
内存真能当SSD用了!!!

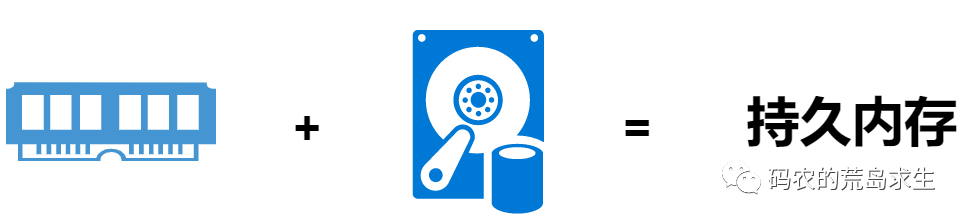
持久内存

面向存储编程
面向内存编程
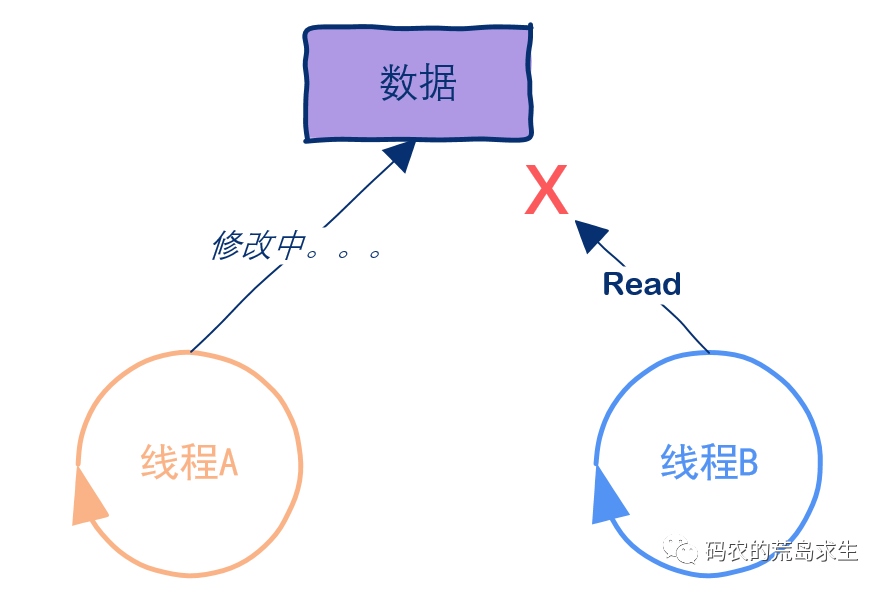
面向持久内存编程
For example
struct account {string name;int money;};
struct account *xfg = new account();xfg->name = "xiaofengge";xfg->money = 100000000; // 单位人民币
 。
。struct data *xfg = new data();xfg->name = "xiaofengge";xfg->money = 100000000;
基于持久化内存编程的复杂性

解决方案

总结
评论