
MCN 服装穿搭评价模型 | 附源码
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
Outfit Compatibility Prediction and Diagnosis with Multi-Layered Comparison Network
论文题目:Outfit Compatibility Prediction and Diagnosis with Multi-Layered Comparison Network
论文地址:https://arxiv.org/abs/1907.11496
代码:https://github.com/WangXin93/fashion_compatibility_mcn

简介
本文基于一个多层比较网络(Multi-Layered Comparison Network,MCN) 实现搭配匹配预测和诊断,并实现一个端到端的框架。主要贡献如下:
通过采用梯度值来近似输入商品的相似度实现对搭配的诊断,可以给出搭配中哪件商品最不不合适,并可以通过替换该商品来提高搭配的评价得分; 利用CNN 的不同层的特征进行商品之间两两对比,得到一个相似度矩阵,然后再通过两层全连接层来输出搭配的评价得分;CNN的不同层特征可以解释为不同级别的语义信息,从低级的颜色、纹理到高级的风格等信息; 对 Polyvore 进行处理,得到一个更加干净的数据集 Polyvore-T,并对类别进行归纳得到新的 5 大类型--上装、下装、鞋子、包和首饰(Top、Bottom、Shoe、Bag、Accessory)
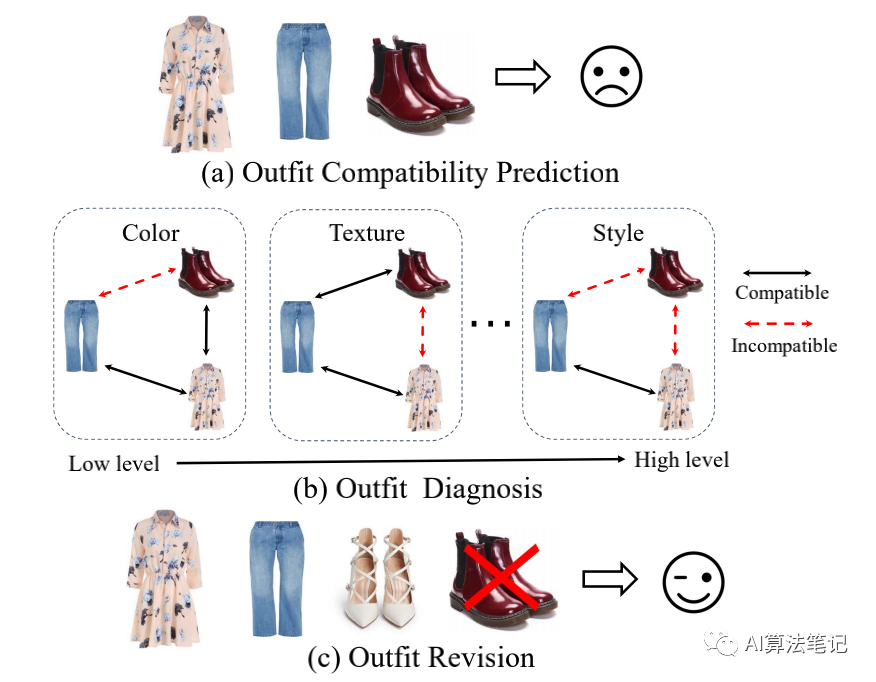
本文的应用可以如下所示,主要分为三方面的应用:
判断搭配好坏,也可以对搭配进行评分; 对搭配进行诊断,判断需要替换哪件商品; 根据 2 的诊断结果,从数据集选择合适的同类别商品进行替换。
背景
1. 时尚商品识别和理解
时尚商品识别是实现搭配匹配性的第一步,也是非常关键的步骤。
《DeepFashion》[7]论文建立了一个时尚商品数据集--DeepFashion,并采用CNN学习商品的类别、属性和位置信息;
一些相关的方法分别从有监督、无监督,加入文本信息、搭配之间的关联信息等方面来提高对商品的识别精度。
2. 视觉匹配性学习
搭配的匹配性是非常主观的审美标准,但目前也存在不少搭配相关的网站,比如 Polyvore 数据集(也是目前搭配领域非常常用的数据集)。
之前对于搭配匹配性的学习方法主要分为两个方向:
学习一对商品的匹配性 采用端到端方法学习搭配的匹配性
对于一对商品的匹配性,可以通过计算商品的特征的欧式距离,但最近的学者认为搭配匹配性并不像检索任务一样严格,并不太适用欧式距离来学习,于是就有很多工作是尝试采用其他的 metric learning 方法来学习。但这个方向的问题是没有考虑到整体搭配的匹配性和两两商品的匹配性之间的关系。
对于第二个采用端到端方法,则可以学习多种商品的特征,然后利用 MLP 来计算搭配的匹配性得分。但 MLP 并不是一个有效的学习每个商品间关系的方法。也有工作采用 LSTM 进行学习,但搭配更类似集合,而不是序列,因为它是无序的。
方法
MCN 整体流程如下所示:
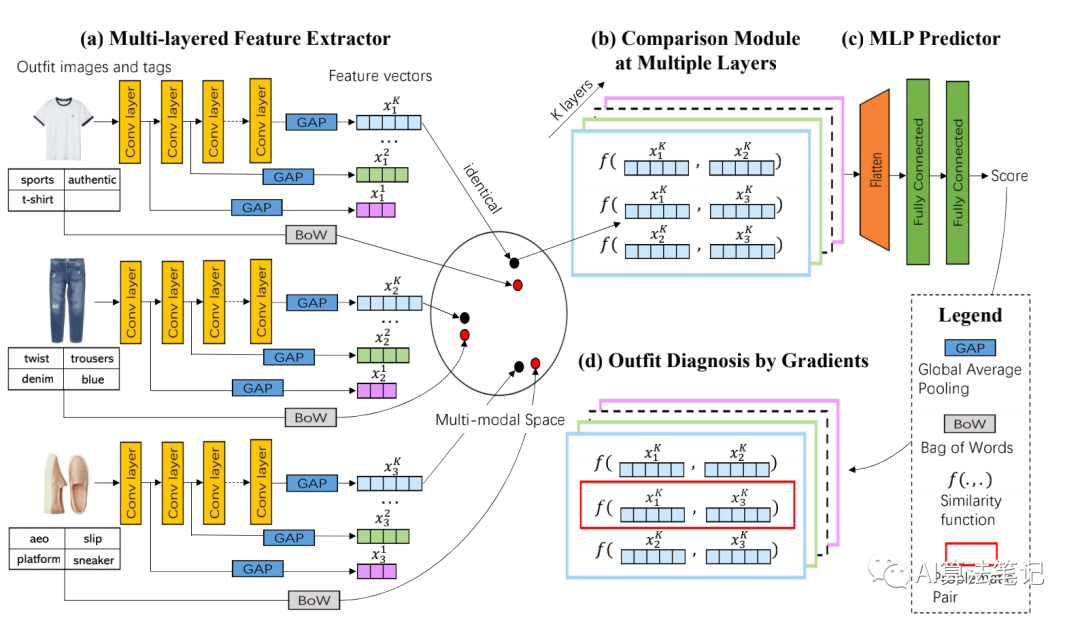
从上图可以知道,MCN 总共分为四大部分,分别如下:
Multi-layered Feature Extractor Comparisons at Different Layers Predictor Outfit Diagnosis by Gradients
其中第四部分是对搭配进行诊断,训练模型阶段仅包含前三个部分。下面会分别介绍这几部分内容:
1. Outfit Diagnosis by Gradients
整体搭配的匹配性是综合考虑了商品之间两两在不同方面,比如颜色、纹理、风格等,进行对比后的结果。一般要学习整体匹配性和成对商品相似度的关系,可以考虑两种方法:
线性模型
优点:有很好的解释性,输入的权重就表明其输出的重要性程度;缺点:受限的容量
多层感知器(MLP)
优点:有更好的容量
缺点:可解释行差
结合两者的优点,所以本文是采用梯度来近似每对商品的相似度的重要程度,从而找出不合适的商品。
首先给出商品之间的相似度矩阵 R,其公式如下所示,具体的计算方法将在下一节介绍。

R 矩阵中每个数值都是两个商品在不同特征的相似度,因为本文采用了 CNN 的四层输出特征,所以 R 矩阵是有四个,也就是 K = 4,K 表示商品对比的不同方面,其大小 ,N 是搭配中商品的个数,而本文的 N = 5,设置了搭配的商品数量上限是 5 件,因此 R 矩阵的大小是 。
当然这里在代码实现的时候,并不需要存储 5*5 = 25 个数值,而是仅需要 15 个数值,这是剔除重复的元素。
在获得相似性矩阵 R 后,就会将这个矩阵传到 2 层的 MLP,即两个全连接层,这里 R 矩阵的维度就是 (batch, 15*4)。通过两层 MLP 输出搭配的匹配得分,公式如下所示:

这里使用了非线性激活函数 ReLU,即 R 和最终搭配得分 s 之间是一个非线性关系,这有助于提高搭配匹配判断的性能,但并不好解释做出这个搭配匹配判断结果的原因,因此采用的就是上述说的梯度值。
具体来说,对搭配评价得分 s 采用一阶泰勒展开式,可以得到:
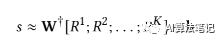
这个近似公式就是一个线性模型(wx+b的形式),这里的权重 W 就可以用于表示相似度矩阵的重要程度,也就是每对商品的相似性的重要性,而 W 的元素是等于 s 对每个 R 的导数,即:
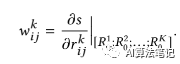
假如不匹配的搭配的标签是 1,上述公式里的 w 就表示为第 i 个商品和第 j 个商品在第 k 种特征方面的相似程度对整体搭配不匹配的影响程度,数值越大自然表示影响越大了。
如果是单个商品的重要程度,可以对包含该商品的梯度进行求和,这里是计算了第 q 个商品的重要程度:
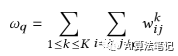
训练过程,对于输出层的激活函数采用 Sigmoid 函数,而损失函数采用二值交叉熵:
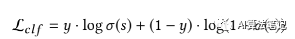
2. Comparisons with Projected Embedding
上一节是整体介绍了 MCN 如何判断搭配的评价,以及对搭配的诊断,至于替换商品其实就是在数据集选择商品替换当前搭配,然后计算搭配的得分,判断是否符合阈值(比如评价得分大于0.9就停止搜索,采用当前替换的商品)。这里可以发现最重要的就是如何计算两个商品的相似度矩阵。
一个比较简单的方法的就是采用余弦相似性来计算相同空间中特征的距离。但这有几个缺点:
匹配性的变化会被压缩。比如和同一个衬衫很匹配的所有裤子都被强制拉近距离,但这些裤子并非都很相似; 三角形不等式会限制每个 embedding 的位置。比如存在这种情况,一条裤子和一件衬衫很匹配,然后裤子和一个鞋子又很匹配,那么这个鞋子也会强制靠近这件衬衫,使得它们是匹配的。
为了避免上述问题,这里参考了论文**[1, 2],采用不同服饰类型集合的投影变量(projected embedding)**来处理这个问题。
一套搭配通常是包含不同类型的商品,比如上衣、下装、鞋子等等,不同对类型的集合可以作为一个条件,用于将 embedding 投影到不同的子空间,这里定义:
然后投影过程的计算如下所示

其中 P 表示投影,这里的距离 d 采用余弦相似性。实现如下所示:
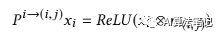
其中,m 是一个可学习的 mask 向量,它的作用就是一个像素元素的门函数,在不同的匹配性条件下,挑选相关的像素元素,这里参考**[3]**,添加两个损失函数,如下所示,Lmask是让 masks 变得更加稀疏,而 Lemb 则是鼓励 CNN 在隐式空间中编码归一化的特征表示,因此前者采用 L1 正则,后者是 L2 正则方法。

3. Multi-Layered Representation
对商品的特征表示也是非常关键的,不仅可以更好对搭配进行诊断,判断哪件商品不合适,也有助于搭配匹配性的预测。
一种构建不同特征表示的方法,就是预定义一些特征,比如颜色、纹理和形状等等,但这种做法可能不能完全表示时尚商品的特征。
另一种做法就是利用 CNN 的特征,对于CNN的不同网络层可以捕捉图像的不同特征,浅层的通常是捕捉到低级特征,比如颜色、纹理,而深层的可以获取高级的特征,包括商品风格和匹配性等。
因此,本文采用 CNN 的不同网络层的输出特征作为商品的特征表示,具体来说,就是指定网络层的输出会再连接一个全局平均池化(global average pooling, GAP)层来将网络层的特征图变为向量表示。
GAP的两大作用:
将网络层的特征图转换为向量,满足计算余弦相似性 ; 包括颜色、纹理等特征是和位置没有相关性的,GAP 可以有效丢弃空间信息
因此,采用 K 层的特征图就可以得到 K 个相似度矩阵 R。在本文中,基础网络模型采用 ResNet-50,然后 K=4。
4. Visual Semantic Embedding
现实生活中,商品通常都有多种描述信息,包括图像、文字等。Visual Semantic Embedding(VSE)[4]就是一种可以很好利用这些不同形式的信息的方法,参考[5,6],只需要给这些信息设计一个表达式。
在Polyvore 数据集中,每个商品都有一个文字的描述,如"classic skinny jeans",文字信息可以采用如下符号进行表示:
w_i 表示的就是第 i 个单词,并且可以表示为一个 one-hot 向量 e_i,然后 e_i 的词向量(word embedding)如下表示:
W_T 表示词向量的权重
一套搭配的语义向量(semantic embedding)如下表示:
对于视觉特征 x,也是有相似的处理过程,得到一个视觉向量,如下表示
所以,VSE 的目标就是让同一个商品的 v 和 u 两个语义向量在联合空间中的距离减小,因此这里采用的是**对比损失(contrastive loss),**公式如下所示:

这里 d(u,v) 表示的就是两个向量的距离。然后对于来自同个商品的 u 和 v,v_k 表示所有其他不匹配商品的语义向量,而 u_k 表示其他所有不匹配的商品的视觉向量。因此上述损失函数是期望所有匹配的 u 和 k 的距离要小于不匹配的情况(也就是公式中 u 和 v_k 或者 u_k 和 v 这两种情况),并且设置一个间距 m。
在实际训练中,可以采用一个 mini-batch 作为搜索所有 u_k 和 v_k 的集合。
最后,整体的损失函数如下所示:

实验
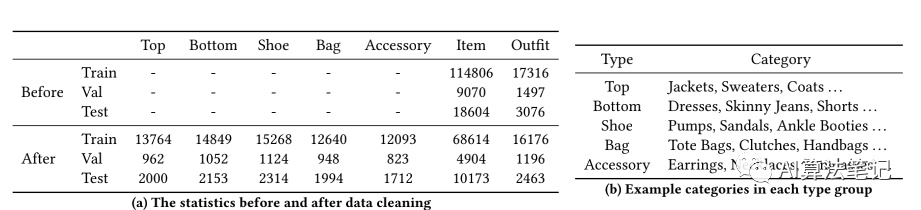
1. Polyvore-T 数据集
论文采用的 Polyvore 数据集,原始数据集有 21899 套搭配,但原始数据集存在这几个问题:
给的类别会有重叠的,比如 "shoulder bags" 和 "bags" 有些类别数量太少,不足以进行训练
因此将总共 381 个类别通过下述方法分成 5 个大类:
不相关的类别,包括镜子等都被删除,只保留 158 个类别; 手动将剩余的类别分为 5 个类别--Top、Bottom、Shoe、Bag和Accessory 删除不在指定类别的商品,并对剩余商品根据指定的标签进行分类
具体统计信息如下表所示:
2. 实验
实验设置
采用预训练模型的 ResNet-50 输入图片大小是 224*224 搭配的商品数量是 3-5件,不足5件的会采用缺少的类别的平均图 在计算完相似度矩阵后,添加一个 BN 层 batch = 32 训练epochs=50 采用 SGD,初始学习率0.01 损失函数的三个权重分为是 5e-3, 5e-4 和 1
负样本
正样本就是polyvore数据集中的原始搭配,而负样本是通过对正样本的每个商品,随机从其他搭配中挑选相同类别的商品替换。
主要也是因为现实生活很少会有专门设计糟糕的搭配;此外,对于 Polyvore网站,相信专家都是根据不同美学规则来进行组合商品得到搭配,因此随机组合的搭配很大概率是不好的。
实验结果
主要是两个实验,如下图所示
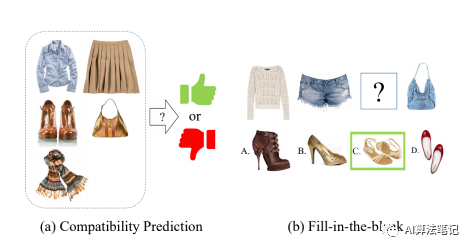
搭配匹配性预测(Compatibility Prediction):给定一套搭配,计算整套搭配的得分,并判断搭配的好坏。如下图a所示 补充搭配(Fill-in-the-blank):对一套搭配,补充缺少的商品。如下图b所示,实验中会给定四个候补商品,测试模型四选一选择正确商品的准确率。
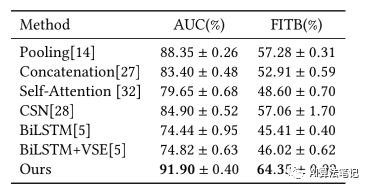
实验结果如下表所示,总共对比了 6 种其他的方法,本文方法在搭配匹配性预测任务和补充搭配任务都取得最好的性能,分别是91.9%和64.35%。
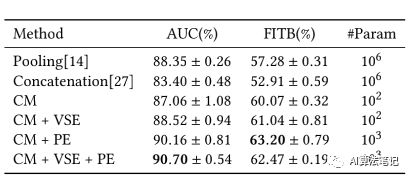
接着是分析 MCN 模型中四个模块对模型性能的影响,如下表所示,CM 表示采用相似度矩阵,VSE是采用视觉语义向量信息,PE是采用投影向量来计算商品间的相似度。
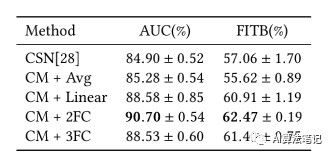
然后就是研究商品两两的相似度和整体匹配性的关系,实验如下表所示,实验结果表明采用两层FC的效果是最好的,也说明两者之间是一种非线性的关系。
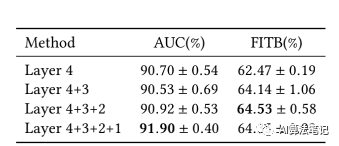
而下表则表明 CNN 不同层的输出特征都对模型的性能做出了贡献。
模型诊断的例子如下图所示,给出都是评分很差的搭配,红色框的商品是最需要替换的商品,然后分别给出每层特征计算的商品间相似度。

诊断接着进行替换商品,再经过模型输出得分,例子如下图所示,红色箭头表示更换前后的商品。

参考文献
下面是论文中部分的参考文献
【1】Hongxu Chen, Weiqing Wang, and Hao Wang. [n. d.]. PME : Projected Metric Embedding on Heterogeneous Networks for Link Prediction. ([n. d.]).
【2】Mariya I. Vasileva, Bryan A. Plummer, Krishna Dusad, Shreya Rajpal, Ranjitha Kumar, and David Forsyth. 2018. Learning Type-Aware Embeddings for Fashion Compatibility. (2018), 1–66. arXiv:1803.09196 http://arxiv.org/abs/1803.09196
【3】Andreas Veit, Serge Belongie, and Theofanis Karaletsos. 2017. Conditional similarity networks. Proceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017 2017-Janua (2017), 1781–1789. https://doi.org/10.1109/CVPR.2017.193 arXiv:1603.07810
【4】Ryan Kiros, Ruslan Salakhutdinov, and Richard S Zemel. [n. d.]. Unifying VisualSemantic Embeddings with Multimodal Neural Language Models arXiv : 1411 .2539v1 [ cs . LG ] 10 Nov 2014. ([n. d.]), 1–13. arXiv:arXiv:1411.2539v1
【5】Xintong Han, Zuxuan Wu, Yu-Gang Jiang, and Larry S. Davis. 2017. Learning Fashion Compatibility with Bidirectional LSTMs. Proceedings of the 2017 ACM on Multimedia Conference - MM ’17 1 (2017), 1078–1086. https://doi.org/10.1145/3123266.3123394 arXiv:1707.05691
【6】Takuma Nakamura and Ryosuke Goto. 2018. Outft Generation and Style Extraction via Bidirectional LSTM and Autoencoder. (2018).
【7】Deepfashion: Powering robust clothes recognition and retrieval with rich annotations.
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  ,告诉大家你也在看
,告诉大家你也在看