
AWS 发布以 Flink on Zeppelin 为内核的 Kinesis Data Analytics Studio
最近AWS发布一款新产品:Amazon Kinesis Data Analytics Studio,其中内核就是 Flink on Zeppelin。以下文字援引自AWS 官网:https://aws.amazon.com/blogs/aws/introducing-amazon-kinesis-data-analytics-studio-quickly-interact-with-streaming-data-using-sql-python-or-scala/
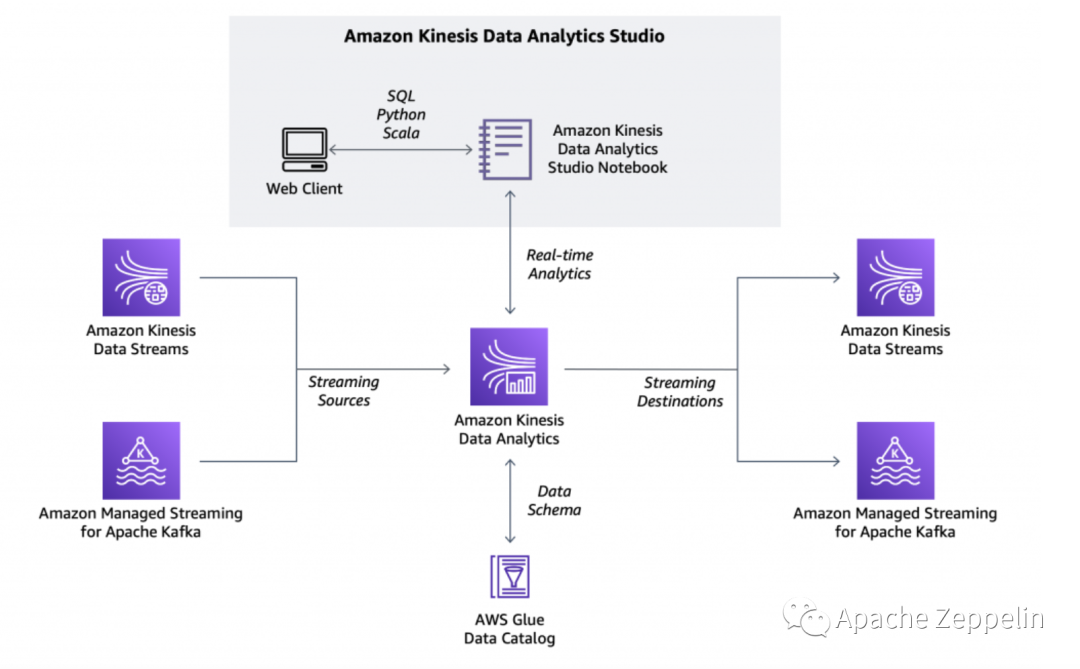
To make it easier to analyze streaming data, today we are pleased to introduce Amazon Kinesis Data Analytics Studio.
Now, from the Amazon Kinesis console you can select a Kinesis data stream and with a single click start a Kinesis Data Analytics Studio notebook powered by Apache Zeppelin and Apache Flink to interactively analyze data in the stream. Similarly, you can select a cluster in the Amazon Managed Streaming for Apache Kafka console to start a notebook to analyze data in Apache Kafka streams. You can also start a notebook from the Kinesis Data Analytics Studio console and connect to custom sources.
所以你还等什么,快来Flink on Zeppelin社区吧,扫码加入下面的钉钉群加入我们吧。更多Flink on Zeppelin中文资料请看语雀文档:https://www.yuque.com/jeffzhangjianfeng/gldg8w
----------------- 招聘 --------------------
开宗明义,我们认为大数据上半场战斗已经结束,上半场战斗主要是底层引擎之争,目前已经趋于稳定。大数据的下半场战斗将发生在引擎之上的平台层。
如果你是有经验的大数据工程师,可能会有下面这3个痛点:
1. 缺少一个真正的可以提高工程师开发效率的平台。通常你需要在本地开发,然后打包上传代码,切换到集群环境里跑你的代码,如果出现错误,需要重新打包上传,整个过程效率低下,从开发到生产环境的过渡不够smooth。
2. 与上下游整合效率低下。大数据不是一个孤立的领域,通常需要结合上下游,上游是数据源,下游是BI,AI应用,现在大部分情况你需要在各种工具之间做切换以及数据交换才能完成整个端到端的解决方案。
3. 对接各种引擎成本太高。通常情况下,一个企业内有多种引擎来应对各种不同场景,你需要对接各种引擎,而每种引擎的对接方式又是千差万别,导致引擎对接成本太高。
我们是阿里云的大数据开放平台组,立志于打造一款革命性的大数据开发平台产品来解决上面的问题。如果你有志于为大数据领域做出一些小小的贡献,欢迎加入我们。
岗位要求
• 基本功扎实,有学习的热情和态度,有很强的解决问题能力。有快速学习新框架,看源码的能力。
• 熟悉Java,Python等开发语言,具备扎实的计算机理论基础,
• 具有良好的软件架构设计能力和写可读性高的代码能力
• 有大数据研发经验者。例如利用大数据框架(Hadoop,Spark,Flink 等等)工具构建过大数据产品或者ETL,大数据分析等,并且需要理解主流引擎的内部工作机制。
• 不仅有技术的深度,也有做产品的热情和sense。
• 有数据分析经验,机器学习经验者加分
• 有开源贡献经验者加分
这是一次难得的机会,希望我们有机会一起来做一个伟大的产品。
有意者请发送简历到 jeffzhang.zjf@alibaba-inc.com公司地址:浦东张江人工智能岛