Hive实操学习全集
学习完hive的远程配置,接下来就该学习hive的实操了,这个才是我们在企业中进行数据分析的主要工作内容。
DDL建表
我们通过阅读官方文档,就可以找到所有的DDL操作。
hive官方文档
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
建表语句
不同于mysql和oracle,hive可以直接存储数组类型数据,键值对类型数据。同时还可以指定分隔符。因为最终数据是存储在hdfs的文件中的。通过分隔符来标识每个数据对应hive表中的哪个字段。
Create Table
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
column_constraint_specification:
: [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
default_value:
: [ LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ]
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]根据如下数据建表
人员表
id,姓名,爱好,住址
1,小明1,lol-dota-movie-book-love,beijing:tongzhou-beijing:chaoyang
2,小明2,lol-dota-movie-book-love,beijing:tongzhou-beijing:chaoyang
3,小明3,lol-dota-movie-book-love,beijing:tongzhou-beijing:chaoyang
4,小明4,lol-dota-movie-book-love,beijing:tongzhou-beijing:chaoyang
5,小明5,lol-dota-movie-book-love,beijing:tongzhou-beijing:chaoyang
6,小明6,lol-dota-movie-book-love,beijing:tongzhou-beijing:chaoyang指定分隔符
行格式里面,属性值以,隔开。集合里面用-隔开,键值对用:隔开。
create table psn
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';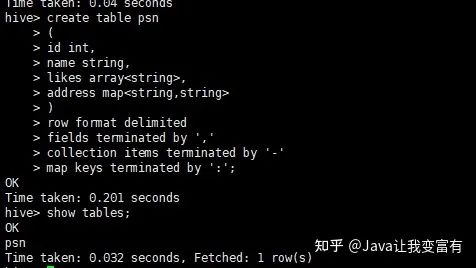
详细建表语句
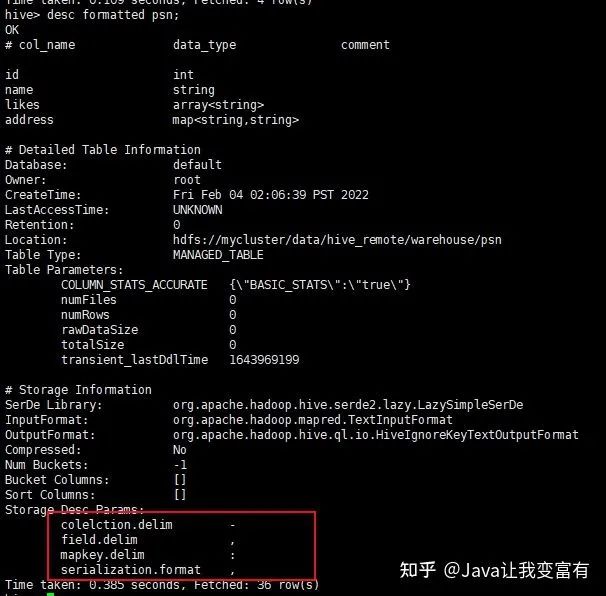
默认分隔符1
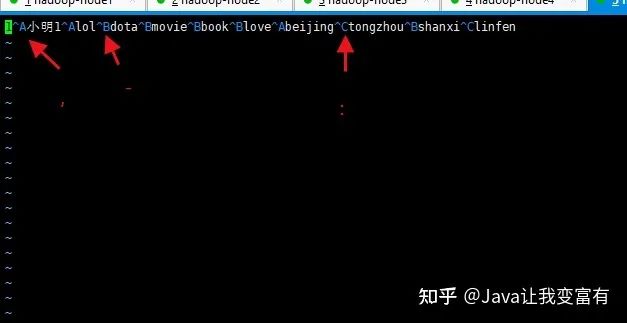
接下来我们使用默认建表分隔符,导入数据的分割符也就必须使用默认的了。下边的标识分别代表,- :
create table psn2
(
id int,
name string,
likes array<string>,
address map<string,string>
)
然后我们上传数据到psn2表目录下。
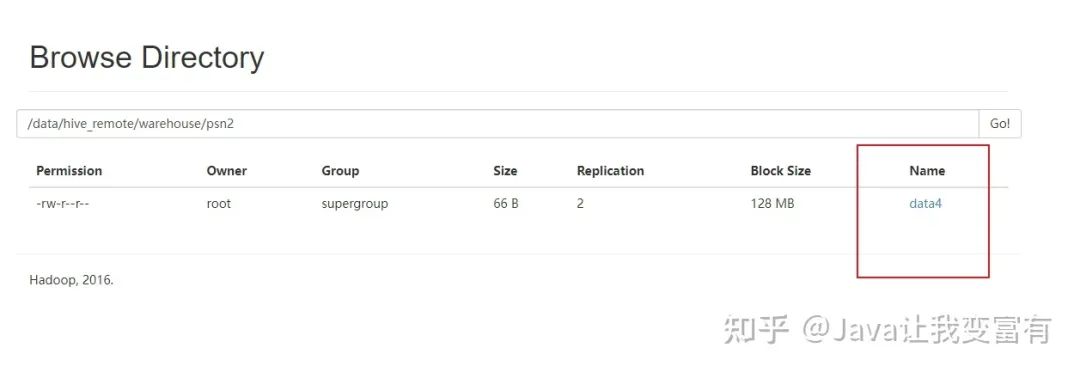
查询结果正确。
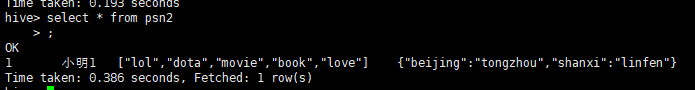
默认分隔符2
create table psn3
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by '\001'
collection items terminated by '\002'
map keys terminated by '\003';通过上述建表语句,也可以识别默认分隔符的数据。
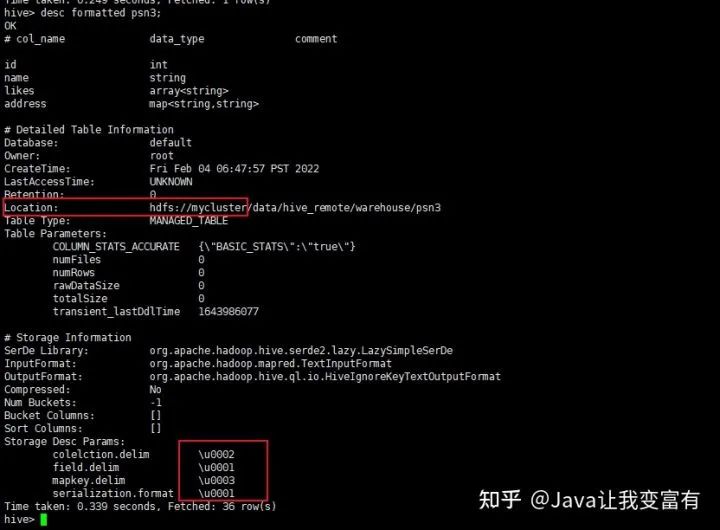

分区表
分区的作用,如果有个字段代表男女,那么根据性别创建分区之后,查询男性数据,只需要去男性分区查询就好了,不用混入女性查询,查询效率会大大增加。一般都是根据时间做分区。
创建分区表的时候,分区描述本来就是个字段,所以不能重复写两个。
create table psn5
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';如果写成如下方式会报错,重复字段;
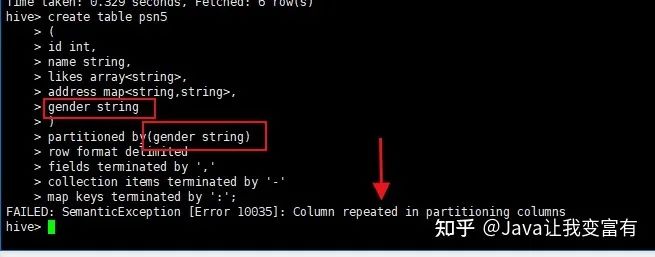
正确的如下:
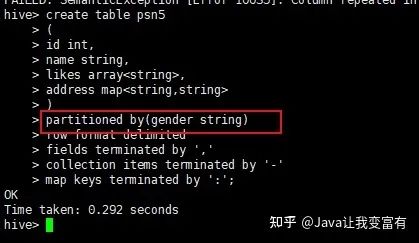
分区表导入
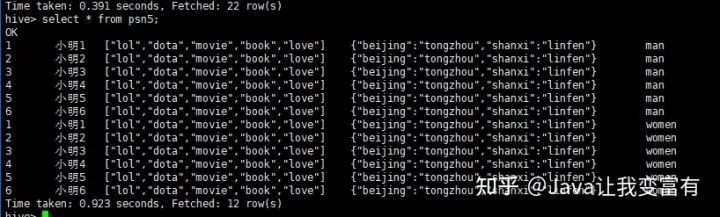
分区表导入数据时,我们可以通过导入单个分区数据,同时指定分区字段的值。如下所示,我们导入男性分区,就知道我们此次导入的数据都是男性的。因此我们就指定性别为男性。
load data local inpath '/root/data/data' into table psn5 partition(gender='man');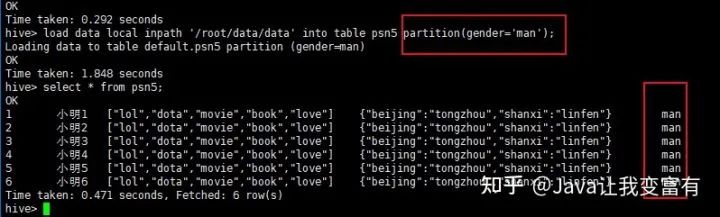
从文件目录可以看出,以后查询数据,先查询分区表,再查询数据。
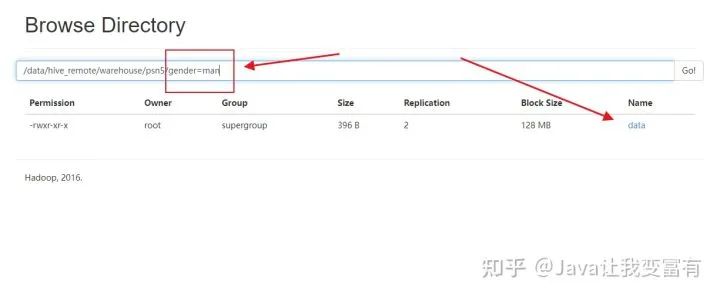
例如我们再加载一份women的数据,分区指定值为women。
load data local inpath '/root/data/data' into table psn5 partition(gender='women');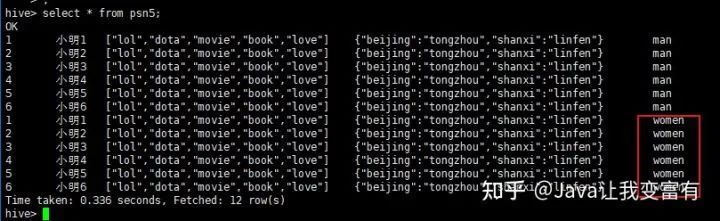
然后我们可以看到,psn5表存储目录如下所示:
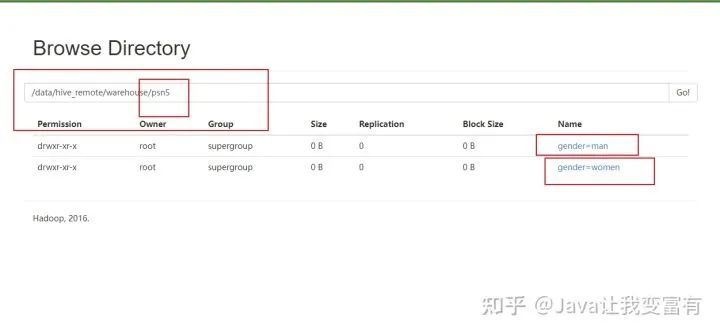
多分区
当创建了多个分区之后,每次导入数据,必须指定所有分区的值,因为只有这样,才知道数据最终应该放到哪个目录下边。如下所示,我们再将年龄也添加分区。
create table psn6
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(gender string,age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';如下,我们导入一个分区文件,指定年龄为11,性别为women。再导入一个分区文件,指定年龄为12,性别为man。
load data local inpath '/root/data/data' into table psn6 partition(age=11,gender='women');
load data local inpath '/root/data/data' into table psn6 partition(age=12,gender='man');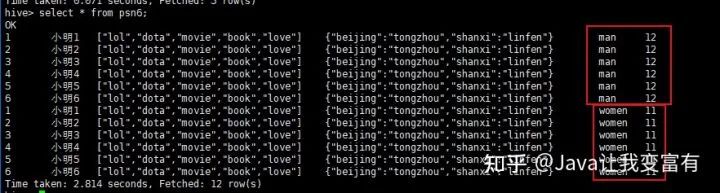
存储目录应该会和我们猜想的差不太多。

分区列添加
单独添加一个分区列,不导入数据,此时需要将其他分区的值也要带上。不可只指定一个。如下为错误操作:
alter table psn6 add partition(gender='girl');
如下为正确操作:
alter table psn6 add partition(gender='girl',age=12);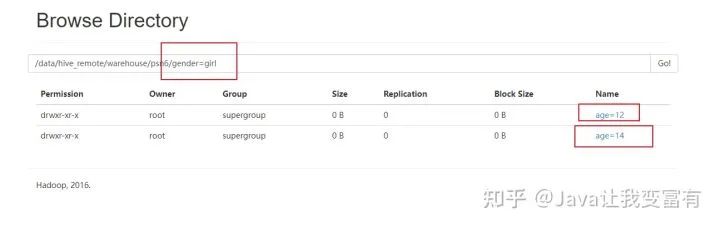
分区删除
删除表中非分区字段标记的记录不支持,但是可以支持删除分区数据,因为分区本就是一个目录来区分的,所以会删除掉指定分区下的所有文件数据。会发现两个都被删除了。
alter table psn6 drop partition(gender='girl');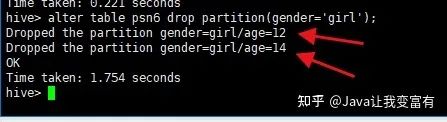
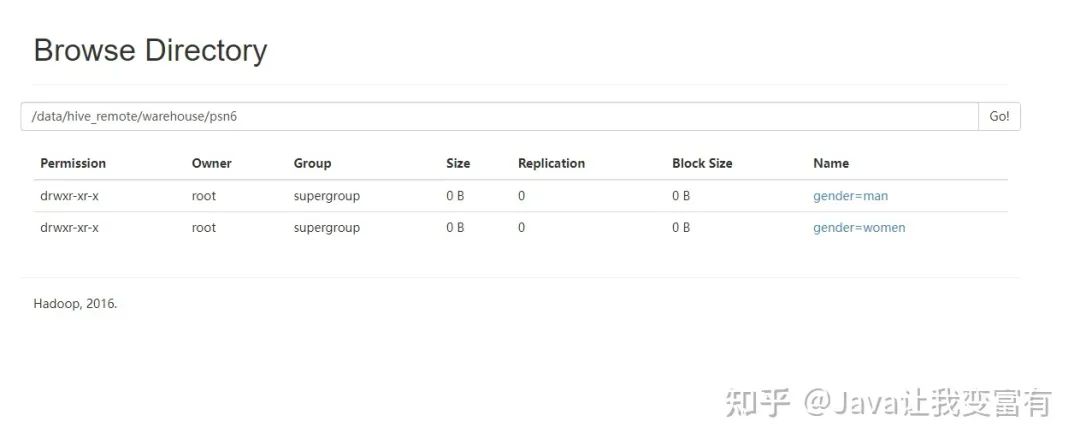
分区修复
当我们没有通过hive添加分区,而是通过hdfs创建好了表的分区目录时,此时分区是没有进入元数据的,因此查询表就会不止所踪。如下我们先上传数据至对应分区,查询结果显示无数据。
[root@node4 data]# hdfs dfs -put data /tengYue/age=10/
[root@node4 data]# hdfs dfs -put data /tengYue/age=20/
此时我们进行分区修复,因为对表实行分区修复,肯定是检测表的目录,然后按照规则将我们创建的分区添加到元数据中。使用如下命令,我们可以看到hive自动将我们的分区添加到了元数据中。
msck repair table psn7;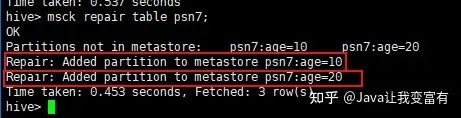
此时我们执行查询得到如下结果,分区修复:
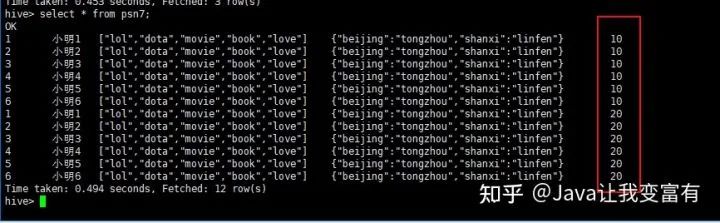
创建外部表
外部表创建需要指定存储位置。
create external table psn4
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/tengYue';然后我们给psn4加载数据,用如下命令:
load data local inpath '/root/data/data' into table psn4;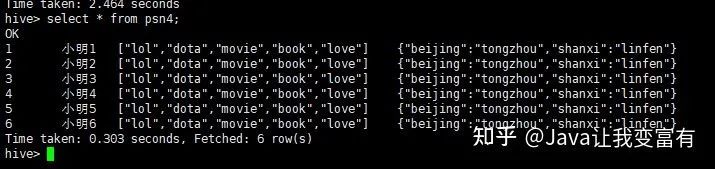
然后我们看下存储数据的地方,就是我们刚才指定的目录下边。
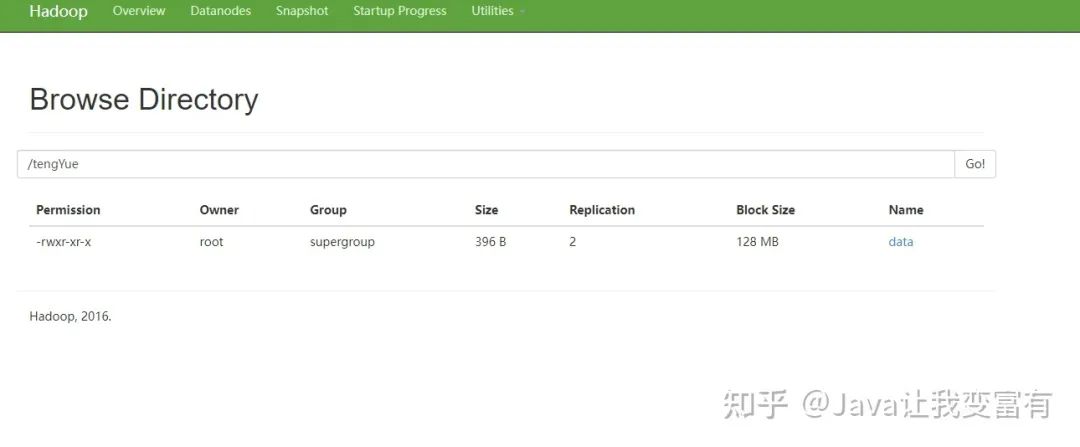
元数据中外部表的标识如下:

Hive Serde
在我们导入数据的时候,可以先用正则表达式对导入的数据进行一波清洗,将每条记录格式化成我们想要的。例如如下数据,我们想要得到的数据不包含[] 还有双引号:
192.168.57.4 - - [29/Feb/2019:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:35 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:35 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:35 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2019:18:14:36 +0800] "GET /bg-upper.png HTTP/1.1" 304 -建表语句如下:
CREATE TABLE logtbl (
host STRING,
identity STRING,
t_user STRING,
time STRING,
request STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE;然后加载数据到hdfs中表的对应目录下。
load data local inpath '/root/data/log' into table logtbl;接着查询数据可以看到数据已经被我们格式化完成。
select * from logtbl;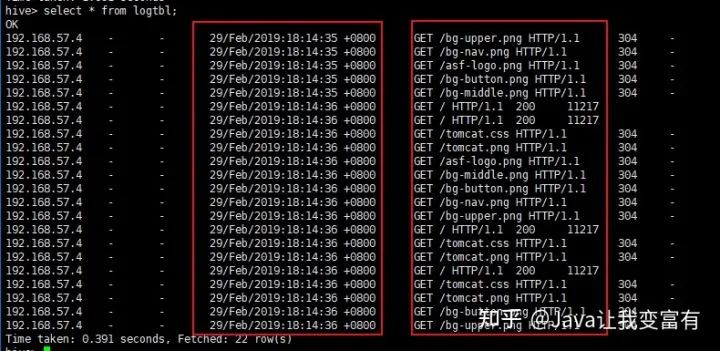
DDL删表
内部表的删除
内部表的删除,会删除元数据和表数据。
drop table psn;
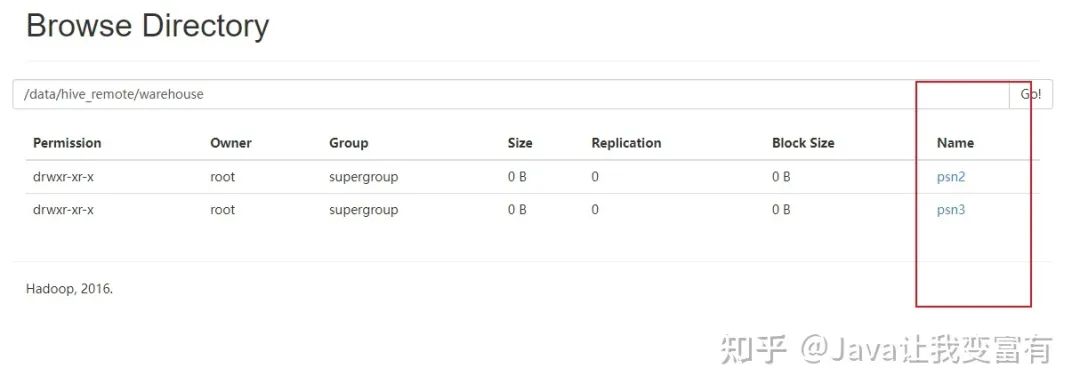
外部表的删除
而外部表的删除则只会删除元数据,并不会删除数据。如下图所示。
drop table psn4;
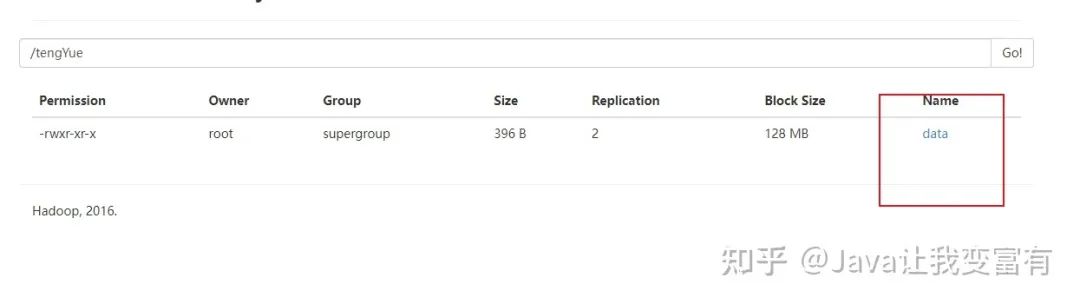
如果我们再次创建外部表,会发现不用加载数据,psn4就可以查询到数据。除非我们通过HDFS文件系统强行删除数据文件。
create external table psn4
(
id int,
name string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/tengYue';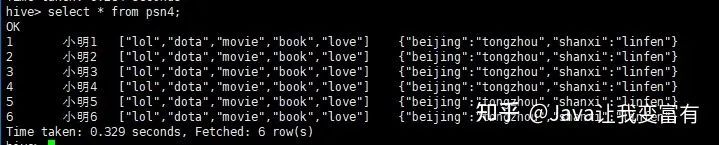
DML新增操作
通过文件导入
加载数据到hive数据库中,可以通过load操作,直接将文件转换成数据库文件。
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)

load data local inpath '/root/data/data' into table psn;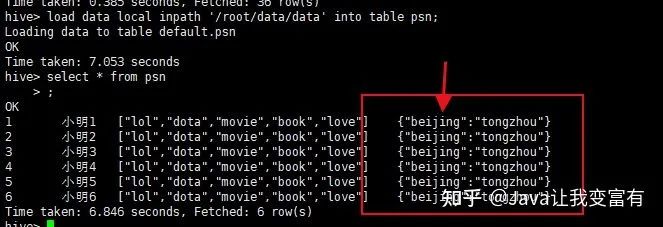
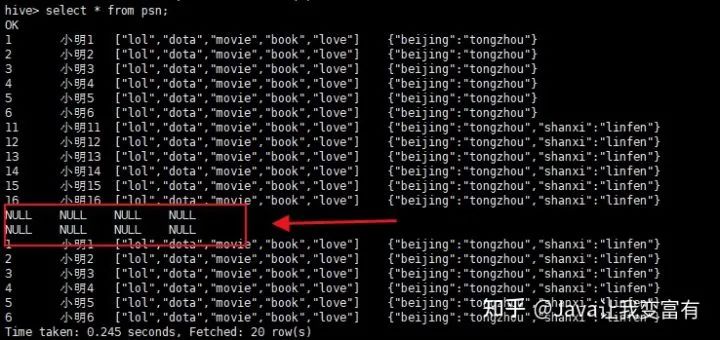
数据问题
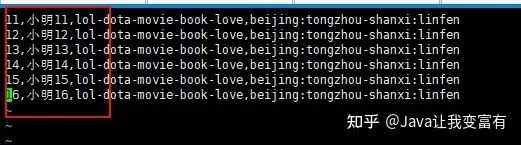
由于beijing这个key是一致的,所以发现地址上边,两个地址变成了最后一个地址,前边的地址被相同的key给覆盖掉了,根据推测,修改地址上相同的key。

修改后的文件如下:
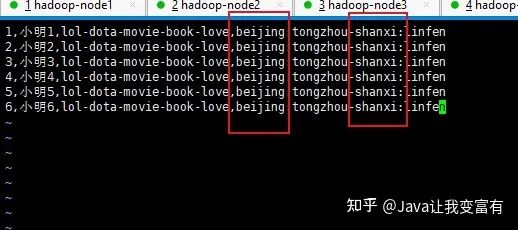
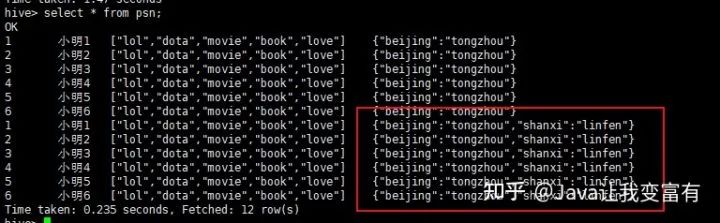
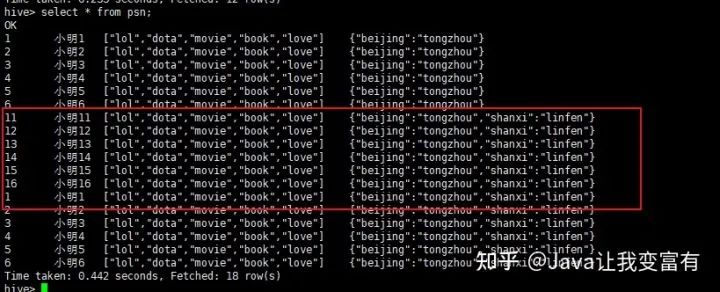
新数据导入
我们可以看到数据导入是追加操作,而且我们上述的推测是正确的,一行记录中相同的key值会遭到覆盖。
直接上传hdfs
接下来我们直接上传新文件至hive检测的库表目录下,会发现,其实hive直接会把表目录下的文件全部读取出来。
hdfs dfs -put data2 /data/hive_remote/warehouse/psn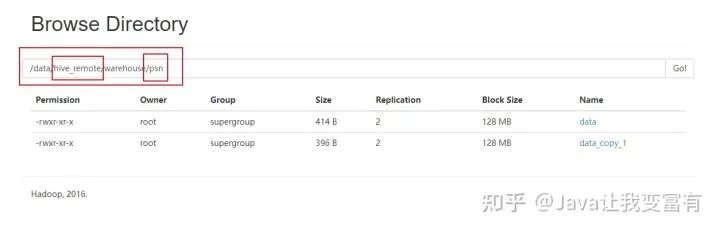
果然直接都读取到了。看来这个东西一点也不像数据库。在没学习过它的时候,总觉得它和数据库差别不大。现在发现mysql是写时检查机制,会在插入数据的时候检测是否符合数据库规范,否则无法插入。而hive是读时检查,可以随便放到它表的目录下,但是读取的时候,如果格式不对那么它会给出错误的行记录。按照自己的规则处理。
上传错误数据
hdfs dfs -put data3 /data/hive_remote/warehouse/psn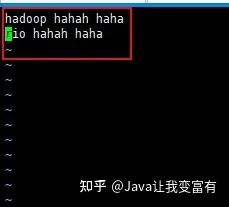
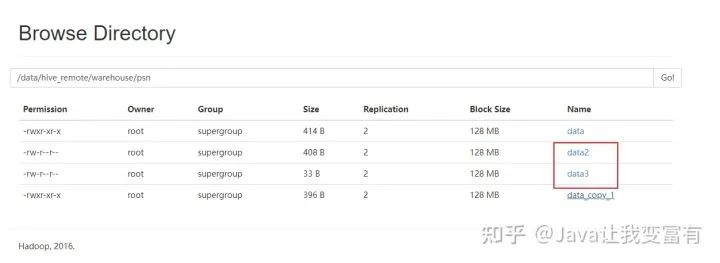
读取到的错误数据也按照自己的规则处理。
通过查表新增
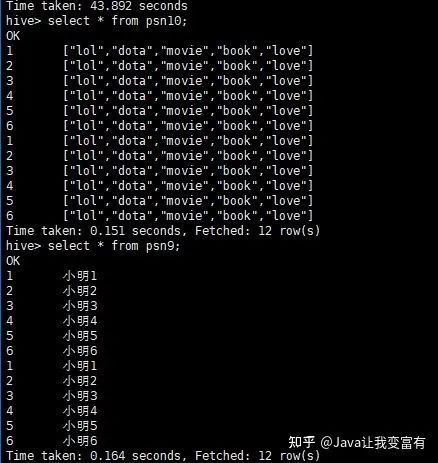
insert into table psn9 select id,name from psn5 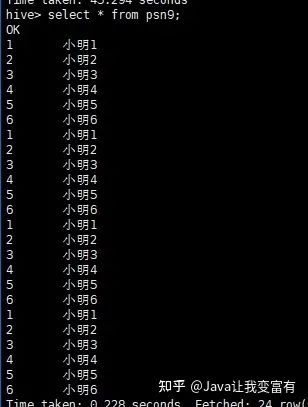
通过查表覆盖
创建新表如下:
create table psn9
(
id int,
name string
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';通过如下命令覆盖数据:
insert overwrite table psn9 select id,name from psn;这种方式会启动一个mapReduce任务:
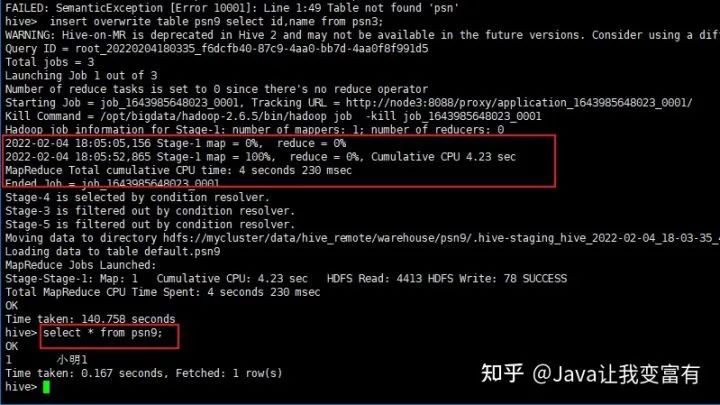
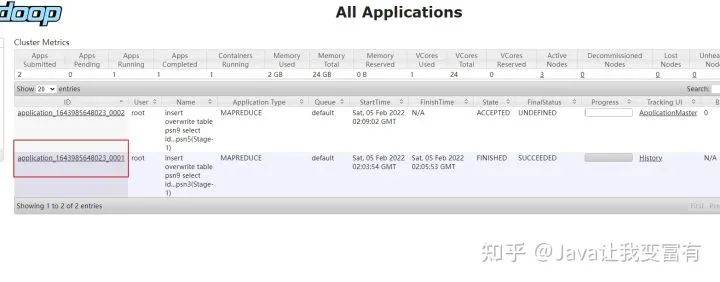
第二次再次执行。
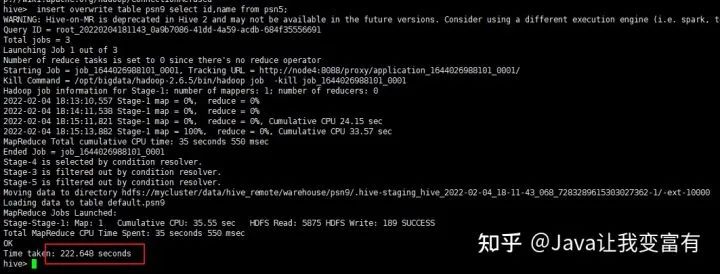
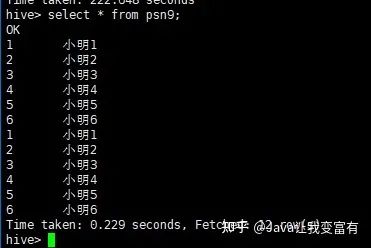
同时新增两张表
新增psn10表
create table psn10
(
id int,
likes array<string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';执行如下命令:
from psn5
insert overwrite table psn9
select id,name
insert into table psn10
select id,likes;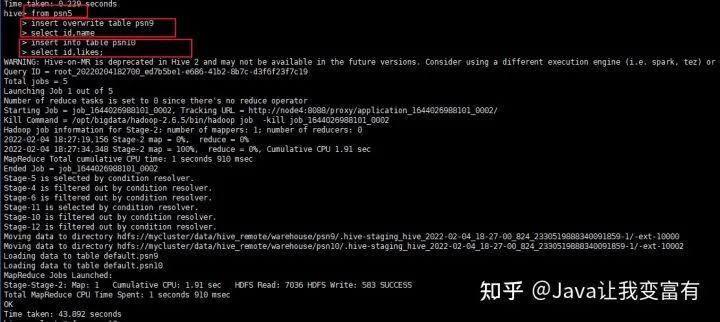
DML删除操作
不支持非分区删除
本想着把之前的数据删除了,重新导入,发现无此操作。反正是测试,索性把新的文件直接导入吧。
Attempt to do update or delete using transaction manager that does not support these operations.
Hive操作符与函数
具体的详细操作可以通过下方官方文档查看:
LanguageManual UDFcwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
复杂类型操作符
例如我们的map类型,直接通过key值,就可以取出来每条记录该字段对应的key值对应的value值。
select address["beijing"] from psn5;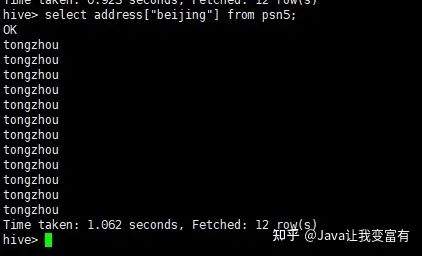
还有数组类型的,直接通过索引下标就可以取出来对应索引的值。
hive> select likes[1] from psn5;
OK
dota
dota
dota
dota
dota
dota
dota
dota
dota
dota
dota
dota
Time taken: 0.334 seconds, Fetched: 12 row(s)
字符串拼接
hive> select name||' likes '||likes[0]||','||likes[1]||','||likes[2] from psn5;
OK
小明1 likes lol,dota,movie
小明2 likes lol,dota,movie
小明3 likes lol,dota,movie
小明4 likes lol,dota,movie
小明5 likes lol,dota,movie
小明6 likes lol,dota,movie
小明1 likes lol,dota,movie
小明2 likes lol,dota,movie
小明3 likes lol,dota,movie
小明4 likes lol,dota,movie
小明5 likes lol,dota,movie
小明6 likes lol,dota,movie
Time taken: 0.401 seconds, Fetched: 12 row(s)
内置数学函数
sum函数,不过每次使用函数都会提交一个mapReduce任务。
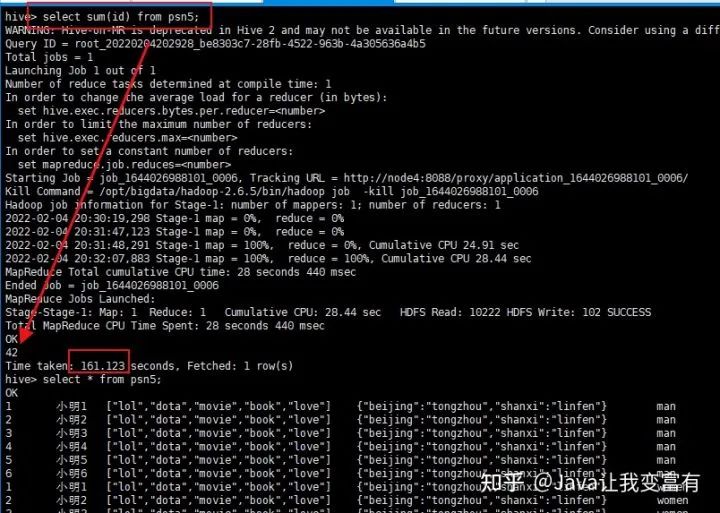
UDTF函数
如下一个数组字段,经过explode函数,就会被拆分成一个一个的元素。
select explode(likes) from psn5;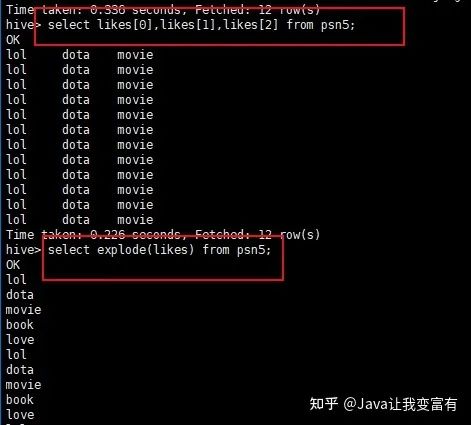
UDFs函数
自定义函数。自己使用编程语言,编译成jar包,上传到hive集群。然后创建自定义函数,指向jar包函数定义类的全类名路径。这样就可以使用自己的自定义函数来处理数据了。
组合函数
例如,我们需要将一个文件中的单词单个输出,单词都是以空格分割。那么我们可以通过使用split函数先将数据变成数组,然后再使用explode函数,将数组拆分。
然后创建表words:
create external table words(line string) location '/words';上传文件至hdfs的words表目录空间下:
hdfs dfs -put words /words然后我们可以查询到表数据:
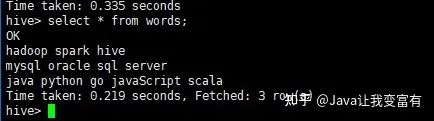
接着使用split函数可以得到每一行的数组。
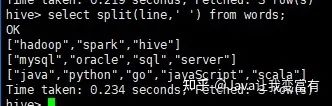
然后使用explode+split函数的组合,达到如下的效果。
select explode(split(line,' ')) from words;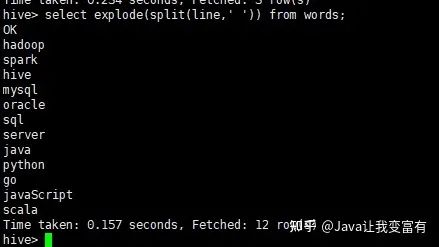
Hive参数设置
hive参数设置需要注意参数作用域。通过命令行启动的参数,一般只在本次进程中起作用。退出进程,下次如果不带入,则失去效果。想要记住效果,肯定需要提前持久化到某个配置文件中。
设置表头信息
hive设置表头显示参数启动。
hive --hiveconf hive.cli.print.header=true;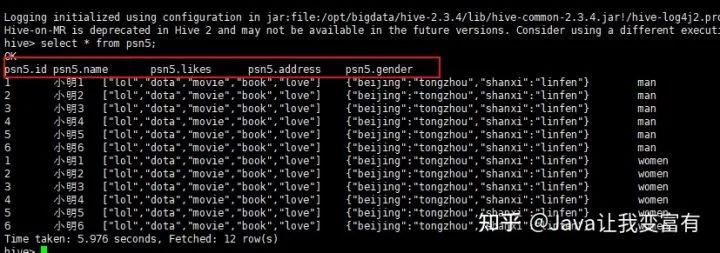
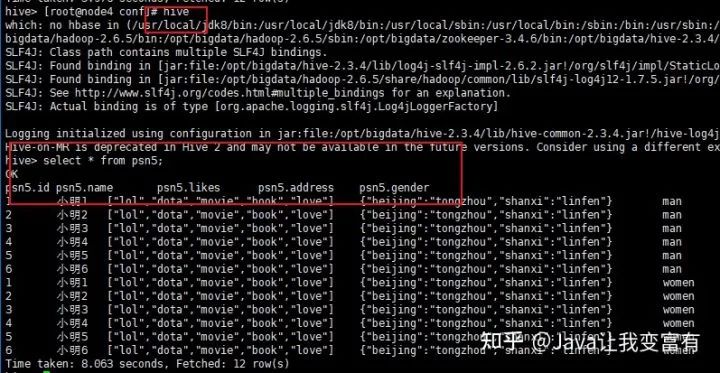
持久化设置
.hiverc 文件中得配置,在hive启动时就加载到本次会话中。
echo 'set hive.cli.print.header=true' >> .hiverc
设置变量
hive -d abc=1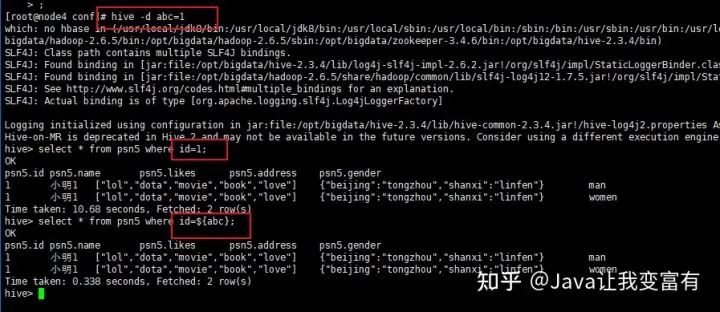
输出结果文件
hive -e "select * from psn5" >> a.txt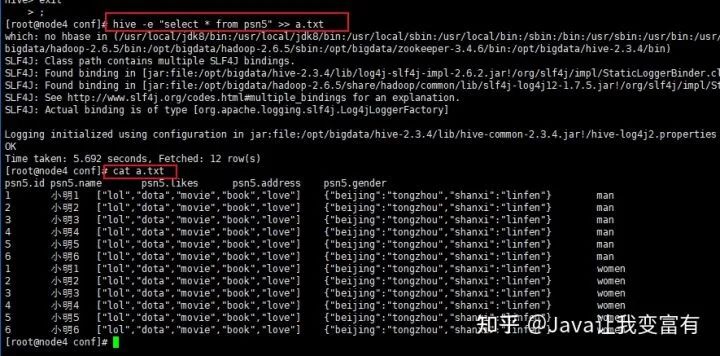
动态分区
文章开头我们实操的是静态分区,每次加载数据,都需要加载某个分区的数据文件。要男性的,都必须是男性的数据。而动态分区,可以根据每条记录属于哪个分区而动态存储到相应的分区目录下。首先我们需要先设置非严格模式,如果不设置就会出现如下错误。
hive> insert into psn20 partition(age,gender) select id,name,likes,address,age,gender from psn6;
FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column.
To turn this off set hive.exec.dynamic.partition.mode=nonstric设置非严格模式
set hive.exec.dynamic.partition.mode=nostrict;执行新增语句
insert into psn20 partition(age,gender) select id,name,likes,address,gender,age from psn6;然后发现提交了一个mapReduce任务:
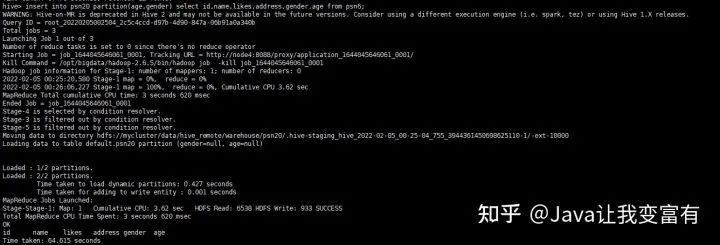
结果如下:
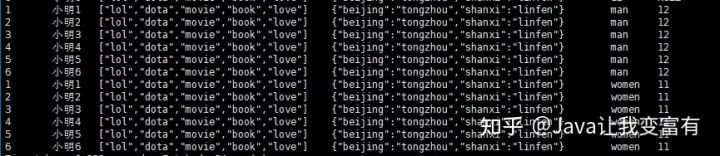
去HDFS文件系统查看表目录,可以发现,我们的分区已经创建好了:
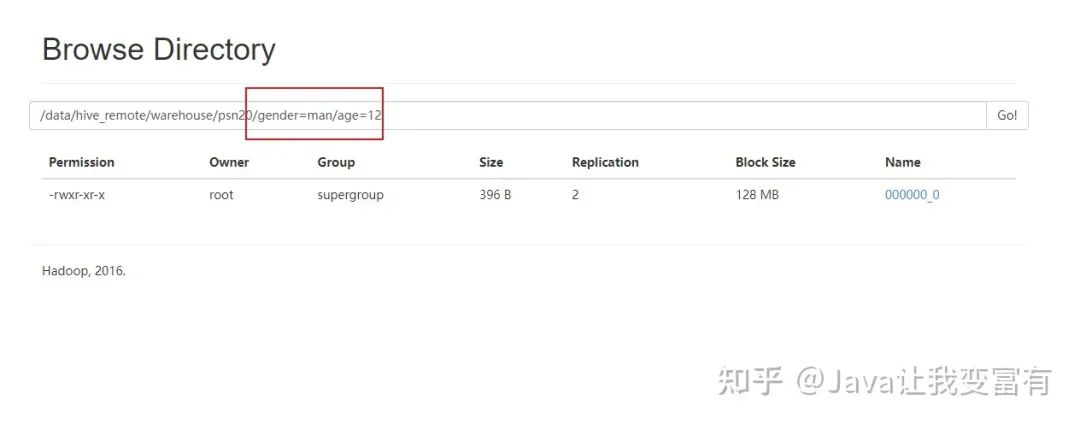
分桶操作
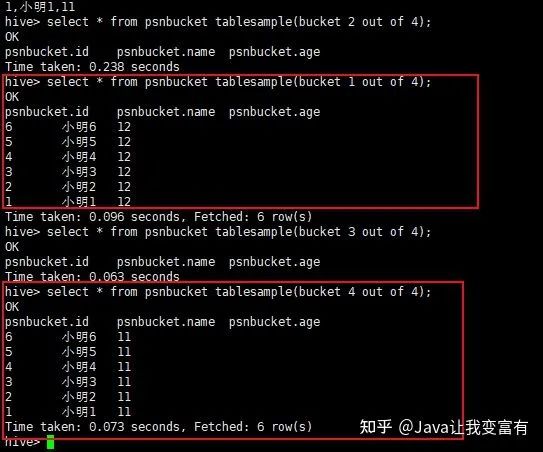
按照某个字段进行分桶操作,可以将整个数据分割成几个文件,文件数量就是我们指定的桶的数量。如下示例,我们按照年龄分桶,一共指定四个桶。
create table psnbucket(id int,name string,age int)
clustered by(age) into 4 buckets
row format delimited fields terminated by ',';然后像表中插入数据。插入数据的时候按照hash算法,将记录存放到不同的桶中。
insert into table psnbucket select id,name,age from psn6;查看hadoop文件系统,可以发现一共四个文件存储目录。
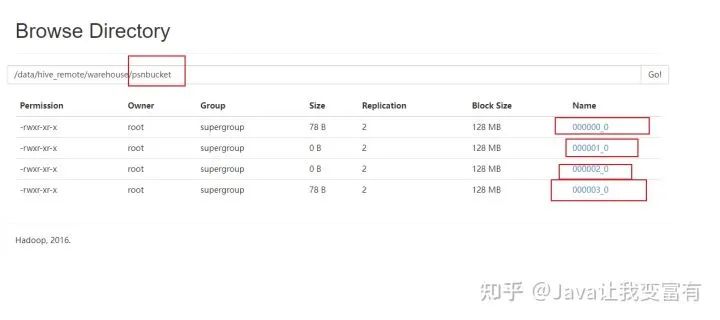
接下来我们查询其中一个桶的数据。由于我们的年龄只有11和12,可想而知,我们的两个桶肯定没有数据,两个桶各自6条数据。
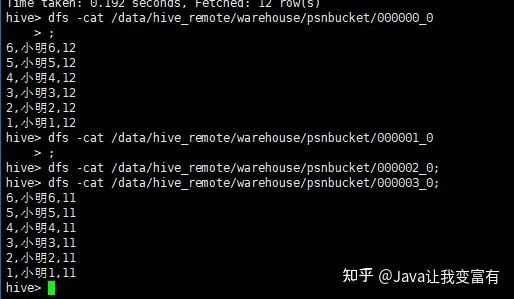
分桶取数据: