
Python如何画好看的 知识图谱!

来源 | Python爬虫数据分析挖掘
1
前言
最近想搞一点好玩的事情(技术),今天打算做一个小程序:一键查询明星个人信息。(从数据抓取到知识图谱展示,全程代码完成原创,不涉及调用api包)
思路:从爬取网页数据(某度百科),进行数据处理,最后通过知识图谱图进行展示。
最后会将代码开源放在文章末尾!
下面先看演示:
图片版
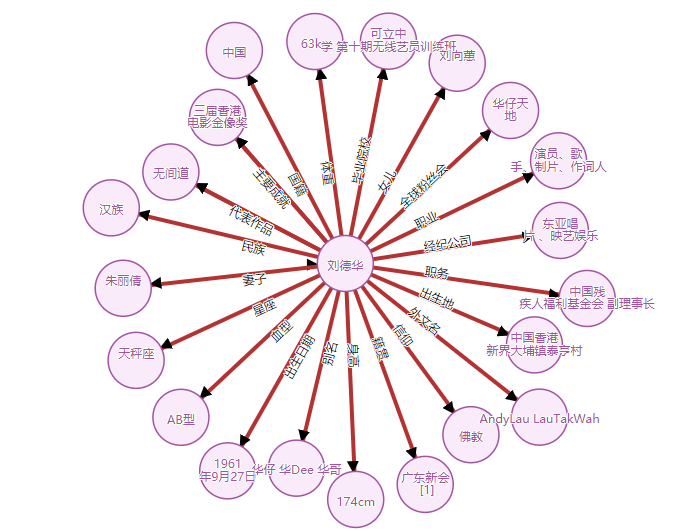
动图版
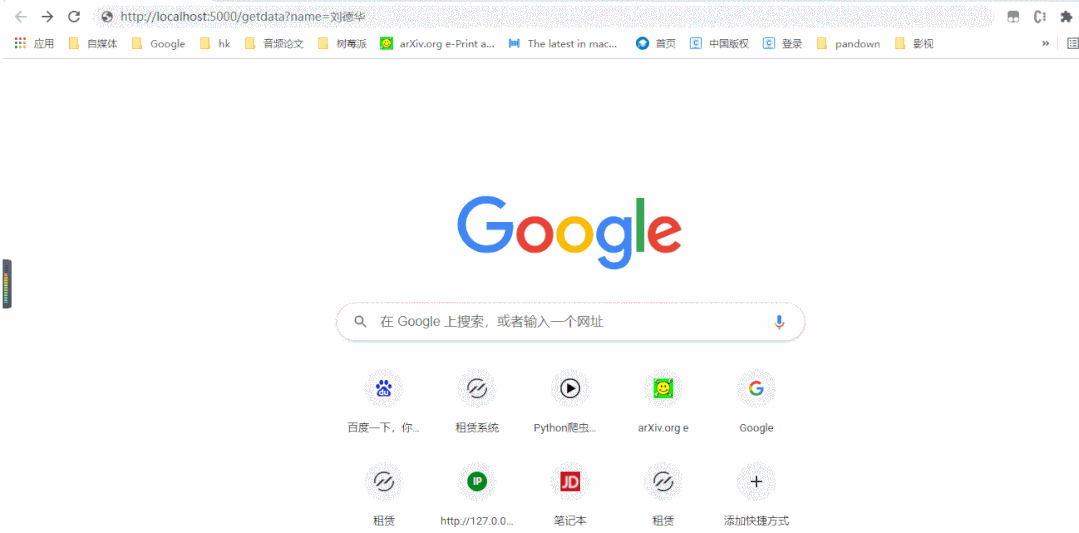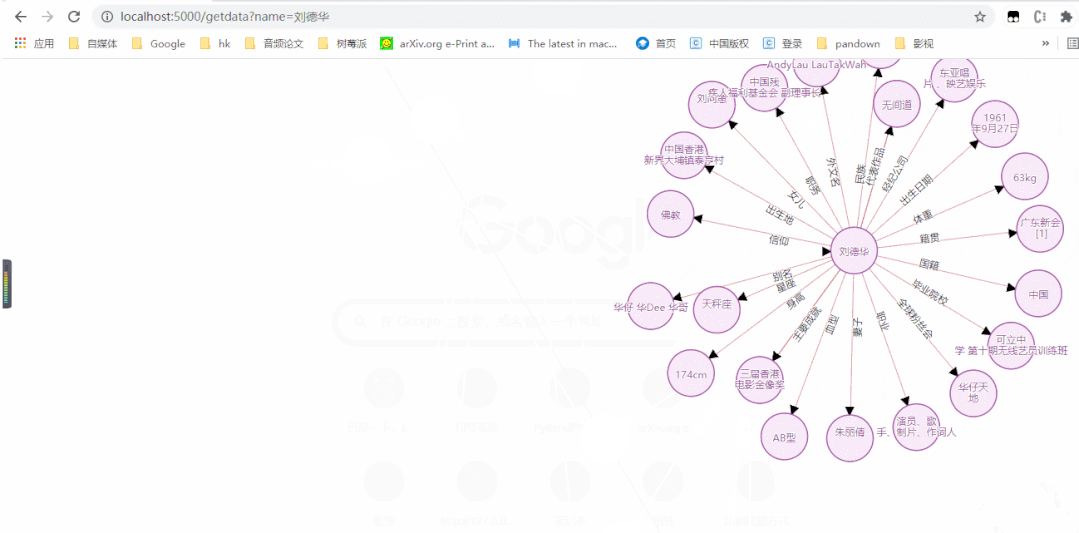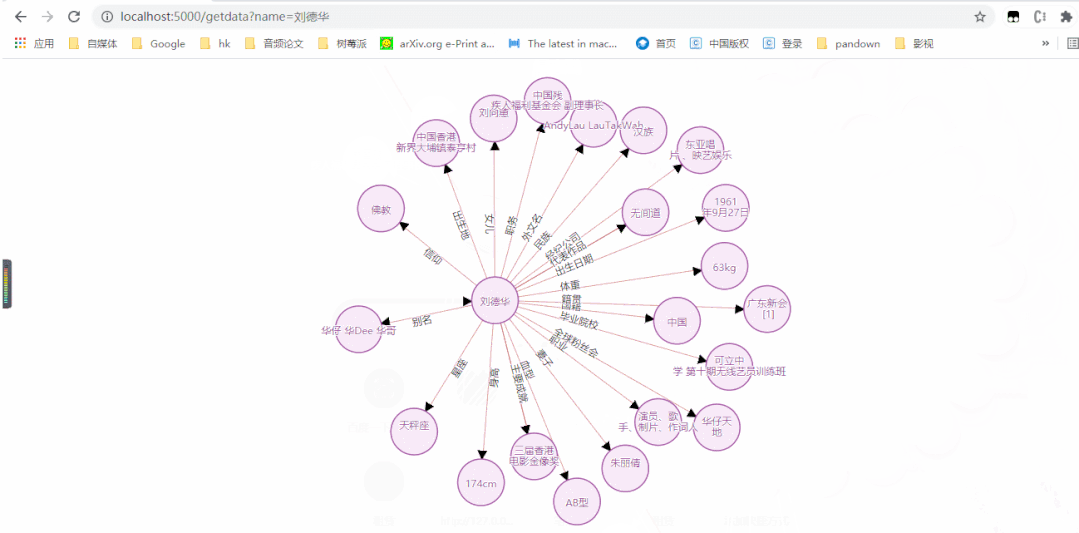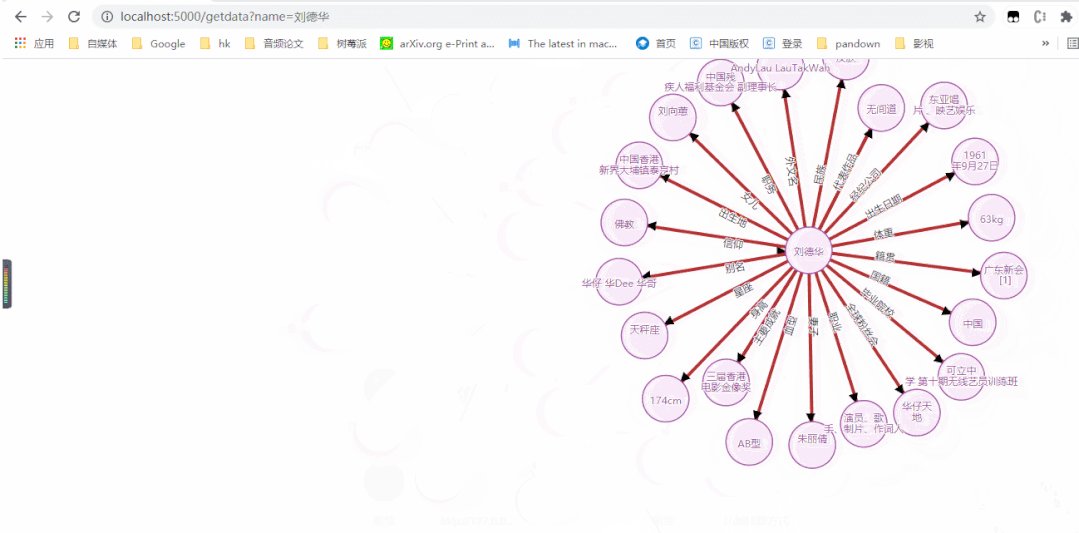
2
采集数据
1.分析链接
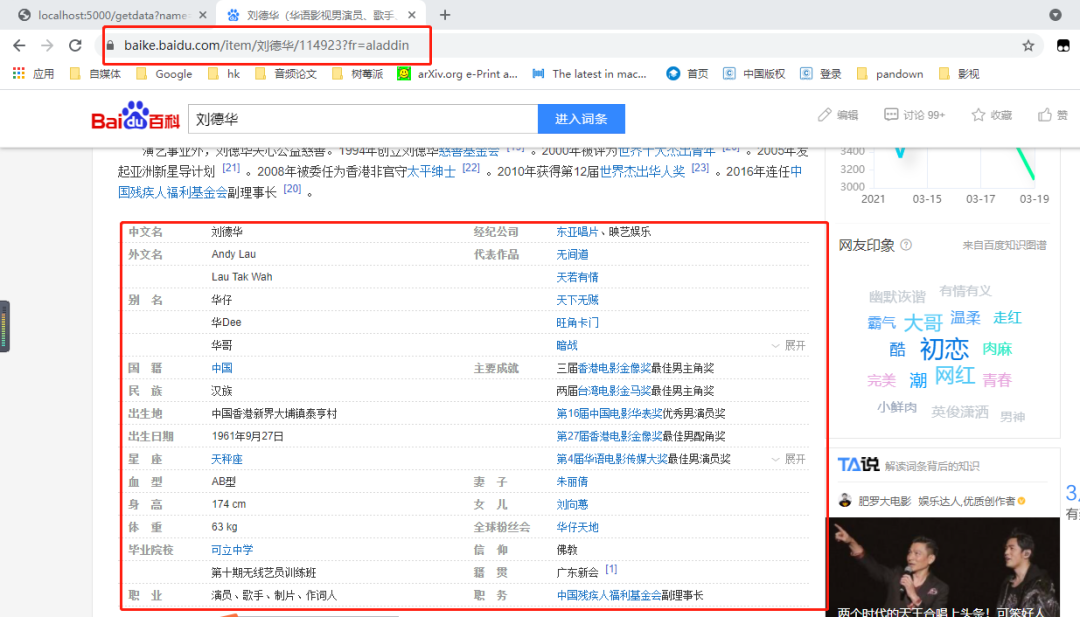
https://baike.baidu.com/item/刘德华/114923?fr=aladdin
链接上中有两个参数:
明星名字:刘德华
编号:114923
编号是通过另外一个链接获取(我们希望是直接输入明星名字就可以获取网页),因此我们需要去根据明星获取编号!
2.获取编号
url="https://baike.baidu.com/search/word?word=刘德华"
s = requests.Session()
response = s.get(url, headers=headers)
text = response.text
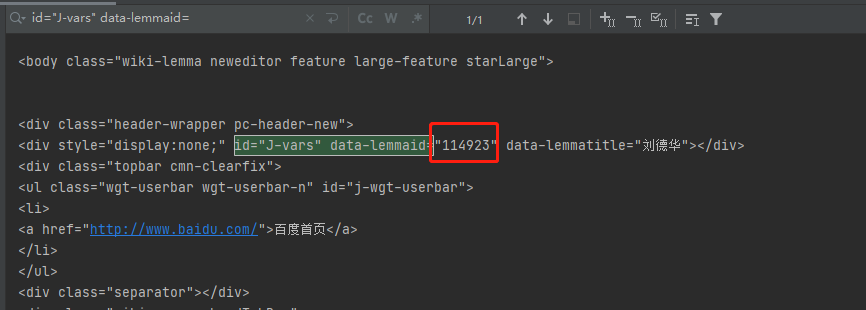
可以看到这个链接中获取的数据包含编号
t_split = text.split('id="J-vars" data-lemmaid="')[1].split('" data-lemmatitle="')[0]
print(text)
这样就可以获取到编号(根据明星名称就可以获取到编号)
3.解析网页数据
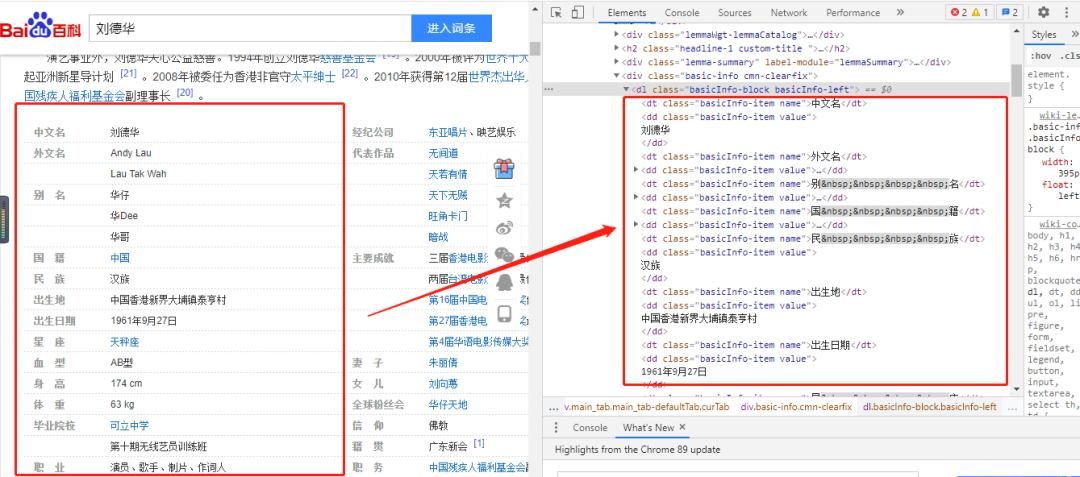
F12查看网页源代码,可以看到左边信息在class=basicInfo-block basicInfo-left,右边的信息在class=basicInfo-block basicInfo-right
其中属性在dt标签,值在dd标签。
basicInfo_left = selector.xpath('//*[@class="basicInfo-block basicInfo-left"]')[0]
dt.append(basicInfo_left.xpath('.//dt'))
dd.append(basicInfo_left.xpath('.//dd'))
basicInfo_right = selector.xpath('//*[@class="basicInfo-block basicInfo-right"]')[0]
dt.append(basicInfo_right.xpath('.//dt'))
dd.append(basicInfo_right.xpath('.//dd'))
代码部分:
url="https://baike.baidu.com/item/刘德华/114923?fr=aladdin"
res = requests.get(url,headers=headers)
res.encoding = 'utf-8'
text = res.text
selector = etree.HTML(text)
#属性
key = []
#值
value = []
dt =[]
dd =[]
basicInfo_left = selector.xpath('//*[@class="basicInfo-block basicInfo-left"]')[0]
dt.append(basicInfo_left.xpath('.//dt'))
dd.append(basicInfo_left.xpath('.//dd'))
basicInfo_right = selector.xpath('//*[@class="basicInfo-block basicInfo-right"]')[0]
dt.append(basicInfo_right.xpath('.//dt'))
dd.append(basicInfo_right.xpath('.//dd'))
for j in dt:
for i in j:
text = i.xpath('.//text()')
if len(text)==1:
text = text[0].replace(" ","").replace("\n","").replace("\xa0","")
else:
text = "-".join(text)
text = text.replace(" ", "").replace("\n", "").replace("\xa0", "")
key.append(text)
for j in dd:
for i in j:
text = i.xpath('.//text()')
if len(text) == 1:
text = text[0].replace(" ", "").replace("\n", "").replace("\xa0", "")
else:
text = "-".join(text)
text = text.replace(" ", "").replace("\n", "").replace("\xa0", "").replace("-", " ")
value.append(text)
for k in range(0,len(key)):
print(key[k]+":"+value[k])

3
处理数据
1.换行处理
爬取的文本中含有\xa0、换行\n、空格等,需要进行处理
text = i.xpath('.//text()')
if len(text)==1:
text = text[0].replace(" ","").replace("\n","").replace("\xa0","")
else:
text = "-".join(text)
text = text.replace(" ", "").replace("\n", "").replace("\xa0", "")2.多值处理

像代表作品,主要成就这些有很多值,为了方便绘制知识图谱图,保留其中一个值就可以。
if key[k]=="代表作品" or key[k]=="主要成就":
v = value[k].split(" ")
dict = {'source': str(name_i), 'target': str(v[0]+v[1]), 'rela': str(key[k]), 'type': 'resolved'}
links.append(dict)
else:
dict= {'source': str(name_i), 'target': str(value[k]), 'rela': str(key[k]), 'type': 'resolved'}
links.append(dict)
3.数据格式处理
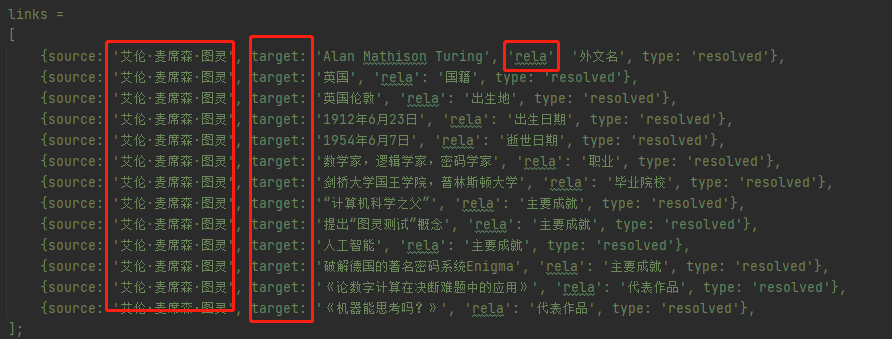
这个是知识图谱要求数据格式
source表示明星,比如刘德华
target表示value,比如中国
rela表示key,比如国籍
for k in range(0,len(key)):
if key[k]=="代表作品" or key[k]=="主要成就":
v = value[k].split(" ")
dict = {'source': str(name_i), 'target': str(v[0]+v[1]), 'rela': str(key[k]), 'type': 'resolved'}
links.append(dict)
else:
dict= {'source': str(name_i), 'target': str(value[k]), 'rela': str(key[k]), 'type': 'resolved'}
links.append(dict)
4
绘制知识图
1.后端部分
这里通过Flask框架来制作网页展示
#获取数据
@app.route('/getdata')
def getdata():
name_i = request.args.get('name')
# 采集数据
links = getlist(name_i)
#return Response(json.dumps(links), mimetype='application/json')
return render_template('index.html', linkss=json.dumps(links))
if __name__ == "__main__":
"""初始化"""
app.run(host=''+ip, port=5000,threaded=True)
其中的getlist,是爬虫代码封装的函数(完整代码下方获取)
用户访问一下链接,并传过来明星的名字
http://localhost:5000/getdata?name=刘德华
flask就调用爬虫程序getlist,获取到数据,然后携带数据linkss跳转到index.html,展示数据。
2.网页部分
var links=eval('{{linkss|safe }}');
var nodes = {};
links.forEach(function(link)
{
link.source = nodes[link.source] || (nodes[link.source] = {name: link.source});
link.target = nodes[link.target] || (nodes[link.target] = {name: link.target});
});
links接收到数据后,在进行forEach取出进行展示。
这里就只贴了修改改动的部分代码,其他的都是不需要改动,完整的html可以在下方获取。
3.效果
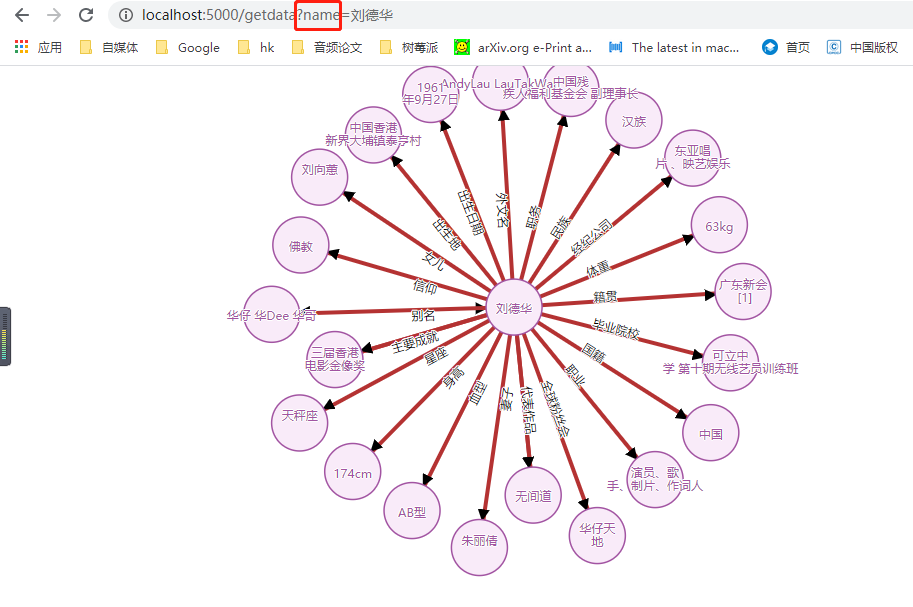
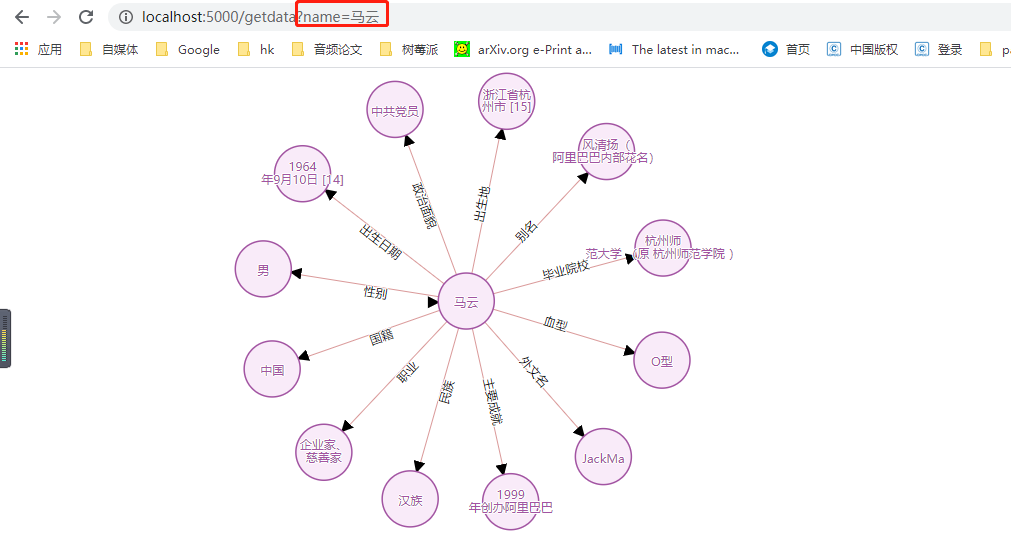
5
总结
1.教大家如何爬取某度百科,其中难点就是如何获取编号!
2.对爬取的数据进行相应的处理和格式转化!
3.Flask的简单使用(小白入门非常适用)。
4.可视化方面,如何制作知识结构图(知识图谱)。
5.本文全是干货(涉及爬虫、数据处理、Flask网页、知识结构图的绘制),推荐收藏!!!
6.源码:https://gitee.com/lyc96/star-visualization