
深度长文:深入理解Ceph存储架构


本文是一篇Ceph存储架构技术文章,内容深入到每个存储特性,文章由Ceph中国社区穆艳学翻译,耿航校稿,以下是具体内容:
目录
第1章 概览
第2章 存储集群架构
2.1 存储池
2.2 身份认证
2.3 PG(s)
2.4 CRUSH
2.5 I/O操作
2.5.1 副本I/O
2.5.2 纠删码I/O
2.6 自管理的内部操作
2.6.1 心跳
2.6.2 同步
2.6.3 数据再平衡与恢复
2.6.4 校验(或擦除)
2.7 高可用
2.7.1 数据副本
2.7.2 Mon集群
2.7.3 CephX
第3章 客户端架构
3.1 本地协议与Librados
3.2 对象的监视与通知
3.3 独占锁
3.4 对象映射索引
3.5 数据条带化
第4章 加密
第1章 概览
Red Hat Ceph是一个分布式的数据对象存储,系统设计旨在性能、可靠性和可扩展性上能够提供优秀的存储服务。分布式对象存储是存储的未来,因为它们适应非结构化数据,并且客户端可以同时使用现代及传统的对象接口进行数据存取。例如:
本地语言绑定接口(C/C++、Java、Python)
RESTful 接口(S3/Swift)
块设备接口
文件系统接口
Red Hat Ceph所具备的强大功能可以改变您公司(或组织)的IT基础架构和管理海量数据的能力,特别是对于像RHEL OSP这样的云计算平台。
Red Hat Ceph具有非常好的可扩展性——数以千计的客户端可以访问PB级到EB级甚至更多的数据。
译者注: 数据的规模可以用KB、MB、GB、TB、PB、EB、YB等依次表示,比如1TB = 1024GB。
每一个Ceph部署的核心就是Ceph存储集群。 集群主要是由2类后台守护进程组成:
Ceph OSD守护进程:Ceph OSD为Ceph客户端存储数据提供支持。另外,Ceph OSD利用Ceph节点的CPU和内存来执行数据复制、数据再平衡、数据恢复、状态监视以及状态上报等功能。
Ceph 监视器:Ceph监视器使用存储集群的当前状态维护Ceph存储集群映射关系的一份主副本。

Ceph客户端接口与Ceph存储集群进行数据读写上的交互。客户端要与Ceph存储集群通信,则需要具备以下条件:
Ceph配置文件,或者集群名称(通常名称为ceph)与监视器地址
存储池名称
用户名及密钥所在路径
Ceph客户端维护对象ID和存储对象的存储池名称,但它们既不需要维护对象到OSD的索引,也不需要与一个集中的对象索引进行通信来查找数据对象的位置。
为了能够存储并获取数据,Ceph客户端首先会访问一台Ceph mon并得到最新的存储集群映射关系,然后Ceph客户端可以通过提供的对象名称与存储池名称,使用集群映射关系和CRUSH算法(可控的、可扩展的、分布式的副本数据放置算法)来计算出提供对象所在的PG和主Ceph OSD,最后,Ceph客户端连接到可执行读写操作的主OSD上进而达到数据的存储与获取。客户端和OSD之间没有中间服务器,中间件或总线。
当一个OSD需要存储数据时(无论客户端是Ceph Block设备,Ceph对象网关或其他接口),从客户端接收数据然后将数据存储为对象。每一个对象相当于文件系统中存放于如磁盘等存储设备上的一个文件。
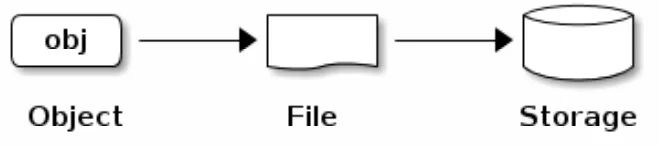
注: 一个对象的ID在整个集群中是唯一的,(全局唯一)而不仅仅是本地文件系统中的唯一。
Ceph OSD将所有数据作为对象存储在扁平结构的命名空间中(例如,没有目录层次结构)。对象在集群范围内具有唯一的标识、二进制数据、以及由一组名称/值的键值对组成的元数据。而这些语义完全取决于Ceph的客户端。例如,Ceph块设备将块设备镜像映射到集群中存储的一系列对象上。

注: 由唯一ID、数据、名称/值构成键值对的元数据组成的对象可以表示结构化和非结构化数据,以及前沿新的数据存储接口或者原始老旧的数据存储接口。
第2章 存储集群架构
为了有效的实现无限可扩展性、高可用性以及服务性能,Ceph存储集群可以包含大量的Ceph节点。每个节点利用商业硬件以及智能的Ceph守护进程实现彼此之间的通信:
存储和检索数据
数据复制
监控并报告集群运行状况(心跳)
动态的重新分布数据(回填)
确保数据完整性(清理及校验)
失败恢复
对于读写数据的Ceph客户端接口来说,Ceph存储集群看起来就像一个存储数据的简单存储池。然而,存储集群背后却是对客户端接口完全透明的方式并且会执行许多复杂的操作。Ceph客户端和Ceph OSD都使用CRUSH算法(可控的、可扩展的、分布式的副本数据放置算法),后面的章节会详细讲解CRUSH算法。
2.1 存储池
Ceph存储集群通过‘存储池’这一逻辑划分的概念对数据对象进行存储。可以为特定类型的数据创建存储池,比如块设备、对象网关,亦或仅仅是为了将一组用户与另一组用户分开。
从Ceph客户端来看,存储集群非常简单。当有Ceph客户端想读写数据时(例如,会调用I/O上下文),客户端总是会连接到存储集群中的一个存储池上。客户端指定存储池名称、用户以及密钥,所以存储池会充当逻辑划分的角色,这一角色使得对数据对象访问进行控制。
实际上,存储池不只是存储对象数据的逻辑划分,它还扮演着Ceph存储集群是如何分布及存储数据的角色,当然了,这些复杂的操作对客户端来说也是透明的。Ceph存储池定义了:
存储池类型:在以前的老版本中,一个存储池只是简单的维护对象的多个深拷贝。而现在,Ceph能够维护一个对象的多个副本,或者能够使用纠删码。正因为保证数据持久化的2种方法(副本方式与纠删码方式)存在差异,所以Ceph 支持存储池类型。存储池类型对于客户端也是透明的。
PG:在EB规模的存储集群中,一个Ceph存储池可能会存储数百万或更多的数据对象。因为Ceph必须处理数据持久化(副本或纠删码数据块)、清理校验、复制、重新再平衡以及数据恢复,因此在每个对象基础上的管理就会出现扩展性和性能上的瓶颈。Ceph通过散列存储池到PG的方式来解决这个瓶颈问题。CRUSH则分配每一个对象到指定的PG中,每个PG再到一组OSD中。
CRUSH规则集:Ceph中,高可用、持久化能力以及性能是非常重要的。CRUSH算法计算用于存储对象的PG,同时也用于计算出PG的OSD Acting Set
译者注:acting set即为活跃的osd集合,集合中第一个编号的osd即为主primary OSD。
CRUSH也扮演着其他重要角色:即CRUSH可以识别故障域和性能域(例如,存储介质类型、nodes, racks, rows等等)。CRUSH使得客户端可以跨故障域(rooms, racks, rows等等)完成数据的写入以便当节点出现粒度比较大的问题时(例如,rack出问题)集群仍然可以以降级的状态提供服务直至集群状态恢复。CRUSH也可使客户端能够将数据写入特定类型的硬件中(性能域),例如SSD或具有SSD日志的硬盘驱动器,亦或具有与数据驱动相同驱动的日志硬盘驱动器。对于存储池来说,CRUSH规则集决定了故障域以及性能域。
数据持久化方式:在EB规模的存储集群中,硬件故障因为可预期所以一般并不算异常。当使用数据对象表示较大粒度的存储接口时(例如块设备),对于这种大粒度存储接口来说,对象的丢失(不管是1个还是多个)都可能破坏数据的完整性进而导致数据不可用。因此,数据丢失是不可容忍也是不能接受的。Ceph提供了2种持久化方式:第1种为副本存储池方式,这种方式将多份相同内容的数据对象通过CRUSH进行故障域的隔离来存储到不同的节点上(比如将对象分别存储在硬件相互隔离的不同节点上),这样即使硬件问题也不会对数据的持久化能力产生什么大的影响;第2种为纠删码存储池方式,这种方式将对象存储到K+M 个块中,其中K表示数据块,M 表示编码块。K+M的和表示总的OSD数量,可以支持最多同时有M 个OSD出现问题,数据也不会丢失。
从客户端角度来看,Ceph对外呈现显得优雅而简单。客户端只需要读取或写入数据到存储池。但是,存储池在数据持久化,性能以及高可用方面发挥着重要的作用。
2.2 身份认证
为了识别用户并防止中间人攻击,Ceph提供了cephx认证系统来验证用户和守护进程。
注: Cephx协议并不处理传输中的数据加密(例如SSL/TLS)也不处理静态数据加密。
Cephx使用共享的密钥进行认证,这也意味着客户端和mon都会有客户端密钥副本。认证协议也就是双方都能够向对方证明他们拥有密钥的副本,而不会实际泄露密钥。这种方式提供了相互认证的机制,意味着集群确信用户拥有密钥以及用户确信集群拥有密钥的副本。
2.3 PG(s)
Ceph将存储池分片处理成在集群中均匀且伪随机分布的PG。CRUSH算法将每个对象分配到一个指定的PG中,并且将每个PG分配到对应的Acting Set集合中—也就是在Ceph客户端和存储对象副本的OSD之间创建一个间接层。 如果Ceph客户端直接就能知道对象存放到具体的哪个OSD中的话,那么Ceph客户端和Ceph OSD之间耦合性就太强了。
相反的,CRUSH算法会动态的将对象分配到PG中,然后再将PG分配到一组Ceph的OSD中。有了这个间接层之后,当新Ceph OSD加入或者Ceph OSD出现问题时,Ceph存储集群就可以动态的进行数据再平衡。通过在数百到数千个放置组的环境中管理数百万个对象,Ceph存储集群可以高效地增长和收缩以及从故障中恢复。
下面的图描述了CRUSH是如何将对象分配到PG中,以及PG分配到OSD中的。

相对整体集群规模来说,如果存储池设置的PG较少,那么在每个PG上Ceph将会存储大量的数据;如果存储池设置的PG过大,那么Ceph OSD将会消耗更多的CPU与内存,不管哪一种情况都不会有较好的处理性能。 所以,为每个存储池设置适当数量的PG,以及分配给集群中每个OSD的PG数量的上限对Ceph性能至关重要。
译者注: PG是对象的集合, 在同一个集合里的对象放置规则都一样(比如同一集合中的对象统一都存储到osd.1、osd.5、osd.8这几台机器中);同时,一个对象只能属于一个PG,而一个PG又对应于所放置的OSD列表;另外就是每个OSD上一般会分布很多个PG。
2.4 CRUSH
Ceph会将CRUSH规则集分配给存储池。当Ceph客户端存储或检索存储池中的数据时,Ceph会自动识别CRUSH规则集、以及存储和检索数据这一规则中的顶级bucket。当Ceph处理CRUSH规则时,它会识别出包含某个PG的主OSD,这样就可以使客户端直接与主OSD进行连接进行数据的读写。
为了将PG映射到OSD上,CRUSH 映射关系定义了bucket类型的层级列表(例如在CRUSH映射关系中的types以下部分)。创建bucket层级结构的目的是通过其故障域和(或)性能域(例如驱动器类型、hosts、chassis、racks、pdu、pods、rows、rooms、data centers)来隔离叶子节点。
除了代表OSD的叶子节点之外,层次结构的其余部分可以是任意的,如果默认类型不符合你的要求,可以根据自己的需要来定义它。 CRUSH支持一个有向无环图的拓扑结构,它可以用来模拟你的Ceph OSD节点在层级结构中的分布情况。
因此,可以在单个CRUSH映射关系中支持具有多个Root节点的多个层级结构。例如,可以创建SSD的层级结构、使用SSD日志的硬盘层级结构等等。
译者注: CRUSH的目的很明确, 就是一个PG如何与OSD建立起对应的关系。
2.5 I/O操作
Ceph客户端从Ceph mon获取‘集群映射关系Cluster map,然后对存储池中的对象执行I/O操作。对于Ceph如何将数据存于目标中来说,存储池的CRUSH规则集和PG数的设置起主要的作用。拥有最新的集群映射关系,客户端就会知道集群中所有的mon和OSD的信息。但是,客户端并不知道对象具体的存储位置(不知道对象具体存在哪个OSD上)。
对于客户端来说,需要的输入参数仅仅是对象ID和存储池名称。逻辑上也比较简单:Ceph将数据存储在指定名称的存储池中(例如存储池名称为livepool)。当客户端想要存储一个对象时(比如对象名叫 “john”、“paul”、"george”、 “ringo”等),客户端则会以对象名、根据对象名信息计算的hash码、存储池中的PG数、以及存储池名称这些信息作为输入参数,然后CRUSH(可控的、可扩展的、分布式的副本数据放置算法)就会计算出PG的ID(PG_ID)及PG对应的主OSD信息。
译者注:根据设置的副本数(比如3副本)则计算出的列表如(osd.1、osd.3、osd.8), 这里的第一个osd.1就是主OSD。
Ceph客户端经过以下步骤来计算出PG ID信息。
客户端输入存储池ID以及对象ID(例如,存储池pool=”liverpool”, 对象ID=”john”)。
CRUSH获取对象ID后对其进行HASH编码。
CRUSH根据上一步的HASH编码与PG总数求模后得到PG的ID。(译者注:例如HASH编码后为186,而PG总数为128,则求模得58,所以这个对象会存储在PG_58中;另外这也可以看出PG数对存储的影响,因为涉及到对象与PG的映射关系,所以轻易不要调整PG数)
CRUSH计算对应PG ID的主OSD。
客户端根据存储池名称得到存储池ID(例如”liverpool”=4)。
客户端将PG ID与存储池ID拼接(例如 4.58)
客户端直接与Activtin Set集合中的主OSD通信,来执行对象的IO操作(例如,写入、读取、删除等)。
译者注: Pool的名称与ID(ID=4,存储池名称为default.rgw.log)。

Ceph存储集群的拓扑和状态在会话(I/O上下文)期间相对比较稳定。与客户端在每个读/写操作的会话上查询存储相比,Ceph客户端计算对象存储位置的速度要更快些。CRUSH算法不但能使客户端可以计算出对象应当存储的位置,同时也使得客户端可以和Acting Set集合中的主OSD直接交互来实现对象的存储与检索。 由于EB规模的存储集群一般会有数千个OSD存储节点,所以客户端与Ceph OSD之间的网络交互并不是什么大的问题。即使集群状态发生变化,客户端也可以通过Ceph mon查询到更新的集群映射关系。
2.5.1 副本I/O
和Ceph客户端一样,Ceph OSD也是通过与Ceph mon交互来获取到最新的集群映射关系。Ceph OSD也使用CRUSH算法,但是用这个算法是用来计算对象的副本应该存储在什么位置(译者注: 客户端用CRUSH是用来找主OSD以及计算出Acting Set列表,而OSD用CRUSH则是主OSD定位对应的副本是谁)。
在典型的写操作场景下,Ceph客户端使用CRUSH算法计算对象所在的PG ID以及Acting Set列表中的主OSD,当客户端将对象写到主OSD时,主OSD会查看这个对象应该存储的副本个数(例如,osd_pool_default_size = n),然后主OSD根据对象ID、存储池名称、集群映射关系这些信息再根据CRUSH算法来计算出Acting Set列表中的从属OSD(译者注: 除列表中第一个OSD外,其它的都是从属OSD)。
主OSD将对象写入从属OSD中,当主OSD收到从属OSD回复的ACK确认并且主OSD自身也完成了写操作后,主OSD才会给Ceph客户端回复真正写入成功的ACK确认。

通过有代表性的Ceph客户端(主OSD)执行数据复制的能力,Ceph OSD守护进程相对的减轻了Ceph客户端的这一职责,同时确保了数据高可用以及安全性。
注: 比较典型的就是主OSD和从属OSD在部署时会将故障域进行隔离(比如不同时配置到一个rack上或一个row上,亦或是同一个node上)。CRUSH计算从属OSD的ID也会考虑故障域信息。
2.5.2 纠删码I/O
纠删码实际上是一种前向错误纠正编码,这种编码会将K个数据块通过补充N个编码块的方式,将原始数据扩展为更长的消息编码,以便当N个数据块出现问题时数据依旧不会丢失。随着时间的推移,开发了不同的纠删编码算法,其中最早和最常用的算法之一是Reed-Solomon算法。
可以通过等式 N = K + M 对这一算法进行理解,等式中 K 表示数据块的个数,M 代表了编码块的个数,而 N 则是在 纠删编码 过程中创建的总的块的个数。值 M 可以简化为 N – K ,也就是说在计算原始的K个数据块时 N – K 个冗余块也一并需要计算出来。这种方法保证只要N个块中的K有效就可以访问所有原始数据。换句话说,即使有 N – K 个块出现了故障,对外提供服务的数据仍旧是没有问题的。
例如配置(N=16,K=10)或者纠删编码 10/16,10个基本的块(K)中会有额外补充的6个块( M = K-N, 如16-10 = 6 ) 。这16个块(N)可能对应16个OSD。即使有6个OSD出现问题,原始文件也可以从这10个已经验证的数据块中重建恢复。这就意味着不会有任何的数据丢失,因此纠删码也具备比较高的容错能力。
和副本存储池类似,纠删码存储池也是由up set列表中的主OSD来接收所有的写操作。在副本存储池中,Ceph对PG中的每个对象在从属OSD上都会有一份一样的数据对象;而对于纠删码存储池来说,可能略有不同。每个纠删码存储池都会以 K+M 个块来存储每一个对象。
对象(的数据内容)会被切分成 K 个数据块以及 M个编码块。纠删码存储池创建时也需要配置成 K+M 的大小(size)以便每个块都可以存储到Activtin Set列表中的每个OSD上。对象的属性存储这些块的等级。主OSD负责数据划分到 K+M 个块的纠删编码以及将这些编码信息发送到其它的OSD上。同时主OSD也会维护PG的权威日志(译者注: 权威日志实际是一种进度控制机制,尤其当某些节点出现问题时,可以根据权威日志进行数据的恢复)。
例如,使用5个OSD (K + M = 5) 创建纠删码存储池,支持其中2个 (M = 2) 块的数据丢失。
将对象写入纠删码存储池中的时候(比如对象名叫 NYAN,内容为 ABCDEFGHI )纠删码计算函数会将对象的内容按长度平分成3个块(即,分成K个数据块),第一个块内容为 ABC , 第二个块内容为DEF , 第三个块内容为 GHI , 如果块内长度不是 K 的倍数,那么平分后最后的一块所剩余的空位就会进行填充以使其长度为K(比如内容串为ABCDEFGHIJ,则3个数据块内容依次为ABCD、EFGH、IJ..,最后的IJ长度不够就会填充);除了将内容按K切分外, 纠删码函数也要创建另外2个编码块,即第4个块内容为 XYZ ,第5个块内容为 GQC 。
这里的每一个块内容都对应Action Set列表中的一个OSD。 这些块有相同的名称都叫 NYAN , 但块存在不同的OSD中。除了名称之外,数据块创建的对应序号需要存储在对象的属性中( shard_t ) 。 包括 ABC 内容的第一个块存储在 OSD5 上,而包括 YXY 内容的第4个块则存储在 OSD3 上。
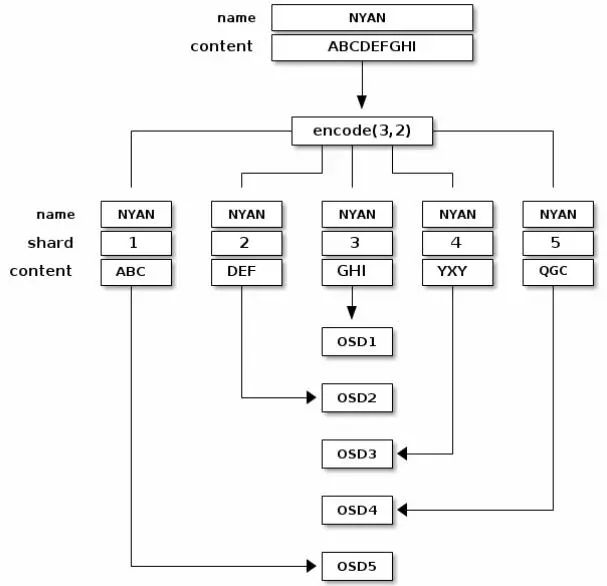
译者注: 注意上图中,5个块的名称都叫NYAN,每个块的内容为K个均分的内容, 同时被切分后的每个块都有一个唯一序号shard, 每个块都对应不同的OSD,即块按HOST进行故障域隔离。
译者注: 比如以下配置及图例中,K=4, M=2 并且以rack作为故障域)
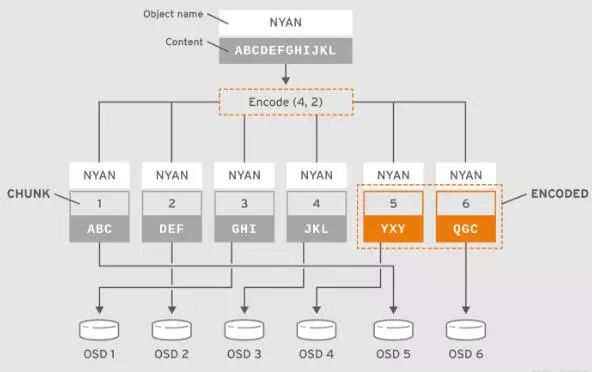
如果从纠删码存储池中读取对象 NYAN, 解码函数需要读取3个块: 包括ABC 的第一个块, 包括GHI 的第3个块以及包括YXY 的第4个块;然后重构出对象的内容ABCDEFGHI 。解码函数来通知第2个块和第5个块缺失(一般称为纠删或擦写)。
可在这2个缺失的块中,第5个块缺失可能因为OSD4 状态是OUT而读不到,只要读到3个块可读的话,解码函数就可以被调用:因为OSD2对应的是最慢的块,所以读取时排除掉不在考虑之内。
将数据拆分成不同的块是独立于对象放置规则的。CRUSH规则集和纠删码存储池配置决定了块在OSD上的放置。例如,在配置中如果使用lrc(局部可修复编码)插件来创建额外块的话,那么恢复数据的话则需要更少的OSD。
例如lrc配置信息: K=4、M=2、L=3 中,使用jerasure插件库来创建6个块(K+M),但局部值(L=3 )则要求需要再创建2个局部块。额外创建的局部块个数可以通过(K+M)/L 来计算得出。如果0号块的OSD出现问题,那么这个块的数据可以通过块1,块2以及第一个局部块进行恢复。在这个例子中,恢复也只需要3个块而不是5个块。关于CRUSH、纠删码配置、以及插件的内容,可以参考存储策略指南。
注: 纠删码存储池的对象映射是失效的,不能设置为有效状态。关于对象映射的更多内容,可以参考对象映射章节。
注: 纠删码存储池目前公支持RADOS网关(RGW),对于RADOS的块设备(RBD)目前还不支持。
2.6 自管理的内部操作
Ceph集群也会自动的执行一些自身状态相关的监控与管理工作。例如,Ceph的OSD可以检查集群的健康状态并将结果上报给后端的Ceph mon;再比如,通过CRUSH算法将对象映射到PG上,再将PG映射到具体的OSD上;同时,Ceph OSD也通过CRUSH算法对OSD的故障等问题进行自动的数据再平衡以及数据恢复。 以下部分我们将介绍Ceph执行的一些操作。
2.6.1 心跳
Ceph OSD加入到集群中并且将其状态上报到Ceph mon。在底层实现上,Ceph OSD的状态就是up或为down ,这一状态反映的就是OSD是否运行并为Ceph客户端的请求提供服务。如果Ceph OSD在集群中的状态是donw且为in ,那么表明此OSD是有问题不能提供服务的;如果Ceph OSD并没有运行(比如服务crash掉了),那么这个Ceph OSD也不能上报给Ceph mon其自身状态为Down 。
Ceph mon会定期的ping 这些OSD以此来确信这些OSD是否仍在运行。当然了,Ceph也提供了更多的机制,比如使Ceph OSD可以评判与之关联的OSD是否状态为down(译者注:比如在副本OSD间相互ping状态的关系,没有副本关系的话,OSD之间不会建立连接亦即更不会ping彼此),以及更新Ceph的集群映射关系并上报给Ceph mon。由于OSD分担了部分工作,所以对于Ceph mon来说,工作内容相对要轻量很多。
2.6.2 同步
Ceph OSD守护进程执行同步,这里的同步指的是将存储放置组(PG)的所有OSD中对象状态(包括元数据信息)达到一致的过程。同步问题通常都会自行解决无需人为的干预。
注: 即使Ceph mon对于OSD存储PG的状态达成一致,这也并不意味着PG拥有最新的内容。
当Ceph存储PG到OSD的acting set列表中的时候,会将它们分别标记为主,从等等。惯例上,Acting set列表中的第一个是主OSD,主OSD也负责协调组内的PG进行同步操作,这里的主OSD也是唯一 接收客户端的写入对象到给定PG请求的OSD。
当一系列的OSD负责一个放置组PG,则这一系列的OSD,我们称它们为一个Acting Set。Acting Set可能指的是当前负责放置组的Ceph OSD守护进程或者某个有效期内,负责特定放置组的OSD守护进程。
Acting Set中的部分Ceph OSD可能不会一直是up 状态。当Acting Set中的OSD状态是up 状态时,那么这个OSD也是Up Set中的成员。相对Acting Set来说,Up Set是非常重要的,因为当OSD失败时,Ceph可以将PG重新映射到其他Ceph OSD上。
注: 对于PG包括osd.25、osd.32、osd.61的Acting Set列表,列表中第一个OSD即osd.25 是主OSD。哪果主OSD失败,那么从属OSD 即osd.32 就会成为新的主OSD,同时原主osd.25 也会从Up Set列表中删除。
2.6.3 数据再平衡与恢复
当我们向Ceph存储集群中新增加Ceph OSD的时候,集群映射关系随着新增加的OSD同时也会更新。因此,由于这一变化改变了计算CRUSH时提供的输入参数,所以也就间接的改变了对象的放置位置。CRUSH算法是伪随机的,但会均匀的放置数据。所以集群中新增加一台OSD时,也只会有一小部分的数据发生迁移。一般迁移的数据量是集群总数据量与OSD数量的比值(例如,在有50个OSD的集群中,当新增加一台OSD时也只有1/50 或者2%的数据受到迁移影响)。
下面的图示描述了部分的PG(非全部PG)从已有的OSD 1,OSD 2上迁移到新OSD 3上达到数据再平衡的过程(因为对大型集群的影响要小得多,所以过程相对粗略一些)。 即使在再平衡过程中,CRUSH也是稳定的。大部分的PG仍然保留着原始的配置,由于新增加了OSD,所以每个OSD都会增加一些(可用的)容量,因此在重新平衡完成后,新的OSD上也不会出现负载峰值的情况。

2.6.4 校验(或擦除)
作为Ceph中维护数据一致性以及整洁性的部分,Ceph OSD 守护进程也可以完成PG内的对象清理工作,意思就是Ceph OSD守护进程比较副本间PG内的对象元数据信息。校验/擦除(通常是天级别的调度策略)捕获异常或文件系统的一些错误。同时,Ceph OSD守护进程也可以进行更深层次的比较(对象数据本身的按位比较),而这种深层次的比较(可以发现驱动盘上坏的扇区)一般是周级别的调度策略。
2.7 高可用
除了通过CRUSH算法实现高可扩展性外,Ceph也需要支持高可用性。这就意味着即使集群处于降级状态或某个Ceph mon出现问题情况下(译者注:这里出问题的mon个数不能超过mon总数的一半,否则集群会阻塞所有操作),客户端仍旧可以进行数据的读写。
2.7.1 数据副本
在副本存储池中,Ceph需要对象的多个副本在降级状态下运行。理想情况下,即使Acting Set中的一个OSD出现问题,Ceph存储集群也可以支持客户端读写操作。基于此,Ceph默认也是一个对象保持3副本的设置,写操作则要求至少2个副本为clean状态(译者注: 具体设置多少个副本为clena才支持写操作,这要依赖于设置存储池时的配置,例如,在ceph osd dump | grep pool输出中的replicated size 3 min_size 2,这里的2就是至少有多少个副本为clean,在这个存储池上的写操作才被支持,而这个值是可以再更新的)。
如果有2个OSD出现问题,Ceph仍然可以保留数据不会丢失,但是就不能进行写操作了。
在纠删码存储池中,Ceph需要多个OSD来存储对象分割后的块以便在降级状态仍然可以操作。与副本存储池类似,理想情况下,在降级状态下纠删码存储池也支持Ceph客户端进行读写操作。基于此,我们则建议设置K+M=5 通过5个OSD来存储块信息,同时设置M=2 以保证即使2个OSD出现问题也可以根据剩余的OSD进行数据的恢复重建。
2.7.2 Mon集群
在客户端进行数据读写之前,客户端必须从Ceph mon端获取最新的集群映射关系。一个Ceph存储集群可以与一台mon进行通信发起操作,然而这就存在单点问题(例如这个单点的mon出现问题,Ceph客户端则不能进行数据的读写)。
为了提供服务的可靠性以及容错性,Ceph支持mon组成集群方式提供服务。在mon集群中,延迟和其他的故障可能导致一个或多个mon落后于集群当前的状态。基于此,Ceph必须在集群状态的各种mon实例之间达成一致。对于集群当前的状态,Ceph也总是使用大多数的mon(例如: 1、2:3、3:5、4:6等等)或者Paxos算法进行一致性确认。同时,mon集群内机器间也需要NTP时间服务防止时钟漂移。
2.7.3 CephX
Cephx 认证协议的操作方式与Kerberos类似。用户、角色调用Ceph客户端来与mon交互,不像Kerberos,每一个monitor都可以对用户进行认证并分发密钥,所以使用cephx 不存在单点问题或瓶颈。mon返回类似于Kerberos的包含会话密钥信息的结构以便调用方可以根据密钥对接Ceph的所提供的服务。这里的会话密钥本身使用了用户的永久密钥进行加密,因此只有用户自已才可以从Ceph mon请求服务。
客户端使用会话密钥从monitor处获取想要的服务,mon则通过认证使得客户端有权限对接OSD来完成数据交互。Ceph mon和OSD共享一个秘钥,因此客户端可以使用mon提供的凭证与群集中的任何OSD或元数据服务器进行交互。和Kerberos类似,cephx 凭证也有超时时间,所以并不能使用一个超时的凭证偷偷的对集群进行攻击。只要用户的密钥在到期前不泄露的话,这种身份认证的形式可以防止攻击者以其他用户的身份创建伪造消息或更改其他用户的合法消息访问通信介质。
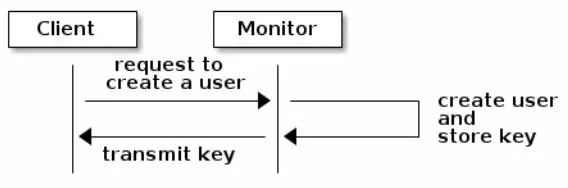
如果使用Cephx 认证,管理员必须先设置用户。在下面的图示中,client.admin 用户通过命令行执行ceph auth get-or-create-key 命令,创建用户以及密钥。Ceph的auth 子系统生成用户名以及密钥,并将其存于mon中以及将用户名与密钥返回给调用命令的client.admin 用户。 这也就意味着客户端与mon共享同一个密钥。
注: client.admin 用户必须以安全的方式向用户提供用户ID和密钥。
第3章 客户端架构
Ceph客户端在数据存储的接口方面还是存在比较大的差异的。Ceph的块设备提供了可以像挂载本地物理驱动盘一样的块存储,而Ceph对象网关则通过用户的管理提供了兼容S3与Swift的Restful对象存储接口。而对于这些接口,都是使用的RADOS(可靠且自动分布式的对象存储)协议与Ceph存储集群进行的交互;同时这些接口也都有一些相同的基本前提:
Ceph配置文件,或集群名称(通常为ceph )与mon地址
存储池名称
用户名以及密钥的路径
Ceph客户倾向于遵循一些类似的模式,例如对象的监视-通知以及条带化。下面大概介绍下Ceph客户端里使用的RADOS,librados以及常见的模式。
3.1 本地协议与Librados
现代的应用需要有异步通信能力简单的对象存储接口,Ceph存储集群就有这个能力并提供简单的接口。此接口提供了对集群直接、并行的对象存取。
存储池操作
快照
读、写对象
– 创建或删除
– 整个对象或字节范围
– 追加或截断创建/设置/获取/删除 XATTRs
创建/设置/获取/删除 K/V对
复合操作和双重ack语义
3.2 对象的监视与通知
Ceph客户端可以为对象注册持久的关注点,并保持与主OSD的会话开启。客户端可以向所有观察者发送通知消息和数据,并在观察者收到通知时接收通知。这使得客户端可以使用任何对象作为同步/通信的通道。
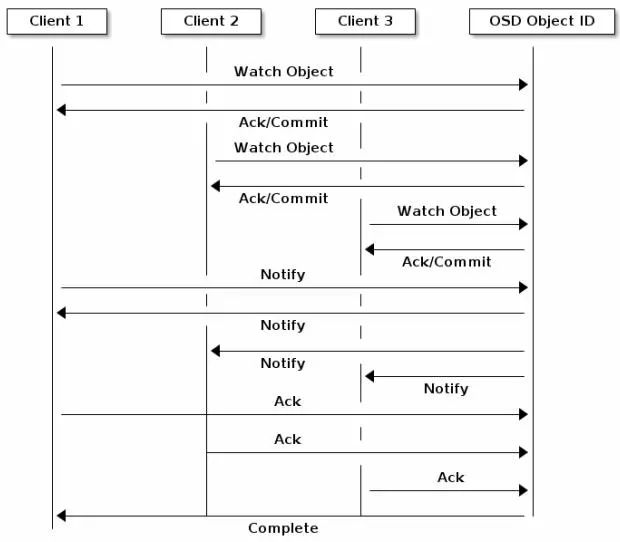
3.3 独占锁
独占锁提供一种功能特性:任一客户端可以对RBD中资源进行’排它的’锁定(如果有多个终端对同一RBD资源进行操作时)。这有助于解决当有多个客户端尝试写入同一对象时发生冲突的场景。此功能基于前一节中介绍的对象的监视与通知。因此,在写入时,如果一个客户端首先在对象上建立独占锁,那么其它的客户端如果想写入数据的话就需要在写入前先检查是否在对象上已经放置了独占锁。
设置了这一特性的话,同一时刻只有一个客户端能够对RBD资源进行修改,尤其像快照创建与删除这种改变RBD内部结构的时候。这一特性对于失败的客户端也起到了一些保护的作用,例如,虚拟机没有响应了,然后在其他地方使用同一块磁盘启动它的副本,那么这个无响应的虚拟机将在Ceph中被列入黑名单,并且无法破坏新的虚拟机中数据。
强制的独占锁功能特性默认是不开启的,但是可以在创建镜象时显示的通过加入–image-features参数来开启这一特性,例如:
rbd -p mypool create myimage –size 102400 –image-features 5
这里的5是1与4的和值, 其中1使得分层特性生效,4使得独占锁特性生效。所以执行上面这个命令后会创建100GB的RBD镜象,同时既支持分层特性也支持独占锁特性。
强制的独占锁也是后面提到的对象索引映射使用的前提。如果没有开启强制的独占锁,那么对象索引映射也不会生效。
独占锁也为mirror这块内容做了不少的工作。
3.4 对象映射索引
对象映射索引也是一种功能特性,可以在客户端写入rbd映像时跟踪RADOS对象是否已经存在了。当有写入操作时,写操作被转义为RADOS对象中的偏移,如果对象映射索引功能开启那么对于存在的RADOS对象就会被跟踪到。所以当对象已经存在时我们就可以提前知道。对象映射索引保存在librbd客户端机器内存中,所以对于不存在的对象就省去了再去查询OSD的这一步开销。对象映射索引对于一些操作还是比较有利的,即:
调整大小
导出操作
复制操作
扁平化
删除
读取
缩小操作就像是对尾部对象的部分删除。导出操作知道哪些对象被RADOS请求。复制操作知道哪些对象存在并需要复制。它不需要遍历潜在的数百或数千个可能的对象。扁平化操作将所有父对象拷贝到克隆中,以便可以将克隆与父项分离,即可以删除从子克隆到父快照的引用。因此,不是对所有潜在的对象,仅是对存在的对象进行复制。
删除操作仅删除镜象中存在的对象。读取操作对于不存在的对象会直接跳过。因此,对于调整大小(仅缩小)、导出操作、复制操作、扁平化和删除等操作,这些操作需要针对所有可能受到影响的RADOS对象(无论它们是否存在)发布操作。如果启用对象映射索引特性的话,对象若不存在就不需要发布操作了。
例如,我们有一个RBD镜象,有1TB的数据且比较稀疏,可能拥有数百或数千个RADOS对象。如果不开启对象映射索引的话,执行删除操作则需要对每一个潜在的目标对象发布删除对象操作;但是如果开启了这一特性,那么只需要对真正存在的对象发布一个删除对象的操作就可以了。
对象映射索引对于克隆是比较有价值的(自身没有实际对象但可以从父对象那获取)。当有一个克隆的镜象时,克隆初始并没有什么对象,所有对克隆对象的读操作都会重定向到父对象中。开启对象映射索引可以改善读操作,首先对于克隆对象向OSD发布读操作,如果读失败了,那么再向克隆对象的父对象发布读操作。读操作会直接忽略掉根本不存在的对象。
对象映射索引默认是不开启的,但是可以在创建镜象时显示的通过加入–image-features参数来开启这一特性。同时独占锁 也是对象映射索引功能特性的使用前提。如果不开启独占锁功能特性则对象映射索引也不会生效。创建镜象时如果开启对象映射索引,可以执行:
rbd -p mypool create myimage –size 102400 –image-features 13
这里的13是1、4、8的和值, 其中1 使得分层特性生效,4 使得独占锁特性生效,8 使得对象映射索引特性生效。所以执行上面这个命令后会创建100GB的RBD镜象,同时既支持分层特性也支持独占锁特性和对象映射索引特性。
3.5 数据条带化
存储设备一般在吞吐量上都有限制,这就会影响到服务的性能和伸缩性。因此,存储系统一般会提供条带化方案来提高性能与吞吐能力(即,将有序的信息分割成多个区段后存储到多个设备上)。关于条带化最常见的就是RAID(译者注: 磁盘阵列RAID,意为将多个磁盘组合成一个容量更大的磁盘组,利用单块盘存储的叠加效果来提升整个磁盘存储冗余能力。采用这种方案后,将存储的数据切割成许多个区段数据,然后分别存放在各个硬盘上)。与Ceph中条带化最相似的RAID类型就是RAID 0或’条带化卷’。Ceph的条带化提供了RAID 0级的吞吐能力以及n路RAID镜像的可靠性和快速的数据恢复能力。
Ceph提供3种客户端对接类型: Ceph块设备(CephRBD)、Ceph文件系统(CephFS)、Ceph对象存储(一般是Ceph RGW)。数据存储方面,Ceph客户端会将用户提交的数据转换为Ceph存储集群内部的格式存储到集群中,在提供给用户的接口上也是按照这3种类型完成的:块设备镜像、对象存储的RESTful接口、以及CephFS系统目录。
提示: 存储在Ceph存储集群中的对象自身并没有条带化。 Ceph对象存储,Ceph块设备和Ceph文件系统将客户端数据条带化后存储在Ceph集群内的多个对象中。如果想充分发挥并行能力,使用librados库直接将数据写入到Ceph存储集群的Ceph客户端必须执行条带化(以及并行I/O)。
最简单的Ceph条带化格式即为条带数量为1的单个对象。 Ceph客户端将条带单元块写入到Ceph存储集群对象中,直到对象达到其最大容量,然后再为额外的条带化数据创建另一个对象。对于较小的块设备镜像、S3或Swift对象来说,这种简单的条带化方式可能就完全能够满足需求,然而,这种简单的形式并没有最大限度的利用Ceph在整个放置组中分布数据的能力,因此并不能有较大的性能提升。下面图示描述了这种最简单的条带化方式:
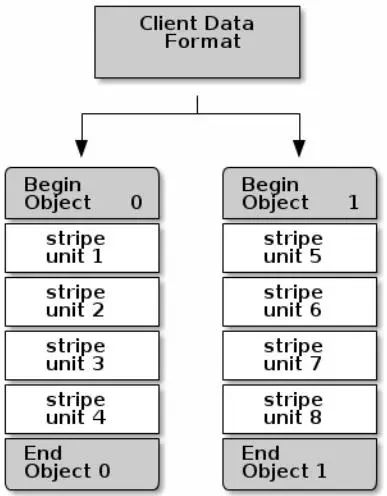
译者注: 例如每一个对象存储上限是4M,同时每一个单元块占1M,这时我们有一个8M大小的文件想进行存储,这样前4M存储在对象0中,后4M就创建另一个对象1来存储。
如果可以预知存储需求为较大的图像,或较大的S3对象或Swift对象(例如视频),若想有较大的读写性能提升,则可以通过将客户端数据条带化分割存储到多个对象上。如果客户端将条带单元块并行的写入到对应对象中,由于对象映射到不同的PG上进而会映射到不同的OSD上,每个写操作都以最大化速并行进行,那么写性能的提升是相当明显的。
如果完全只对一块磁盘写入操作的话,受限就比较多: 磁头的移动(例如每次6ms的寻址时间开销)、设备的带宽(例如每秒最大100MB)。通过扩展多个对象上的写入(映射到不同的PG以及OSD上),Ceph不但可以降低每个驱动盘的寻址时间,同时也可以合并多个驱动盘的吞吐能力以获取更快的读写速度。
注: 条带化独立于对象的副本。由于CRUSH跨OSD复制对象,所以条带化也会自动完成复制。
在下面的图示中,客户端跨越对象集(对象集 1)来获取条带数据。对象集中由4个对象组成,第1个条带单元块是存储在object 0中的stripe unit 0,第4个条带单元块是存储在 object 3中的stripe unit 3。当写完第4个单无块时,客户端会判断对象集是否已满,如果没有满的话,客户端继续将条带单元块写入第1个对象中(下图中的object 0)。如果对象集已满,那么客户端就会创建一个新的对象集(下图中的对像集 2),然后将第1个条带单元块(stripe unit 16)写入到新对象集中的第1个对象中(下图中的object 4)。
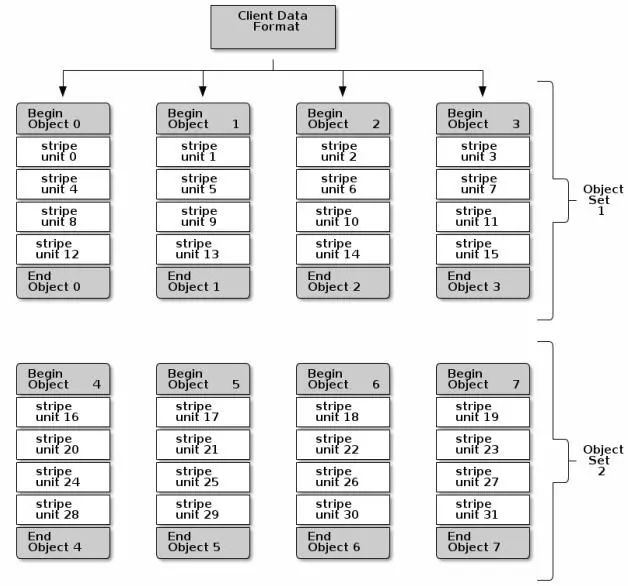
Ceph数据条带化过程中,有3个比较重要的参数会对条带化产生影响:
对象大小:Ceph存储集群中可以配置对象大小的上限值(比如2M、4M等),对象大小也应该足够的大以便与条带单元块相适应,同时设置对象的大小也应该是单元块大小的倍数。Red Hat则建议对象大小比较合理的值是16MB。
条带宽度:条带化中的单元块大小也是可配置的(例如64kb)。Ceph客户端将写入对象的数据划分为相同大小的条带单元块(因为写入的数据不一定是单元块的倍数,所以最后剩余的一个单元块可能大小与其它的不一样)。条带宽度应该是对象大小的一个分数(比如对象是4M,单元块是1M,则一个对象能包含4个单元块),以便对象可以包含更多条带单元块。(译者注:条带宽度也是指同时可以并发读或写的条带数量。一般这个数量等于RAID中的物理硬盘数量)
条带数量:根据条带数量,Ceph客户端将一批条带单元块写入到一系列对象中。这里的一系列对象也就是对象集。在Ceph客户端写入对象集中最后一个对象之后会返回到对象集中的第1个对象。
重要提示: 在服务上线生产环境前,最好对条带化进行性能上的测试,因为一旦数据写入,就无法再更改条带参数信息了。
一旦Ceph客户端将条带化数据映射到条带单元块上,进而映射到对象上,在对象最终以文件形式存储在磁盘上之前,Ceph的CRUSH算法会将对象映射到PG中,然后再将PG映射到OSD守护进程中。
注: 由于客户端写入单个存储池中,因此条带化到对象中的所有数据都会映射到同一个存储池的PG内。所以也会使用相同的CRUSH映射关系以及相同的访问控制策略。
译者注: 在Ceph存储中,涉及条带化的主要是Order、stripe_unit和stripe_count这3个参数。由这3个参数确定了数据的写入与存储编排方式。默认情况order是22,也即对象大小为4MB(2的22次方),strip_unit大小与对象大小一致(也是4M),strip_count为1(对象集中只有1个对象)。
第4章 加密相关
LUKS磁盘加密及带来的好处: 在Linux系统中,可以使用LUKS方法对磁盘分区进行加密,由于LUKS是对整个块设备进行加密,所以对于便携式存储能够起到较好的数据保护作用。
可以使用Ceph-ansible工具创建加密的OSD存储节点,这样可以对OSD上存储的数据进行保护。更详细的内容可以参考
中的Ceph OSD配置章节。
如何使用ceph-ansible创建加密的磁盘分区: 在OSD安装过程中,ceph-ansible会调用ceph-disk工具来完成创建加密分区的工作。
除了数据和日志分区外(Ceph data和ceph journal),ceph-disk 工具也会创建一个小的密码箱分区以及名称为cephx client.osd-lockbox 的用户。ceph密码箱分区包含一个密钥文件,client.osd-lockbox 用户使用这个密钥文件获取LUKS私钥,从而对ceph data和ceph journal分区进行解密。
之后,Ceph-disk会再调用cryptsetup 工具为ceph data和ceph journal分区创建2个dm-crypt设备。其中dm-crypt设备使用ceph data和ceph journal的GUID作为标识。
Ceph-ansible如何处理LUKS密钥: Ceph-ansible工具将LUKS私钥存储在Ceph monitor监视器的K/V存储中。每个OSD都有自己的密钥将存储在dm-crypt设备上加密的OSD数据和日志进行解密。加密分区在服务启动时就自动的进行了解密操作。
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师技术全联盟书店”相关电子书(35本技术资料打包汇总详情可通过“阅读原文”获取)。
内容持续更新,现下单“架构师技术全店打包汇总(全)”,后续可享全店内容更新“免费”赠阅,格仅收188元(原总价270元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
