
全球首个!7nm世界最大芯片打造AI集群,解锁120万亿「大脑级」AI模型

新智元报道
新智元报道
来源:wired
编辑:yaxin su Catherine
【新智元导读】突触是神经网络的「桥梁」。今日,Cerebras 宣布世界首个「大脑级」AI 集群,能够训练120万亿参数模型,击败人脑百万亿个突触!
突触,是神经网络的「桥梁」。
人类大脑有大约 100 万亿个突触,860 亿个神经元。
因为有了突触,才可以把神经元的电信号传递到下一神经元。
而现在,Cerebras 宣布了「第一个大脑级 AI 解决方案」!
一个可以支持 120 万亿参数 AI 模型的单一系统,击败了人脑万亿个突触。

相比之下,最大的AI硬件集群大约占人类大脑规模的 1%,约 1 万亿个突触(参数)。
Cerebras 可以通过单个CS-2系统(85万个内核)实现首创!

世界第一!192个AI集群,解锁万亿参数模型
参数越多,人工智能模型就越复杂。
谷歌在短短2年内将模型参数的数量提高了大约1000倍。

参数的数量,所需的算力,都呈指数级增长。

Cerebras 的创始人兼首席执行官Andrew Feldman表示,最新的处理器如此强大的原因就是,在晶片上打造而不是单个芯片上。

192个 CS-2 集中在一起,将使最大的人工智能神经网络的规模扩大100倍。
Cerebras系统由其第二代晶圆WSE-2提供动力。
WSE-2 有2.6万亿个晶体管和85万个AI优化内核,再次刷新记录。

相比之下,最大的图形处理器只有540亿个晶体管,比 WSE-2少2.55万亿个晶体管。
与英伟达相比,WSE-2还拥有内核数是A100的123倍;缓存是其1000倍;可提供的内存带宽,则达到了A100的13万倍。
「大脑级」 AI 解决方案
首个大脑级 AI 解决方案如何诞生呢?
除了用到最大芯片,Cerebras还揭露了4项新技术。
这种技术组合可以轻松组建大脑规模的神经网络,并将工作分配到人工智能优化的核心集群上。

一、Cerebras Weight Streaming:分解计算和内存
这是一种新的软件执行模式,可以将计算和参数存储分解,使规模和速度得以独立且灵活地扩展,同时解决了小型处理器集群存在的延迟和内存带宽问题。
具体来说,这项技术首次实现了在芯片外存储模型参数,同时提供与在芯片上相同的训练和推理性能。
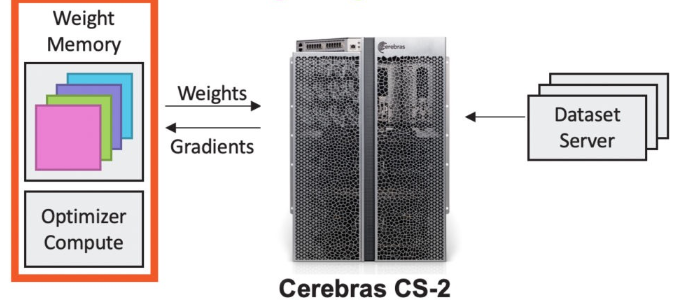
建立在WSE庞大规模的基础上,一个小型参数存储可以连接包含数千万个内核的许多晶圆,或者说,120 万亿个参数模型需要的 2.4 PB 存储可以分配给单个 CS-2。
模型权重保存在中央芯片外,它们被传输到晶片上,用于神经网络每一层的计算。
在神经网络的增量训练中,梯度从晶圆流到中央存储,然后被用于更新权重。

最终,用户可以将 CS-2 的使用数量从1个扩展到192个,同时无需更改软件。
二、Cerebras MemoryX:启用百万亿参数模型
这是一种一内存扩展技术,它使模型参数能够存储在芯片外,并有效地流式传输到 CS-2,实现同在芯片上那样的性能。
这一架构灵活性极强,支持4TB 到 2.4PB 的存储配置,2000 亿到 120 万亿的参数大小。
也就是说,最终,WSE 2可以提供高达 2.4 PB 的高性能内存,CS-2 可以支持具有多达 120 万亿个参数的模型。
三、Cerebras SwarmX:提供更大、更高效的集群
这是一种人工智能优化的高性能通信结构,可将 Cerebras的芯片内结构扩展到芯片外,从而扩展AI集群,而且使其性能实现线性扩展。
也就是说,10 个 CS-2 有望实现比单个 CS-2 快 10 倍的相同解决方案。
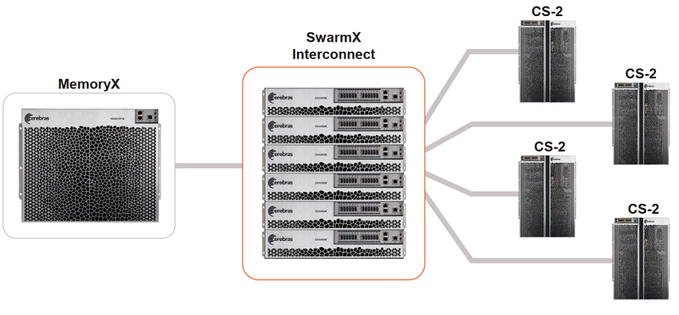
最终,SwarmX 可以将CS-2 系统从2个扩展到192 个,鉴于每个 CS-2 提供85万个 AI 优化内核,Cerebras 便可连接 1.63 亿个 AI 优化内核集群。
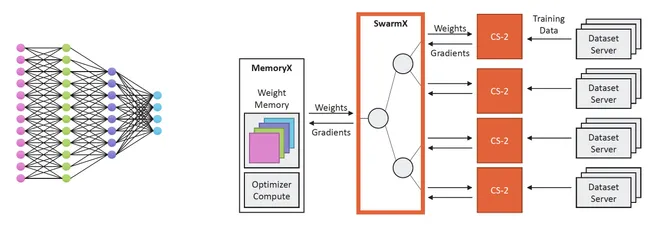
连接SwarmX的 CS-2 计算机接收神经网络的权重流、分割后的训练数据,同时计算传送到 MemoryX 的反向传播梯度。
四、Selectable Sparsity:缩短时间
Cerebras WSE 基于细粒度数据流架构,其 85万个 AI 优化计算内核可以单独忽略零。
Cerebras 架构独有的数据流调度和巨大的内存带宽,使这种类型的细粒度处理能够加速所有形式的稀疏性。

Cerebras
简言之,用户可以在他们的模型中选择权重稀疏程度,直接减少 FLOPs 和解决时间。
比iPad还大,「巨无霸」芯片迭代史
「巨芯」一代问世,大有可为
科技行业日新月异,变化发展飞快。芯片行业更是如此,之前再先进的工艺,两年后就有可能面临淘汰。这是信息时代不可逆转的趋势。
作为全球芯片龙头,NVIDIA依然占据着庞大的市场份额。
位于美国硅谷的AI创企Cerebras虽然没有NVIDIA那么全面,但其技术解决方案显然已经吸引到了许多客户。
早在2019年,Cerebras曾发布了第一代WSE(Wafer Scale Engine)芯片。
这款芯片是有史以来最大的AI芯片,有40万个内核和1.2万亿个晶体管,使用台积电16nm工艺制程。

与多数芯片不同,一代「巨芯」不是在12英寸硅晶圆上制作的,而是在单个晶圆上通过互联实现的单芯片。互联设计可保持高速运行,使万亿个晶体管同时工作。
与传统芯片相比,WSE还包含3000倍的高速片上存储器,并具有10000倍的存储器带宽。WSE的总带宽为每秒100 petabits,不需要诸如TCP/IP和MPI之类的通信协议支持。
由于大芯片可以更快处理信息,减少训练时间,研究人员能够测试更多想法。WSE的问世在当时消除了整个行业进步的主要瓶颈。
「巨芯」二代另辟蹊径,良率更高
2021年,Cerebras推出了最新的Wafer Scale Engine 2(WSE-2)芯片,该芯片为超级计算任务而构建,具有破纪录的2.6万亿个晶体管和85万颗AI优化内核,采用台积电的7nm工艺制造。
与第一代WSE芯片相比,二代芯片更加先进。

WSE-2的晶体管数、内核数、内存、内存带宽和结构带宽等性能特征增加了一倍以上。
在先进工艺的支持下,Cerebras 可以在同样的8*8英寸,面积约46225mm2的芯片中塞进更多的晶体管。
而且,正是采用了台积电的7nm工艺,电路之间的宽度仅有七十亿分之一米。
当有内核发生故障时,单独的故障内核并不影响芯片的使用。况且在台积电这样的晶圆代工厂中,很少会出现连续的内核缺陷。
由此可见,二代「巨芯」的良率较高。
参考资料:
https://www.wired.com/story/cerebras-chip-cluster-neural-networks-ai/
https://www.tomshardware.com/news/worlds-largest-chip-unlocks-brain-sized-ai-models-with-163-million-core-cluster

