
CVPR 2022|Transformer图像风格迁移,快手、中科院自动化
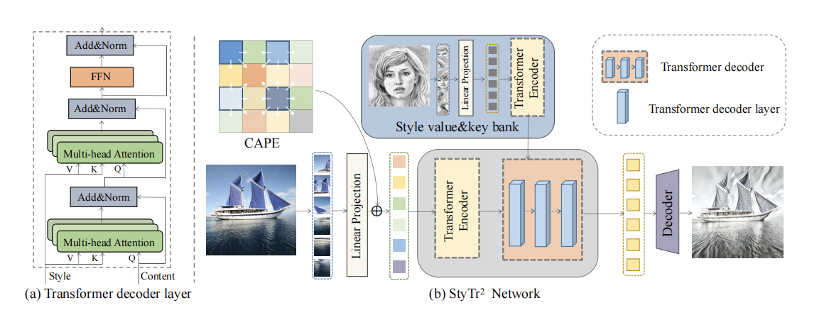
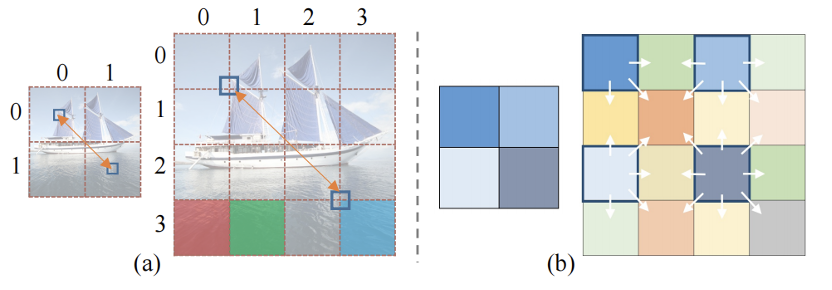
机器之心 作者:快手Y-tech 本文提出了一种基于 Transformer 的图像风格迁移方法,我们希望该方法能推进图像风格化的前沿研究以及 Transformer 在视觉尤其是图像生成领域的应用。

论文链接:https://arxiv.org/abs/2105.14576
代码地址:https://github.com/diyiiyiii/StyTR-2



猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》
评论