
Parquet 实践 | Uber 在 Apache Parquet 中使用 ZSTD 减少存储实践
背景
我们基于 Apache Hadoop® 的数据平台以最小的延迟支持了数百 PB 的分析数据,并将其存储在基于 HDFS 之上的数据湖中。我们使用 Apache Hudi™ 作为我们表的维护格式,使用 Apache Parquet™ 作为底层文件格式。我们的数据平台利用 Apache Hive™、Apache Presto™ 和 Apache Spark™ 进行交互和长时间运行的查询,满足 Uber 不同团队的各种需求。
Uber 在过去几年的增长使数据量和处理数据所需的相关访问负载成倍增加。随着数据量的增长,相关的存储和计算成本也在增长,从而导致硬件采购需求的增长、更高的资源使用,甚至导致内存不足(OOM) 或高 GC 停顿。本博客将介绍 Uber 如何解决存储成本效率问题,其中还会涉及到 CPU、IO 和网络的成本解决。
我们启动了几个降低存储成本的计划,包括给旧分区设置 TTL (Time to Live),将数据从热/温存储转移到冷存储,以及在文件格式级别上减少数据大小。在本博客中,我们将重点关注在文件格式级别(主要是在Parquet)上减少存储中的数据大小。
Apache Parquet™ 在 Uber 的使用
Uber 数据是存储在 HDFS 之中的,并注册为原始表或建模表,主要采用 Parquet 格式,还有一小部分采用 ORC 文件格式。本文主要讨论的是 Apache Parquet 格式。Apache Parquet 是一种列式存储文件格式,它支持嵌套数据。在列存储格式中,数据的存储方式是这样的:不同行的同一列数据是紧挨着的存储在一起,这将使列数据的后续编码和压缩更加有效。
Apache Parquet 格式介绍
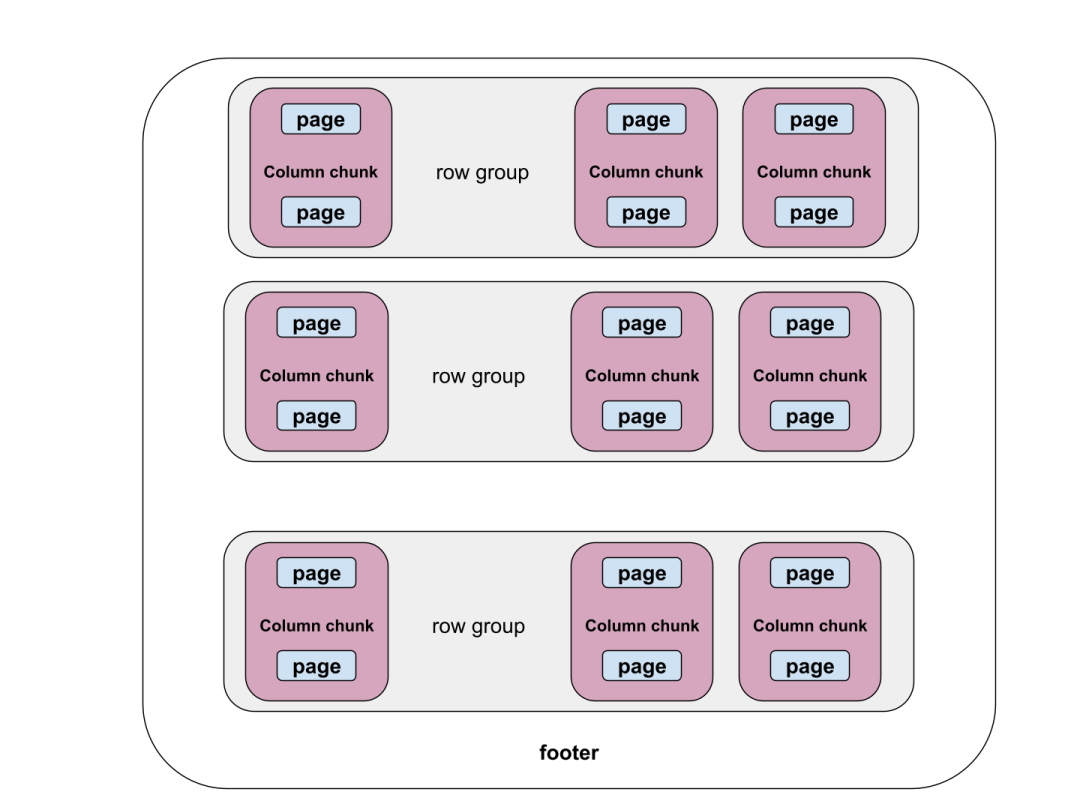
Parquet 格式如下图所示。文件分为行组(row groups),每个行组由每个列的列块(column chunks)组成。每个列块被进一步划分为页(pages),编码和压缩是在页级别进行的。
 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
编码和压缩
写入 Parquet 文件时,列数据被组装到页中,页是编码和压缩的最小单位。Parquet 提供了多种编码机制,包括普通编码、字典编码(dictionary encoding)、游程编码(RLE、run-length encoding)、增量编码(delta encoding)和字节分割编码(byte split encoding)。大多数编码都支持连续零,因为这样可以提高编码效率。编码后的压缩将使数据的大小更小,这个过程不会丢失信息。Parquet 中有几种压缩方法,包括 SNAPPY、GZIP、LZO、BROTLI、LZ4 和 ZSTD。通常,选择正确的压缩方法需要在压缩比和读写速度之间进行权衡。
Uber 的 Parquet 的事情情况
Uber 的数据湖平台使用 Apache Hudi,它是在 Uber 开发并开源的,因为表格式(table format)和 Parquet 是 Hudi 文件格式的头等公民。我们的数据平台利用了 Apache Hive、Apache Presto 和Apache Spark 来实现交互式和长时间运行的查询。Parquet 也是 Spark 中存储格式的一等公民;Presto 也支持 Parquet 文件格式,同时对其进行了大量的优化。Hive 是唯一一个生成 ORC 格式数据的引擎,但是 Hive 有很大一部分生成的表也是 Parquet 格式的。简而言之,Parquet 是 Uber 的主要文件格式。因此,下面讨论的措施是围绕着 Parquet 的优化或添加 Parquet 工具来实现存储成本效率的目标。
文件格式的成本效率举措(Parquet)
将 ZSTD (Zstandard) 压缩引入 Uber Data Lake
ZSTD 介绍
ZSTD 可以实现更高的压缩比,同时保持合理的压缩和解压缩速度(更多信息可以在这里找到)。它提供从1到22的压缩级别,因此用户可以选择压缩比和压缩速度之间的权衡。通常,当压缩级别增加时,压缩比也会增加,但代价是牺牲压缩速度。
ZSTD 与 GZIP 和 SNAPPY 的比较
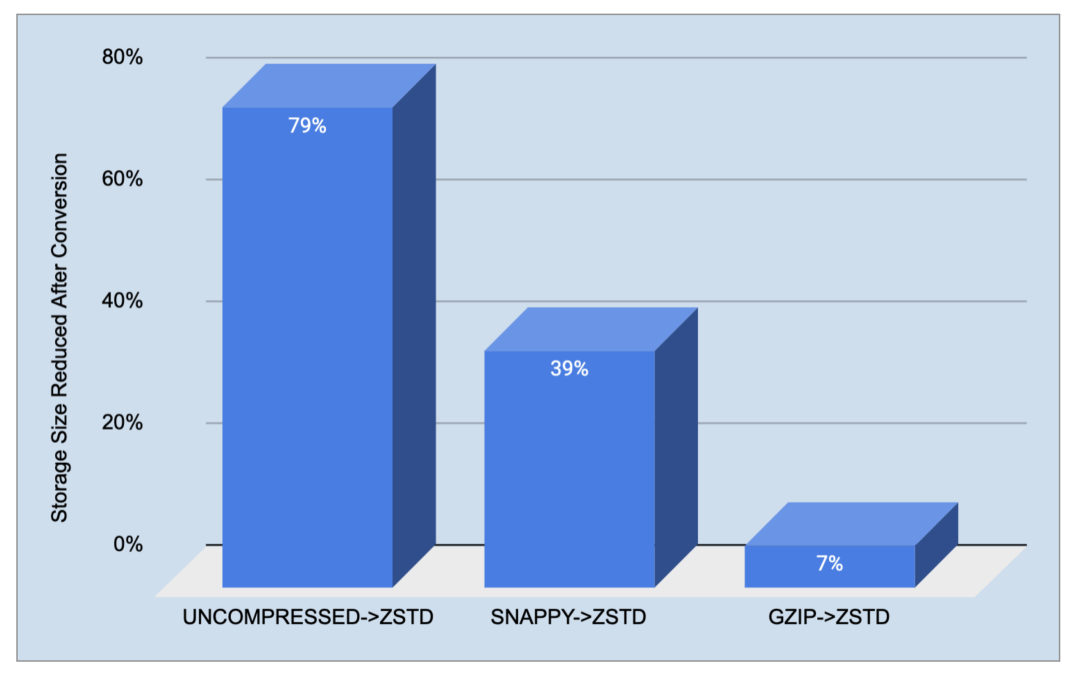
在本项目实施之前,我们的数据湖主要使用 GZIP 和 SNAPPY 压缩。我们对使用 GZIP/SNAPPY 压缩后读取数据的存储大小减少和 vCore 使用情况进行了基准测试。
我们挑选了排名前 10 大的 Hive 表,将它们转换为 ZSTD,并观察到以下效果:从 GZIP 到 ZSTD(默认压缩级别 3),我们观察到存储大小下降了约 7%,而从 SNAPPY 到 ZSTD,我们看到约 39% 的减少。令人惊讶的是,我们的数据湖中仍有一些未压缩的表。使用 ZSTD 压缩它们时可以大约减少 79% 的大小。
 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
虽然我们看到文件大小减少,但是我们希望在使用 ZSTD 替代 GZIP 和 SNAPPY 后在计算(查询的 vCore 持续时间)指标等方面的基准测试。
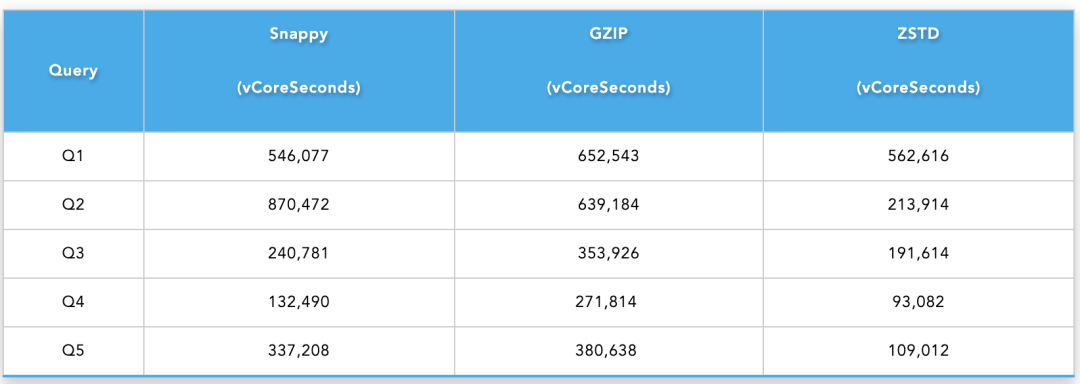
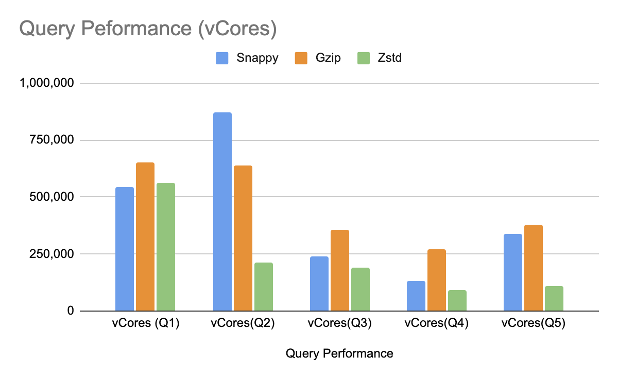
我们使用不同的 Hive 查询进行了基准测试,并比较了使用不同压缩方法压缩的数据的 vCore 使用时间。我们选择这些查询是为了尽可能地模仿真实的用例。
query_1 (Q1):全表扫描查询;query_2 (Q2):带有 Shuffle 的全表扫描查询;query_3 (Q3):带有条件过滤的全表扫描查询;query_4 (Q4):具有条件过滤、聚合和 Shuffle 操作的全表扫描查询;query_5 (Q5):具有条件过滤和 unnest row 转换的全表扫描查询。下表显示了基准比较结果。
 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
总的来说,从 GZIP/SNAPPY 转换到 ZSTD 时,我们看到了比较好的结果,这不仅体现在减少存储大小,而且还节省了 vCore 使用时间。
ZSTD 压缩级别测试
如前所述,ZSTD 支持 22 个压缩级别。当压缩级别发生变化时,压缩比和资源消耗之间存在权衡。我们想对数据减少量与压缩级别、读/写时间与压缩级别进行基准测试。这一次,我们选择 GZIP 作为基线。从 GZIP 转换到 ZSTD 时,我们选择了从 1 到 22 的压缩级别并检查了结果。
我们通过从 3 张表中选择 65 个 Parquet 文件来设置我们的基准测试,其中每个文件的大小约为 1 GB。这些文件是使用 GZIP 压缩的。测试通过使用 GZIP 解压缩将数据读入内存,然后通过使用 ZSTD 将数据压缩回 Parquet 格式来写入数据。我们运行了 22 个循环,每个循环的压缩级别从 1 到 22。基准测试结果如下所示:
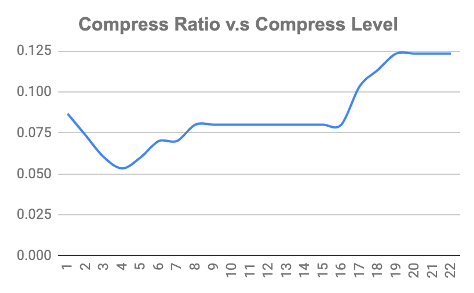
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
上图显示,随着压缩的增加,存储大小也会减少。有趣的是,当压缩级别从 1 变为 2 时,压缩率变小。从第 8 级到第 17 级,压缩率变化不大。我们没有看到随着压缩级别的变化压缩率也跟着一起变化,但我们确实看到了随着压缩级别的增加,压缩率也会变大。
下图显示了压缩级别更改时的写入和读取时间。我们可以看到,当压缩级别增加时,写入时间也会增加,而解压缩时间保持不变。
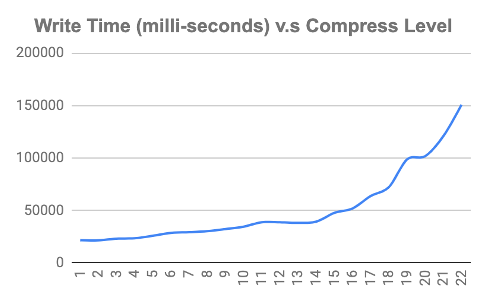
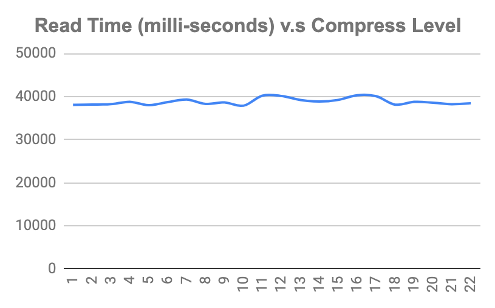
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
基准测试结果帮助我们根据用例决定正确的压缩级别。对于将现有数据从 GZIP 离线转换到 ZSTD,我们可以选择更高的压缩级别,同时牺牲压缩写时间,这是离线作业可以容忍的。我们选择的压缩级别为19,因为当写入时间增加时,超过这个级别并不会对减小数据大小有好处。好消息是,读取时间保持不变,因此无论我们选择何种压缩级别,都不会影响客户的查询速度。
让 Parquet 支持 ZSTD
Parquet(1.11.1 及更低版本)支持 ZSTD,但依赖于 Hadoop(2.9.1 或更高版本)提供的实现。Uber 的 Hadoop 运行在比这更早的版本上,所以升级需要付出巨大的努力。此外,如果依赖 Hadoop,本地开发会很痛苦,因为在本地主机上中部署 Hadoop 会很困难。我们主动将 Hadoop ZSTD 替换为 ZSTD-JNI,这是一个链接到 Parquet 的包装包,让我们避免部署 Hadoop。更改已合并到 Parquet 1.12.0 及更高版本。对于 Hive 和 Spark,这足以支持 ZSTD,但 Presto 是另一回事。Presto 重写了 Parquet 的某些部分,它的压缩是使用 airlift 包。不过我们对其进行了相关修改,并开源给社区(#15939),以使其支持 ZSTD。
列删除
当创建一张表时,表所有者可以创建他们想要的任何列,因为没有相关的数据治理。但其中一些列可能不会被使用,而那些未使用的列占用了大量空间。我们发现,在删除未使用的列后,仅一张表就可以节省 PB 级别的数据。
为了找到需要删除的列,我们通过分析表血缘(table linkage)和审计日志来检测是否使用了某个列。我们还开发了一个 Parquet 工具来估计要移除的列的大小。这个工具已经合并到开源版本中 PARQUET-1821 中。
最初,我们使用 Spark 进行列删除。它将数据读入内存,删除列,然后写回文件,但这非常慢,因为它涉及许多耗时的操作(编码/解码,shuffle 操作等)。为了以高吞吐量的方式运行列删除,我们开发了一个工具,可以在文件复制过程中删除列,直接跳过要删除的列。这样,速度非常快,因为它只复制文件。与直接使用 Spark 相比,这种方式速度提高了 20 倍。Parquet 列修剪(Parquet column prune)工具已经开源了,已合并到社区版的 Parquet,具体参考 PARQUET-1800
我们的数据湖使用 HDFS 进行存储,它不支持就地更新文件。因此,我们使用该工具删除所需的列,并将新文件放在具有完全相同的文件名和权限的新位置。我们将保持 HMS 和 Hudi schema 不变,并保持超出该时间范围的文件不变。有一个已知问题是多个在线 rewriter 在同一时间位置访问数据会产生冲突,我们的长期目标是将这个 rewriter 嵌入到 Hudi 集群中,从而在 writers 和 rewriters 之间进行协调。
下图显示了文件是如何更改的,以及保存了哪些内容:
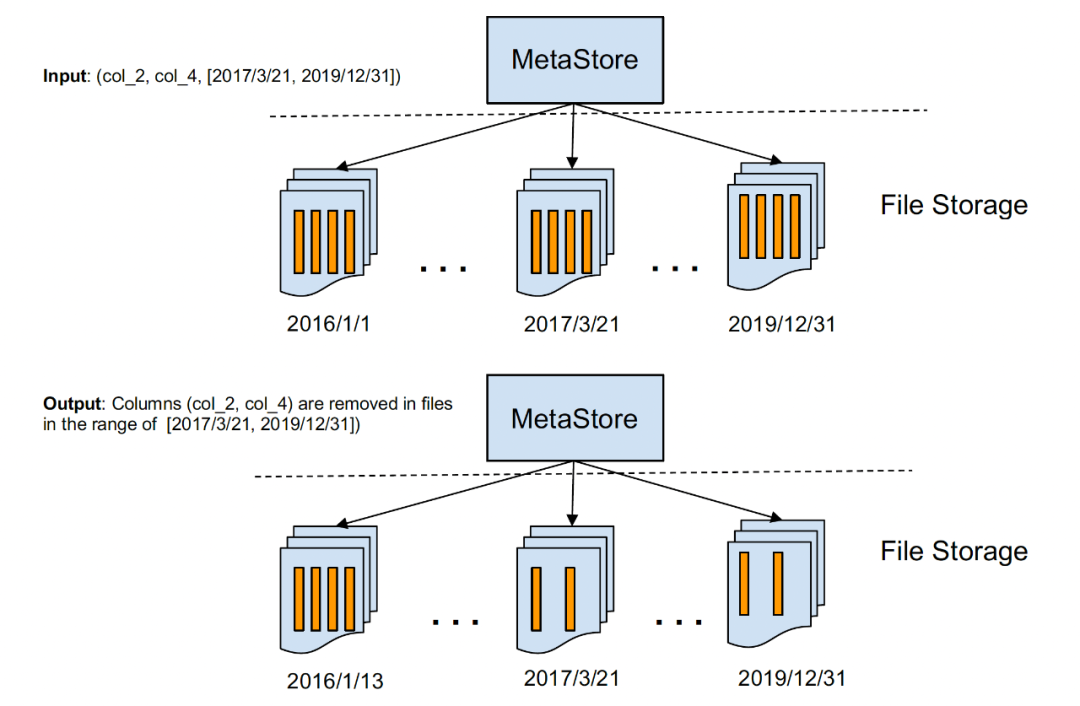
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
多个列重新排序
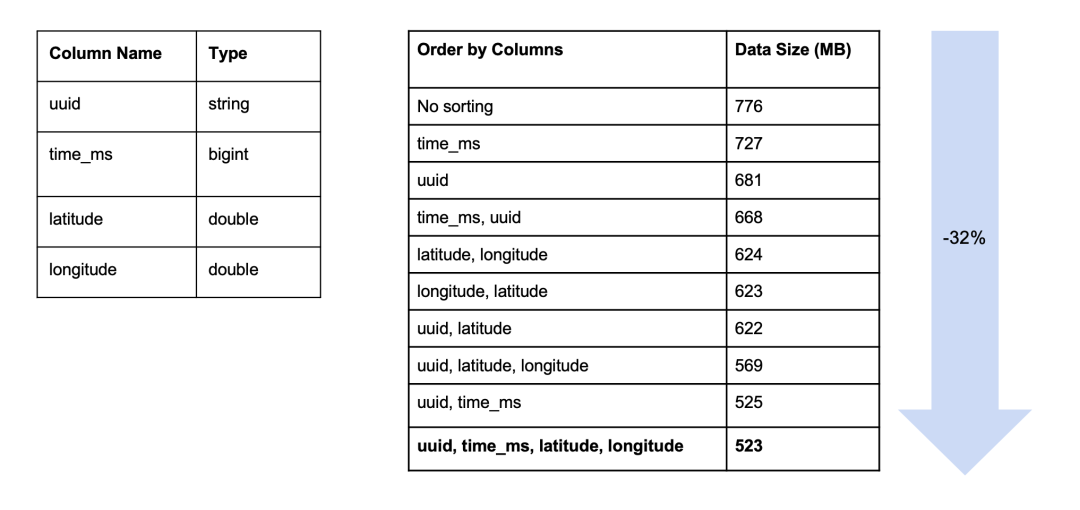
我们用来减少 Parquet 文件大小的另一种技术称为列重新排序。在对列进行排序后,通过将相似的数据排序在一起,编码和压缩的效率更高。受《Reordering Rows for Better Compression: Beyond the Lexicographic Order》这篇论文启发,我们投入精力对不同列进行排序所获得空间的节省进行基准测试。实验涉及到一张表,其含有一个分区以及4个列,分别为 uuid 字段类型为 string,time_ms 字段类型为 bigint,以及 latitude 和 longitude 字段类型为 double。我们按照不同的顺序对它们进行排序。结果表明,排序会影响数据的大小。最终,我们看到相比对数据不进行排序,按照 UUID, time_ms, latitude, longitude 顺序对数据进行排序后数据大小减少了 32%。
 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
关键要点
ZSTD 的兴起
我们将大量的数据从 GZIP/SNAPPY 转换到 ZSTD,并观察到存储空间的巨大减少。除了节省存储,我们还通过 ZSTD 减少了 vCore 的使用。我们将自己的修改合并进社区的 Apache Parquet 仓库 ,包括“用 JNI-ZSTD 替换 Hadoop ZSTD ”和“添加 trans-compression 命令”。第一个变化消除了对设置 Hadoop 的依赖,第二个依赖增加了从 GZIP/SNAPPY 转换到 ZSTD 的压缩速度。
从高吞吐量列剪枝到删除未使用的列
在大数据分析表中,有些列可能非常大,但从未使用过,例如 UUID 列。删除未使用的列将节省大量存储空间。依靠查询引擎的列级审计日志,我们可以检测到未使用的列。我们还引入了一个列修剪工具,并将代码更改合并到 Apache Parquet 仓库中。使用这个工具而不是使用查询引擎的好处是速度快,该工具的速度接近复制文件的速度,远快于查询引擎。
下一步
增量编码(Delta Encoding )
增量编码是由 D. Lemire 和 L. Boytsov 在 《Decoding billions of integers per second through vectorization》论文中描述的 Binary packing 而来。这种编码类似于 RLE/bit-packing 编码。但是,当整数的范围在整个页面(entire page.)上很小时,就会特别使用 RLE/bit-packing 编码。增量编码算法对编码整数大小的变化不太敏感。
字节分割编码(Byte Splitting Encoding )
字节流分割编码(Byte Stream Split)被引入到 Apache Parquet 1.12.0。这种编码本身并不会减少数据的大小,但在之后使用压缩算法时可以显着提高压缩率和速度。这种编码创建了几个字节流,每个值的字节被分散到相应的流中。因此,像“0”这样的相同值的长度会增加,并有利于后面的 RLE。
这种编码创建了长度为 N 的 K 个字节流,其中 K 是数据类型的字节大小,N 是数据序列中元素的个数。每个值的字节分散到相应的流中。第 0 个字节进入第 0 个流,第 1 个字节进入第 1 个流,依此类推。流按以下顺序连接:第 0 个流、第 1 个流等。
总结
文件格式是许多公司忽略的一个方面。我们证明,在这一领域的投资(例如,改进压缩、编码、数据排序等)会带来巨大的投资回报。
ZSTD 是一种有效的压缩技术,它不仅可以提高数据的存储效率,而且可以提高数据的读取速度。在我们的工作被合并到开源(1.12.0+)之后,在 Parquet 中使用 ZSTD 不再需要 Hadoop 设置了。
列删除是一个具有挑战性的领域,但也有效地检测未使用的巨型列并删除它们以节省巨大的空间。
列排序和降低 decimal 精度,以及字节流分割等高级编码,可以实现更高的压缩比和节省存储空间。
大规模地转换现有数据以应用上述技术是一项挑战。我们在 Parquet 上进行了多项创新,将速度提高了10倍,使转换速度更快。相关更改已经合并到社区的 Parquet 中。
我们要感谢 Roshan Savio Lasrado 对 ZSTD 性能基准测试的巨大贡献!
本文翻译自《Cost Efficiency @ Scale in Big Data File Format》 https://eng.uber.com/cost-efficiency-big-data/