NAS在检测中的应用

极市导读
本文主要介绍将NAS用于detection上,作者以NAS-FPN作为开场,陆续介绍了EfficientDet、SpineNet、CRNAS。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
一. NAS-FPN
这篇文章里使用RNN Controller来做NAS,以前看[1]、[2]时留了一些疑问,所以就在这先说说RNN控制器。
RNN-Controller:最早的NAS文章[1]中,强化学习模型的主体是RNN结构,用来做序列处理。那么如何采样到状态转换序列呢?很简单,先初始化一个RNN,begin token做输入送入RNN输出第一层结构,第一层结构做输入送入RNN输出第二层结构......就这样先在一个eposide期间得到整个网络结构,重复采样多个eposide,就可以采样到多个  序列,这个r是怎么得到了呢?就是一个eposide采样得到的整个网络的精度,有了精度作为回报就可以更新RNN了。
序列,这个r是怎么得到了呢?就是一个eposide采样得到的整个网络的精度,有了精度作为回报就可以更新RNN了。
在之后的NAS文章[2]中,不对整个模型做搜索,而是去搜索网络的基本Cell,然后将搜索得到的Cell堆叠起来构成网络的整体结构,更具体的,每个Cell有更细致的微结构。从大的层面来看,Normal Cell和Reduction Cell都接受两个输入  和
和  。在生成Cell结构的过程中,论文巧妙的将其递归的分成几步,每一步的操作都是一样的。具体的,生成Normal Cell和Reduction Cell的过程,就是将下面的过程重复B次,先验条件下,B=5。步骤如下:
。在生成Cell结构的过程中,论文巧妙的将其递归的分成几步,每一步的操作都是一样的。具体的,生成Normal Cell和Reduction Cell的过程,就是将下面的过程重复B次,先验条件下,B=5。步骤如下:
从
和 或上一步中得到的隐含状态中选择一个作为输入一。从
和 或上一步中得到的隐含状态中选择一个作为输入二。(可以与第一个一样)从操作集合中选择一个操作应用在输入一上。
从操作集合中选择一个操作应用在输入二上。
选择一个方法将第三步和第四步的结果合并。
这时的NAS如何采样到状态转换序列?
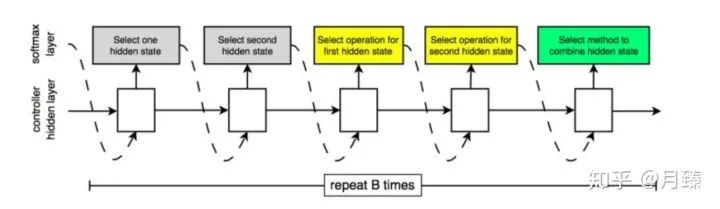
RNN的每步输出可以是不同种类的信息,什么意思呢?从上图可以看出来,采样仍然是分步采样的,即softmax layer作为RNN的输入输出第一个选择的隐含状态,第一个选择的隐含状态作为输入输出第二个选择的隐含状态......这里可能就存在一个问题输入和输出的集合不是同一个集合,但是即使操作集合和状态集合不一样大,也不影响将状态或者操作通过词嵌入映射到同一维度;反之,输出时也不影响将同一纬度的东西映射成不同维度的probability vector来回到操作集合或者状态集合。
二. EfficientDet
之前已经有很多的工作设计更加高效的检测器结构(比如one-stage或者anchor-free的检测器、对现有结构进行压缩),但这些方法大都以获得更高的效率为目标而对精度有损,同时只针对特定的硬件约束无法充分利用实时变化的资源限制。因此就有了一个很自然的问题:有没有可能构建一个效率和精度更高的可扩展的检测器结构,同时可以缩放模型来应对不同的资源限制?基于one-stage的检测器结构组成,作者重新审视了backbone、neck(论文中的FPN部分)、head(论文中的class/box网络),确定了两个主要挑战:
Challenge 1:高效的多尺度特征融合——之前从FPN、PANet、NAS-FPN中已经介绍了各种进行跨尺度特征融合的网络结构,它们都有一个共同点:当融合不同分辨率的输入特征时,都是简单地将它们进行相加。然而由于分辨率不同它们对于融合后的特征的贡献应该是不等价的,为了解决这个问题,作者提出了一种简单而高效的加权双向特征金字塔网络(BiFPN),它对不同分辨率的输入特征引入不同的加权值,同时应用了top-down和bottom-up的特征融合;
Challenge 2:模型缩放——之前的方法中通常会采用更大的backbone或者更大的输入图片来提高检测精度,我们观察到当将高效性和精度同时考虑在内的话,缩放特征网络和box/class网络同样很重要。受到EfficientNet的启发,因此作者提出了一种复合缩放方法,它可以对所有的backbone、feature network、box/class prediction network同时做resolution/width/depth上的联合缩放;
以EfficientNet为backbone,结合BiFPN和复合缩放方法,作者提出了EfficientDet[4]——一种可扩展式的检测器。
1. BiFPN
在本节,作者先公式化了多尺度的特征融合问题,然后为BiFPN引入了两个核心观点:高效的双向跨尺度连接和加权特征融合。
1.1 Problem Formulation
多尺度特征融合旨在融合不同分辨率的特征。给定一组输入特征  ,这里的
,这里的  指的是在
指的是在  等级的特征,其特征分辨率为 input resolution/
等级的特征,其特征分辨率为 input resolution/  ,我们的目标是找到一个转换函数f来高效地融合不同的特征,输出一组新特征:
,我们的目标是找到一个转换函数f来高效地融合不同的特征,输出一组新特征:  。
。
以Figure 2(a)中FPN的特征融合为例,它的输出为:

1.2 Cross-Scale Connections
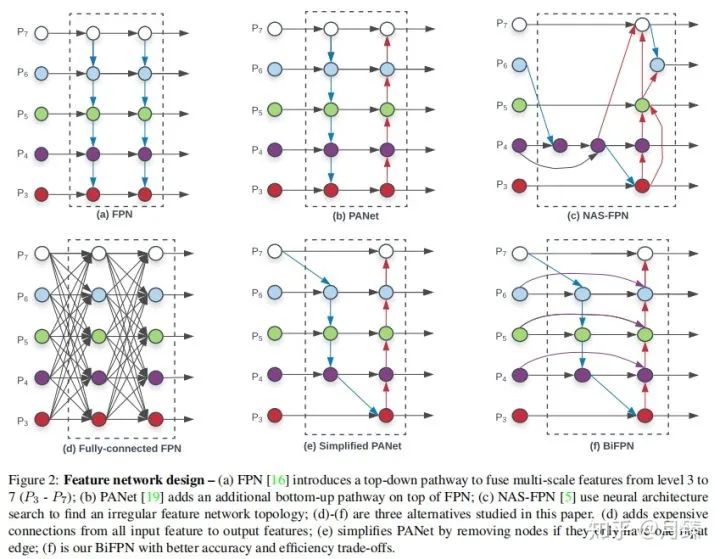
和RetinaNet设置一样,也是采用了P3-P7作为neck的特征融合层。作者通过这几个简化图清楚地展示了思考过程,(a)是原始FPN特征融合,通过top-down支路增加了大特征图的高层语义信息,提高了小物体的检测精度,但同时使得顶层的特征优化的没有以前好,大物体的检测精度比较低;(b)在(a)的基础上加上了bottom-up特征融合,使得顶层特征的细节信息变得更多了;(c)通过NAS搜索的特征融合方式。
通过研究FPN、PANet和NAS-FPN的性能,作者发现PANet比其他两个的表现要好,但是它的计算成本也更加昂贵,所以为了提高模型的效率,作者从NAS-FPN中的设计中获取灵感来对PANet进行改进,做了以下优化:
首先,移除只有一条输入边的节点,因为从直觉上这样的节点对网络特征融合贡献的小,即(b)变成了(e);
第二点,如果输出节点和输入节点在同一个等级,在它们之间条件一条边,(e)变成了(f)
最后,不像PANet只有一条top-down和botton-up路径,在这里可以重复堆叠这样的路径来获取更高级的特征;
1.3 Weighted Feature Fusion
不同层对最终融合的特征影响实际上是不同的,但是RetinaNet采用的是直接相加进行融合,当然更理想的情况是可以自适应地进行加权求和。最直接的就是引入可学习的权重就好了。基于这个想法,考虑下面三种加权方式:
Unbounded fusion:
 ,这里的
,这里的  可以是一个标量(per feature)、一个向量(per channel)、一个多维度的tensor(per-pixel)。然而由于加权值是无界的,这经常会导致训练不稳定。所以考虑对加权值应用正则化技术;
可以是一个标量(per feature)、一个向量(per channel)、一个多维度的tensor(per-pixel)。然而由于加权值是无界的,这经常会导致训练不稳定。所以考虑对加权值应用正则化技术;Softmax-based fusion:
 ,这样就将加权值约束到0-1之间,但是由于softmax这会导致增加额外的计算成本,运行速度变慢;
,这样就将加权值约束到0-1之间,但是由于softmax这会导致增加额外的计算成本,运行速度变慢;Fast normalized fusion:
 ,权重经过relu保证是大于0的,然后简单地做求和归一化,可以同时保证精度和实际运行速度;
,权重经过relu保证是大于0的,然后简单地做求和归一化,可以同时保证精度和实际运行速度;
最后我们的BiFPN整合了双向跨尺度连接和fast normalized fusion,这里我们描述了Figure 2(f)中level 6处的两个融合特征:

2. EfficientDet
基于BiFPN,作者衍生出了一族检测模型,命名为EfficientDet。在本节,我们讨论整个模型的结构和复合缩放方法。
2.1 EfficientDet Architecture
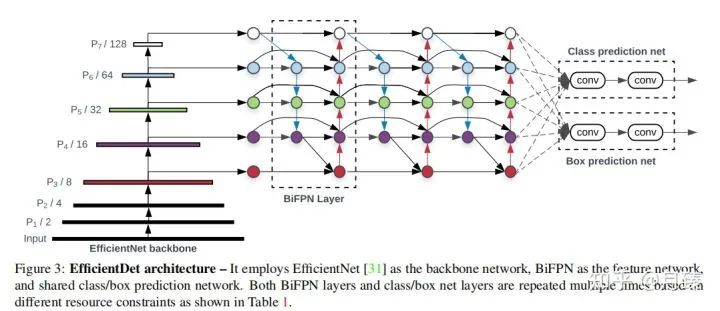
上图是EfficientDet模型的整体结构,backbone是在ImageNet上预训练好的EfficientNet,BiFPN作为neck产生高级的融合特征,这些融合特征最后被送进class/box网络来产生最终的预测结果。
2.2 Compound Scaling
和EfficientNet一样引入了复合系数进行联合优化,在gird search基础上加了一些先验,如下:
Backbone network:直接利用EfficientNet的B0-B6作为预训练的backbone。
BiFPN network:指数调整BiFPN的channel数,线性调整BiFPN的depth,即:
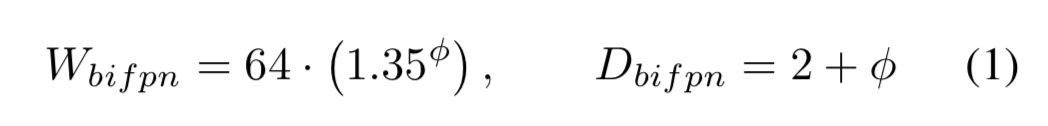
Box/class prediction network:channel数和BiFPN保持一致,线性调整depth,即:
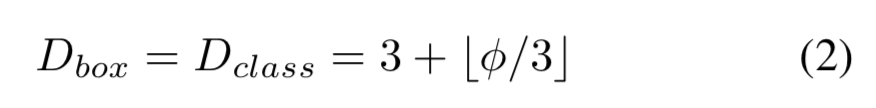
Input image resolution:因为使用了P3-P7层进行特征融合,输入分辨率调整后必须是128的倍数,即:
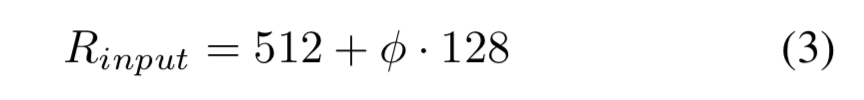
以上就是EfficientDet根据复合系数  进行调整的策略了,总结如下:
进行调整的策略了,总结如下:

3. 实验结果
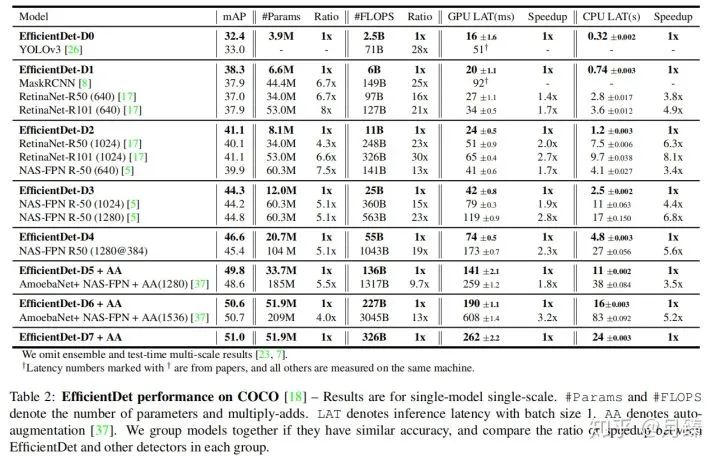
下面这张图展示了EfficientDet这个系列在相同参数量和计算量下相对之前的模型的优越之处:
3.1 Ablation Study
3.1.1 Disentangling Backbone and BiFPN

首先来研究过Backbone和特征融合对检测精度的影响。从ResNet50+FPN出发,先使用EfficientNet-B3替换ResNet50,map涨了3个点,参数量和FLOPS反而下降了;再进一步使用BiFPN替换FPN,直接涨了4个点,同时参数量和计算量也下降了,这可能是因为使用的是深度分离卷积。
3.1.2 BiFPN Cross-Scale Connections
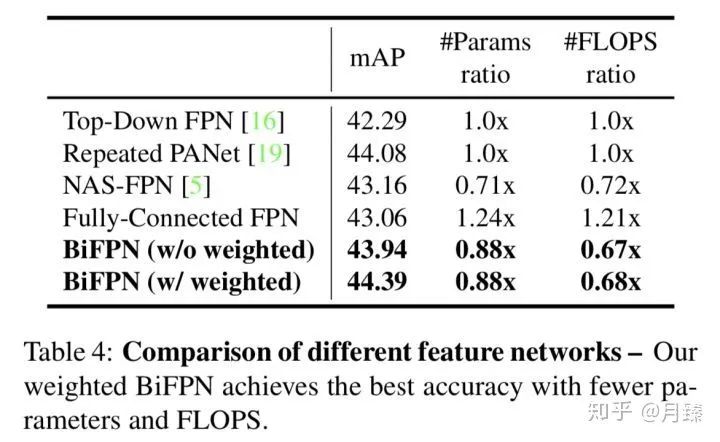
原始的PANet和FPN都只有一次top-down和botton-up路径,为了进行公平的比较,这里将其分别堆叠了5次。BiFPN的精度和Repeated PANet[6]基本持平,但是计算量和参数量都有降低,此外利用加权特征融合后,BiFPN的精度又能进一步提升。
3.1.3 Softmax vs Fast Normalized Fusion
接着是对加权融合方式的研究,结果如下:
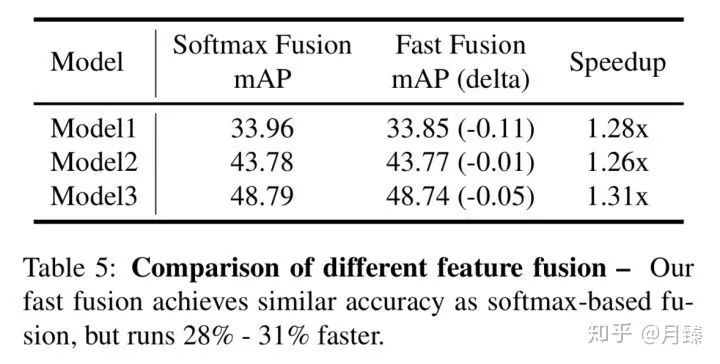
可以看出来,Fast Fusion取得了和Softmax Fusion相近的结果,但加速效果很明显。
3.1.4 Compound Scaling
最后研究了单一维度上的scale和这种联合scale的影响:
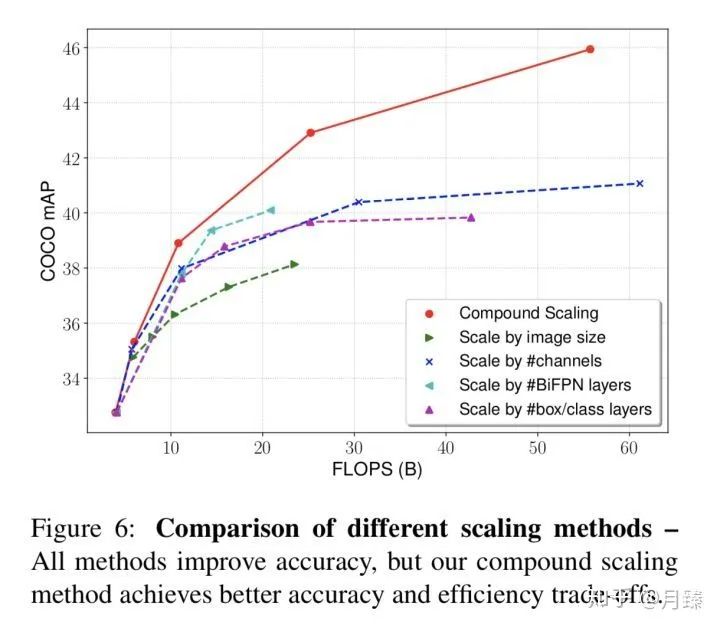
三. SpineNet
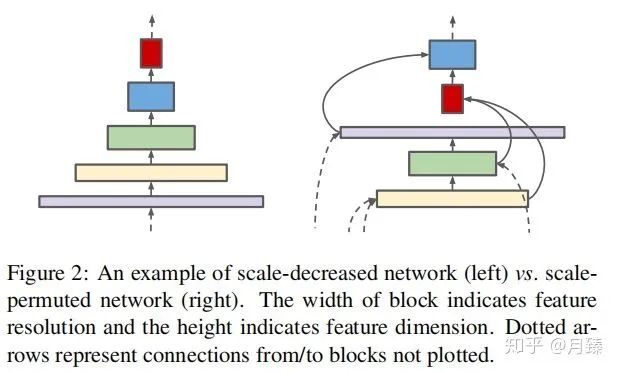
在分类任务中,传统的CNN的分辨率通常会随着网络的深度逐渐变小,这样在top层特征图就会有一个很大的感受野和丰富的语义信息,从而可以更好的encode输入图像,完成分类。但是对于像检测这样同时需要分类和定位的任务来说,这样的网络结构是不是还是最佳的呢?答案是否定的,直接使用顶层的特征图做检测发现小物体检测的精度很低,这是因为在不断下采样的过程中丢失了大量的细节信息,即使通过top-down path(decode)也无法完全恢复,导致检测的性能下降很严重。于是这篇论文提出了SpineNet,,将编码器和解码器合二为一构建了尺度可变的backbone,这个backbone同时具备之前提到的编码器和解码器功能,因此也是直接连在分类和回归网络上的。而这个尺度可变的backbone具备两个特点:首先,中间特征图的分辨率能够随时增加或减少,这样模型可以随着深度的增加而保留空间信息;其次,特征图之间能够跨越特征尺度连接,以促进多尺度特征融合。下图显示了SpineNet和传统CNN之间的结构区别:
1. Method
作者提出的backbone是一个固定的steam network后面跟着learned scale-permuted network。其中steam network是分辨率之间降低的网络(传统意义上的CNN),并且在steam network这部分的blocks可以用作后续的scale-permuted network的输入。实际上这篇文章要搜的就是后面的scale-permuted network。
一个scale-permuted网络是由一系列构建块  组成,每个block
组成,每个block  多对应一个用来描述分辨率大小的特征等级
多对应一个用来描述分辨率大小的特征等级  , 等级对应的块中特征图大小为网络输入分辨率的
, 等级对应的块中特征图大小为网络输入分辨率的  ,同个块中所有层的特征图大小一样。受到NAS-FPN的启发,作者定义了5个“输出块”(等级从
,同个块中所有层的特征图大小一样。受到NAS-FPN的启发,作者定义了5个“输出块”(等级从  ),scale-permuted中的剩余块称为“中间块”。网络结构搜索时先搜索这N个块的排列顺序,再搜索它们之间的连接方式,最后进一步通过调整模块的属性来提高性能。
),scale-permuted中的剩余块称为“中间块”。网络结构搜索时先搜索这N个块的排列顺序,再搜索它们之间的连接方式,最后进一步通过调整模块的属性来提高性能。
1.1 Search Space
Scale permutations:这N个块的相对顺序是很重要的,因为一个块只能接受两个输入,而且它的输入都来自它之前的块。所以总共有  中可能的排序。块的排列顺序是首先要确定好的。
中可能的排序。块的排列顺序是首先要确定好的。
Cross-scale connections:每个块可以从之前块(包括steam network中的块)中接受两个输入。当融合不同分辨率的两个输入时需要做resamping spatial and feature dimensions操作(后面会细说),这个搜索空间大小为  ,这里的m是steam network中候选块的数量。
,这里的m是steam network中候选块的数量。
Block adjustments:作者允许进一步增大了搜索空间,每一个块的种类可以从{bottleneck block,residual block}中任意选择,同时中间块也可以调整自己的等级(在自己的等级上加{-1, 0, 1, 2}中的任意一个)。
1.2 Resampling in Cross-scale Connections
融合特征的一个重大挑战就是parent(有两个,代表模块的输入)和target模块之间的分辨率和通道数可能不同,所以需要做一些调整,操作示意图如Figure 4。这篇论文引入了比例因子α(默认为0.5)将通道数C调整为α×C(降低计算量)。然后再使用最近邻插值进行上采样或进行stride为2的卷积用于下采样特征图以匹配目标特征图分辨率。最后,再应用1×1卷积将输入特征图的通道数α×C与目标特征图的通道数相匹配,如下图所示:
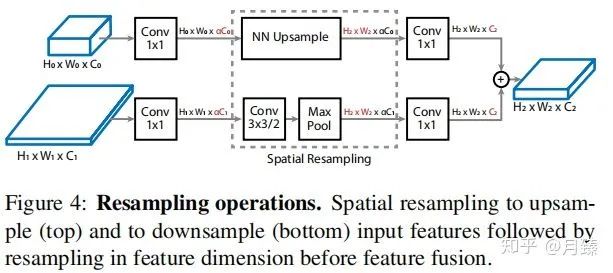
1.3 Scale-Permuted Model by Permuting ResNet
现在考虑一个问题如何排列ResNet网络的块结构来构造一个scale-permuted模型。由于连接块的操作Resampling in Cross-scale Connections的计算量可以忽略,所以比较是公平的。原始的ResNet-50仅含有4种尺度  ,第6和第7种尺度是如何产生的呢?w 我认为这里是将一个
,第6和第7种尺度是如何产生的呢?w 我认为这里是将一个  模块替换为一个
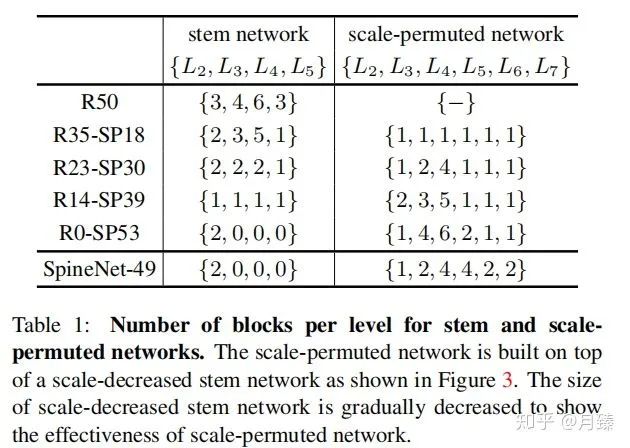
模块替换为一个  , 同时这三个等级的模块特征通道数都是256。table 1展示了搜索出来的一族模型的构建块的对比数量,R[N]-SP[M]代表在手工构造网络中有N个特征层,scale-permuted网络中有M个特征层。
, 同时这三个等级的模块特征通道数都是256。table 1展示了搜索出来的一族模型的构建块的对比数量,R[N]-SP[M]代表在手工构造网络中有N个特征层,scale-permuted网络中有M个特征层。
1.4 SpineNet Architectures
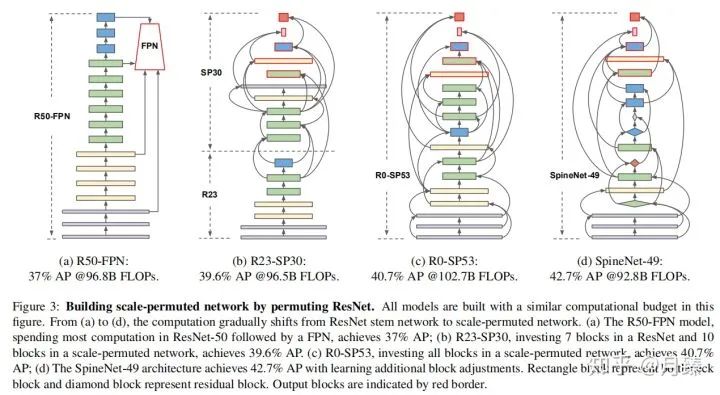
如上图所示,其中有红色边框的块看作是输出块,按照论文描述每个特征图都应该只有两个输入,但是图中可以看到一些输出特征图是有三个输入的,这是因为采用了和NAS-FPN一样的做法,即如果feature blocks不连接到更高顺序的任何中间feature blocks,则将它们连接到相应级别的输出feature blocks。
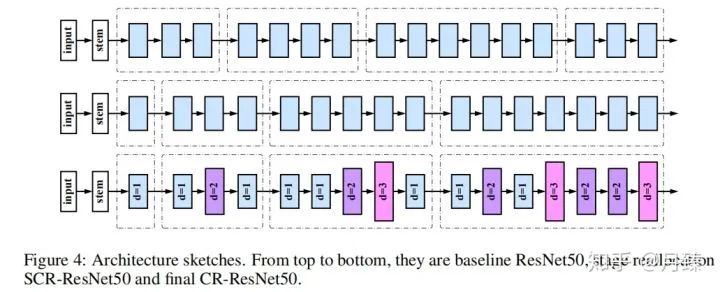
考虑到ResNet-50可能并不是最佳的基础网络,所以作者又添加了feature blocks自身的尺度以及block类型调整的搜索空间,最终得到上图(d)的结果,这也能进一步带来精度的提升。而在SpineNet-49的基础上,作者又构建了一些扩展的网络结构 SpineNet-49s/49/96/143。其中SpineNet-49s是将整个网络的特征通道数统一用0.75缩放,SpineNet-96是将每个块 重复堆叠两次,  连接原始 的两个输入,
连接原始 的两个输入,  连接输出目标块,SpineNet-143是将每个块重复堆叠三次,同时resampling操作时的
连接输出目标块,SpineNet-143是将每个块重复堆叠三次,同时resampling操作时的  。Figure 5展示了通过重复块增加网络深度的例子。
。Figure 5展示了通过重复块增加网络深度的例子。

2. 实验
NAS细节:和[1]中一样,训练一个RNN控制器来搜索网络结构,为了加速搜索,设计了一个代理SpineNet(SpineNet-49的特征通道数缩放为原来的0.25,resampling时的  ,box/class网络中的特征通道数为64),每次采样到的结构训练5个epoch得到的精度作为reward。
,box/class网络中的特征通道数为64),每次采样到的结构训练5个epoch得到的精度作为reward。

Ablation Studies
Importance of Scale Permutation:选取了两种固定块排列顺序的结构(Hourglass和Fish)与R0-SP53对比,结果如下:
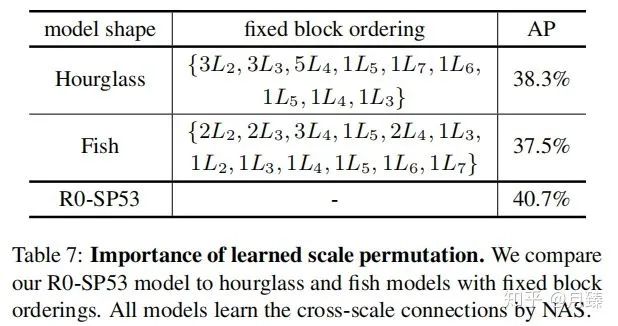
结果表明联合优化块排列和连接关系得到的结果要比使用固定结构只优化连接关系得到性能好。
Importance of Cross-scale Connections:cross-scale的连接拓扑结构在融合不同分辨率的特征中扮演着重要角色,接下来作者对拓扑结构做一些破坏,以R0-Spine53为例,主要的破坏方式有三种:(1)一处最短范围的连接(2)移除最长的连接(3)移除所有的连接,顺序连接各个模块。结果如table 8所示,任何一种破坏都会损失网络性能。

四. CR-NAS
这篇文章来自商汤ICRL 2020[6],其motivation就是在检测中,通常是将分类网络直接拿来做backbone的,但其实这是不合适的。作者分析了这个Gap的可能的一大原因是两个任务的data相差太大。对分类而言,ImageNet输入大小是224*224,但是对于检测而言,拿COCO为例,输入可能到800*1333,而且还需要去handle各个尺度的物体。那么我们如何才能设计(搜索)一个适合于检测的backbone呢?
作者写了一个对论文的介绍,详情可见:ICLR2020|商汤提出新目标检测NAS方法:算力重分配(CRNAS) - 云+社区 - 腾讯云
1. Two-level Architecture Search Space
作者提出了CR-NAS,先对不同分辨率的stage进行重新分配,然后在空间位置上对卷积的空洞因子进行重新分配。
1.1 Stage Reallocation Space
假设一个backbone在不断下采样的过程中产生四种尺度的特征——  ,可以视作四个stage,同个stage中的block分辨率相同,由于网络设计中遵循分辨率减半的同时channel数加倍,所以不同stage中每个block的计算量也是相等的,于是就有了一个思路,能不能对每种stage的block数量中心分配,只要总数不变,网络整体上的计算量就是相同的。
,可以视作四个stage,同个stage中的block分辨率相同,由于网络设计中遵循分辨率减半的同时channel数加倍,所以不同stage中每个block的计算量也是相等的,于是就有了一个思路,能不能对每种stage的block数量中心分配,只要总数不变,网络整体上的计算量就是相同的。
实际中往往需要针对不同的计算预算学习不同的stage reallocation,不同的应用需要不同size的模型。所以作者设计了一个搜索空间可以覆盖各种候选情况。以ResNet系列为例,设计第一个和第二个stage的block数量选择范围为  ,第三个stage为
,第三个stage为  ,第四个stage为
,第四个stage为  。
。
1.2 Convolution Reallocation Space
空洞卷积是通过对卷积位置进行稀疏采样来影响有效感受野的,它的另外一个好处就是没有增加额外的参数和计算量(我觉得增加了)。由于第一步我们已经对stage的重新分配进行了搜索,也就是各个stage的block数量已经确定了,所以在这里只需要针对每个块搜索出它的空洞率(1,2,3)。
1.3 Stage Reallocation Search
先训练一个包含所有block选择的supernet,然后采样子结构  并直接在目标检测任务上进行评估,设定block总数的约束为N,可以发现最好的分配策略为:
并直接在目标检测任务上进行评估,设定block总数的约束为N,可以发现最好的分配策略为:
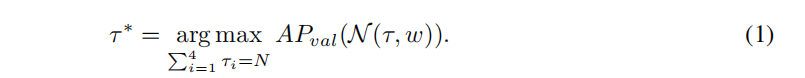
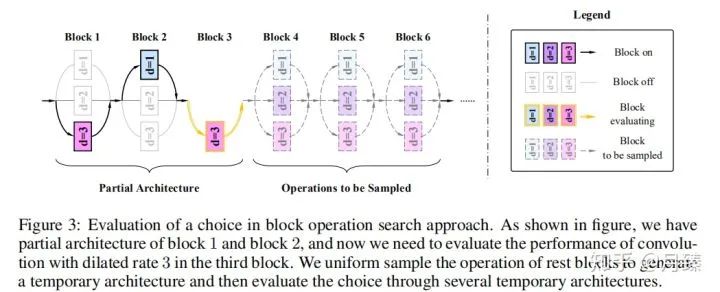
1.4 Block Operation Search
在1.3中为每个stage选择了确定的block数量后,网络的结构也就确定了,接下来就是对每个块中的卷积层的空洞率进行微调。假如有16个块,每个块的空洞率可以在 {1, 2, 3} 之间选择,作者先训练一个包含所有选择的supernet,然后通过搜索得到最佳的选择,搜索空间大小为  ,为了进一步减小搜索成本。作者选择贪心搜索算法。
,为了进一步减小搜索成本。作者选择贪心搜索算法。
具体来讲,就是先将网络结构 o看作一系列选择  。从第一块开始遍历,每次保留前K=3个最佳结构;对于第一个块,由于空洞率可以有三种选择,所以要训练评估三次,当空洞率为1时,对后面的blocks的空洞率随机采样,采样5000个结构,然后选择5000张图片评估一次,作为空洞率=1时的评估结构,这样对于第一个块前三个最佳结构分别对应空洞率等于1,2,3;对于第二个块,由于第一块有三个选择,那么就有进行9次评估了,从中选择最佳的三个结果......依次遍历完所有的块,然后从最佳的K个结构中选择最好的那个作为最终的选择。伪代码如下:
。从第一块开始遍历,每次保留前K=3个最佳结构;对于第一个块,由于空洞率可以有三种选择,所以要训练评估三次,当空洞率为1时,对后面的blocks的空洞率随机采样,采样5000个结构,然后选择5000张图片评估一次,作为空洞率=1时的评估结构,这样对于第一个块前三个最佳结构分别对应空洞率等于1,2,3;对于第二个块,由于第一块有三个选择,那么就有进行9次评估了,从中选择最佳的三个结果......依次遍历完所有的块,然后从最佳的K个结构中选择最好的那个作为最终的选择。伪代码如下:

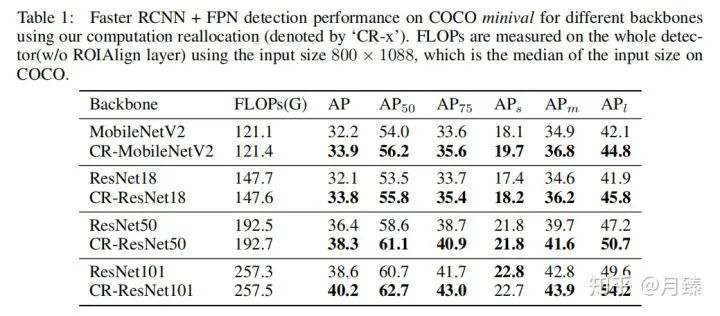
实验结果:
参考文献
推荐阅读