
一文详解 Nacos 高可用特性

作者 | kiritomoe
前言
服务注册发现是一个经久不衰的话题,Dubbo 早期开源时默认的注册中心 Zookeeper 最早进入人们的视线,并且在很长一段时间里,人们将注册中心和 Zookeeper 划上了等号,可能 Zookeeper 的设计者都没有想到这款产品对微服务领域造成了如此深厚的影响,直到 SpringCloud 开始流行,其自带的 Eureka 进入了人们的视野,人们这才意识到原来注册中心还可以有其他的选择。再到后来,热衷于开源的阿里把目光也聚焦在了注册中心这个领域,Nacos 横空出世。
Kirito 在做注册中心选型时的思考:曾经我没得选,现在我只想选择一个好的注册中心,它最好是开源的,这样开放透明,有自我的掌控力;不仅要开源,它还要有活跃的社区,以确保特性演进能够满足日益增长的业务需求,出现问题也能即使修复;最好...它的功能还要很强大,除了满足注册服务、推送服务外,还要有完善的微服务体系中所需的功能;最重要的,它还要稳定,最好有大厂的实际使用场景背书,证明这是一个经得起实战考验的产品;当然,云原生特性,安全特性也是很重要的...
似乎 Kirito 对注册中心的要求实在是太高了,但这些五花八门的注册中心呈现在用户眼前,总是免不了一番比较。正如上面所言,功能特性、成熟度、可用性、用户体验度、云原生特性、安全都是可以拉出来做比较的话题。今天这篇文章重点介绍的是 Nacos 在可用性上体现,希望借助于这篇文章,能够让你对 Nacos 有一个更加深刻的认识。
高可用介绍
当我们在聊高可用时,我们在聊什么?
系统可用性达到 99.99% 在分布式系统中,部分节点宕机,依旧不影响系统整体运行 服务端集群化部署多个节点
这些都可以认为是高可用,而我今天介绍的 Nacos 高可用,则是一些 Nacos 为了提升系统稳定性而采取的一系列手段。Nacos 的高可用不仅仅存在于服务端,同时它也存在于客户端,以及一些与可用性相关的功能特性中。这些点组装起来,共同构成了 Nacos 的高可用。
客户端重试
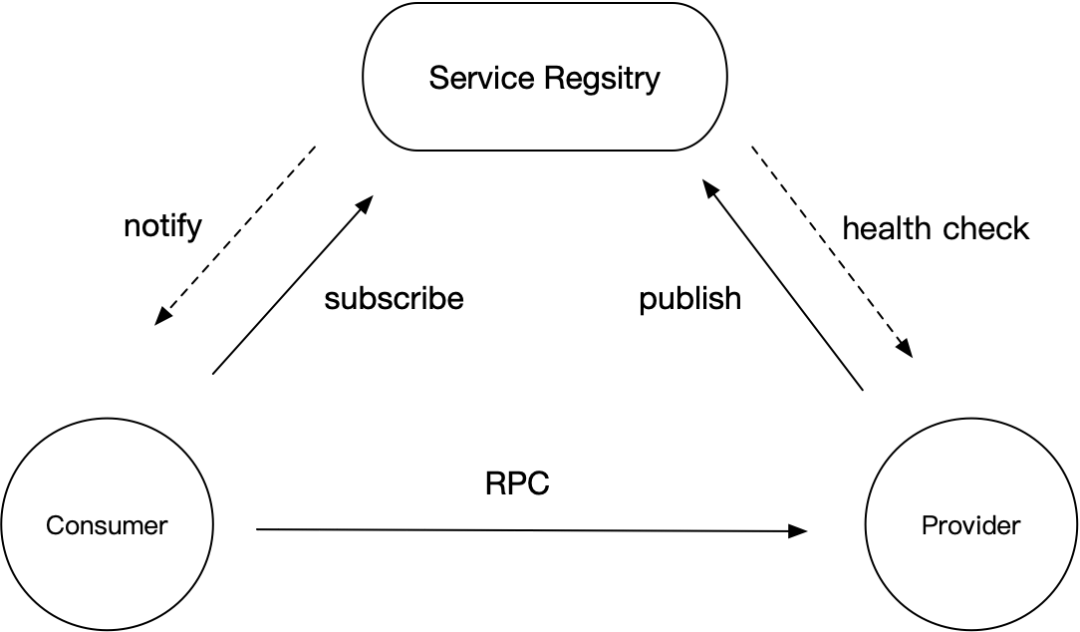
先统一一下语义,在微服务架构中一般会有三个角色:Consumer、Provider 和 Registry,在今天注册中心的主题中,Registry 是 nacos-server,而 Consumer 和 Provider 都是 nacos-client。
在生产环境,我们往往需要搭建 Nacos 集群,在 Dubbo 也需要显式地配置上集群地址:
<dubbo:registry protocol="nacos" address="192.168.0.1:8848,192.168.0.2:8848,192.168.0.3:8848"/>
当其中一台机器宕机时,为了不影响整体运行,客户端会存在重试机制
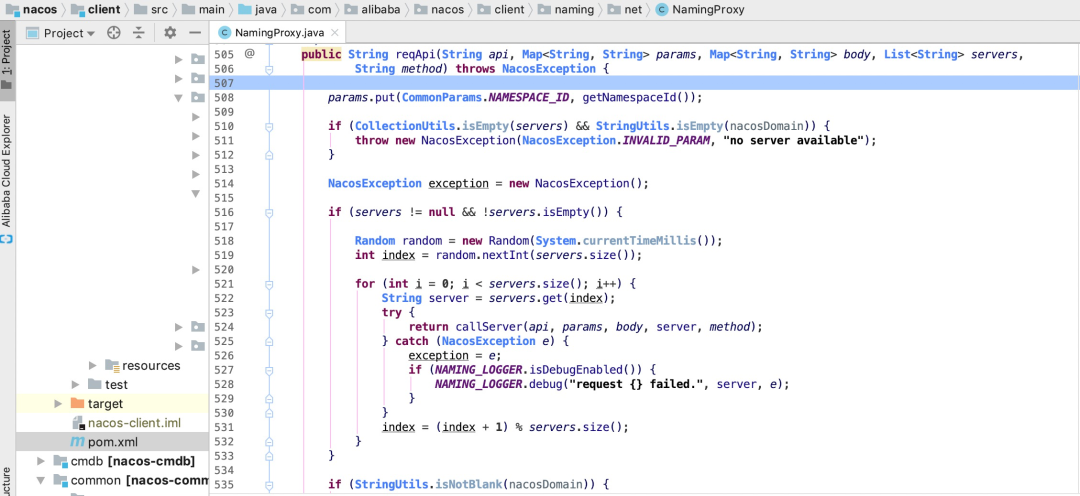
逻辑非常简单,拿到地址列表,在请求成功之前逐个尝试,直到成功为止。
该可用性保证存在于 nacos-client 端。
一致性协议 distro
首先给各位读者打个强心剂,不用看到”一致性协议“这几个字就被劝退,本节不会探讨一致性协议的实现过程,而是重点介绍其与高可用相关的特性。有的文章介绍 Nacos 的一致性模型是 AP + CP,这么说很容易让人误解,其实 Nacos 并不是支持两种一致性模型,也并不是支持两种模型的切换,介绍一致性模型之前,需要先了解到 Nacos 中的两个概念:临时服务和持久化服务。
临时服务(Ephemeral):临时服务健康检查失败后会从列表中删除,常用于服务注册发现场景。 持久化服务(Persistent):持久化服务健康检查失败后会被标记成不健康,常用于 DNS 场景。
临时服务使用的是 Nacos 为服务注册发现场景定制化的私有协议 distro,其一致性模型是 AP;而持久化服务使用的是 raft 协议,其一致性模型是 CP。所以以后不要再说 Nacos 是 AP + CP 了,更建议加上服务节点状态或者使用场景的约束。
distro 协议与高可用有什么关系呢?上一节我们提到 nacos-server 节点宕机后,客户端会重试,但少了一个前提,即 nacos-server 少了一个节点后依旧可以正常工作。Nacos 这种有状态的应用和一般无状态的 Web 应用不同,并不是说只要存活一个节点就可以对外提供服务的,需要分 case 讨论,这与其一致性协议的设计有关。distro 协议的工作流程如下:
Nacos 启动时首先从其他远程节点同步全部数据 Nacos 每个节点是平等的都可以处理写入请求,同时把新数据同步到其他节点 每个节点只负责部分数据,定时发送自己负责数据的校验值到其他节点来保持数据一致性
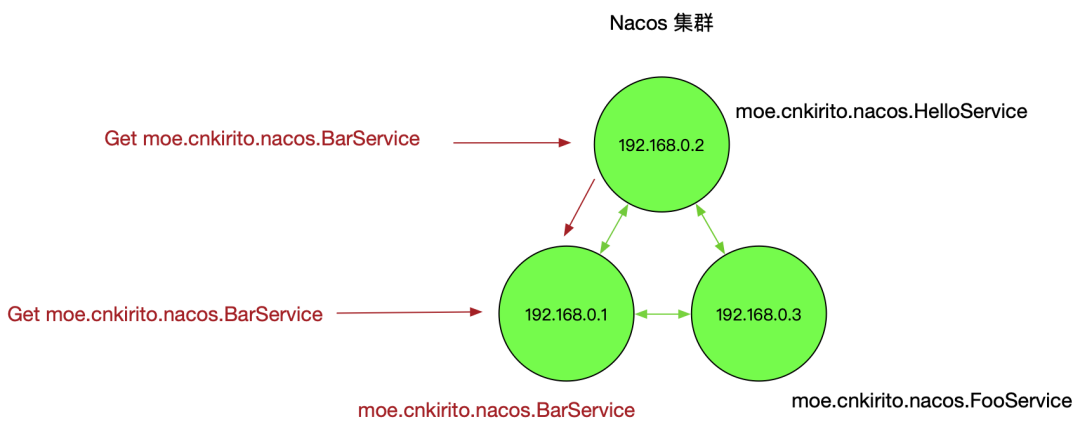
如上图所示,每个节点负责一部分服务的读写,但每个节点都可以接收到读写请求,这时就存在两种读写情况:
当该节点接收到属于该节点负责的服务时,直接读写。 当该节点接收到不属于该节点负责的服务时,将在集群内部路由,转发给对应的节点,从而完成读写。
而当节点发生宕机后,原本该节点负责的一部分服务的读写任务会转移到其他节点,从而保证 Nacos 集群整体的可用性。
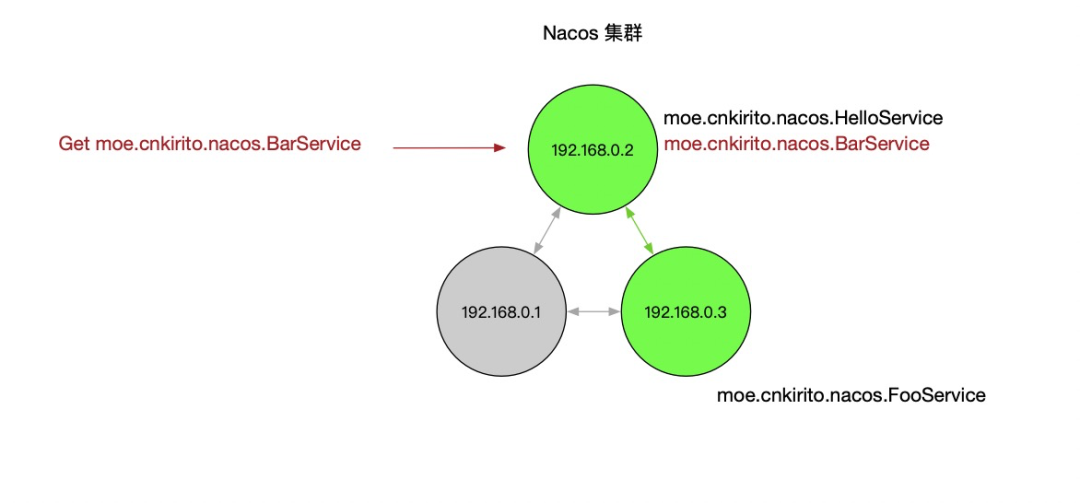
一个比较复杂的情况是,节点没有宕机,但是出现了网络分区,即下图所示:
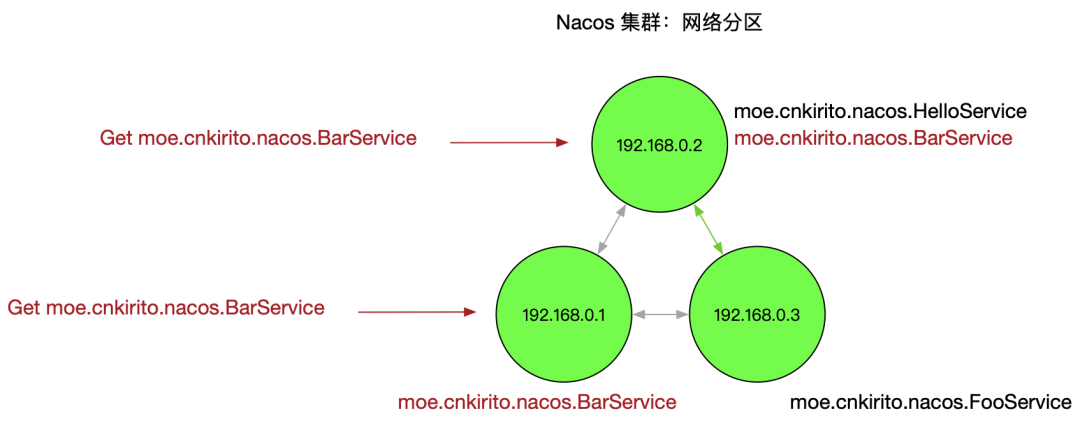
这个情况会损害可用性,客户端会表现为有时候服务存在有时候服务不存在。
综上,Nacos 的 distro 一致性协议可以保证在大多数情况下,集群中的机器宕机后依旧不损害整体的可用性。该可用性保证存在于 nacos-server 端。
本地缓存文件 Failover 机制
注册中心发生故障最坏的一个情况是整个 Server 端宕机,这时候 Nacos 依旧有高可用机制做兜底。
一道经典的 Dubbo 面试题:当 Dubbo 应用运行时,Nacos 注册中心宕机,会不会影响 RPC 调用。这个题目大多数人应该都能回答出来,因为 Dubbo 内存里面是存了一份地址的,一方面这样的设计是为了性能,因为不可能每次 RPC 调用时都读取一次注册中心,另一面,这也起到了可用性的保障(尽管可能 Dubbo 设计者并没有考虑这个因素)。
那如果,我在此基础上再出一道 Dubbo 面试题:Nacos 注册中心宕机,Dubbo 应用发生重启,会不会影响 RPC 调用。如果了解了 Nacos 的 Failover 机制,应当得到和上一题同样的回答:不会。
Nacos 存在本地文件缓存机制,nacos-client 在接收到 nacos-server 的服务推送之后,会在内存中保存一份,随后会落盘存储一份快照。snapshot 默认的存储路径为:{USER_HOME}/nacos/naming/ 中
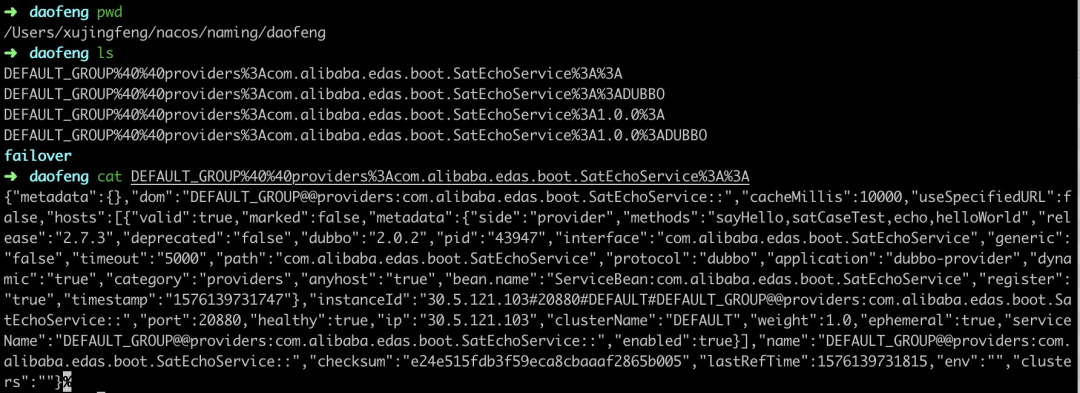
这份文件有两种价值,一是用来排查服务端是否正常推送了服务;二是当客户端加载服务时,如果无法从服务端拉取到数据,会默认从本地文件中加载。
前提是构建 NacosNaming 时传入了该参数:namingLoadCacheAtStart=true
Dubbo 2.7.4 及以上版本支持该 Nacos 参数;开启该参数的方式:dubbo.registry.address=nacos://127.0.0.1:8848?namingLoadCacheAtStart=true
在生产环境,推荐开启该参数,以避免注册中心宕机后,导致服务不可用的稳定,在服务注册发现场景,可用性和一致性 trade off 时,我们大多数时候会优先考虑可用性。
细心的读者还注意到 {USER_HOME}/nacos/naming/{namespace} 下除了缓存文件之外还有一个 failover 文件夹,里面存放着和 snapshot 一致的文件夹。这是 Nacos 的另一个 failover 机制,snapshot 是按照某个历史时刻的服务快照恢复恢复,而 failover 中的服务可以人为修改,以应对一些极端场景。
该可用性保证存在于 nacos-client 端。
心跳同步服务
心跳机制一般广泛存在于分布式通信领域,用于确认存活状态。一般心跳请求和普通请求的设计是有差异的,心跳请求一般被设计的足够精简,这样在定时探测时可以尽可能避免性能下降。而在 Nacos 中,出于可用性的考虑,一个心跳报文包含了全部的服务信息,这样相比仅仅发送探测信息降低了吞吐量,而提升了可用性,怎么理解呢?考虑以下的两种场景:
nacos-server 节点全部宕机,服务数据全部丢失。nacos-server 即使恢复运作,也无法恢复出服务,而心跳包含全部内容可以在心跳期间就恢复出服务,保证可用性。 nacos-server 出现网络分区。由于心跳可以创建服务,从而在极端网络故障下,依旧保证基础的可用性。
以下是对心跳同步服务的测试,使用阿里云 MSE 提供 Nacos 集群进行测试

调用 OpenApi:curl -X "DELETE mse-xxx-p.nacos-ans.mse.aliyuncs.com:8848/nacos/v1/ns/service?serviceName=providers:com.alibaba.edas.boot.EchoService:1.0.0:DUBBO&groupName=DEFAULT_GROUP" 依次删除各个服务
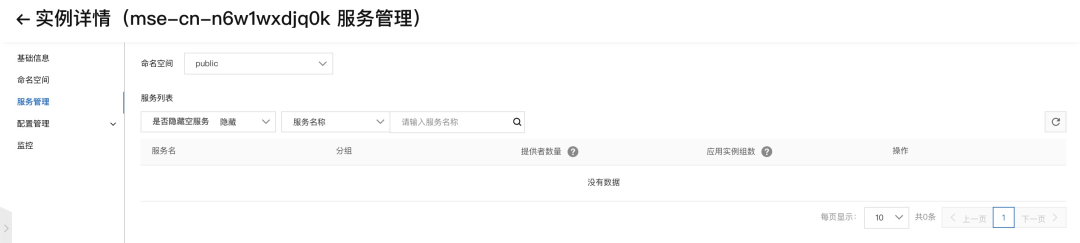
过 5s 后刷新,服务又再次被注册了上来,符合我们对心跳注册服务的预期。
集群部署模式高可用
最后给大家分享的 Nacos 高可用特性来自于其部署架构。
节点数量
我们知道在生产集群中肯定不能以单机模式运行 Nacos,那么第一个问题便是:我应该部署几台机器?前面我们提到 Nacos 有两个一致性协议:distro 和 raft,distro 协议不会有脑裂问题,所以理论来说,节点数大于等于 2 即可;raft 协议的投票选举机制则建议是 2n+1 个节点。综合来看,选择 3 个节点是起码的,其次处于吞吐量和更高可用性的考量,可以选择 5 个,7 个,甚至 9 个节点的集群。
多可用区部署
组成集群的 Nacos 节点,应该尽可能考虑两个因素:
各个节点之间的网络时延不能很高,否则会影响数据同步 各个节点所处机房、可用区应当尽可能分散,以避免单点故障
以阿里云的 ECS 为例,选择同一个 Region 的不同可用区就是一个很好的实践
部署模式
主要分为 K8s 部署和 ECS 部署两种模式。
ECS 部署的优点在于简单,购买三台机器即可搭建集群,如果你熟练 Nacos 集群部署的话,这不是难事,但无法解决运维问题,如果 Nacos 某个节点出现 OOM 或者磁盘问题,很难迅速摘除,无法实现自运维。
K8s 部署的有点在于云原生运维能力强,可以在节点宕机后实现自恢复,保障 Nacos 的平稳运行。前面提到过,Nacos 和无状态的 Web 应用不同,它是一个有状态的应用,所以在 K8s 中部署,往往要借助于 StatefulSet 和 Operator 等组件才能实现 Nacos 集群的部署和运维。
MSE Nacos 的高可用最佳实践
阿里云 MSE(微服务引擎)提供了 Nacos 集群的托管能力,实现了集群部署模式的高可用。
当创建多个节点的集群时,系统会默认分配在不同可用区。同时,这对于用户来说又是透明的,用户只需要关心 Nacos 的功能即可,MSE 替用户兜底可用性。 MSE 底层使用 K8s 运维模式部署 Nacos。历史上出现过用户误用 Nacos 导致部分节点宕机的问题,但借助于 K8s 的自运维模式,宕机节点迅速被拉起,以至于用户可能都没有意识到自己发生宕机。
下面模拟一个节点宕机的场景,来看看 K8s 如何实现自恢复。
一个三节点的 Nacos 集群:

执行 kubectl delete pod mse-7654c960-1605278296312-reg-center-0-2 以模拟部分节点宕机的场景。

大概 2 分钟后,节点恢复,并且角色发生了转换,Leader 从杀死的 2 号节点转给 1 号节点

总结
本文从多个角度出发,总结了一下 Nacos 是如何保障高可用的。高可用特性绝不是靠服务端多部署几个节点就可以获得的,而是要结合客户端使用方式、服务端部署模式、使用场景综合来考虑的一件事。
特别是在服务注册发现场景,Nacos 为可用性做了非常多的努力,而这些保障,Zookeeper 是不一定有的。在做注册中心选型时,可用性保障上,Nacos 绝对是优秀的。
2021-01-03

2021-01-03

2021-01-03

2021-01-02

2021-01-02

2021-01-02
2021-01-01

扫一扫,关注我
知晓前沿科技,领略技术魅力
﹀
﹀
﹀
深度交流
技术 + 社会
职场 + 创业
