
Pandas 数据分析第 六 集
三步加星标
你好,我是 zhenguo
Pandas 使用技巧最近连载 5 篇,是时候分析一下它的基本框架。Pandas 使用行索引和列标签表达和分析数据,分别对应 axis=0, axis=1,行索引、列标签带来一些便捷的功能。
如果玩Pandas,还没有注意到对齐 alignment,这个特性,那该好好看看接下来的分析。
基于行索引的对齐,与基于列标签的对齐,原理是一致的,它们其实相当于字典的 key,起到对齐数据作用。但是,这种说法抽象了些,没有例子不好想象出对齐的作用。
下面使用前几天推荐你的 9 个小而经典的数据集,里的 google app store 这个小而经典的数据集,重点分析“行对齐”功能,理解它后,列对齐也自然理解。
导入包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
版本号:
print(pd.__version__)
print(np.__version__)
print(sns.__version__)
1.0.1
1.18.1
0.11.0
导入数据:
df = pd.read_csv('kaggle-data/googleplaystore.csv')
df.head(3)

rank = df_normal.Rating.rank(method='min',na_option='bottom',ascending=False)
rank.head(3)
method 参数指定:Rating 值相等时排名取小,na_option 指定空值排到最后,ascending 指定倒序
将上面得到的新列 rank 插入 df_normal 中:
df_normal.insert(2,'rank', rank, allow_duplicates=True)
df_normal.head(3)
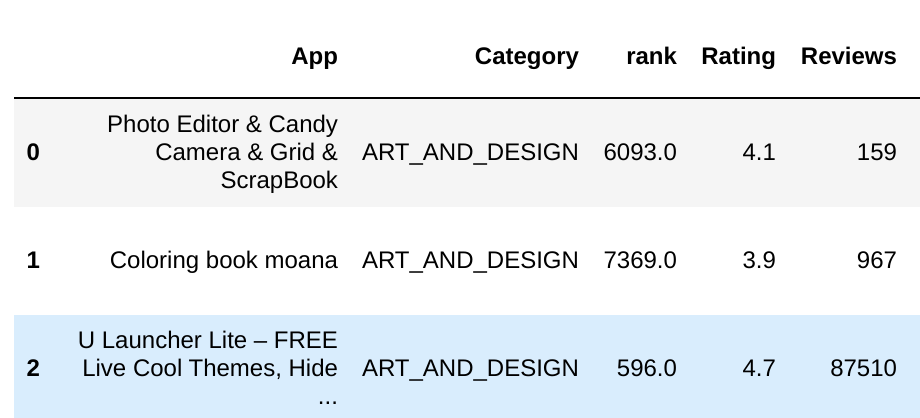
因为 df_normal 和 rank 的行索引 index 都是从0 开始的自增,所以即便没有自动对齐,也是准确的:

### 根据 Reviews 次数从少到多排序
df_by_reviews = df_normal.sort_values(by='Reviews')
df_by_reviews.head(3)

得到 df_by_reviews ,注意它的 index 不是按照从0自增
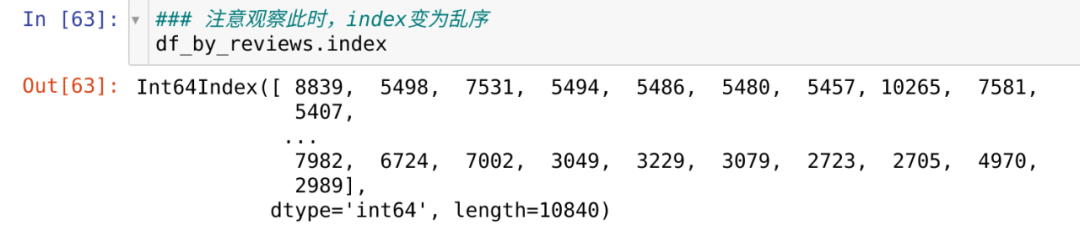
此时在 df_by_reviews 中,插入 rank 还能确保数据对齐吗
### 此时插入排名 rank 列,数据会自动对其
df_by_reviews.insert(3,'rank_copy',rank)
df_by_reviews.head()
看到 rank 列 和 rank_copy 列相等,通过下面一行代码验证出来:
### 如果后者index序列中某些值没有出现在df_by_reviews的index中
### 举个例子
df_test = pd.DataFrame({'a':[1,4,7],'b':[5,2,1]},index=[4,3,1])
ser = pd.Series(index=[3,2,1],data=[0,9,8])

评论