Python指导你买车,少花钱买好车
后台回复【大礼包】送你Python自学大礼包
文 | 派森酱
来源:Python 技术「ID: pythonall」

今日话题:双十一开始预热了,酱子们,有什么要入手的嘛?
上次为买车,爬了懂车帝的车型评分;这次,爬车友圈。
爬完后,对我来说,买车首先要排除的就是轩逸!
我不喜欢日产的轩逸,全是塑料,一开门一股塑料异味,车皮薄的指甲一划就是一道印,还有到了夏天超车不关空调是真的费劲。不是我黑日产,这些缺点真让我反感它,卖的还贵。
其它的缺点呢,相信车主最有发言权,所以对轩逸的懂车帝车友圈爬了几页“【最不满意】”。并且用一行代码(后面会介绍),生成这种比较美观的文章:
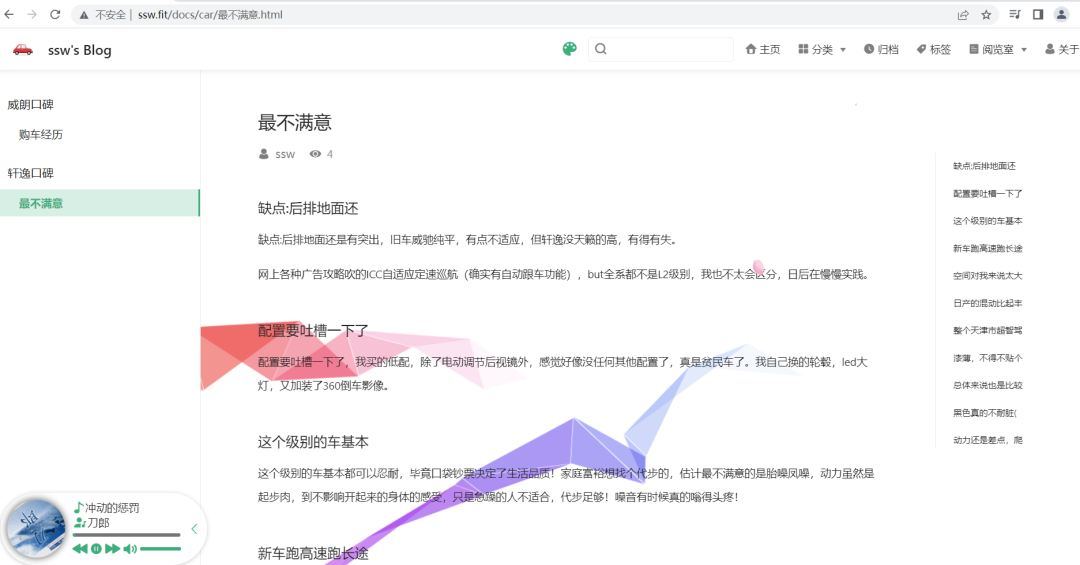
http://www.ssw.fit/ ,点击导航栏的“阅览室”->“选车”可以看到内容
我就想看看这个车缺点突出为毛卖的这么好,咱找找碴,揪揪它的缺点。
除此之外,这篇文章对购车很有帮助,如果你想了解某个车型的某一方面,比如【驾驶感受】、【乘坐体验】、【空间表现】、【最满意】等等,可以针对其中一项爬它个几十页,一下子几十条车主撰写的相关内容就出来了,一口气了解个够!
我对威朗比较感兴趣,从【购车经历】、【驾驶感受】、【空间表现】、【销售态度】四个维度了解这款车,是不是非常全面?还可以从空间表现等方面对比轩逸:
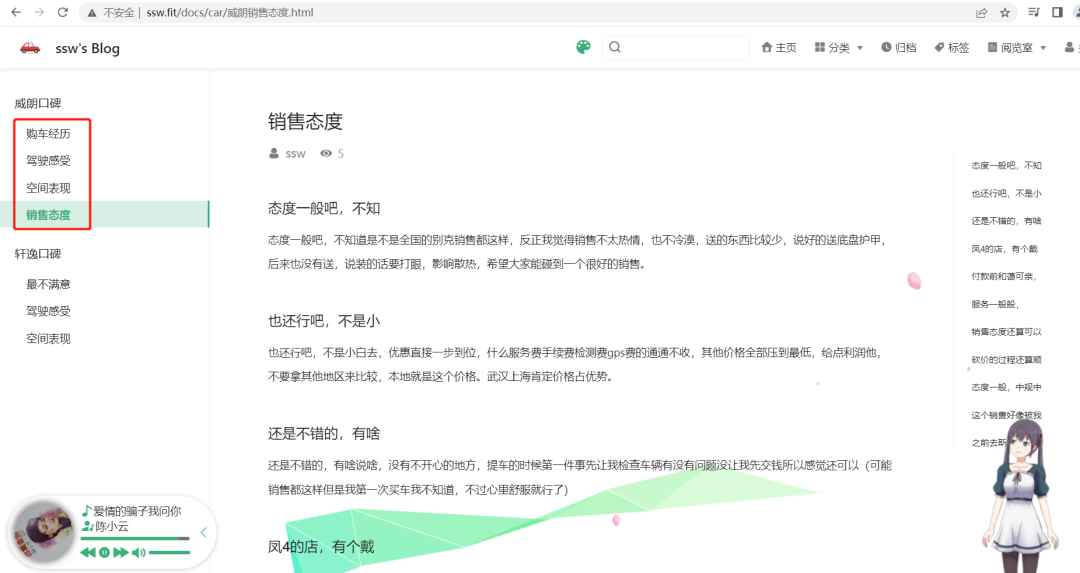
有没有想了解的车型,哪项内容?告诉我,帮你爬下来生成文章贴到这里。有兴趣的话,也可以看完全文,自己动手把它们爬下来。
话不多说,进入正题。
这车值不值得购买
当你了解好爱车的价格行情后,接下来最担心的是口碑如何,心里疑窦丛生:这车究竟值不值得购买呢?于是一头扎进车友圈,一边吹水,一边看大家分享购车经验:
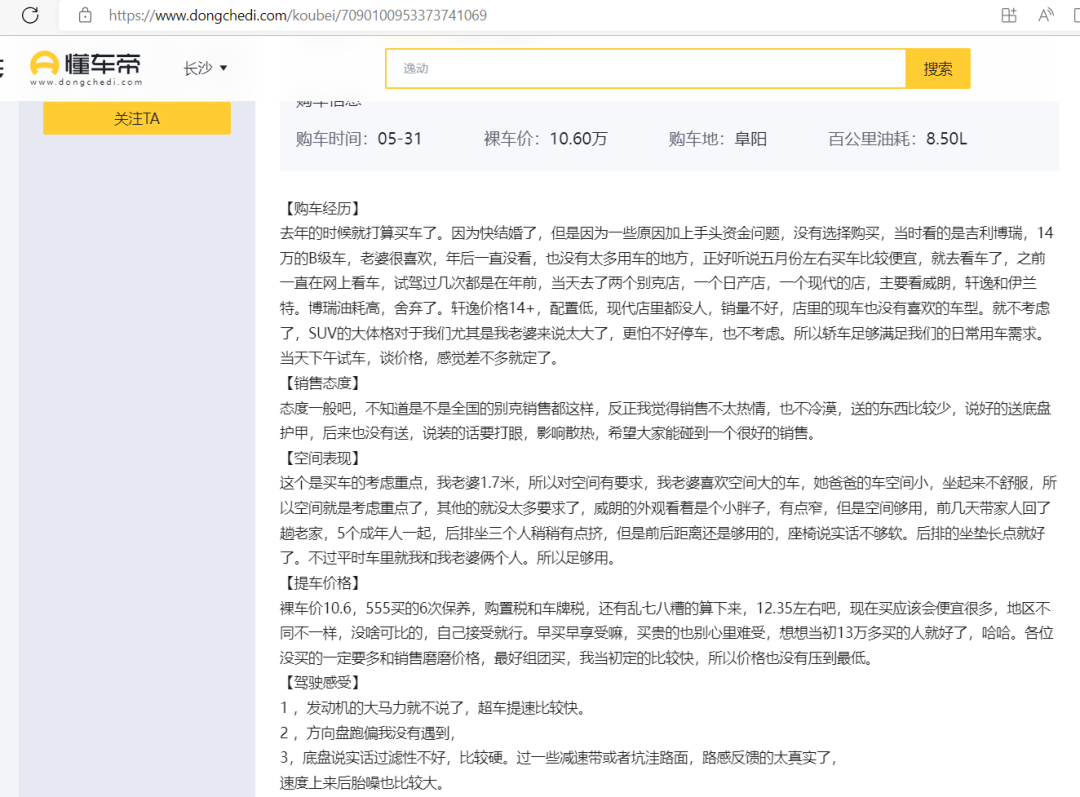
这是一个很标准的车型点评,如果车主都按这个结构来写车评那就太好了。
属于少数情况,这种忽略它
可是呢,有些把【购车经历】写做【提车经历】,还有“【”符号一个也不写的,我能怎么办啊?😂第一种属于少数情况,忽略它。
第二种咱们用try except语句覆盖它
try:
# 匹配“【购车经历】”
r = re.compile(r'.*【购车经历】(.*)', re.S)
m = match(data, r, lambda a: a)
content = m.strip().split('【')[0]
print('### '+content[0:8]+'\n'+content)
except Exception as e:
#如果没写“【购车经历】”几个字,则默认第一段文字为购车经历
#还有一种情况,一个“【”符号也没有的,则默认全篇都是写购车经历
print(data.strip().split('【')[0])
取到了车评,如何筛选内容?pampy又用到了,与re.S进行多行匹配:
import re
from pampy import match
s = '''【购车经历】
家里的老轩逸陪我度过了7年12万公里,烧机油烧的我心碎,动力也是太弱,所以年初就有了换车的打算,我换车目的很明确,车不大,动力强就是我的菜
【提车价格】
裸车11.69,全部办齐是13.63,外观选的蓝色,说实话GS的蓝色白色我都不太喜欢,无奈之下只能选了个免费的蓝色。
【驾驶感受】
CVT变速箱,非常平顺,偶尔有点轻微顿挫,0到80响应很快,80以后有点后劲不足,涡轮迟滞感觉明显
【最满意】外观很帅,动力够用,燃油经济性,动力兼顾。'''
#多行匹配。不使用re.S时,则只在每一行内进行匹配
r = re.compile('.*【购车经历】(.*)',re.S)
m= match(s, r, lambda a:a)
#去掉换行符\n,以【为分割符
print(m.strip().split('【')[0])
输出:
家里的老轩逸陪我度过了7年12万公里,烧机油烧的我心碎,动力也是太弱,所以年初就有了换车的打算,我换车目的很明确,车不大,动力强就是我的菜
wow,购车经历就这样被匹配出来了。其它的【驾驶感受】、【乘坐体验】、【最不满意】方法一样,你想单独看哪个?不着急,精彩在后头。
怎么生成漂亮的文章
你知道下图威朗的二十多条【购车经历】怎么写成的吗?
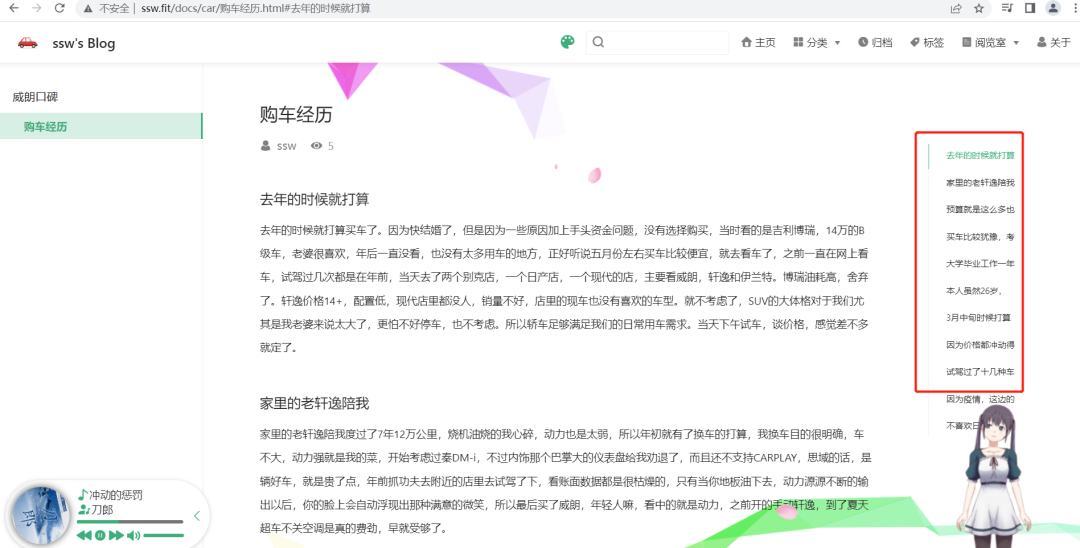
答案是一行代码:
#3个#是markdown语法,content[0:8]提取购车经历的前几个汉字作为段落标题,content是购车经历
print('### '+content[0:8]+'\n'+content)
我只爬了威朗车主圈3页,共23条数据,按上面的格式print出来就是一篇文章了:
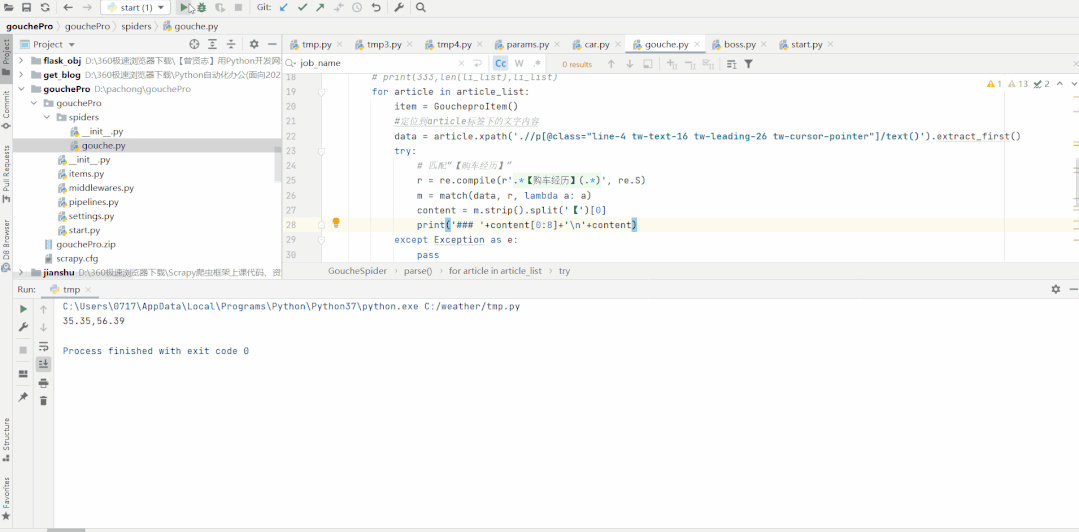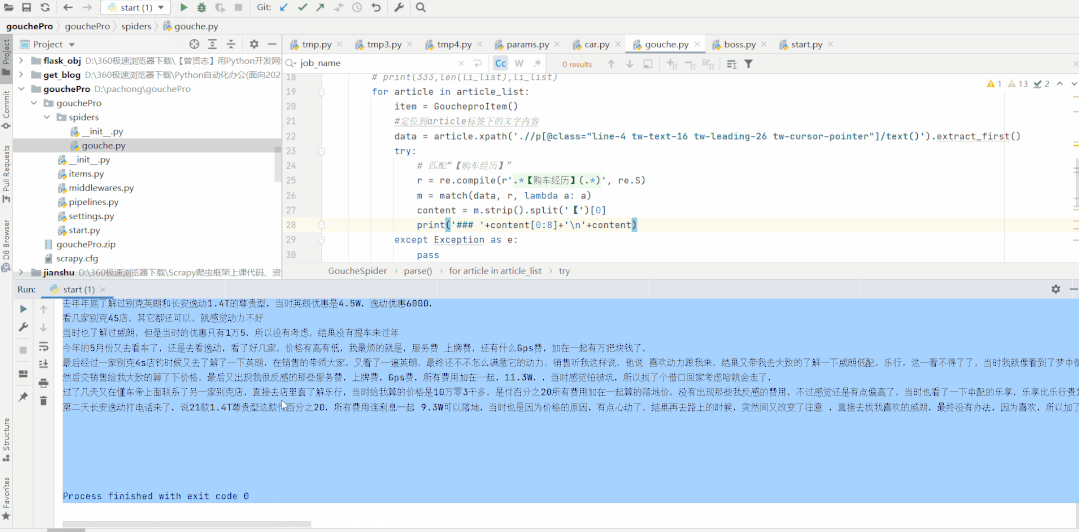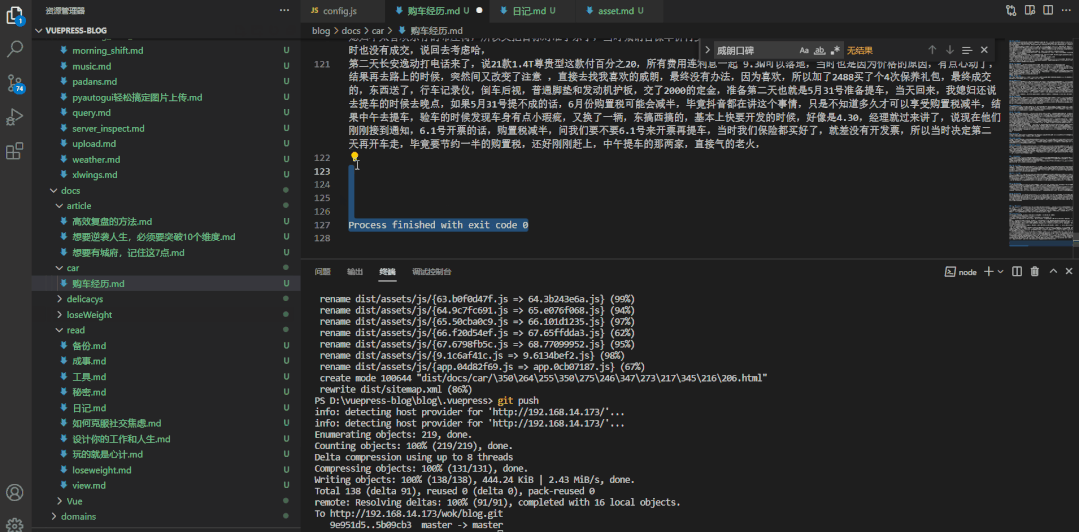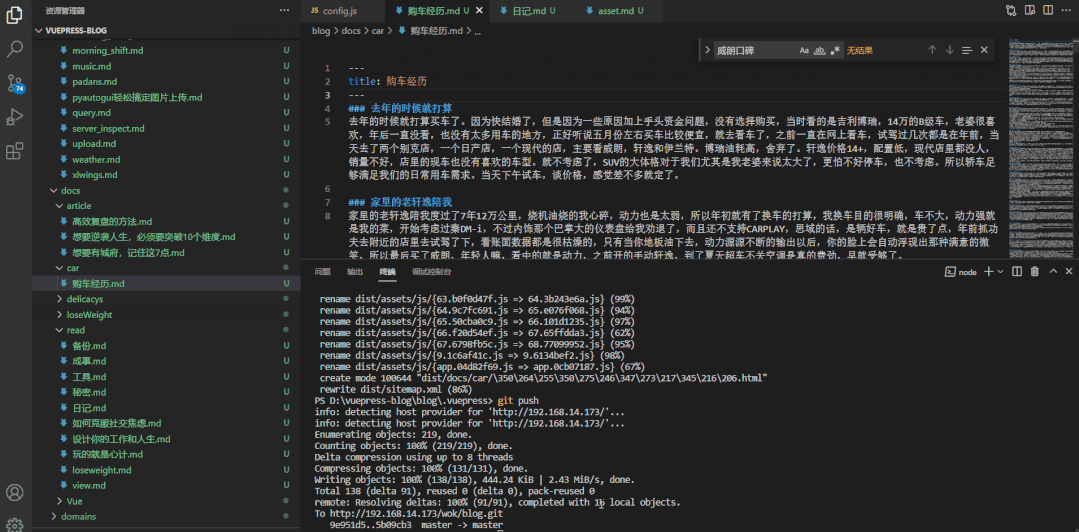
需要爬哪个车型,进入那个车型的车友圈,点“懂车分(口碑)”
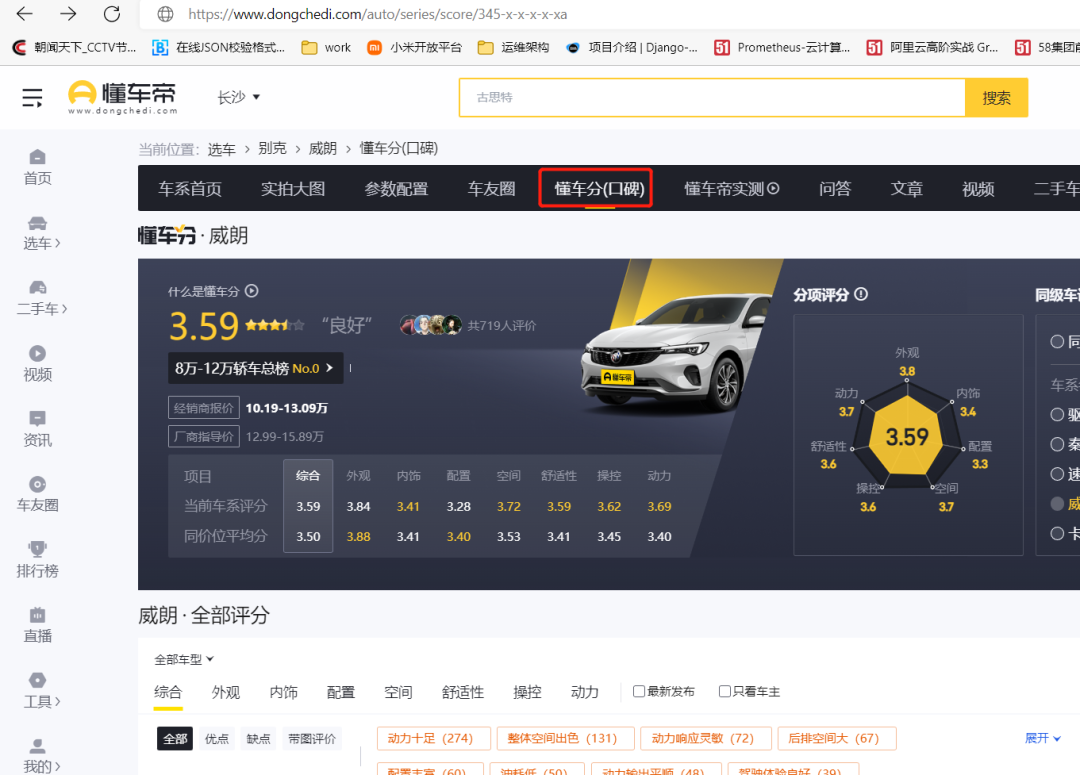
再点击第2页就可以看到345-x-S0-x-x-x-2格式的url。下面这个是别克威朗的第2页:
#345是威朗,2是第二页
https://www.dongchedi.com/auto/series/score/345-x-S0-x-x-x-2
翻页的话修改最后一位数字。内容匹配好了,要发起请求的url也有了,接下来用工具scrapy把上面的内容填进去!
附录(配置scrapy)
创建scrapy项目
#创建scrapy项目
scrapy startproject gouchePro
cd gouchePro
#生成一个爬虫
scrapy genspider gouche "https://www.dongchedi.com/"
修改配置文件 settings.py
# 是否遵守协议,设置false
ROBOTSTXT_OBEY = False
#日志级别
LOG_LEVEL = 'ERROR'
#设置USER_AGENT
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
打开爬虫配置文件
将起始url粘贴到start_urls中,先对第一页进行数据爬取。345是威朗,最后的数字1是第一页:
start_urls = ['https://www.dongchedi.com/auto/series/score/345-x-S0-x-x-x-1']
打开浏览器开发者工具,定位一下
article标签都在section标签下边:
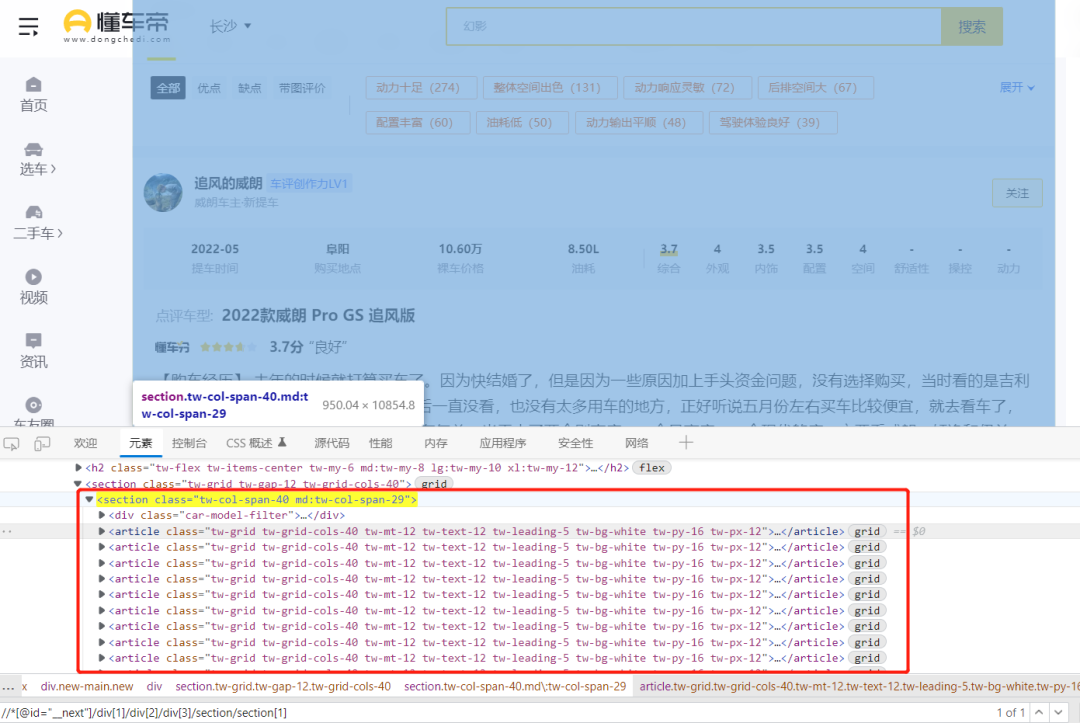
右键复制article标签的xpath路径,返回的是一个列表
article_list = response.xpath('//*[@id="__next"]/div[1]/div[2]/div[3]/section/section[1]/article')
定位到article标签下的p标签
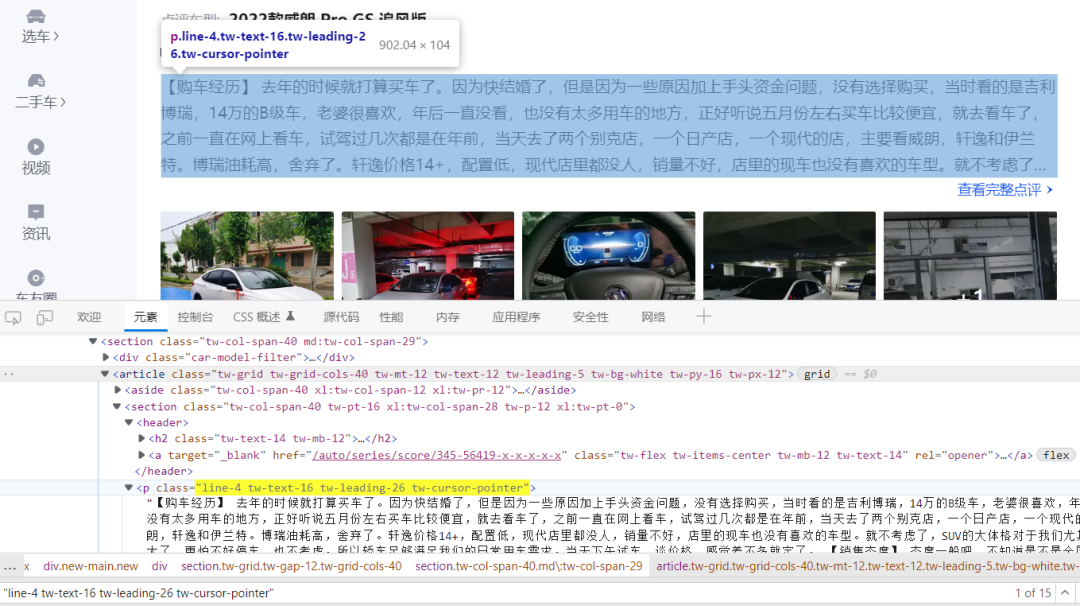
这样就拿到了车主的评价内容
for article in article_list:
job_name = article.xpath('.//p[@class="line-4 tw-text-16 tw-leading-26 tw-cursor-pointer"]/text()').extract_first()
分页操作
第一页已经在start_urls中设置了,所以下一页page_num从2开始
page_num = 2
爬取前3页
scrapy.Request对第2、3页发起请求,callback递归调用parse函数
url = 'https://www.dongchedi.com/auto/series/score/345-x-S0-x-x-x-%d'
if self.page_num <= 3:
new_url = format(self.url%self.page_num)
self.page_num += 1
yield scrapy.Request(new_url,callback=self.parse)
gouche.py完整内容
# -*- coding: utf-8 -*-
import scrapy,re
from pampy import match
from gouchePro.items import GoucheproItem
class GoucheSpider(scrapy.Spider):
name = 'gouche'
start_urls = ['https://www.dongchedi.com/auto/series/score/345-x-S0-x-x-x-1']
url = 'https://www.dongchedi.com/auto/series/score/345-x-S0-x-x-x-%d'
page_num = 2
def parse(self, response):
article_list = response.xpath('//*[@id="__next"]/div[1]/div[2]/div[3]/section/section[1]/article')
for article in article_list:
item = GoucheproItem()
#定位到article标签下的文章
job_name = article.xpath('.//p[@class="line-4 tw-text-16 tw-leading-26 tw-cursor-pointer"]/text()').extract_first()
item['job_name'] = job_name
try:
# 匹配“【购车经历】”
r = re.compile(r'.*【购车经历】(.*)', re.S)
m = match(job_name, r, lambda a: a)
content = m.strip().split('【')[0]
print('### '+content[0:8]+'\n'+content)
except Exception as e:
#如果没写“【购车经历】”几个字,则默认第一段文字为购车经历
#还有一种情况,一个“【”符号也没有的,则默认全篇都是写购车经历
pass
#分页操作
if self.page_num <= 3:
new_url = format(self.url%self.page_num)
self.page_num += 1
yield scrapy.Request(new_url,callback=self.parse)
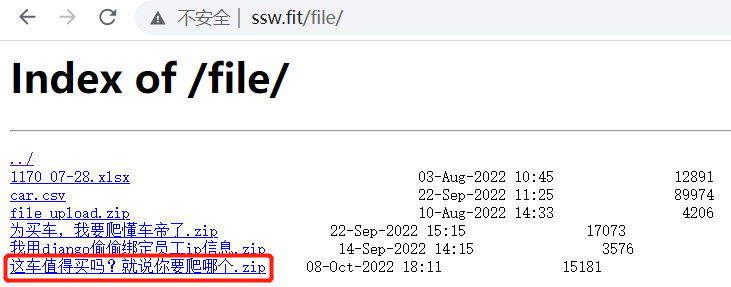
代码下载地址
已上传到 linux服务器上,http://ssw.fit/file/