
python基础篇大合集,进程、装饰器、列表详解篇!

进程以及状态
1. 进程
2. 进程的状态
进程的创建-multiprocessing
1. 创建进程
2. 进程pid
3. Process语法结构如下
4. 给子进程指定的函数传递参数
5. 进程间不共享全局变量
进程和线程对比
功能
定义的不同
区别
优缺点
进程以及状态
1. 进程
程序:例如xxx.py这是程序,是一个静态的
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
不仅可以通过线程完成多任务,进程也是可以的
2. 进程的状态
工作中,任务数往往大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致了有了不同的状态。
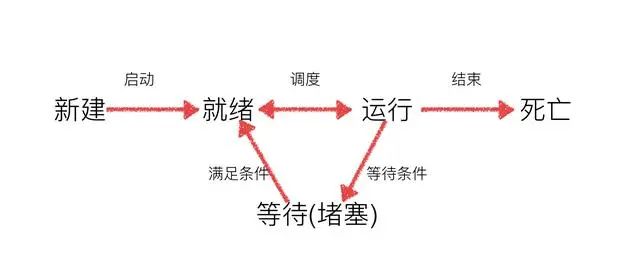
就绪态:运行的条件都已经满足,正在等在cpu执行
执行态:cpu正在执行其功能
等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
进程的创建-multiprocessing
multiprocessing模块就是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情
1. 创建进程
import multiprocessing
import time
def test():
while True:
print("--test--")
time.sleep(1)
if __name__ == "__main__":
p = multiprocessing.Process(target=test)
p.start()
while True:
print("--main--")
time.sleep(1)
说明:
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动
2. 进程pid
import multiprocessing
import os
def test():
print("子进程在运行,pid=%d" % (os.getpid()))
print("子进程运行结束")
if __name__ == "__main__":
print("父进程在运行,pid=%d" % (os.getpid()))
p = multiprocessing.Process(target=test)
p.start()
通过os中的getpid()方法能获取到当前运行进程的id。
3. Process语法结构如下
Process([group [, target [, name [, args [, kwargs]]]]])
target:如果传递了函数的引用,可以认为这个子进程就执行这里的代码
args:给target指定的函数传递的参数,以元组的方式传递
kwargs:给target指定的函数传递命名参数
name:给进程设定一个名字,可以不设定
group:指定进程组,大多数情况下用不到
Process创建的实例对象的常用方法:
start():启动子进程实例(创建子进程)
is_alive():判断进程子进程是否还在活着
join([timeout]):是否等待子进程执行结束,或等待多少秒
terminate():不管任务是否完成,立即终止子进程
Process创建的实例对象的常用属性:
name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
pid:当前进程的pid(进程号)
4. 给子进程指定的函数传递参数
import multiprocessing
import os
import time
def test(name, **kwargs):
for i in range(10):
print("子进程在运行,name=%s, pid=%d" % (name, os.getpid()))
print(kwargs)
time.sleep(0.2)
if __name__ == "__main__":
p = multiprocessing.Process(target=test, args=("zhangsan",), kwargs={"xxoo": 666})
p.start()
time.sleep(1)
p.terminate()
p.join()
运行结果:
子进程在运行,name=zhangsan, pid=37751
{'xxoo': 666}
子进程在运行,name=zhangsan, pid=37751
{'xxoo': 666}
子进程在运行,name=zhangsan, pid=37751
{'xxoo': 666}
子进程在运行,name=zhangsan, pid=37751
{'xxoo': 666}
子进程在运行,name=zhangsan, pid=37751
{'xxoo': 666}
5. 进程间不共享全局变量
import multiprocessing
import os
import time
g_nums = [11, 33]
def test1():
"""子进程要执行的代码"""
print("in test1, pid=%d, g_nums=%s", (os.getpid(), g_nums))
for i in range(4):
g_nums.append(i)
time.sleep(1)
print("in test1, pid=%d, g_nums=%s", (os.getpid(), g_nums))
def test2():
"""子进程要执行的代码"""
print("in test2, pid=%d, g_nums=%s", (os.getpid(), g_nums))
if __name__ == "__main__":
p1 = multiprocessing.Process(target=test1)
p1.start()
p1.join()
p2 = multiprocessing.Process(target=test2)
p2.start()
运行结果:
in test1, pid=%d, g_nums=%s (37947, [11, 33])
in test1, pid=%d, g_nums=%s (37947, [11, 33, 0])
in test1, pid=%d, g_nums=%s (37947, [11, 33, 0, 1])
in test1, pid=%d, g_nums=%s (37947, [11, 33, 0, 1, 2])
in test1, pid=%d, g_nums=%s (37947, [11, 33, 0, 1, 2, 3])
in test2, pid=%d, g_nums=%s (37948, [11, 33])
进程和线程对比
功能
进程,能够完成多任务,比如 在一台电脑上能够同时运行多个QQ
线程,能够完成多任务,比如 一个QQ中的多个聊天窗口
定义的不同
进程是系统进行资源分配和调度的一个独立单位.
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
区别
一个程序至少有一个进程,一个进程至少有一个线程.
线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
线程不能够独立执行,必须依存在进程中
可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
优缺点
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
开闭原则:
在不修改原函数及其调用方式的情况下对原函数功能进行扩展
对代码的修改是封闭
不能修改被装饰的函数的源代码
不能修改被装饰的函数的调用方式
用函数的方式设想一下游戏里用枪的场景
1 def game():
2 print('压子弹')
3 print('枪上膛')
4 print('发射子弹')
5 game()
6 game()
7 game()
8
9 此时需要给枪增加一个瞄准镜,比如狙击远程目标时候需要加,狙击近程目标不用加
10 此时上边的代码就变成了现在的代码
11
12 def sight():
13 print('专业狙击瞄准镜')
14 game()
15 sight()
16 sight()
17 sight()
18 此时的设计就不符合开闭原则(因为修改了原代码及调用名称)
装饰器(python里面的动态代理)
本质: 是一个闭包
组成: 函数+实参高阶函数+返回值高阶函数+嵌套函数+语法糖 = 装饰器
存在的意义: 在不破坏原有函数和原有函数调用的基础上,给函数添加新的功能
通用装饰器写法:
1 def warpper(fn): # fn是目标函数相当于func
2 def inner(*args,**kwargs): # 为目标函数的传参
3 '''在执行目标函数之前操作'''
4 ret = fn(*args,**kwargs) # 调用目标函数,ret是目标函数的返回值
5 '''在执行目标函数之后操作'''
6 return ret # 把目标函数返回值返回,保证函数正常的结束
7 return inner
8
9 #语法糖
10 @warpper #相当于func = warpper(func)
11 def func():
12 pass
13 func() #此时就是执行的inner函数
上边的场景用装饰器修改后
1 方式一
2 def game():
3 print('压子弹')
4 print('枪上膛')
5 print('发射子弹')
6
7 def sight(fn): # fn接收的是一个函数
8 def inner():
9 print('安装专业狙击瞄准镜')
10 fn() #调用传递进来的函数
11 print('跑路')
12 return inner #返回函数地址
13
14 game = sight(game) #传递game函数到sight函数中
15 game()
16
17 执行步骤
18 第一步定义两个函数game()为普通函数,sight()为装饰器函数
19 第二步定义game = sight(game)等于把game函数当做参数传递给sight(fn)装饰器函数fn形参
20 第三步执行sight(fn),fn在形参位置,相当于下边函数game()传参过来等于fn
21 第四步执行inner函数,然后return把inner函数内存地址当做返回值返回给sight(game)
22 第五步然后执行game(),相当于执行inner函数
23 第六步,执行inner函数,打印'狙击镜',执行fn()形参,由于fn形参等于game函数,所以执行game()函数,打印'压子弹','上膛','发射子弹'
24 第七步打印'跑路'
25 第八步把打印的结果返回给game()
26
27 方式二
28 def sight(fn): # fn接收的是一个函数
29 def inner():
30 print('安装专业狙击瞄准镜')
31 fn() #调用传递进来的函数
32 print('跑路')
33 return inner #返回函数地址
34
35 @sight #相当于game = sight(game)
36 def game():
37 print('压子弹')
38 print('枪上膛')
39 print('发射子弹')
40 game()
41
42 执行步骤
43 第一步执行sight(fn)函数
44 第二步执行@sight,相当于把把game函数与sight装饰器做关联
45 第三步把game函数当做参数传递给sight(fn)装饰器函数fn形参
46 第四步执行inner函数,然后return把inner函数内存地址当做返回值返回给@sight
47 第五步执行game()相当相当于执行inner()函数,因为@sight相当于game = sight(game)
48 第六步打印'瞄准镜
49 第七步执行fn函数,因为fn等于game函数,所以会执行game()函数,打印'压子弹','上膛','发射子弹'.fn()函数执行完毕
50 第八步打印'跑路'
51 第九步然后把所有打印的结果返回给game()
52
53 结果
54 安装专业狙击瞄准镜
55 压子弹
56 枪上膛
57 发射子弹
58 跑路
一个简单的装饰器实现
1 def warpper(fn):
2 def inner():
3 print('每次执行被装饰函数之前都要先经过这里')
4 fn()
5 return inner
6 @warpper
7 def func():
8 print('执行了func函数')
9 func()
10
11 结果
12 每次执行被装饰函数之前都要先经过这里
13 执行了func函数
带有一个或多个参数的装饰器
1 def sight(fn): #fn等于调用game函数
2 def inner(*args,**kwargs): #接受到的是元组("bob",123)
3 print('开始游戏')
4 fn(*args,**kwargs) #接受到的所有参数,打散传递给user,pwd
5 print('跑路')
6 return inner
7 @sight
8 def game(user,pwd):
9 print('登陆游戏用户名密码:',user,pwd)
10 print('压子弹')
11 print('枪上膛')
12 print('发射子弹')
13 game('bob','123')
14 结果
15 开始游戏
16 登陆游戏用户名密码: bob 123
17 压子弹
18 枪上膛
19 发射子弹
20 跑路
动态传递一个或多个参数给装饰器
1 def sight(fn): #调用game函数
2 def inner(*args,**kwargs): #接受到的是元组("bob",123)
3 print('开始游戏')
4 fn(*args,**kwargs) #接受到的所有参数,打散传递给正常的参数
5 print('跑路')
6 return inner
7 @sight
8 def game(user,pwd):
9 print('登陆游戏用户名密码:',user,pwd)
10 print('压子弹')
11 print('枪上膛')
12 print('发射子弹')
13 return '游戏展示完毕'
14 ret = game('bob','123') #传递了两个参数给装饰器sight
15 print(ret)
16
17 @sight
18 def car(qq):
19 print('登陆QQ号%s'%qq)
20 print('开始战车游戏')
21 ret2 = car(110110) #传递了一个参数给装饰器sight
22 print(ret2)
23 结果
24 开始游戏
25 登陆游戏用户名密码: bob 123
26 压子弹
27 枪上膛
28 发射子弹
29 跑路
30 None
31 开始游戏
32 登陆QQ号110110
33 开始战车游戏
34 跑路
35 None
36 你会发现这两个函数执行的返回值都为None,但是我game定义返回值了return '游戏展示完毕',却没给返回
装饰器的返回值
1 为什么我定义了返回值,但是返回值还是None呢,是因为我即使在game函数中定义了return '游戏展示完毕'
2 但是装饰器里只有一个return inner定义返回值,但是这个返回值是返回的inner函数的内存地址的,并不是inner
3 函数内部的return所以默认为None,所以应该定义一个inner函数内部的return返回值,而且也没有接收返回值的变量,
4 所以要要设置ret = fn(*args,**kwargs)和return ret
5
6 def sight(fn): #调用game函数
7 def inner(*args,**kwargs): #接受到的是元组("bob",123)
8 print('开始游戏')
9 ret = fn(*args,**kwargs) #接受到的所有参数,打散传递给正常的参数
10 print('跑路')
11 return ret
12 return inner
13 @sight
14 def game(user,pwd):
15 print('登陆游戏用户名密码:',user,pwd)
16 print('压子弹')
17 print('枪上膛')
18 print('发射子弹')
19 return '游戏展示完毕'
20 ret = game('bob','123') #传递了两个参数给装饰器sight
21 print(ret)
22 结果
23 开始游戏
24 登陆游戏用户名密码: bob 123
25 压子弹
26 枪上膛
27 发射子弹
28 跑路
29 游戏展示完毕
30
31
32 事例2
33 def wrapper_out(flag): #装饰器本身的参数
34 def wrapper(fn): #目标函数
35 def inner(*args,**kwargs): #目标函数需要接受的参数
36 if flag == True:
37 print('找第三方问问价格行情')
38 ret = fn(*args,**kwargs)
39 print('买到装备')
40 return ret
41 else:
42 ret = fn(*args,**kwargs)
43 return ret
44 return inner
45 return wrapper
46 #语法糖,@装饰器
47 @wrapper_out(True)
48 def func(a,b): #被wrapper装饰
49 print(a,b)
50 print('开黑')
51 return 'func返回值'
52 abc = func('我是参数1','我是参数2')
53 print(abc)
54 结果
55 找第三方问问价格行情
56 我是参数1 我是参数2
57 开黑
58 买到装备
59 func返回值
多个装饰器同用一个函数
1 def wrapper1(fn):
2 def inner(*args,**kwargs):
3 print('wrapper1-1')
4 ret = fn(*args,**kwargs)
5 print('wrapper1-2')
6 return ret
7 return inner
8
9 def wrapper2(fn):
10 def inner(*args,**kwargs):
11 print('wrapper2-1')
12 ret = fn(*args,**kwargs)
13 print('wrapper2-2')
14 return ret
15 return inner
16
17 def wrapper3(fn):
18 def inner(*args,**kwargs):
19 print('wrapper3-1')
20 ret = fn(*args,**kwargs)
21 print('wrapper3-2')
22 return ret
23 return inner
24 @wrapper1
25 @wrapper2
26 @wrapper3
27 def func():
28 print('我是测试小白')
29 func()
30 结果
31 wrapper1-1
32 wrapper2-1
33 wrapper3-1
34 我是测试小白
35 wrapper3-2
36 wrapper2-2
37 wrapper1-2
python列表类型
分类: python
列表类型简介
列表类型是一个容器,它里面可以存放任意数量、任意类型的数据。
例如下面的几个列表中,有存储数值的、字符串的、内嵌列表的。不仅如此,还可以存储其他任意类型。
>>> L = [1, 2, 3, 4]
>>> L = ["a", "b", "c", "d"]
>>> L = [1, 2, "c", "d"]
>>> L = [[1, 2, 3], "a", "b", [4, "c"]]
python中的列表是一个序列,其内元素是按索引顺序进行存储的,可以进行索引取值、切片等操作。
列表结构
列表是可变对象,可以原处修改列表中的元素而不会让列表有任何元数据的变动。
>>> L = ["a", "b", "c"]
>>> id(L), id(L[0])
(57028736, 55712192)
>>> L[0] = "aa"
>>> id(L), id(L[0])
(57028736, 56954784)
从id的变动上看,修改列表的第一个元素时,列表本身的id没有改变,但列表的第一个元素的id已经改变。
看了下面列表的内存图示就很容易理解了。
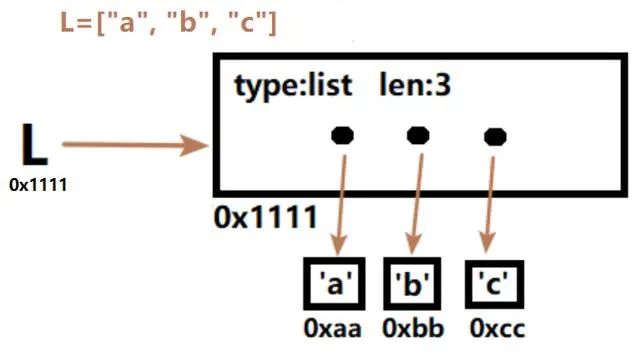
上面是L = ["a", "b", "c"]列表的图示。变量名L存储了列表的内存地址,列表内部包含了类型声明、列表长度等元数据,还保存了属于列表的3个元素的内存地址。需要注意的是,列表元素不是直接存在列表范围内的,而是以地址的形式保存在列表中。
所以,修改列表中的元素时,新建一个元素"aa"(之所以新建,是因为字符串是不可变类型),列表本身并没有改变,只是将列表中指向第一个元素的地址改为新数据"aa"的地址。
因为修改列表数据不会改变列表本身属性,这种行为称为"原处修改"。
所以,列表有几个主要的的特性:
列表中可以存放、嵌套任意类型的数据
列表中存放的是元素的引用,也就是各元素的地址,因此是列表可变对象
列表是可变序列。所以各元素是有位置顺序的,可以通过索引取值,可以通过切片取子列表
构造列表
有两种常用的构造列表方式:
使用中括号[]
使用list()构造方法
使用(中)括号构建列表时,列表的元素可以跨行书写,这是python语法中各种括号类型的特性。
例如:
>>> [1,2,3]
[1, 2, 3]
>>> L = [
1,
2,
3
]
>>> list('abcde')
['a', 'b', 'c', 'd', 'e']
>>> list(range(0, 4))
[0, 1, 2, 3]
上面range()用于生成一系列数值,就像Linux下的seq命令一样。但是range()不会直接将数据生成出来,它返回的是一个可迭代对象,表示可以一个一个地生成这些数据,所以这里使用list()将range()的数据全部生成出来并形成列表。
中括号方式构造列表有一个很重要的特性:列表解析,很多地方也称为"列表推到"。例如:
>>> [x for x in 'abcdef']
['a', 'b', 'c', 'd', 'e', 'f']
list()是直接将所给定的数据一次性全部构造出来,直接在内存中存放整个列表对象。列表推导方式构造列表比list()要快,且性能差距还挺大的。
列表基本操作
列表支持+ *符号操作:
>>> L = [1,2,3,4]
>>> L1 = ['a','b','c']
>>> L + L1
[1, 2, 3, 4, 'a', 'b', 'c']
>>> [1,2] + list("34")
[1, 2, '3', '4']
>>> L * 2
[1, 2, 3, 4, 1, 2, 3, 4]
>>> 2 * L
[1, 2, 3, 4, 1, 2, 3, 4]
可以通过+=的方式进行二元赋值:
>>> L1 = [1,2,3,4]
>>> L2= [5,6,7,8]
>>> L1 += L2
>>> L1
[1, 2, 3, 4, 5, 6, 7, 8]
L1 += L2的赋值方式对于可变序列来说(比如这里的列表),性能要好于L1 = L1 + L2的方式。前者直接在L1的原始地址内进行修改,后者新创建一个列表对象并拷贝原始L1列表。但实际上,性能的差距是微乎其微的,前面说过列表中保存的是元素的引用,所以拷贝也仅仅只是拷贝一些引用,而非实际数据对象。
列表是序列,序列类型的每个元素都是按索引位置进行存放的,所以可以通过索引的方式取得列表元素:
>>> L = [1,2,3,4,5]
>>> L[0]
1
>>> L = [
... [1,2,3,4],
... [11,22,33,44],
... [111,222,333,444]
... ]
>>> L[0][2]
3
>>> L[1][2]
33
>>> L[2][2]
333
当然,也可以按索引的方式给给定元素赋值,从而修改列表:
>>> L = [1,2,3,4,5]
>>> L[0] = 11
通过赋值方式修改列表元素时,不仅可以单元素赋值修改,还可以多元素切片赋值。
>>> L[1:3] = [22,33,44,55]
>>> L
[11, 22, 33, 44, 55, 4, 5]
上面对列表的切片进行赋值时,实际上是先取得这些元素,删除它们,并插入新数据的过程。所以上面是先删除[1:3]的元素,再在这个位置处插入新的列表数据。
所以,如果将某个切片赋值为空列表,则表示直接删除这个元素或这段范围的元素。
>>> L
[11, 22, 33, 44]
>>> L[1:3] = []
>>> L
[11, 44]
但如果是将空列表赋值给单个索引元素,这不是表示删除元素,而是表示将空列表作为元素嵌套在列表中。
>>> L = [1,2,3,4]
>>> L[0] = []
>>> L
[[], 2, 3, 4]
这两种列表赋值的区别,在理解了前文所说的列表结构之后应该不难理顺。
列表其它操作
列表是一种序列,所以关于序列的操作,列表都可以用,比如索引、切片、各种序列可用的函数(比如append()、extend()、remove()、del、copy()、pop()、reverse())等。详细内容参见:python序列操作
除了这些序列通用操作,列表还有一个专门的列表方法sort,用于给列表排序。
列表排序sort()和sorted()
sort()是列表类型的方法,只适用于列表;sorted()是内置函数,支持各种容器类型。它们都可以排序,且用法类似,但sort()是在原地排序的,不会返回排序后的列表,而sorted()是返回新的排序列表。
>>> help(list.sort)
Help on method_descriptor:
sort(...)
L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE*
>>> help(sorted)
Help on built-in function sorted in module builtins:
sorted(iterable, /, *, key=None, reverse=False)
Return a new list containing all items from the iterable in ascending order.
A custom key function can be supplied to customize the sort order, and the
reverse flag can be set to request the result in descending order.
本文仅简单介绍排序用法。
例如列表L:
>>> L = ['python', 'shell', 'Perl', 'Go', 'PHP']
使用sort()和sorted()排序L,注意sort()是对L直接原地排序的,不是通过返回值来体现排序结果的,所以无需赋值给变量。而sorted()则是返回排序后的新结果,需要赋值给变量才能保存排序结果。
>>> sorted(L)
['Go', 'PHP', 'Perl', 'python', 'shell']
>>> L
['python', 'shell', 'Perl', 'Go', 'PHP']
>>> L.sort()
>>> L
['Go', 'PHP', 'Perl', 'python', 'shell']
不难发现,sort()和sorted()默认都是升序排序的(A
>>> L.sort(reverse=True)
>>> L
['shell', 'python', 'Perl', 'PHP', 'Go']
在python 3.x中,sort()和sorted()不允许对包含不同数据类型的列表进行排序。也就是说,如果列表中既有数值,又有字符串,则排序操作报错。
sort()和sorted()的另一个参数是key,它默认为key=None,该参数用来指定自定义的排序函数,从而实现自己需要的排序规则。
例如,上面的列表不再按照默认的字符顺序排序,而是想要按照字符串的长度进行排序。所以,自定义这个排序函数:
>>> def sortByLen(s):
... return len(s)
然后通过指定key = sortByLen的参数方式调用sort()或sorted(),在此期间还可以指定reverse = True:
>>> L = ['shell', 'python', 'Perl', 'PHP', 'Go']
>>> sorted(L,key=sortByLen)
['Go', 'PHP', 'Perl', 'shell', 'python']
>>> L.sort(key=sortByLen,reverse=True)
>>> L
['python', 'shell', 'Perl', 'PHP', 'Go']
再例如,按照列表每个元素的第二个字符来排序。
def f(e):
return e[1]
L = ['shell', 'python', 'Perl', 'PHP', 'Go']
sorted(L, key=f)
L.sort(key=f)
更多的排序方式,参见:sorting HOWTO。比如指定两个排序依据,一个按字符串长度升序排,长度相同的按第2个字符降序排。用法其实很简单,不过稍占篇幅,所以本文不解释了。
列表迭代和解析
列表是一个序列,可以使用in测试,使用for迭代。
例如:
>>> L = ["a","b","c","d"]
>>> 'c' in L
True
>>> for i in L:
... print(i)
...
a
b
c
d
再说列表解析,它指的是对序列中(如这里的列表)的每一项元素应用一个表达式,并将表达式计算后的结果作为新的序列元素(如这里的列表)。
通俗一点的解释,以列表序列为例,首先取列表各元素,对每次取的元素都做一番操作,并将操作后得到的结果放进一个新的列表中。
因为解析操作是一个元素一个元素追加到新列表中的,所以也称为"列表推导",表示根据元素推导列表。
最简单的,将字符串序列中的各字符取出来放进列表中:
>>> [ i for i in "abcdef" ]
['a', 'b', 'c', 'd', 'e', 'f']
这里是列表解析,因为它外面使用的是中括号[],表示将操作后的元素放进新的列表中。可以将中括号替换成大括号,就变成了集合解析,甚至字典解析。但注意,没有直接的元组解析,因为元组的括号是特殊的,它会被认为是表达式的优先级包围括号,而不是元组构造符号。
取出元素对各元素做一番操作:
>>> [ i * 2 for i in "abcdef" ]
['aa', 'bb', 'cc', 'dd', 'ee', 'ff']
>>> L = [1,2,3,4]
>>> [ i * 2 for i in L ]
[2, 4, 6, 8]
>>> [ (i * 2, i * 3) for i in L ]
[(2, 3), (4, 6), (6, 9), (8, 12)]
解析操作和for息息相关,且都能改写成for循环。例如,下面两个语句得到的结果是一致的:
[ i * 2 for i in "abcdef" ]
L = []
for i in "abcdef":
L.append(i * 2)
但是解析操作的性能比for循环要更好,正符合越简单越高效的理念。
学过其他语言的人,估计已经想到了,解析过程中对各元素的表达式操作类似于回调函数。其实在python中有一个专门的map()函数,它以第一个参数作为回调函数,并返回一个可迭代对象。也就是说,也能达到和解析一样的结果。例如:
>>> def f(x):return x * 2
...
>>> list(map(f,[1,2,3,4]))
[2, 4, 6, 8]
map()函数在后面的文章会详细解释。

*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。