
【Python】Kaggle可视化:黑色星期五画像分析
公众号:尤而小屋
作者:Peter
编辑:Peter
本文还是kaggle上一份黑色星期五消费数据的分析,主要是针对用户和商品信息的画像分析。建模的方案参考文章:
本文重点是可视化,使用的图形:柱状图、饼图、散点图、小提琴图、桑基图、树状图、漏斗图、多子图等,全部是Plotly库绘制。
关键词:用户画像、可视化、plotly、Pandas

导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.patches as mpatches
import matplotlib
# 中文显示问题
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #正常显示负号
import plotly.graph_objects as go
import plotly.express as px
from plotly.subplots import make_subplots
from plotly.offline import init_notebook_mode, iplot
# 忽略notebook中的警告
import warnings
warnings.filterwarnings("ignore")
数据基本信息
导入数据
探索数据的基本信息
In [2]:
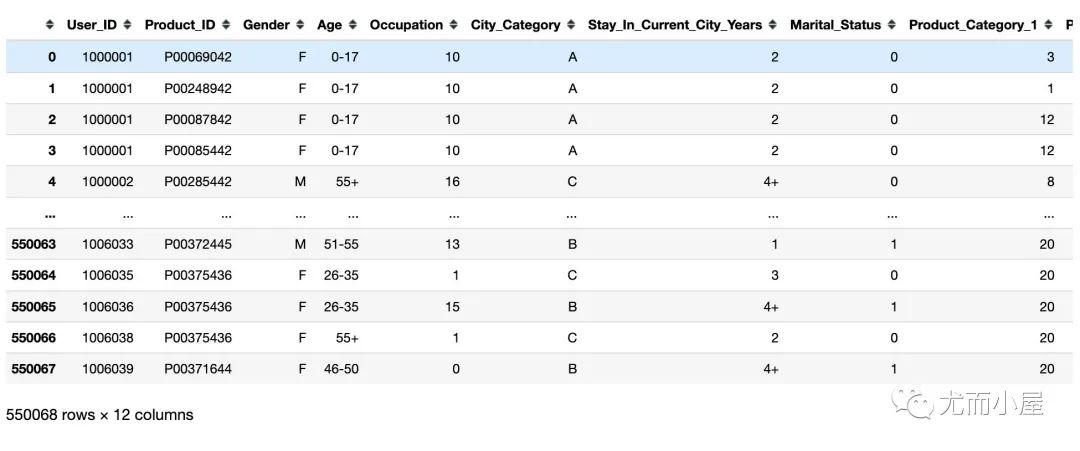
df = pd.read_csv("train.csv")
df
基本信息
In [3]:
# 1、数据大小
df.shape
Out[3]:
(550068, 12)
In [4]:
# 2、字段类型
df.dtypes
Out[4]:
User_ID int64
Product_ID object
Gender object
Age object
Occupation int64
City_Category object
Stay_In_Current_City_Years object
Marital_Status int64
Product_Category_1 int64
Product_Category_2 float64
Product_Category_3 float64
Purchase int64
dtype: object
下面是具体的字段含义为:
User_ID:用户编码 Product_ID:商品编码 Gender:性别(M为男性,F为女性) Age:年龄(0-17,18-25,26-35,36-45,46-50,51-55,55+,7种) Occupation:职业(用数字代表具体职业,一共20种职业) City_Category:城市分类(分为三类城市:ABC) Stay_in_Current_City_Years:在目前城市的居住的年数(0,1,2,3,4+,5种) Marital_Status:婚姻状态(0为未婚,1为已婚) Product_Category_1:产品分类为1(服饰,20种,用1-20表示) Product_Category_2:产品分类为2(电子产品) Product_Category_3:产品分类为3(家具用品) Purchase:购买金额(单位为美元)
In [5]:
# 3、缺失值情况
df.isnull().sum()
Out[5]:
User_ID 0
Product_ID 0
Gender 0
Age 0
Occupation 0
City_Category 0
Stay_In_Current_City_Years 0
Marital_Status 0
Product_Category_1 0
Product_Category_2 173638 # 存在缺失值
Product_Category_3 383247
Purchase 0
dtype: int64
In [6]:
# 4、数据信息
df.info()
'pandas.core.frame.DataFrame' >
RangeIndex: 550068 entries, 0 to 550067
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 User_ID 550068 non-null int64
1 Product_ID 550068 non-null object
2 Gender 550068 non-null object
3 Age 550068 non-null object
4 Occupation 550068 non-null int64
5 City_Category 550068 non-null object
6 Stay_In_Current_City_Years 550068 non-null object
7 Marital_Status 550068 non-null int64
8 Product_Category_1 550068 non-null int64
9 Product_Category_2 376430 non-null float64
10 Product_Category_3 166821 non-null float64
11 Purchase 550068 non-null int64
dtypes: float64(2), int64(5), object(5)
memory usage: 50.4+ MB
缺失值可视化
In [7]:
import missingno
df.isna().sum() / df.shape[0]
Out[7]:
User_ID 0.000000
Product_ID 0.000000
Gender 0.000000
Age 0.000000
Occupation 0.000000
City_Category 0.000000
Stay_In_Current_City_Years 0.000000
Marital_Status 0.000000
Product_Category_1 0.000000
Product_Category_2 0.315666 # 缺失值字段
Product_Category_3 0.696727
Purchase 0.000000
dtype: float64
In [8]:
可以看到有两个字段存在缺失值
# 矩阵图:查看缺失值的分布
missingno.matrix(df)
plt.show()

# 条形图
missingno.bar(df, color="blue")
plt.show()
从下面的图像中也能够观察到只有两个字段存在缺失值
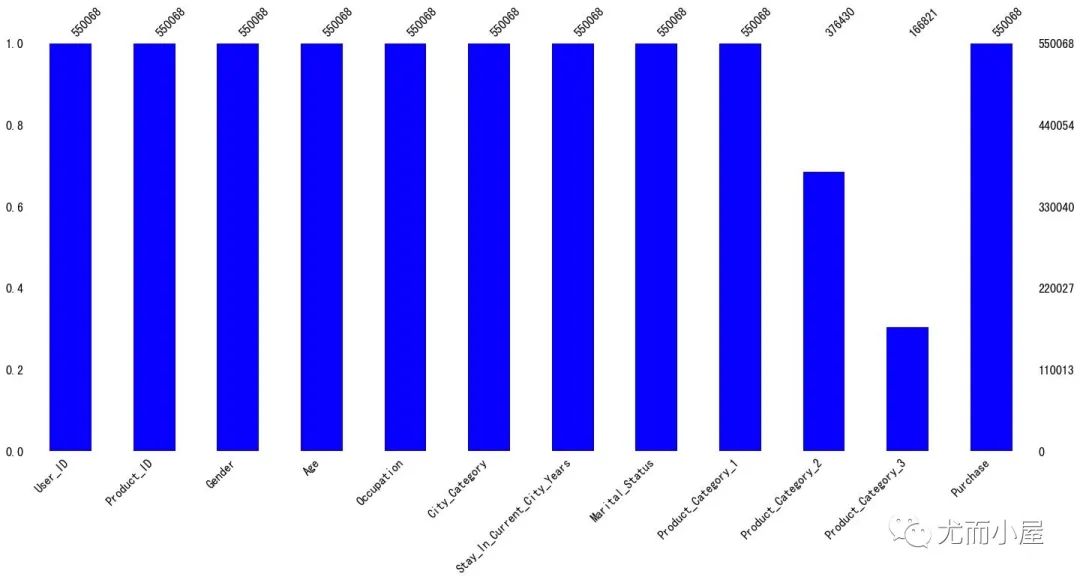
小结1:在我们的数据中包含object、float64和int64共3种数据类型
其中Product_Category_2字段有约31%的缺失占比,Product_Category_3有69%的缺失值占比。
总信息
寻找3个总体的数据信息:
总消费人数 总消费商品种类 总消费金额
In [10]:
# 总消费人数
df["User_ID"].nunique()
Out[10]:
5891
In [11]:
# 总消费商品种类
df["Product_ID"].nunique()
Out[11]:
3631
In [12]:
# 总消费金额
sum(df["Purchase"])
Out[12]:
5095812742
商品类别
In [13]:
# 总消费商品种类
df["Product_Category_1"].nunique()
Out[13]:
20
In [14]:
df["Product_Category_2"].nunique()
Out[14]:
17
画像1:消费金额Top10
In [15]:
不同用户的消费金额对比
df1 = df.groupby("User_ID")["Purchase"].sum().reset_index()
df2 = df1.sort_values("Purchase", ascending=False)
df2["User_ID"] = df2["User_ID"].apply(lambda x: "id_"+str(x))
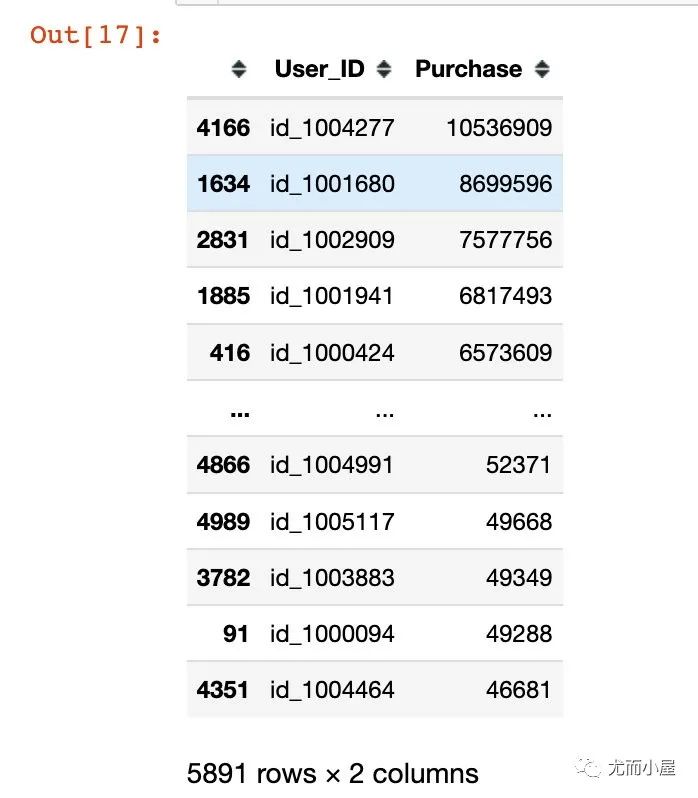
fig = px.bar(df2[:10], # 选择前10人
x="User_ID",
y="Purchase",
text="Purchase")
fig.show()

可以看到最高的一位用户花费了1千多万!
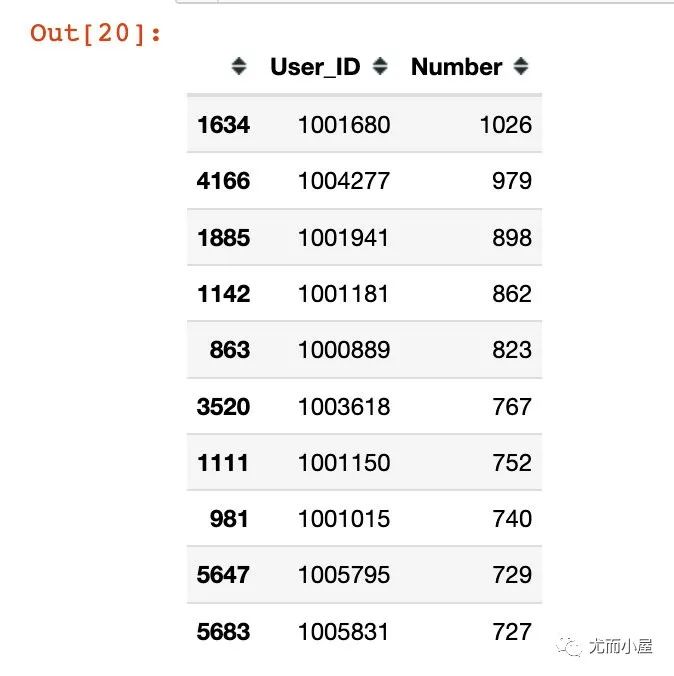
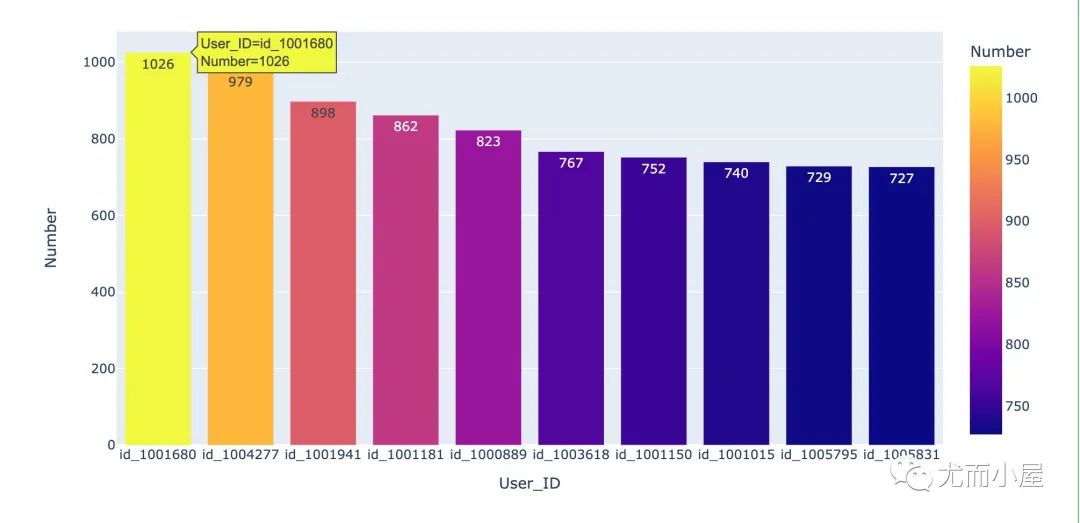
画像2:高频消费前10
In [19]:
df3 = df.groupby("User_ID").size().reset_index()
# Number表示购买次数
df3.columns = ["User_ID", "Number"]
# 降序排列
df4 = df3.sort_values("Number", ascending=False)
df4.head(10)
df4["User_ID"] = df4["User_ID"].apply(lambda x: "id_"+str(x))
fig = px.bar(df4[:10], # 选择前10人
x="User_ID",
y="Number",
text="Number",
color="Number"
)
fig.show()
画像3:人均消费金额Top10
In [23]:
df5 = pd.merge(df2, df4)
# 人均消费金额
df5["Average"] = df5["Purchase"] / df5["Number"]
df5["Average"] = df5["Average"].apply(lambda x: round(x,2))
df5.head()
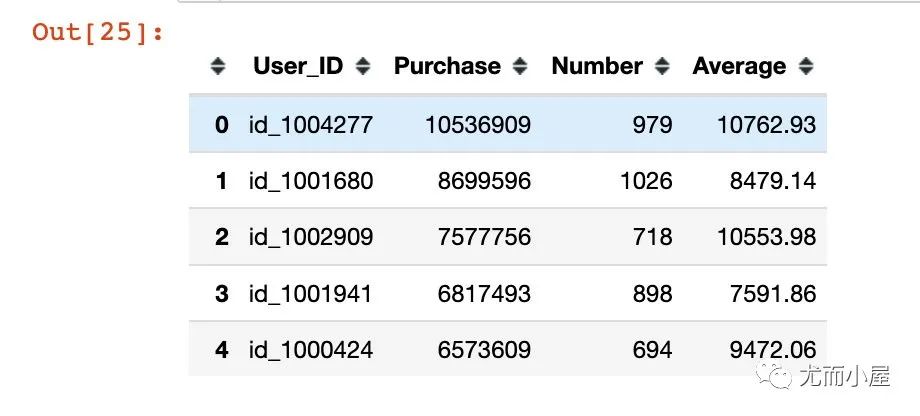
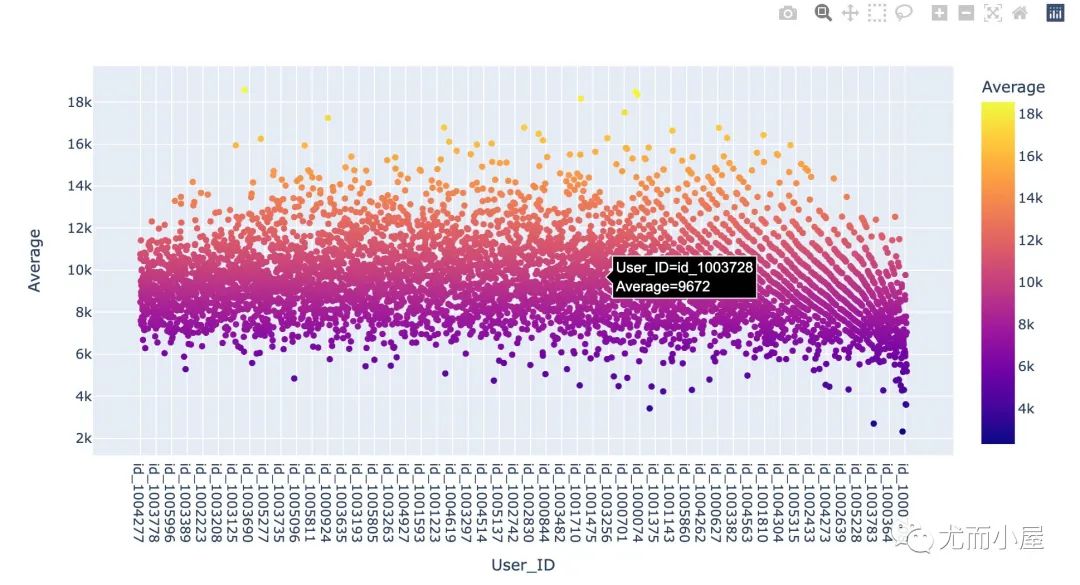
fig = px.scatter(df5,
x="User_ID",
y="Average",
color="Average")
fig.show()
px.violin(df5["Average"])
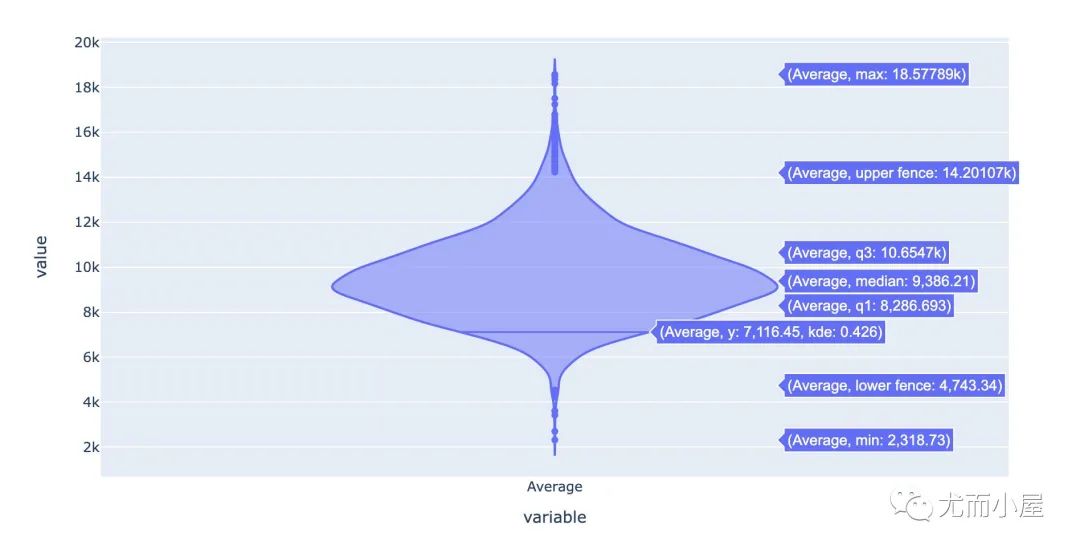
从散点分布图和小提琴图中能够看到,大部分用户的平均消费金额在8k到10k之间
画像4:男女消费对比
In [28]:
df6 = df.groupby("Gender").agg({"User_ID":"nunique", "Purchase":"sum"}).reset_index()
df6
Out[28]:
| Gender | User_ID | Purchase | |
|---|---|---|---|
| 0 | F | 1666 | 1186232642 |
| 1 | M | 4225 | 3909580100 |
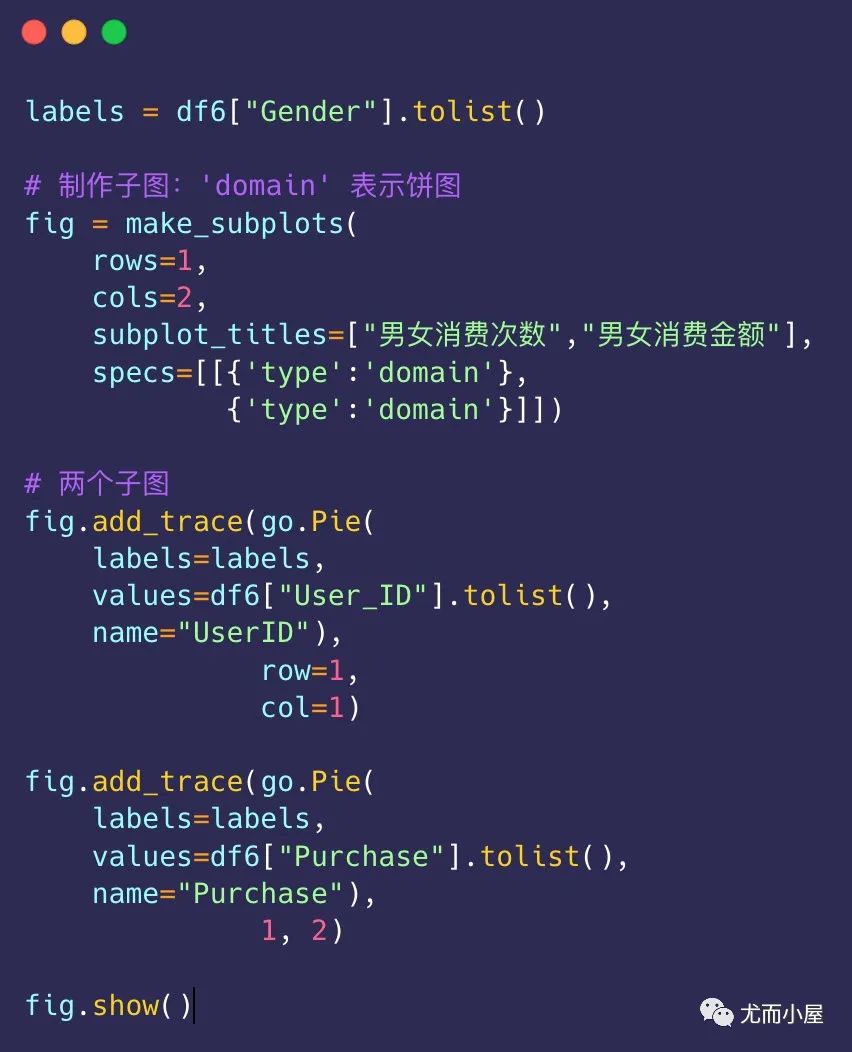
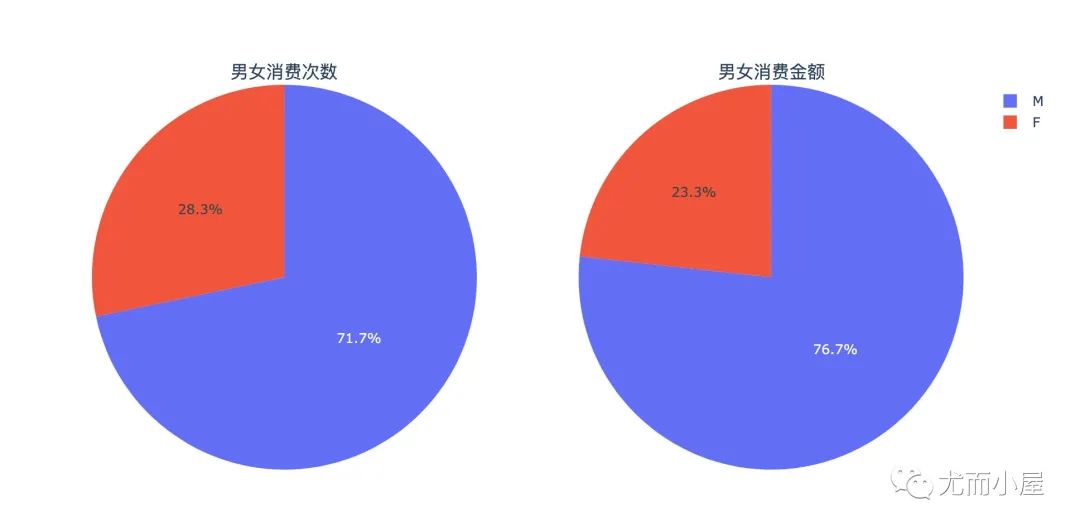
总结:男士才是消费主力军!
画像5:不同年龄的消费人数和金额
In [30]:
df7 = df.groupby("Age").agg({"User_ID":"nunique", "Purchase":"sum"}).reset_index()
df7
Out[30]:
| Age | User_ID | Purchase | |
|---|---|---|---|
| 0 | 0-17 | 218 | 134913183 |
| 1 | 18-25 | 1069 | 913848675 |
| 2 | 26-35 | 2053 | 2031770578 |
| 3 | 36-45 | 1167 | 1026569884 |
| 4 | 46-50 | 531 | 420843403 |
| 5 | 51-55 | 481 | 367099644 |
| 6 | 55+ | 372 | 200767375 |
In [31]:
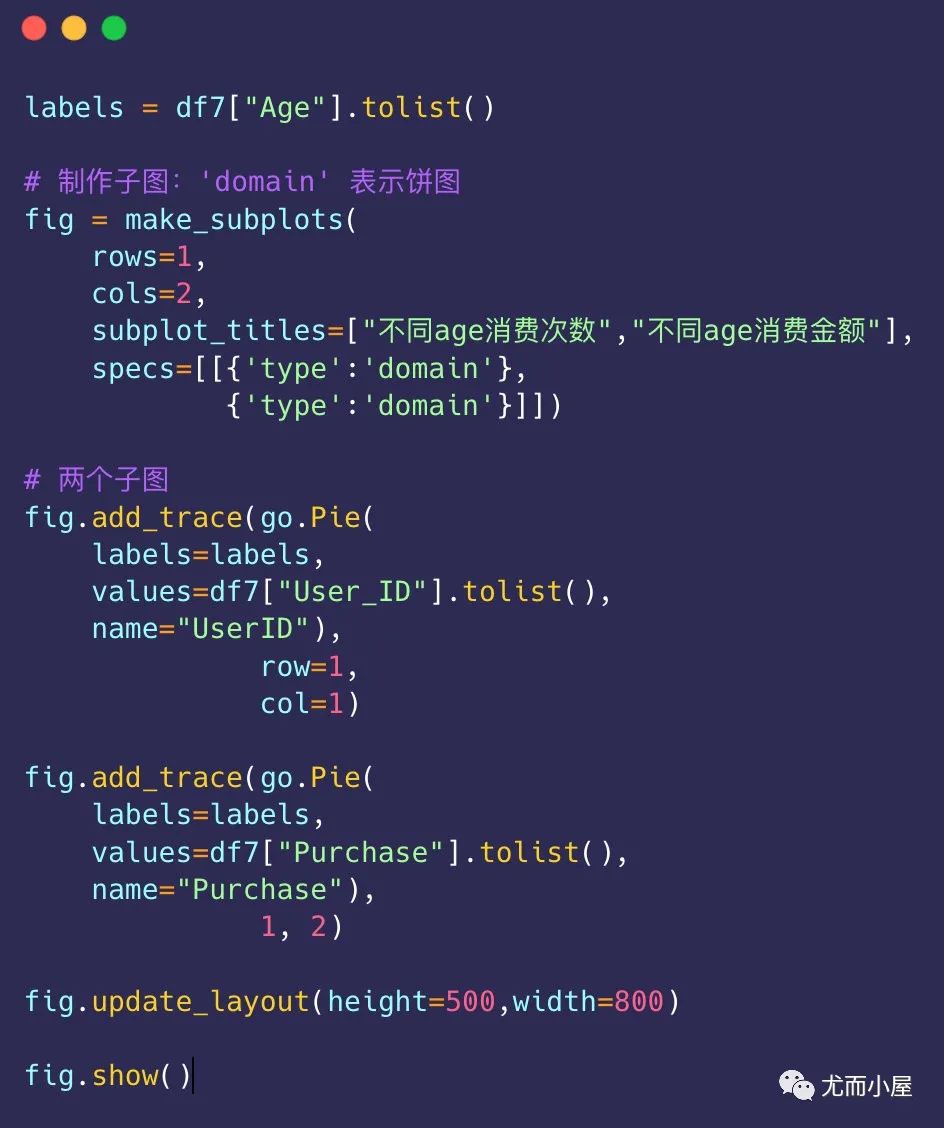
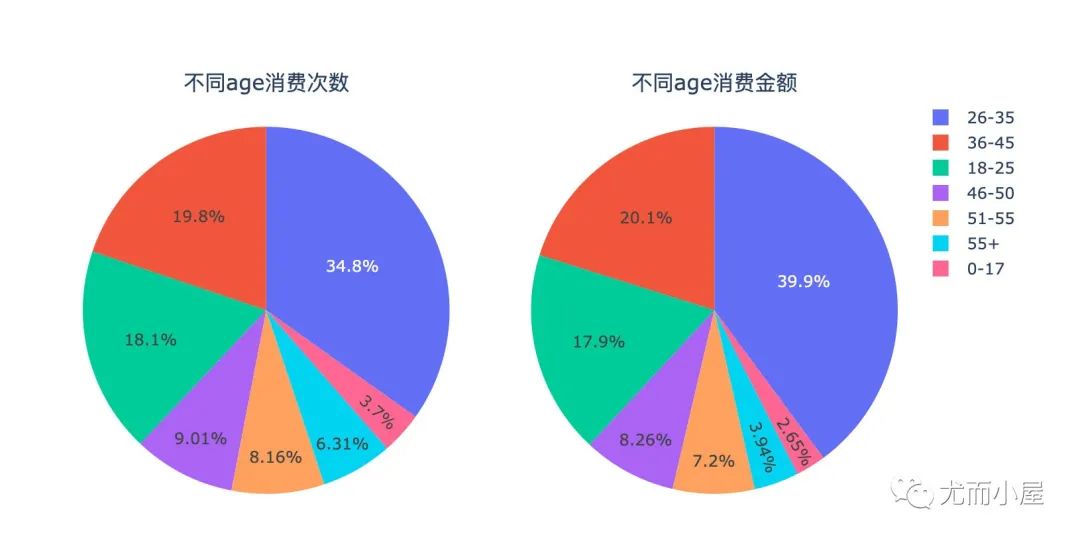
总结:26到35岁的人群,年轻人,大部分都是工作多年的用户,有家庭和经济基础,成为了消费主力军
画像6:不同性别+年龄的消费人数、金额
In [32]:
df8 = df.groupby(["Gender","Age"]).agg({"User_ID":"nunique", "Purchase":"sum"}).reset_index()
df8
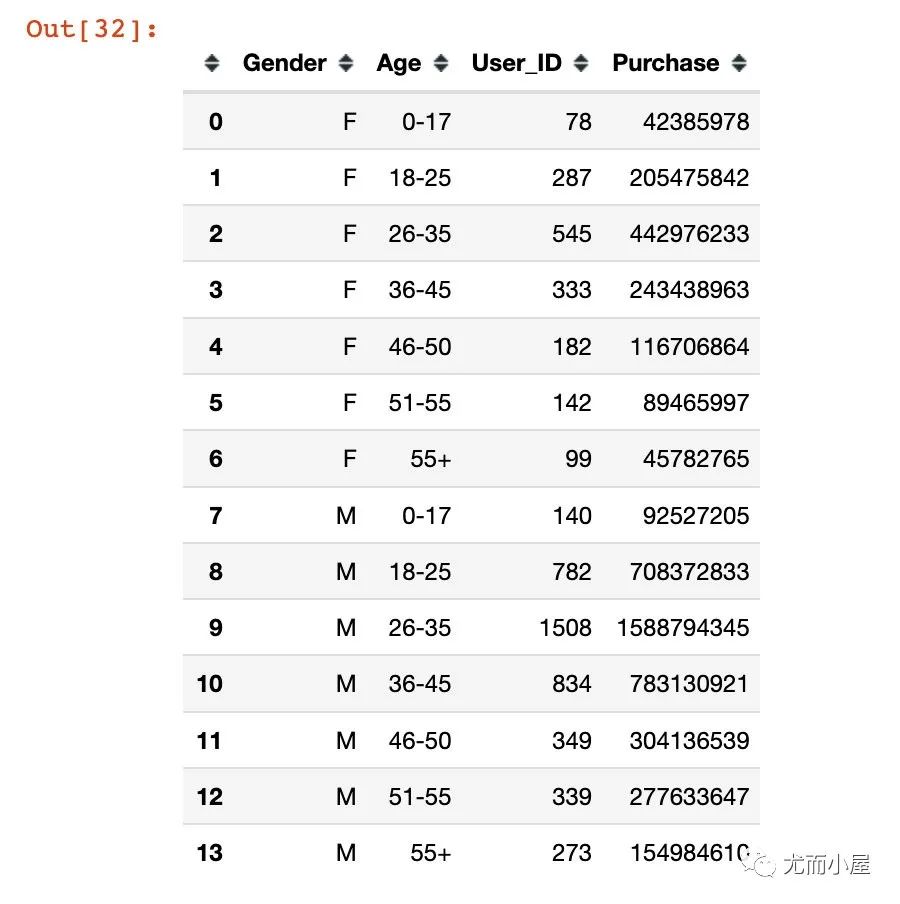
fig = px.treemap(
df8, # 传入数据
path=[px.Constant("all"),"Gender","Age"],
values="Purchase" # 消费金额
)
fig.update_traces(root_color="lightskyblue")
fig.update_layout(margin=dict(t=30,l=20,r=25,b=30))
fig.show()

画像7:不同城市、年龄消费金额
In [34]:
df9 = df.groupby(["City_Category","Age"]).agg({"User_ID":"nunique", "Purchase":"sum"}).reset_index()
df9.head()
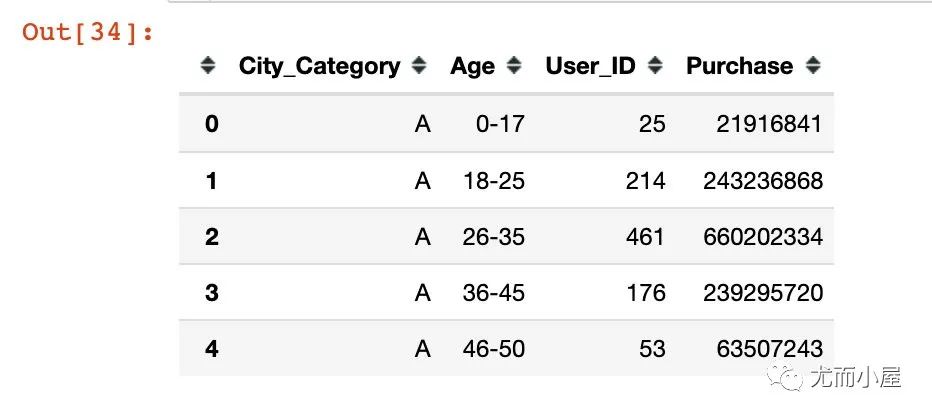
fig = px.bar(df9,
x="City_Category",
y="Purchase",
color="Age",
barmode="group",
text="Purchase"
)
fig.update_layout(title="不同城市不同年龄段的消费金额")
fig.show()
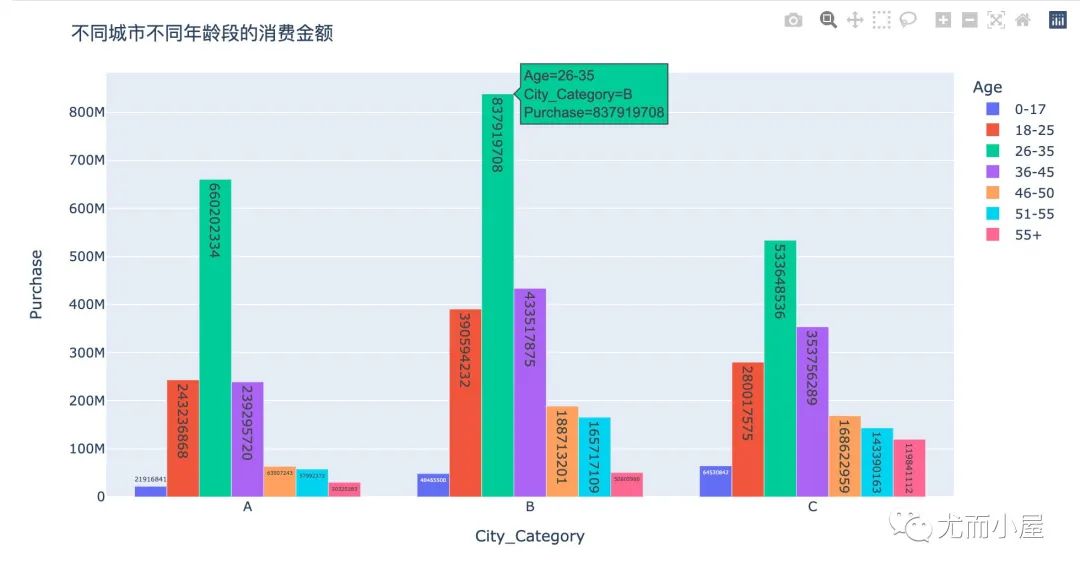
从3个城市来看,26-35一直都是消费主力

从上面的柱状图来看,在不同的年龄段,一直保持A < B < C的现象。C城市果真是消费的主要城市
画像8:不同婚姻状态的消费次数和金额
In [37]:
df10 = df.groupby(["Marital_Status"]).agg({"User_ID":"nunique", "Purchase":"sum"}).reset_index()
df10
Out[37]:
| Marital_Status | User_ID | Purchase | |
|---|---|---|---|
| 0 | 0 | 3417 | 3008927447 |
| 1 | 1 | 2474 | 2086885295 |
In [38]:
df10["Marital_Status"] = df10["Marital_Status"].map({0:"未婚",1:"已婚"})
In [39]:
fig = px.pie(names=df10["Marital_Status"],
values=df10["Purchase"]
)
fig.update_traces(
textposition='inside', # 文本显示位置:['inside', 'outside', 'auto', 'none']
textinfo='percent+label'
)
fig.show()
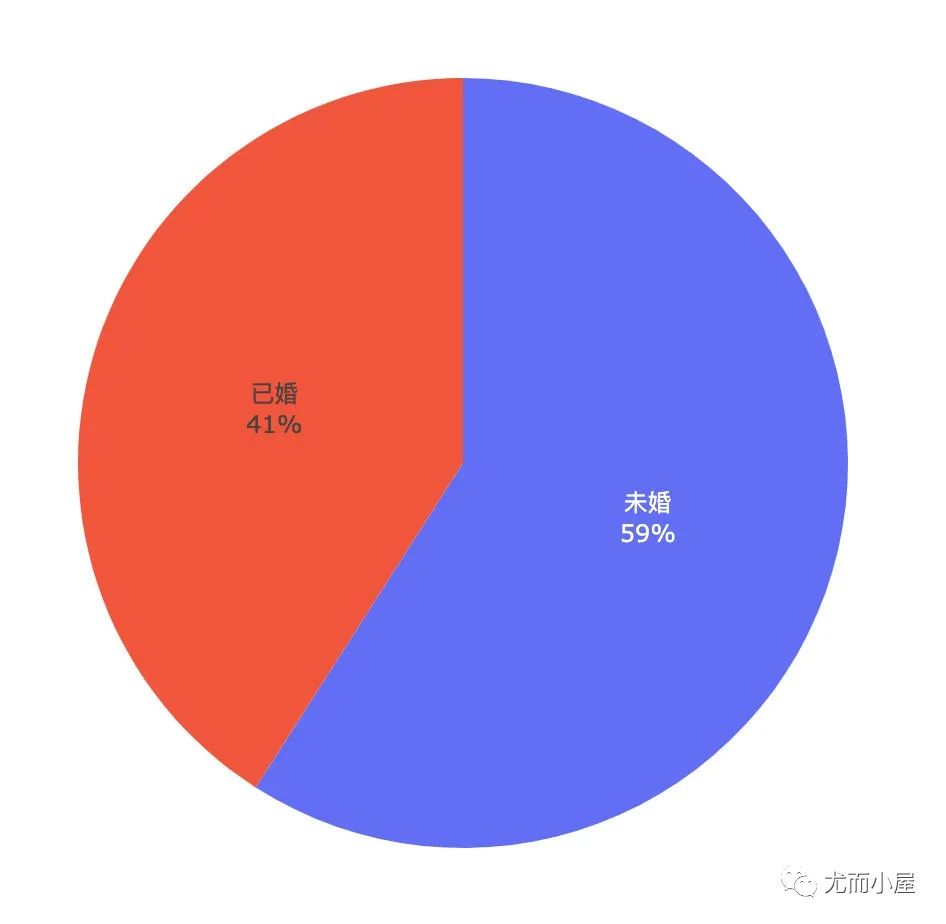
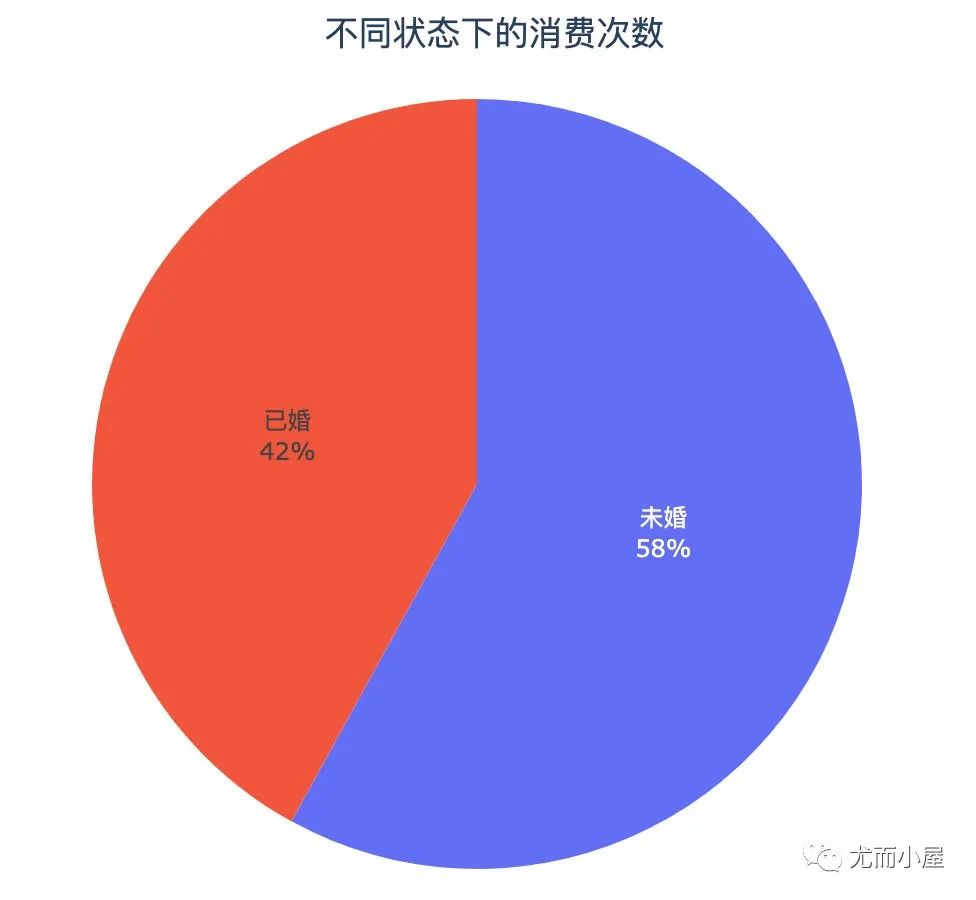
总结:单身自由,就是要买
画像9:城市停留时间
In [41]:
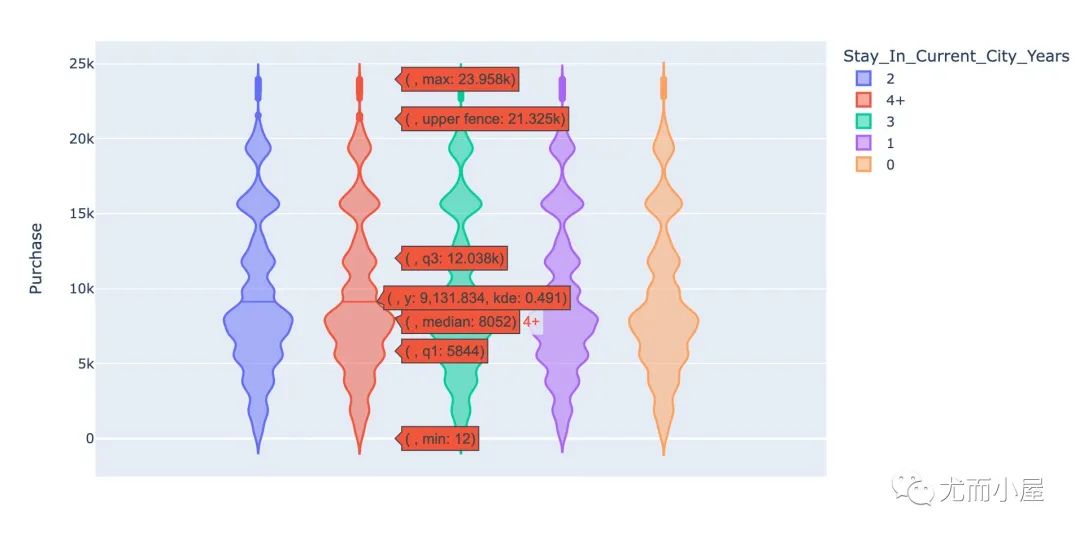
px.violin(df,
y="Purchase",
color="Stay_In_Current_City_Years")
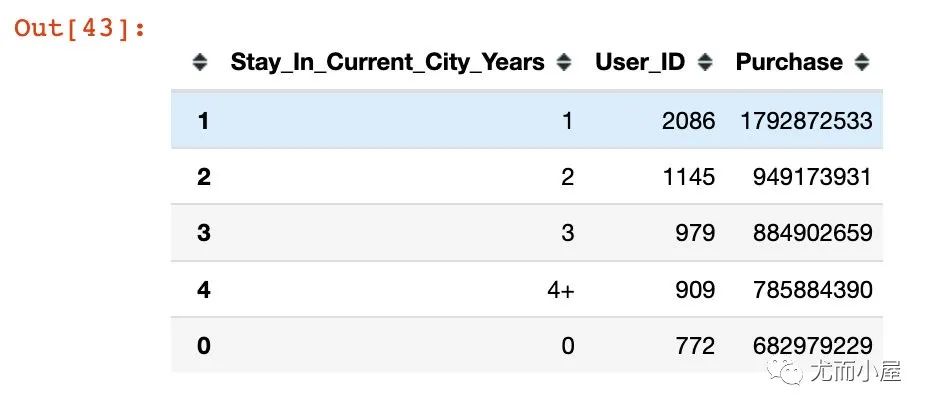
df11 = (df.groupby(["Stay_In_Current_City_Years"])
.agg({"User_ID":"nunique", "Purchase":"sum"})
.reset_index())
df12 = df11.sort_values("User_ID",ascending=False)
df12
stages = df12["Stay_In_Current_City_Years"].tolist()
fig = px.funnel_area(values = df12["User_ID"].tolist(),
names = stages
)
fig.show()
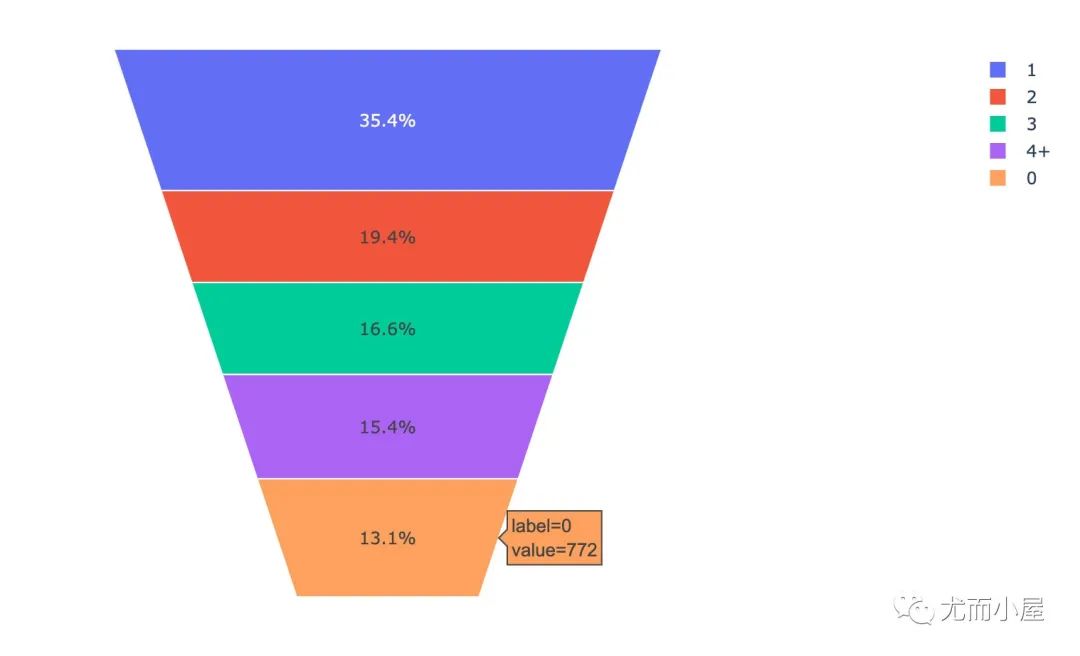
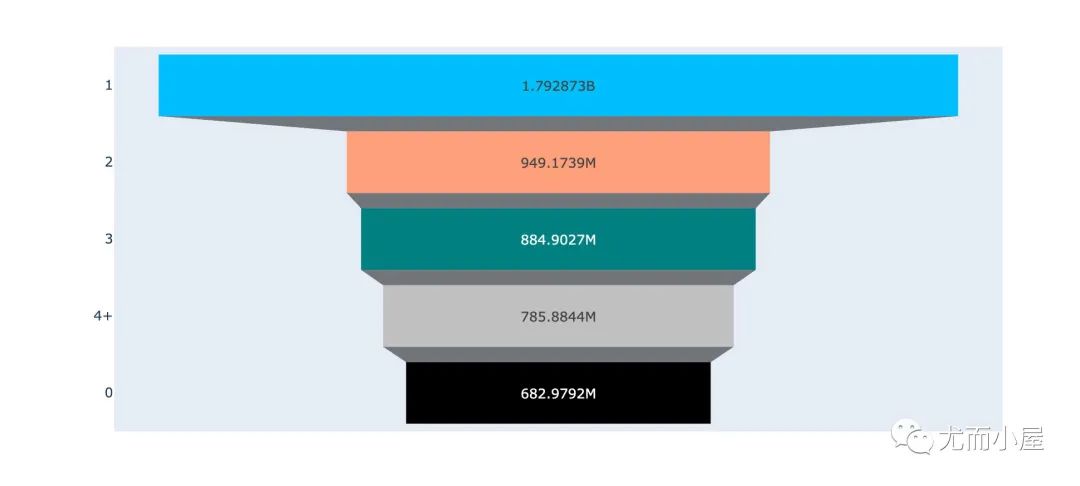
在一个城市停留1-2年内的用户更容易成为消费主力
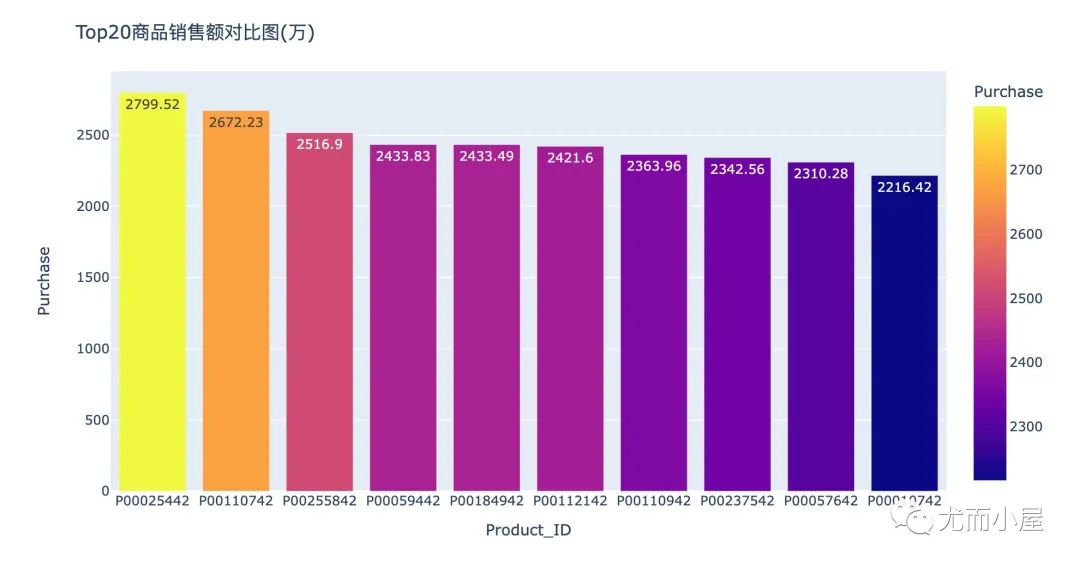
画像10:销售额Top20商品
In [46]:
df13 = df.groupby(["Product_ID"]).agg({"Purchase":"sum"}).reset_index()
# 改成以万为单位
df13["Purchase"] = df13["Purchase"].apply(lambda x: round(x / 10000,2))
# 销售额降序
df13.sort_values("Purchase", ascending=False, inplace=True)
df13
fig = px.bar(df13[:10], # 选择前10人
x="Product_ID",
y="Purchase",
color="Purchase",
text="Purchase")
fig.update_layout(title="Top20商品销售额对比图(万)")
fig.show()
画像11:二八法则
In [49]:
# 销售额
top20 = int(df13["Product_ID"].nunique() * 0.2)
top20
Out[49]:
726
In [50]:
sum(df13[:top20]["Purchase"]) / sum(df13["Purchase"])
Out[50]:
0.7325143993257992
通过计算的结果发现:销售额排名前20的商品其总销售额占据整体的73%,基本上是符合我们听到的二八法则
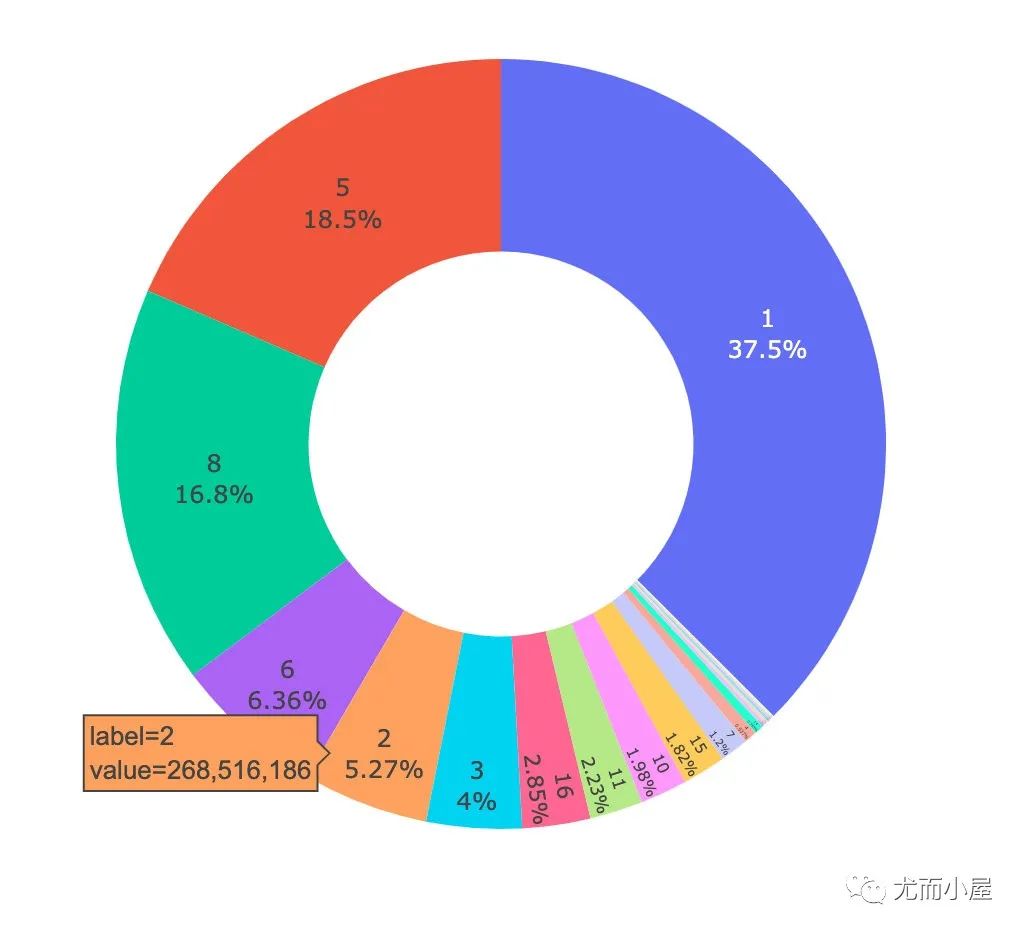
画像11:商品种类
In [51]:
df14 = df.groupby(["Product_Category_1"]).agg({"Purchase":"sum"}).reset_index()
fig = px.pie(names=df14["Product_Category_1"],
values=df14["Purchase"],
hole=0.5
)
fig.update_traces(
textposition='inside',
textinfo='percent+label'
)
fig.show()
px.box(df,
x="Product_Category_1",
y="Purchase",
color="Product_Category_1")

画像12:不同性别不同种类销售额
In [54]:
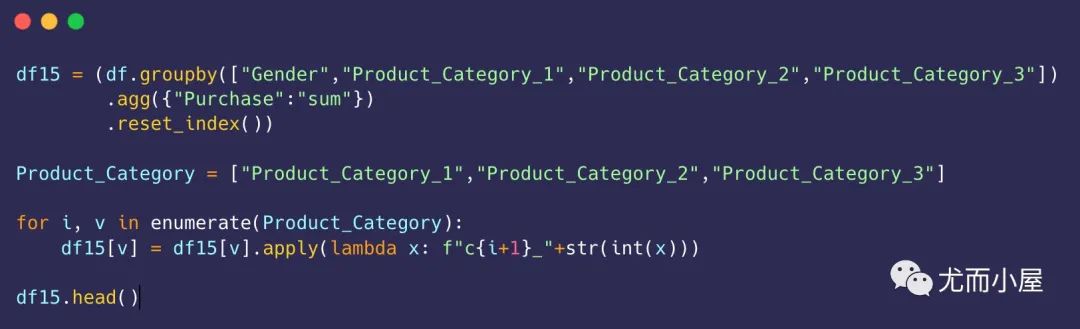
第一级
In [56]:
df16 = df15.groupby("Gender")["Purchase"].sum().reset_index()
df16
Out[56]:
| Gender | Purchase | |
|---|---|---|
| 0 | F | 416719106 |
| 1 | M | 1528099293 |
In [57]:
df16["Total"] = "总销售额"
In [58]:
df16 = df16[["Total","Gender","Purchase"]]
df16.columns = ["父类","子类","数据"]
df16
Out[58]:
| 父类 | 子类 | 数据 | |
|---|---|---|---|
| 0 | 总销售额 | F | 416719106 |
| 1 | 总销售额 | M | 1528099293 |
第二级
In [59]:
df17 = df15.groupby(["Gender","Product_Category_1"])["Purchase"].sum().reset_index()
df17.head()
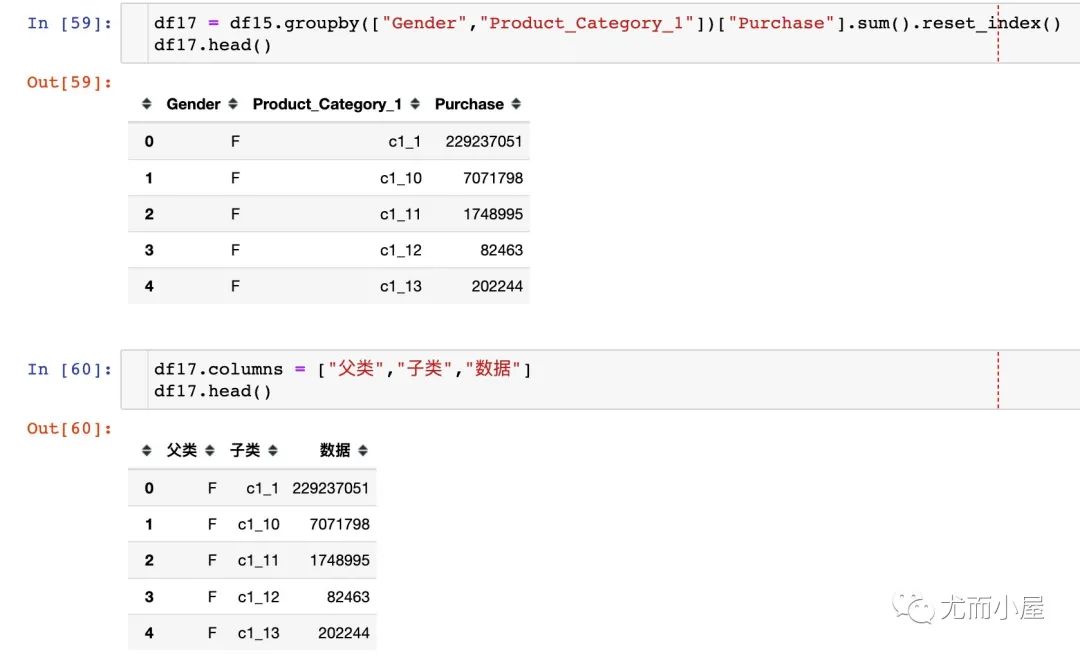
第三级
In [61]:
df18 = df15.groupby(["Product_Category_1","Product_Category_2"])["Purchase"].sum().reset_index()
df18.head()
Out[61]:
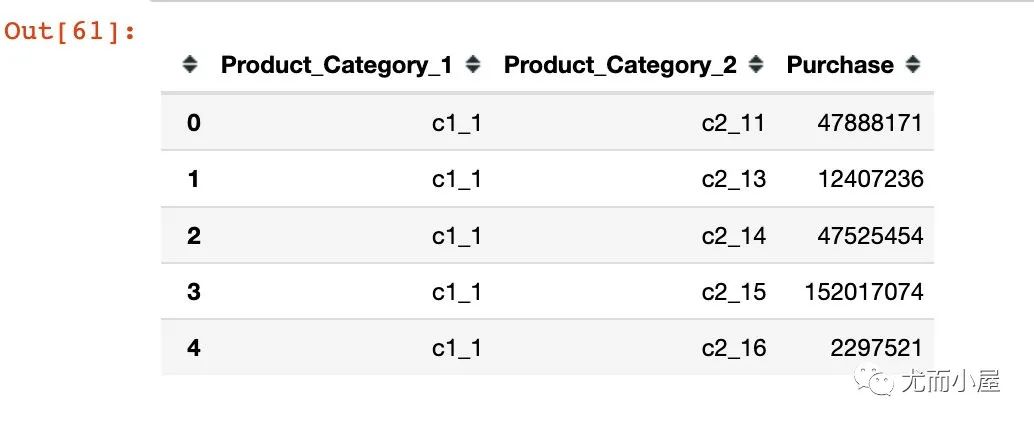
In [62]:
df18.columns = ["父类","子类","数据"]
第四级
In [63]:
df19 = df15.groupby(["Product_Category_2","Product_Category_3"])["Purchase"].sum().reset_index()
df19.head()
Out[63]:
In [64]:
df19.columns = ["父类","子类","数据"]
数据合并
In [65]:
df20 = pd.concat([df16,df17,df18,df19],axis=0).reset_index(drop=True)
df20.head()
Out[65]:
子类和父类元素个数
In [66]:
labels = list(set(df20["父类"].tolist() + df20["子类"].tolist()))
labels[:5]
Out[66]:
['c1_3', 'c3_14', 'c3_18', 'c2_4', 'c2_12']
元素字典设置
In [67]:
number = list(range(0, len(labels)))
index = dict(list(zip(labels, number)))
配对
In [68]:
df20["父类索引"] = df20["父类"].map(index)
df20["子类索引"] = df20["子类"].map(index)
df20
Out[68]:

绘图
In [69]:
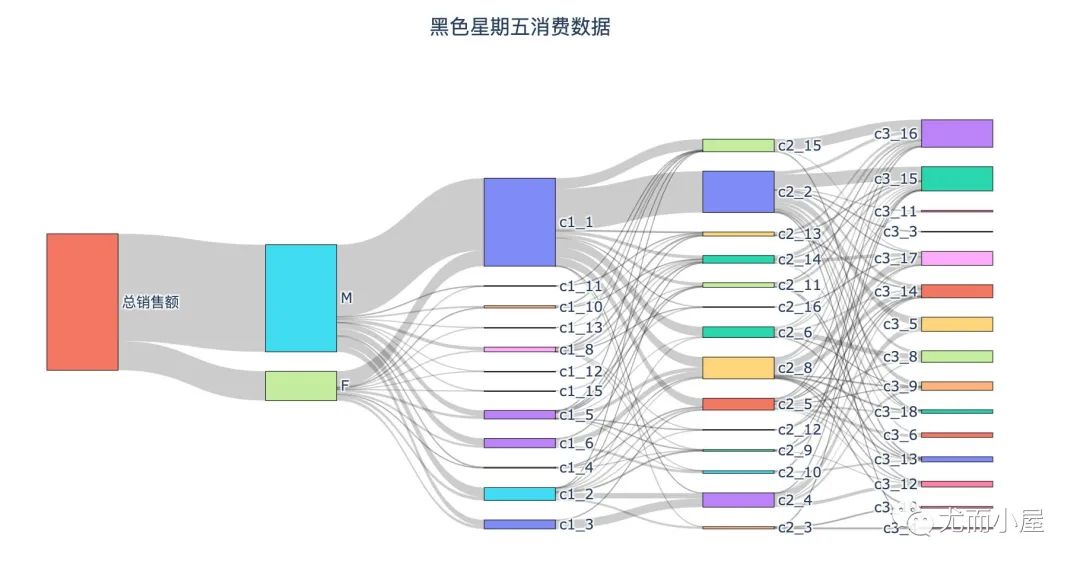
从性别、3个不同的商品类别来看:
男性的消费能力远高于女性 在商品1中,1号品类是一个高需求的物品;在商品2中,2号最高,8号其次 在商品3中,头部需求的物品差距缩小,整体的需求更均衡 从商品种类的关联性来看,c1_1、c2_2、c3_15是最强的
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码