
单路径NAS: 在四小时内设计出给定硬件内最有效的网
作者:晟 沚
编辑:赵一帆
写在最前面
这篇paper[Single-Path NAS: Designing Hardware-Efficient ConvNets in less than 4 Hours]是2019年4月在arxiv上的新文章,来自CMU、微软和哈工大,论文提出了Single-Path NAS,将搜索时间从200 GPU时降低至4 GPU时,同时在ImageNet上达到了74.96% top-1的准确率。
1
概述
目前网络结构搜索(NAS)的解决方案已经逐渐从强化学习,演变算法转至基于梯度的方案,并取得了很好的效果.然而,NAS问题由于需要巨大的组合设计空间,导致需要很长的搜索时间(至少200 GPU-hours).为了缓解这个问题,作者提出了Single-Path NAS,一个硬件有效的新颖的可微分NAS方法,在四小时内搜索出效率最高的网络结构.
最终的contribution如下:
Single-path search space: 和之前的可微分NAS方法相比, Single-Path NAS使用一个single-path的超参数化(over-paramerterized)的卷积网络来编码所有的架构可能性,同时有共享的卷积核参数.因此能够急剧地减少需要训练的参数和搜索所需要的epoch数量;
Hardware-efficient ImageNet classification: 在ImageNet上达到了74.96%的top-1分类准确率,同时在Pixel 1手机上的延迟是79ms,达到了state-of-the-art的结果;
NAS efficiency: 搜索消耗仅仅需要8 epochs(30 TPU-hours), 比之前的方法快了5,000倍
Reproducibility: 开放了源码,地址在: https://github.com/dstamoulis/single-path-nas
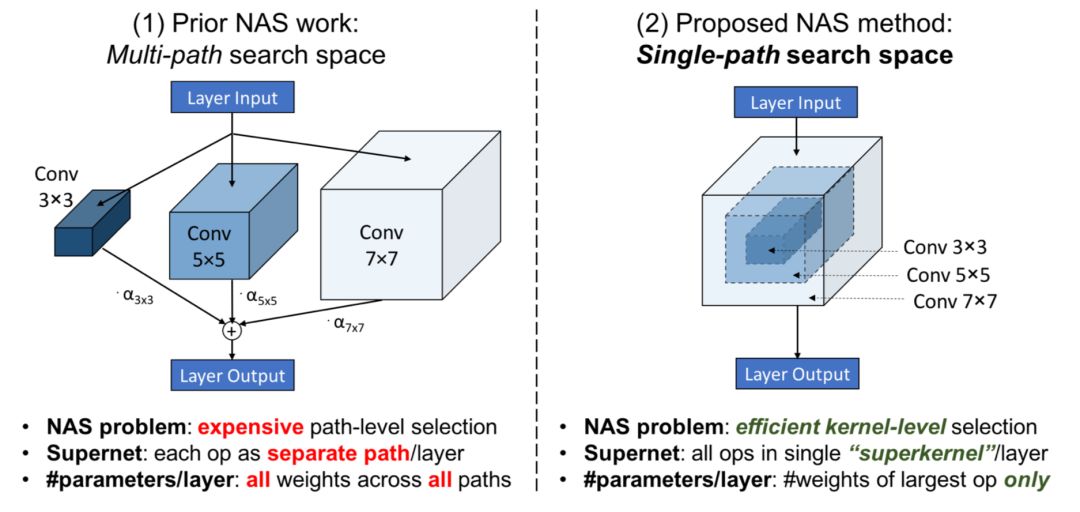
之前的multi-path NAS的低效性: 当前的NAS方法放松找到最优结构的联合优化问题为一个operation/path的选择问题. 首先,构建一个多path的supernet,然后对于每个layer,每个候选的操作作为一个分离的可训练的path添加,如上图左所示.然后NAS解决multi-path supernet的path分布来寻求到最优的架构.
一个最直观的限制就是: 在搜索的过程中随着每层layer的候选操作的数目的线性增加,可训练参数的数量也需要维持和更新,这样就引起显存爆炸的问题.目前的解决方案比如在proxy数据集上搜索, 或者在搜索过程中只更新multi-paths的一个子集(比如ProxylessNAS).然而,他们的方法仍然非常耗时,至少需要200GPU-hours.
如上图右所示,在这篇文章中主要的insight是观测到在NAS中不同的候选的卷积操作可以看成是一个过参数化(over-parameterized)的单独的"superkernel"的子集。这个观测就允许把NAS组合问题看成是找到在某一层中kernel weights子集的问题。通过卷积核的参数共享,就能把所有候选的NAS operations编码成一个单独的"superkernel"中.
2
方法部分
手机卷积网络搜索空间: 一个全新的视角
2.1
网络的搭建基础是MobileNetV2.整个网络的搭建使用7个Block,每个Block中包含4个MBConv.每个MBConv由一个point-wise(1x1)卷积,一个kxk卷积核一个线性1x1卷积组成.除非这个layer是下采样的,否则都会加上残差连接.
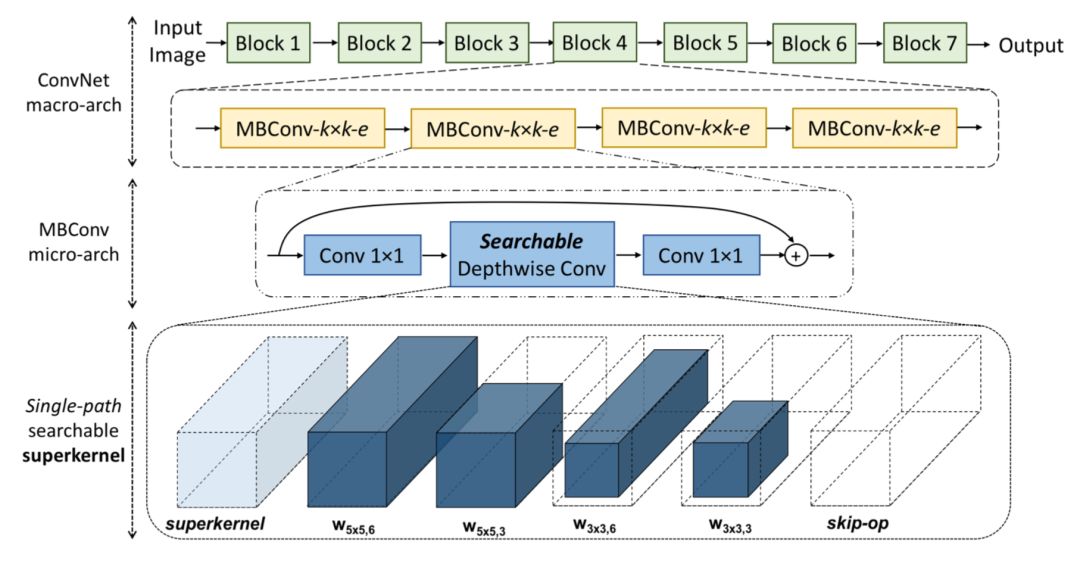
每一个MBConv layer由k和e两个参数决定,其中k表示depthwise conv的kernel size,e表示第一个1x1卷积的输出和输入的ratio.除此之外,也有 skip-op "layer",即直接将两个1x1卷积相连.
上面也提到过,在这篇文章中主要的insight是观测到在NAS中不同的候选的卷积操作可以看成是一个过参数化(over-parameterized)的单独的"superkernel"的子集。这个观测就允许把NAS组合问题看成是找到在某一层中kernel weights子集的问题。这个观测十分重要,因为它允许在不同的MBConv架构选择中共享kernel参数.如图所示,把所有候选的NAS操作编码到单独的"singlekernel"中,换句话说,single path而不是multi-path.
提出的方法: Single-Path NAS表达
2.2
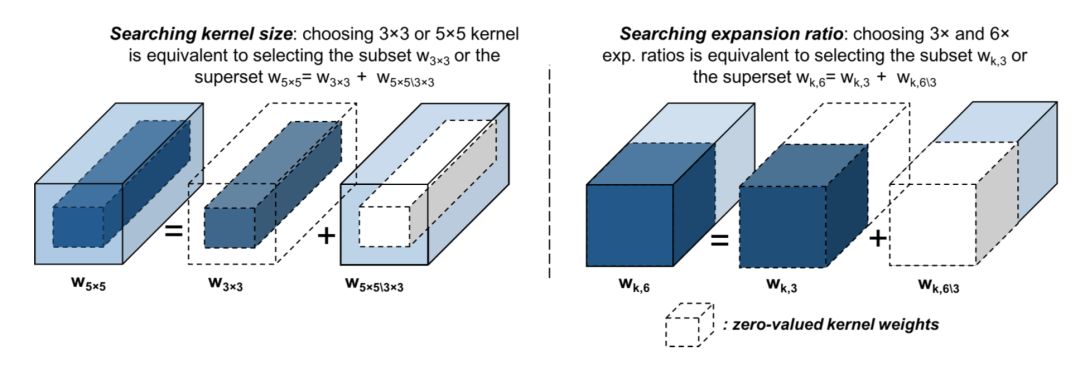
不失一般性,给出了如下的例子,对于MBConv Layer中3x3和5x5的kernel的选择,可以看成:3x3的卷积核权重可以看成是5x5卷积核权重除去"outer"shell的剩余部分(如上图左).因此可以写成如下公式:
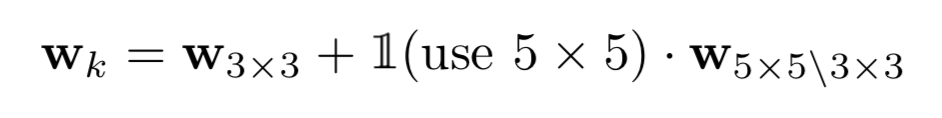
其中1(.)表示编码了NAS架构选择的指示函数(3x3 or 5x5).
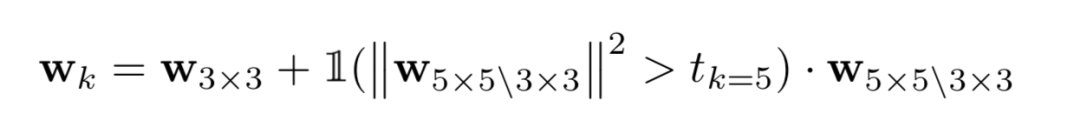
为了将这种表示转为可训练的参数,作者提出使用潜在变量来控制决定(e.g. 一个阈值)是否选择kernel 5x5.值得注意的是,阈值的选择并非手动设置而是作为可训练参数由梯度下降法学到.特别地,为了计算阈值的梯度,将指示函数放松到了sigmoid函数.
对于expansion ratio和skip-op,同样也可以看成在channel数量维度上的"zeroing"操作,加上'skip-op' path,整个可以形式化到如下式子:
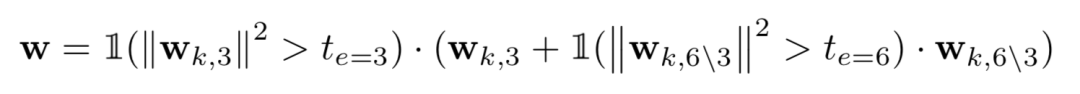
Single-Path VS. Existing Multi-Path
2.3
单路径NAS和多路径NAS的比较分为以下几个方面:
参数方面:
在多路径NAS如(DARTs)中,参数量包括所有path网络本身的参数和架构搜索编码参数,参数量非常巨大;而单路径NAS直接用一个superkernel表示了网络的参数.参数量瞬间减小了许多.
优化方面:
之前的多路径NAS采用迭代优化的方式(优化网络本身的参数和架构结构参数),存在bi-level优化的难题,而单路径NAS需要优化的仅仅是“superkernel”的权重,至于一些上述的变量,都是来自于权重的.因此,这样的优化是非常有效的.
硬件特定的可微分运行损失
2.4
对于现在网络在不同硬件设备上的延时,可以通过在训练过程中加入一项延时正则,来使用梯度下降一起联合优化.
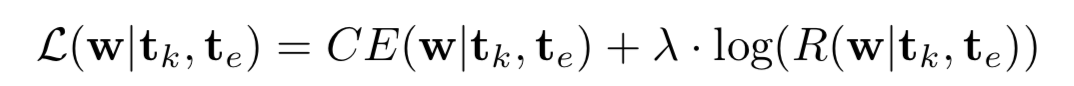
其中,CE表示交叉熵损失,R表示在特定硬件平台上的NAS搜索出的模型运行时间(ms),lamda为平衡两个loss的系数.
3
实验部分
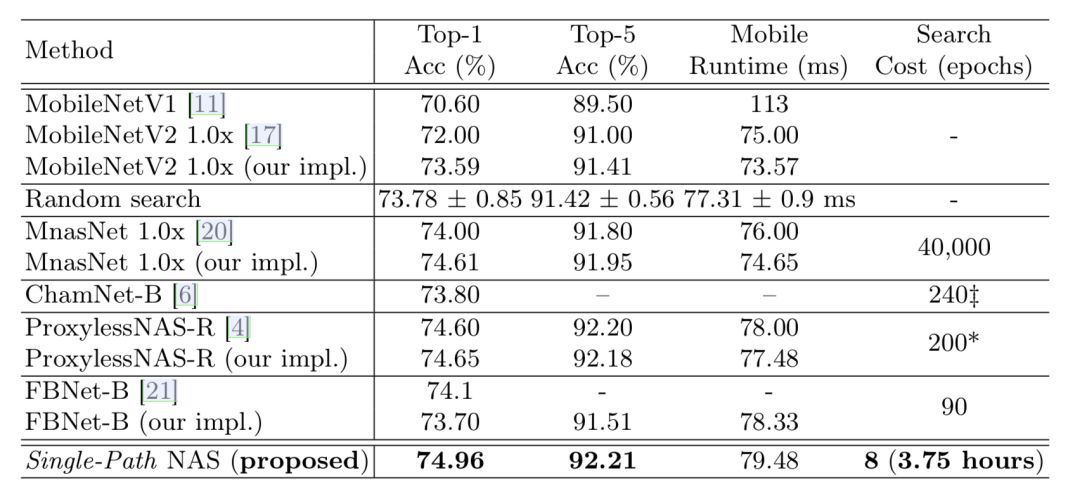
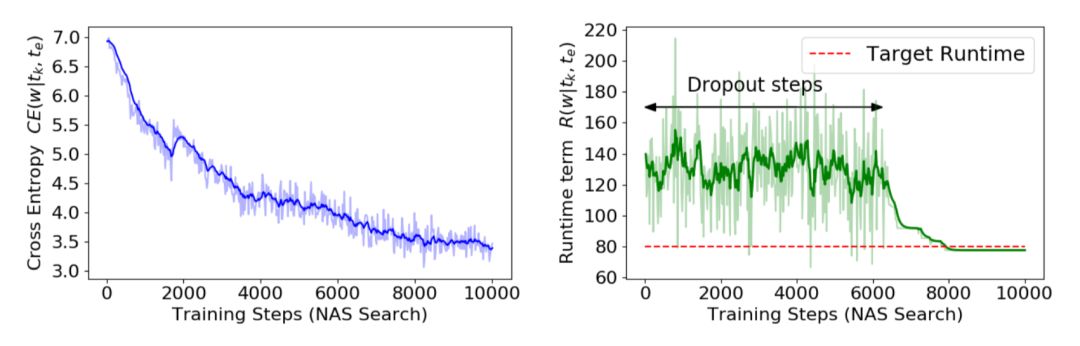
实验在Google Pixel 1手机上作为目标平台,使用Tensorflow实现,最终的效果在ImageNet上达到了74.96% top-1的准确率(手机上inference时间小于80ms),并且搜索时间和之前的方法对比大大降低.比ProxylessNAS搜索耗时快了25倍,比MnasNet快了5000倍,比FBNet快了11倍.在搜索的过程中,仅仅需要8个epoch.
下图是搜索过程中CE和R的可视化曲线.
也可视化出了最终model的可视化结构.

4
总结
目前为止,基于梯度的NAS可以分成单路径和多路径两种方案,目前来看,单路径的NAS确实在搜索效率和显存占用情况要大大优于多路径NAS.除此之外,本文提到的方法不仅仅可以适用于基于梯度的NAS,也同样可以迁移到基于强化学习和演变算法等的网络结构搜索解决方案中.
机器学习算法工程师
一个用心的公众号
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助
