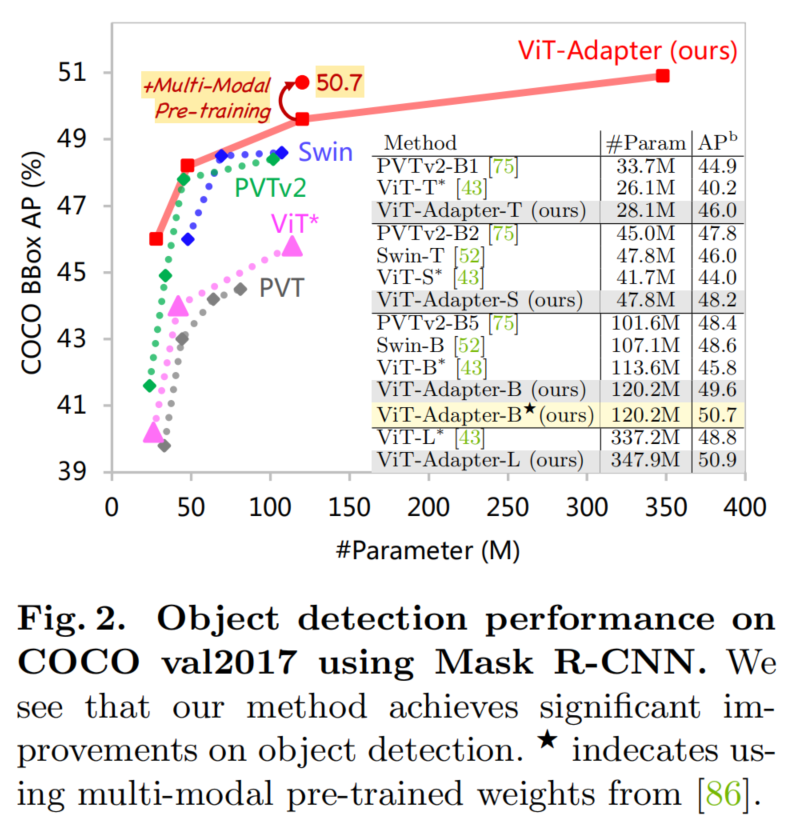
1本文方法
话不多说先对比
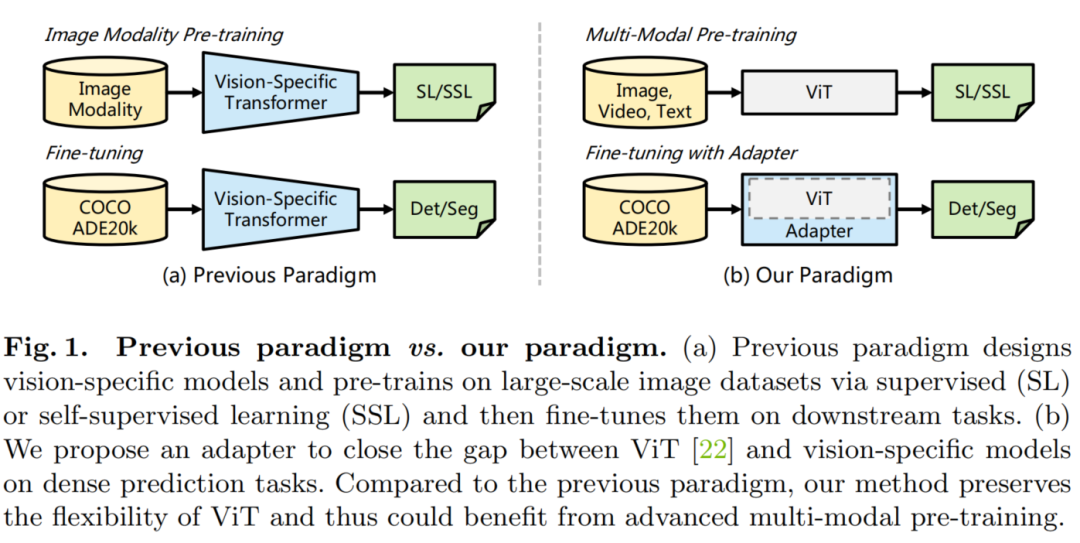
如图 1 所示,与之前对大规模图像数据集(例如ImageNet)进行预训练和对不同任务进行微调的范式相比,本文的范式更加灵活。在ViT-Adapter框架中,Backbone网络是一个通用模型(例如,ViT),可以使用多模态数据和任务进行预训练。当将其应用于下游任务时,视觉专用适配器将输入数据和任务的先验信息引入到通用Backbone网络之中,使模型适用于下游任务。通过这种方式,使用ViT作为Backbone,ViT-Adapter框架实现了与专为密集预测任务设计的Transformer Backbone(如Swin Transformer)相当甚至更好的性能。
方法总览
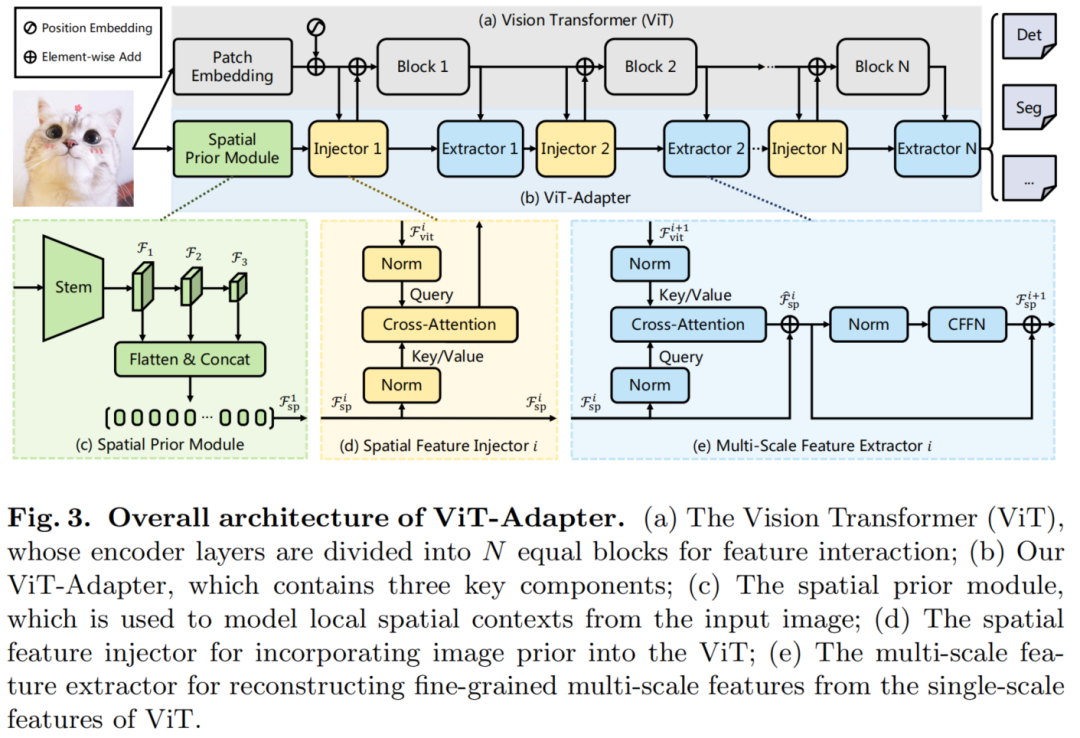
如图3所示,ViT-Adapter模型可以分为2部分。
第1部分是 Backbone(即ViT):它由1个Patch Embedding和L个Transformer Encoder层组成(见图3(a))。第2部分是提出的 ViT-Adapter:如图3(b)所示,它包含1个Spatial prior module,用于从输入图像中捕获空间特征,1个Spatial Feature injector,用于将空间先验注入到ViT中,以及1个多尺度特征提取器,用于从ViT中提取分层特征。
对于ViT,首先将输入图像输入Patch Embedding,将图像分成16×16个不重叠的Patch。在此之后,这些Patch被Flatten并投影到d维Embedding中。这里的特征分辨率降低到原始图像的1/16。最后,嵌入的Patch被和位置嵌入通过ViT的L编码器层。
对于ViT-Adapter,首先将输入图像输入到Spatial prior module中。将收集3种目标分辨率(即1/8、1/16和1/32)的d维空间特征。然后,这些特征映射被Flatten并连接起来,作为特征交互的输入。
具体来说,给定交互时间N,将
ViT的Transforer编码器均匀地分割成N个Blocks,每个Block包含L/N编码器层。对于第i个Block,首先通过Spatial Feature injector将空间先验注入到Block中,然后通过多尺度特征提取器从Block的输出中提取层次特征。经过N个特征交互后,获得了高质量的多尺度特征,然后将特征分割并reshape为3个目标分辨率1/8、1/16和1/32。最后,通过2×2的转置卷积对1/8尺度的特征图进行上采样,得到了1/4尺度的特征图。
通过这种方法,得到了一个与ResNet分辨率相似的特征金字塔,它可以用于各种密集的预测任务。
Spatial Prior Module
最近的工作表明具有重叠滑动窗口的卷积可以帮助Transforer更好地捕捉输入图像的局部连续性。受此启发,作者在ViT中引入了一个基于卷积的Spatial prior module,它通过一个stem和3个卷积将H×W输入图像下采样到不同的尺度。该模块旨在模拟与Patch Embedding平行的图像的局部空间上下文,以免改变ViT的原始架构。
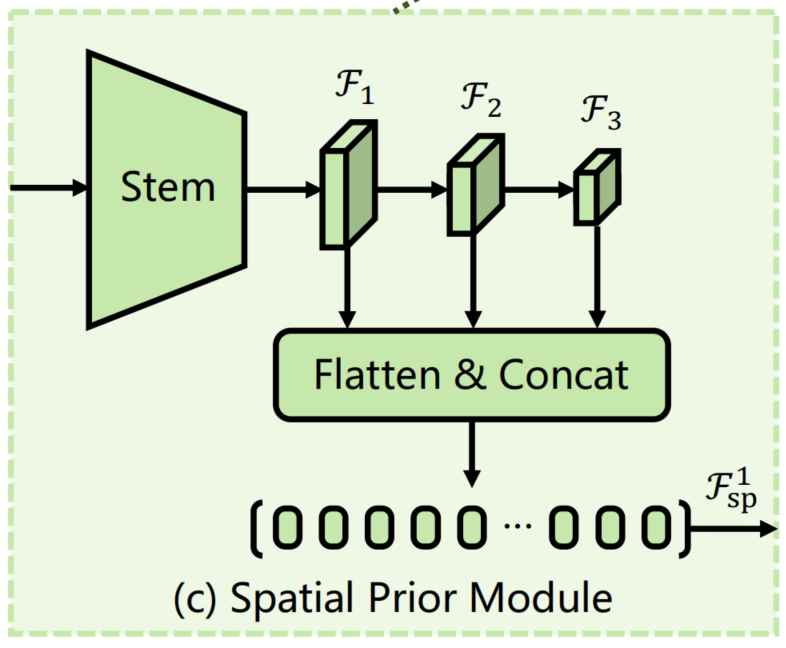
如图3(c)所示,采用了1个借鉴于ResNet的标准卷积stem,它由3个卷积层和一个最大池化层组成。接下来,使用一个步长为2的3×3卷积堆栈构成了该模块的其余部分,它使通道数量增加了一倍并减小了特征图的大小。
最后,在最后采用几个1×1卷积将特征映射投影到D维。通过这种方法,可以得到了1个特征金字塔,它包含了分辨率分别为1/8、1/16和1/32的D维特征图。最后,将这些特征映射Flatten+Concat到特征token 中,作为以后Feature Interaction的输入。
Feature Interaction
由于柱状结构,ViT中的特征图是单尺度和低分辨率的,与金字塔结构的Transformer相比,ViT对于密集预测任务的性能是次优的。为了缓解这个问题,作者提出了2个特征交互模块,在适配器和ViT之间传递特征映射。
具体来说,这2个模块分别是基于Cross-Attention的Spatial Feature Injector和Multi-Scale Feature Extractor。
如前面所述,将基于ViT的Transformer编码器划分为N个相等的Blocks,并分别在每个Block之前和之后应用所提出的2个算子。
1、Spatial Feature Injector
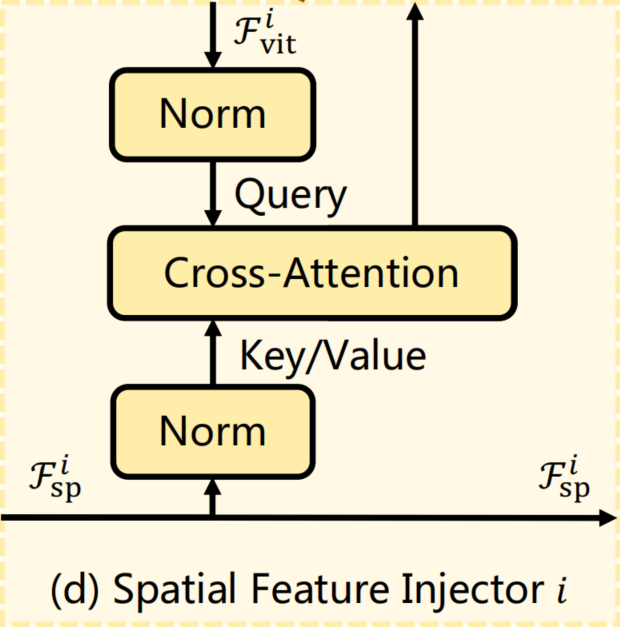
如图3(d)所示,该模块用于将空间先验注入ViT。具体来说,对于Transformer的第i个Block,将以输入特征作为query,空间特征作为key和value。使用Cross-Attention将空间特征注入到输入特征中,该过程通过数学表达式可以表示为:
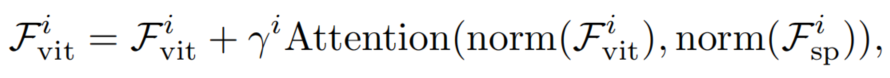
其中归一化层为LayerNorm,注意层的注意力机制是可选的。这里为了降低计算代价,采用了一种具有线性复杂度的可变形注意力来实现注意力层。
此外,应用一个可学习的向量来平衡注意力层的输出和输入特征,它被初始化为0。这种初始化策略确保了的特征分布不会由于空间先验的注入而被大幅修改,从而更好地利用了预训练后的ViT权值。
2、Multi-Scale Feature Extractor
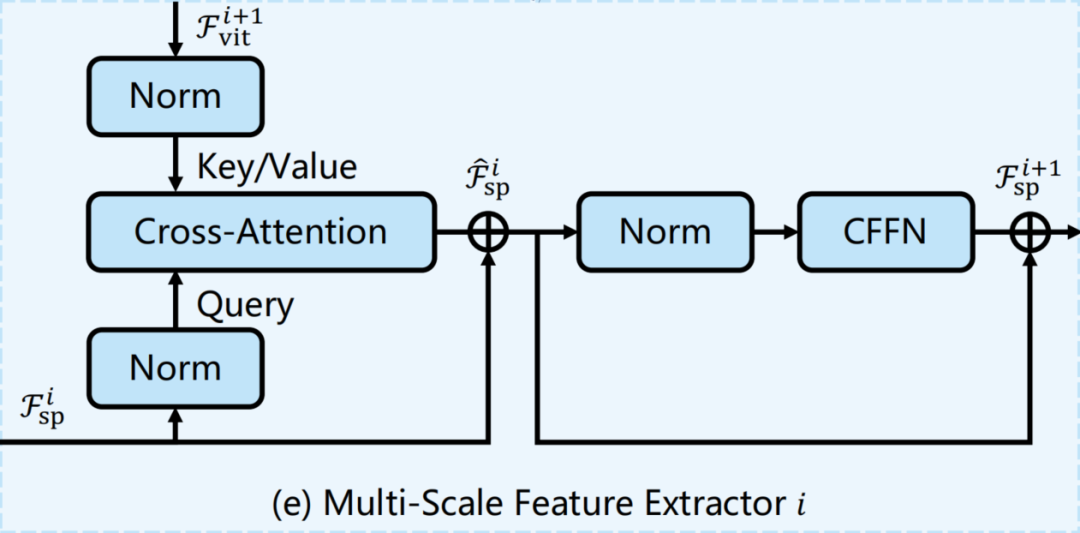
在将空间先验注入ViT后,通过的编码器层获得输出特征。这样便可以交换ViT特征和空间特征的作用。也就是说,采用空间特征作为query,输出特征作为key和value。然后再次通过Cross-Attention来交互这2个特征,过程可以被定义为:
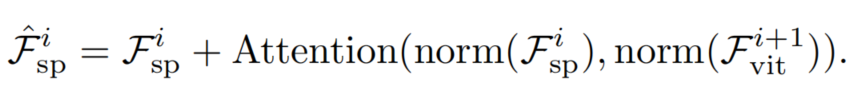
与Spatial Feature Injector一样,在这里使用可变形注意力来降低计算成本。此外,为了弥补固定大小位置嵌入的缺陷,在Cross-Attention之后引入卷积前馈网络(CFFN)。考虑到效率并将CFFN的比率设置为1/4。CFFN层通过带有0填充的深度卷积来增强特征的局部连续性,具体可以表示为:

其中,新的空间特征将被用作下一个Block中特征交互的输入。
Architecture Configurations
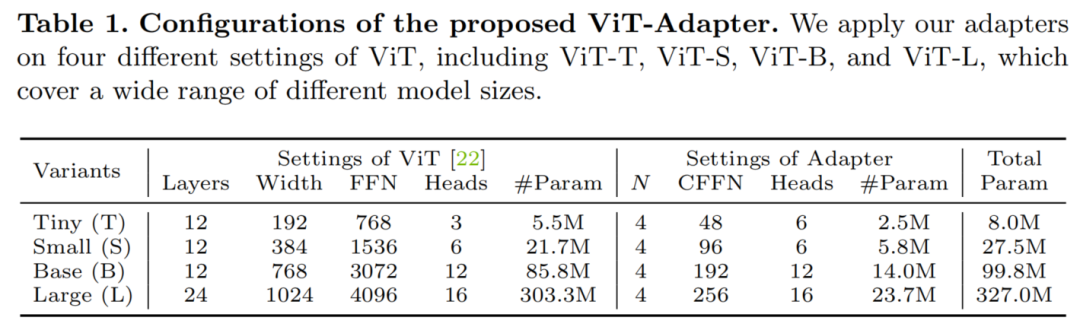
本文为4种不同的ViT变体构建了ViT-Adapter,包括ViT-T、ViT-S、ViT-B和ViT-L。对于这些模型,ViT-Adapter的参数数分别为2.5M、5.8M、14.0M和23.7M。每种配置的细节如表1所示。
2实验
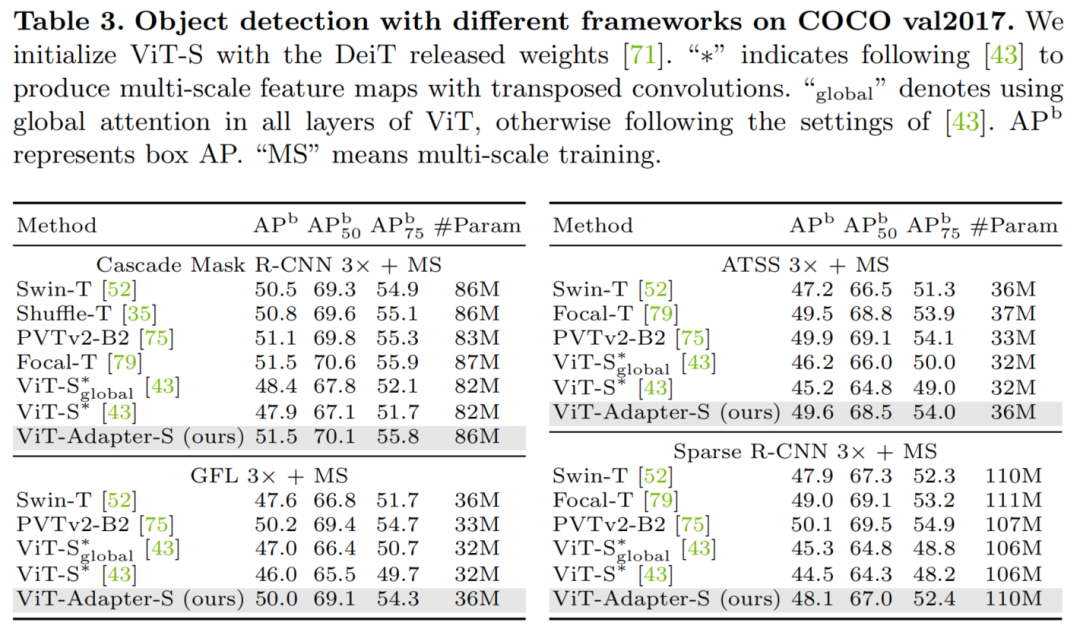
目标检测
实例分割

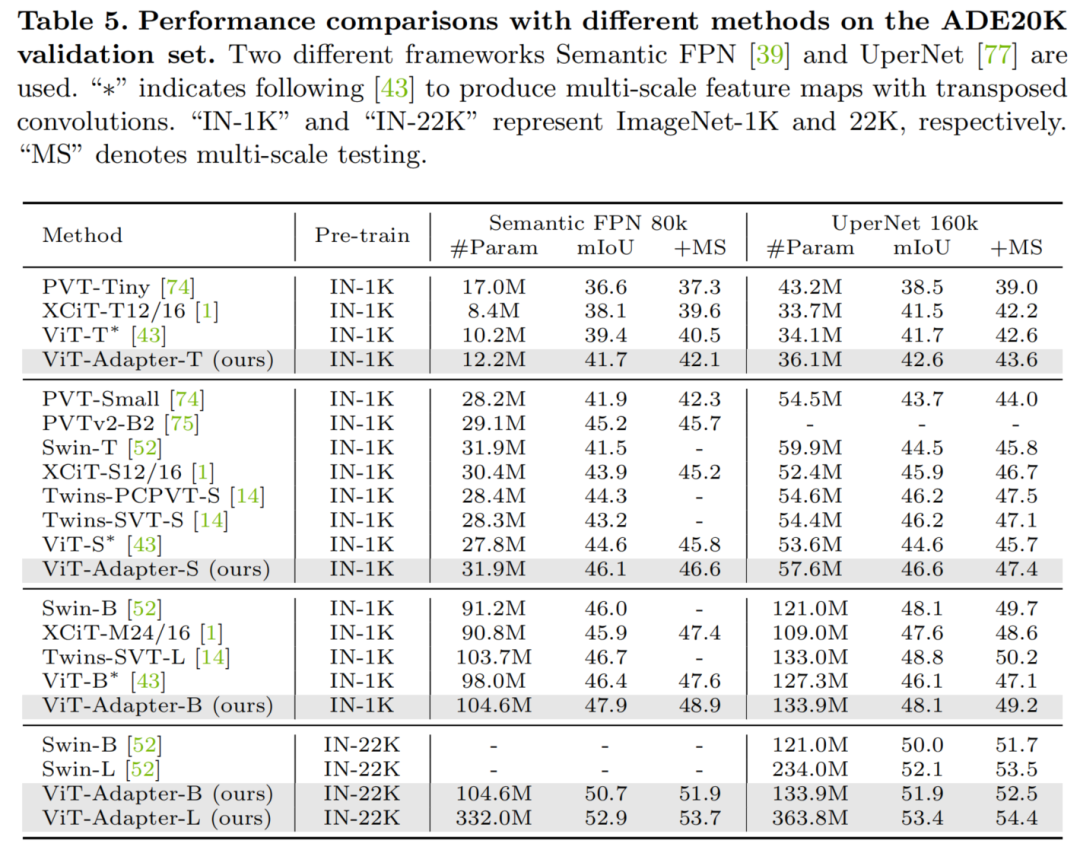
语义分割
可视化结果

3参考
[1].Vision Transformer Adapter for Dense Predictions
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
