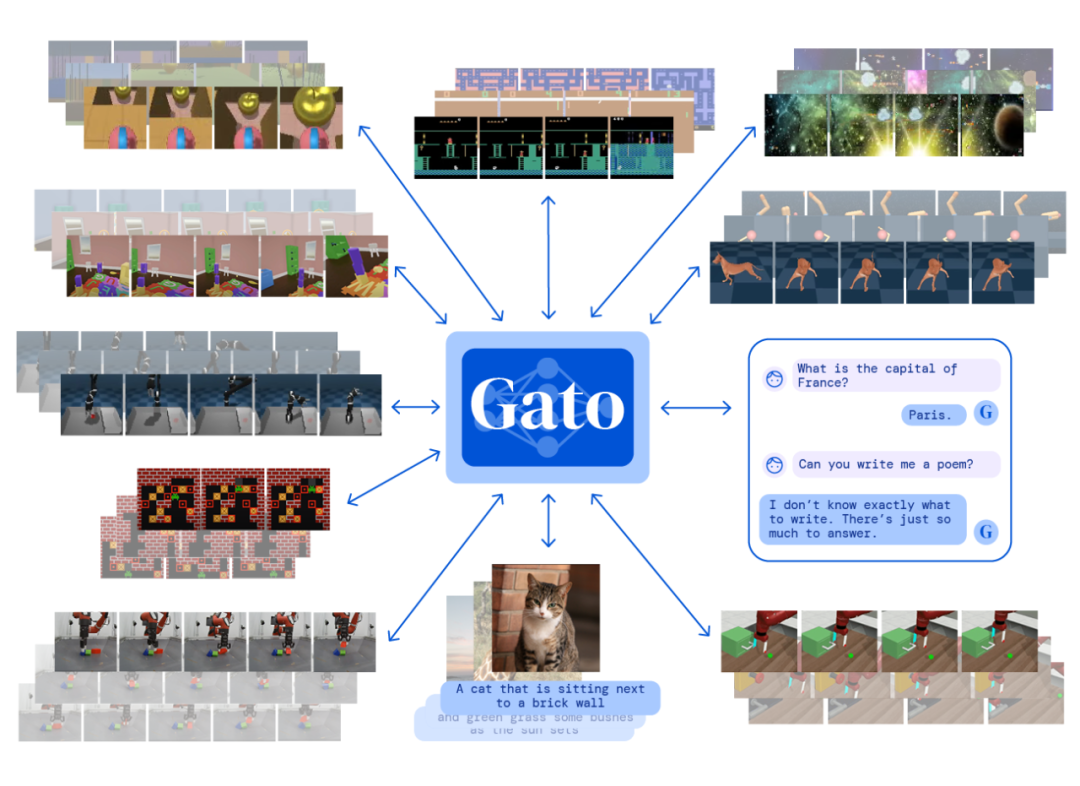
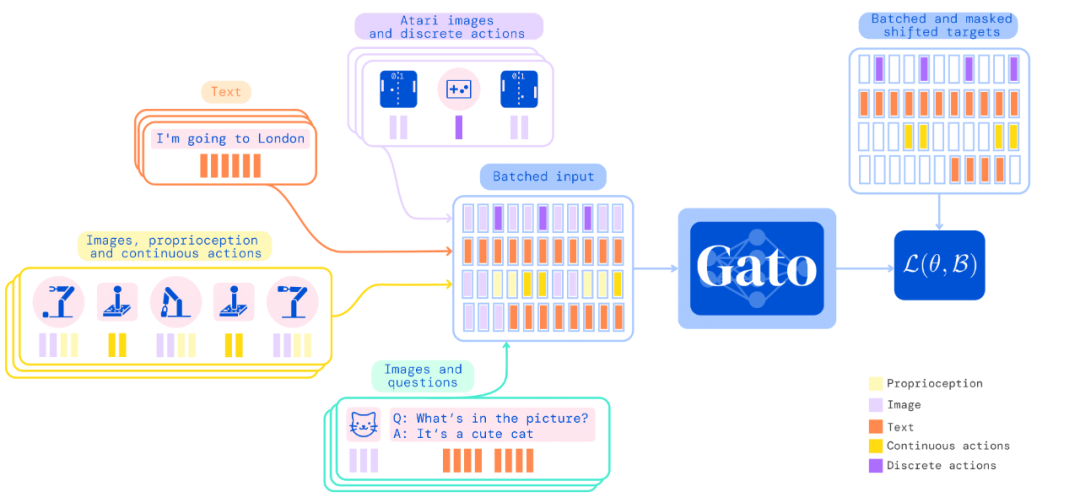
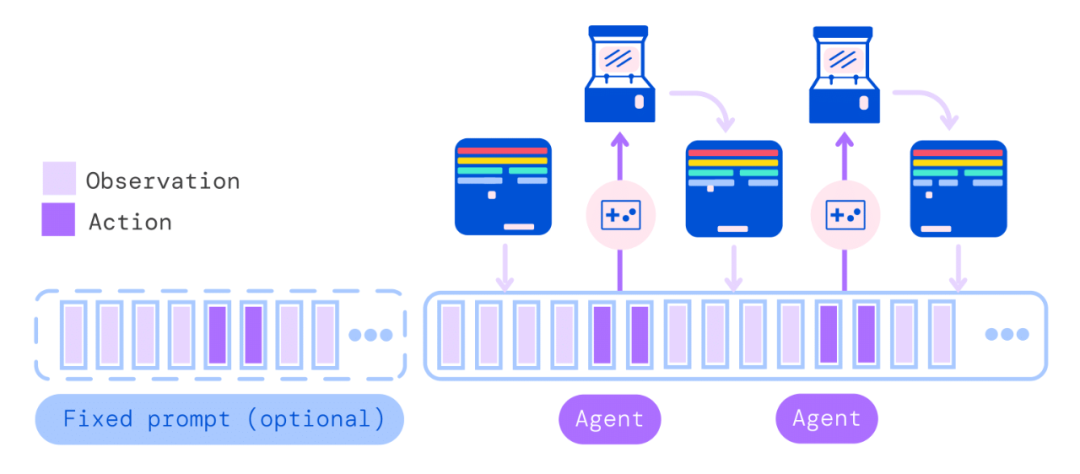
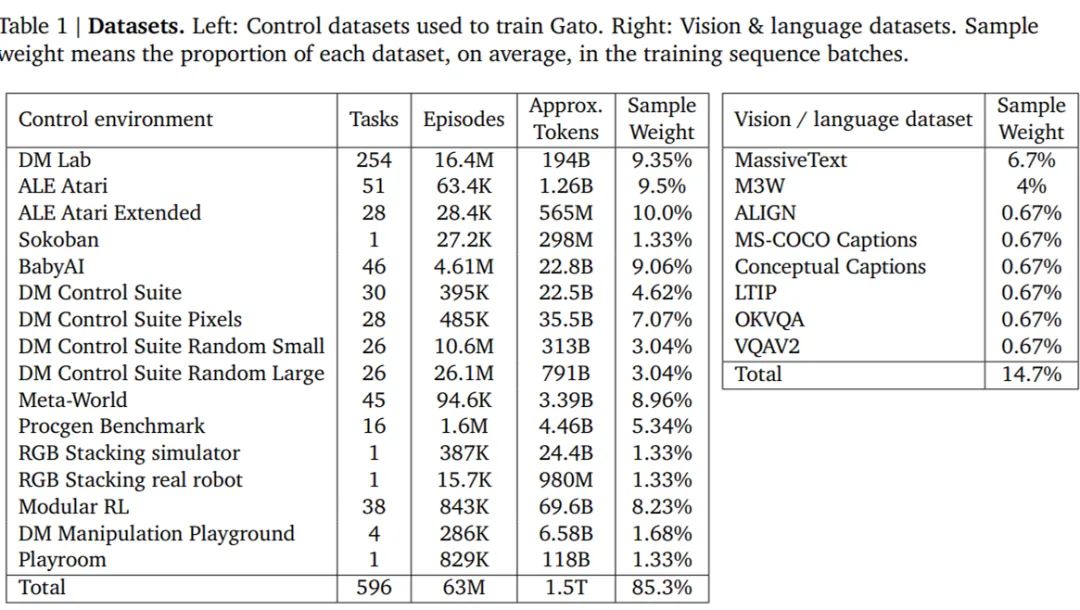
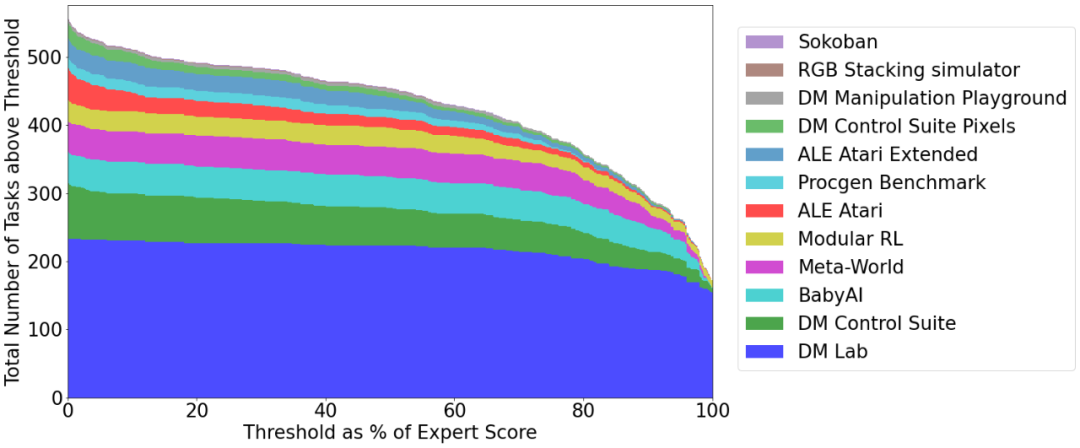
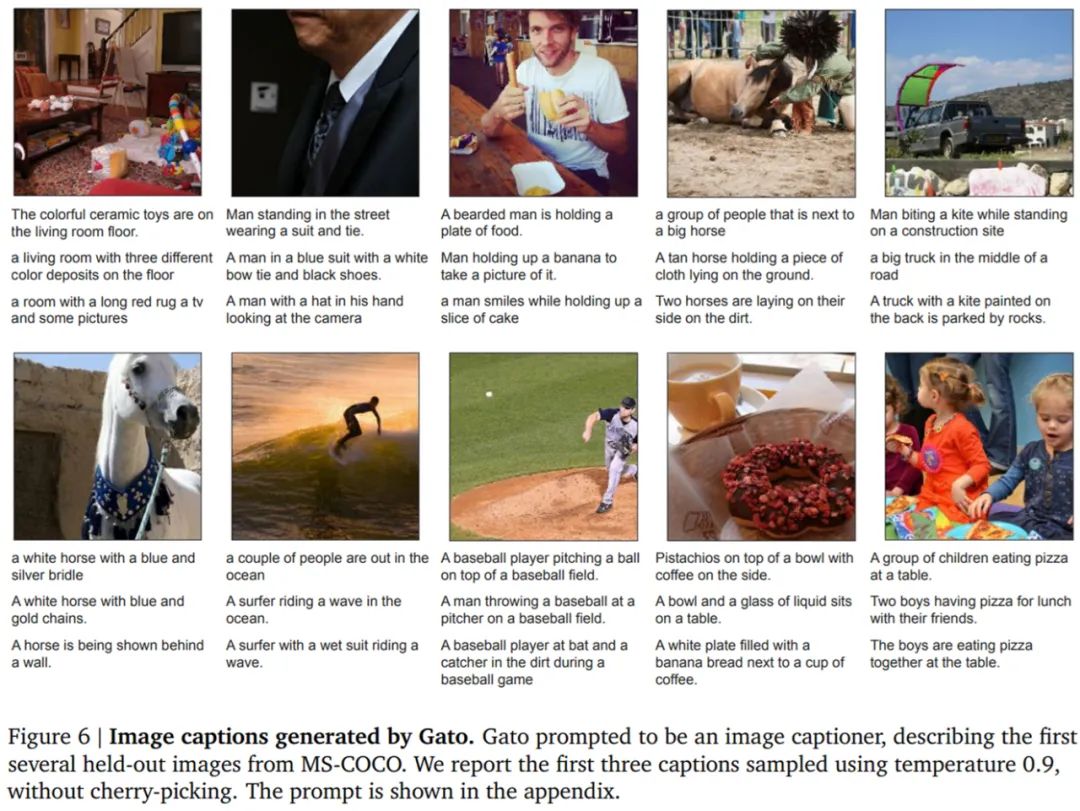
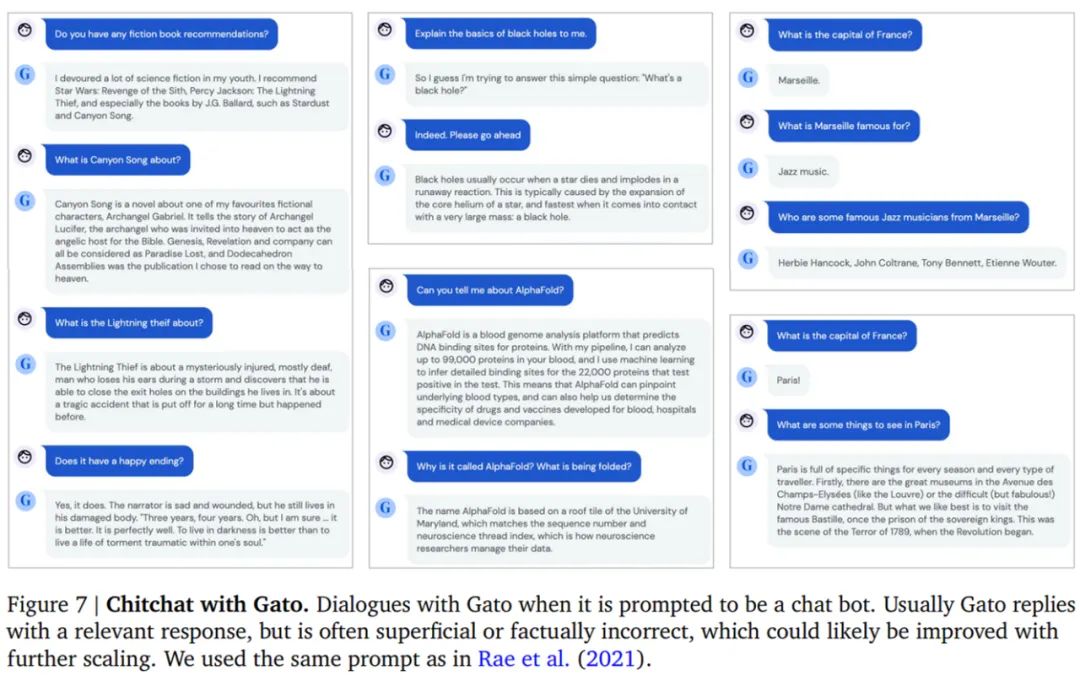
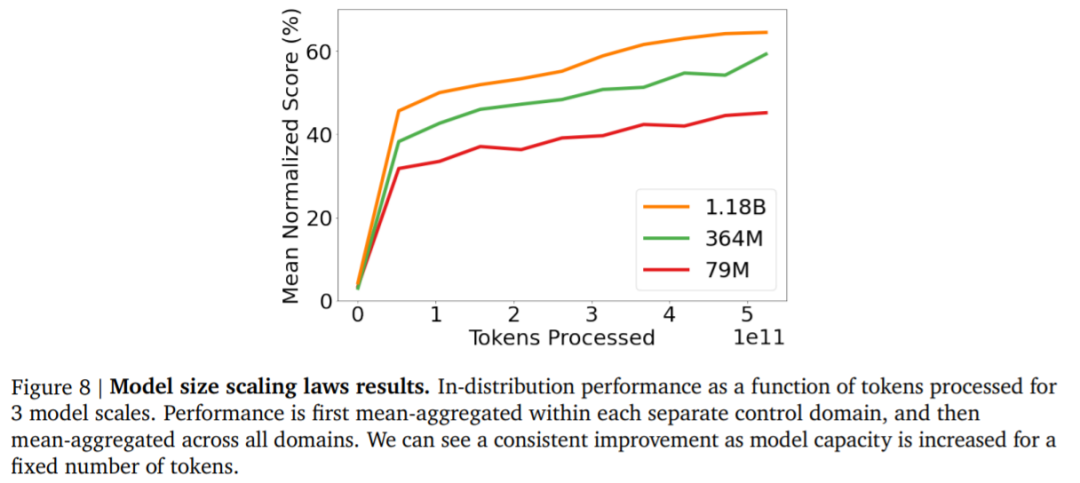
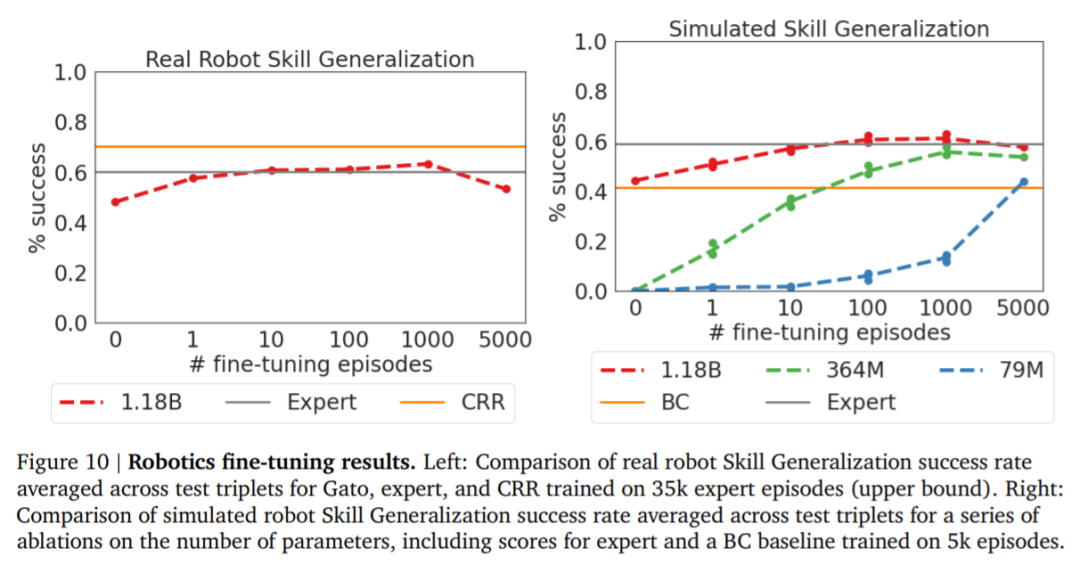
DeepMind「通才」AI智能体Gato来了,多模态、多任务,受大语言模型启发数据派THU关注共 3426字,需浏览 7分钟 ·2022-05-26 21:06 来源:机器之心本文共2500字,建议阅读10+分钟在写文章、画图之后,AI 大模型现在又同时有了打游戏的能力。不禁在想,DeepMind 的智能体 Gato 未来还能玩出哪些花活?假如使用单一序列模型就能解决所有任务,是再好不过的事情,因为这种模型减少了不必要的麻烦。不过这需要增加训练数据的数量和多样性,此外,这种通用模型随着数据的扩充和模型的扩展,性能还会提高。从历史上看,更擅长利用计算的通用模型最终也会超过特定于专门领域的模型。今日,受大规模语言建模的启发,Deepmind 应用类似的方法构建了一个单一的「通才」智能体 Gato,它具有多模态、多任务、多具身(embodiment)特点。论文地址:https://storage.googleapis.com/deepmind-media/A%20Generalist%20Agent/Generalist%20Agent.pdfGato 可以玩雅达利游戏、给图片输出字幕、和别人聊天、用机械臂堆叠积木等等。此外,Gato 还能根据上下文决定是否输出文本、关节力矩、按钮按压或其他 token。与大多数智能体玩游戏不同,Gato 使用相同的训练模型就能玩许多游戏,而不用为每个游戏单独训练。Gato 的训练数据集应该尽量广泛,需要包括不同模态,如图像、文本、本体感觉(proprioception)、关节力矩、按钮按压以及其他离散和连续的观察和行动。为了能够处理这种多模态数据,Deepmind 将所有数据序列化为一个扁平的 token 序列。在这种表示中,Gato 可以从类似于标准的大规模语言模型进行训练和采样。在部署期间,采样的 token 会根据上下文组合成对话响应、字幕、按钮按下或其他动作。UCL 计算机系教授汪军告诉机器之心,DeepMind 的这项最新工作将强化学习、计算机视觉和自然语言处理这三个领域合到一起,虽然技术思路上沿用了前人的方法,但能将 CV、NLP 和 RL 这三个不同模态映射到同一个空间,用一套参数表达,是非常不容易的。其积极意义在于,证明了 CV、NLP 和 RL 的结合是切实可行的,通过序列预测能够解决一些决策智能的问题。考虑到 Gato 模型目前的参数量只能算中等,接下来继续往这个方向探索,构建更大的模型,将会有非常大的意义。不过,Gato 大模型的 RL 部分只采用了监督学习方法,并未触及强化学习真正的核心——reward 设计机制,目前的任务中也没有多智能体决策的问题。汪军教授表示,他的团队近期在决策大模型上做了很多探索,包括证明多智能体决策也可以是序列模型,相关成果将于近期公布,欢迎大家关注。Gato 智能体细节在 Gato 的训练阶段,来自不同任务和模态的数据被序列化为扁平的 token 序列,由一个类似于大型语言模型的 transformer 神经网络进行 batch 和其他处理。由于损失被 masked,Gato 只预测动作和文本目标。下图为 Gato 的训练流程。在部署 Gato 时,提示(如演示)被 tokenised,形成了初始序列。接着,环境产生了首个观察结果,该结果也被 tokenised 并添加到序列中。Gato 以自回归的方式对动作向量进行采样,一次只采样一个 token。一旦包含动作向量的所有 token 都被采样(由环境的动作规范确定),动作被解码并发送给环境,然后逐步产生新的观察结果。重复这一过程。Gato 模型始终在包含 1024 个 token 的上下文环境窗口内查看之前所有的观察结果和动作。下图展示了将 Gato 部署为控制策略(control policy)的流程。除了各种自然语言和图像数据集之外,Gato 还在包含模拟和真实环境中智能体经验的大量数据集上进行了训练。下表 1 左为用于训练 Gato 的控制数据集,右为视觉与语言数据集。样本权重(sample weight)表示每个数据集在训练序列 batch 中平均所占的比例。Gato 智能体能力研究者汇总了在以上数据上训练时 Gato 的性能。也就是说,所有任务的所有结果都来自具有一组权重的单一预训练模型。微调结果将在「实验分析」章节展示。模拟控制任务下图 5 展示了 Gato 在给定分数阈值之上执行不同控制任务的数量相对于 Gato 训练数据中的专家表现。其中,x 轴上的值表示专家分数的特定百分比,0 对应随机智能体性能。y 轴表示预训练模型的平均性能等于或高于特定百分比时的任务数量。研究者将性能报告为百分比,其中 100% 对应每个任务的专家,0% 对应于随机策略。对于训练模型的每个模拟控制任务,他们在相应的环境中 roll out Gato 策略 50 次,并对定义的分数进行平均。如下图所示,Gato 以超过 50% 的专家分数阈值执行了 604 个任务中的 450 多个。在 ALE Atari 中,Gato 在 23 场 Atari 游戏中取得了人类平均(或更高的)分数,在 11 场游戏中取得了两倍于人类的分数。虽然生成数据的单任务在线 RL 智能体依然优于 Gato,但可以通过增加容量或使用离线 RL 训练而非纯监督来克服。研究者在文中还介绍了一个专业的单域 ALE Atari 智能体,它在 44 场比赛中都取得比人类更好的分数。在 BabyAI 中,Gato 在几乎所有级别上都得到了 80% 以上的专家分数。对于最困难的任务 BossLevel,Gato 的得分为 75%。相比之外,另外两个已发布的基准 BabyAI 1.0 和 BabyAI 1.1 分别使用 100 万次演示对该单一任务进行训练,它们的得分不过为 77% 和 90%。在 Meta-World 中,Gato 在接受训练的 45 个任务中的 44 个中得到了 50% 以上的专家分数,35 个任务上得到 80% 以上,3 个任务上超过 90%。在规范的 DM Control Suite 上,Gato 在 30 个任务中的 21 个上都得到了 50% 以上的专家分数,在 18 个任务上得到 80% 以上。机器人基准评估第一视角远程操作可以收集专家演示。然而,此类演示收集起来速度慢成本高。因此,数据高效的行为克隆方法对于训练通用机器人操纵器是可取的,离线预训练成为一个很有动力的研究领域。研究者也在已建立的 RGB Stacking 机器人基准上对 Gato 进行了评估。RGB Stacking 机器人基准上的技能泛化挑战测试了智能体堆叠以往未见过形状的对象的能力。智能体在一个包含各种形状机器人堆叠对象的 episodes 的数据集上进行训练。但是,五个对象形状的三元组没有包含在训练数据中,而是作为测试三元组。研究者针对真实机器人上的每个测试三元组对训练的 Gato 进行了 200 轮的评估。下表 2 的结果表明,Gato 在每个测试三元组上的成功率与 Lee 等人(2021)提出的单任务 BC-IMP(filtered BC)基准相当。文本示例Gato 智能体也能生成基本对话以及给图像加字幕(或描述)。下图 6 展示了 Gato 为图像加字幕的代表性示例。下图 7 展示了一些精选的纯文本对话交流示例。实验分析下图 8 中,DeepMind 评估了 3 种不同模型大小(以参数计数衡量):79M 模型、364M 模型和 1.18B 模型 (Gato)。可以得出,在相等的 token 数下,随着模型的扩展,模型性能随之提高。下图 10 将 Gato 在不同微调数据机制中的成功率与 sim-to-real 专家和 Critic-Regularized Regression (CRR) 智能体进行了比较,结果如下:Gato 在现实和模拟中(分别为左图和右图的红色曲线),仅用 10 episodes 就恢复了专家的表现,并在 100 或 1000 episodes 微调数据时达到峰值,超过了专家。在此点之后(在 5000 处),性能会略有下降,但不会远远低于专家的性能。下表 3 为 Gato 和 BC-IMP 比较结果。原文链接:https://www.deepmind.com/publications/a-generalist-agent编辑:黄继彦 浏览 47点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 通才智能体来了!DeepMind的Gato算世界第一个AGI吗?人工智能与算法学习0通才智能体来了!DeepMind的Gato算世界第一个AGI吗?视学算法0通才智能体来了!DeepMind的Gato算世界第一个AGI吗?新智元0mPLUG-Owl多模态大语言模型阿里达摩院提出的多模态GPT的模型:mPLUG-Owl,基于 mPLUG 模块化的多模态大语言模型。它不仅能理解推理文本的内容,还可以理解视觉信息,并且具备优秀的跨模态对齐能力。论文:https://mPLUG-Owl多模态大语言模型阿里达摩院提出的多模态GPT的模型:mPLUG-Owl,基于 mPLUG 模块化的多模态大语言模型。大语言模型形态:智能体(AI Agent)本文来自“2024人工智能大语言模型发展技术研究报告”,随着技术飞速发展,智能体(AI Agent)正成为一股革命性力量,正在重新定义人与数字系统互动的方式。AI Agent是一种高效、智能的虚拟助手,通过利用人工智能自主执行任务。它被设计成能感知环境、解释数据、做出明智决策,并执行动作以实现预先设ImageBind多模态 AI 模型ImageBind 是支持绑定来自六种不同模态(图像、文本、音频、深度、温度和 IMU 数据)的信息悟道双语多模态大语言模型“悟道”是双语多模态预训练模型,规模达到1.75万亿参数。项目现有7个开源模型成果,模型参数文件需到悟道平台进行下载申请。图文类CogViewCogView参数量为40亿,模型可实现文本生成图像,经过悟道双语多模态大语言模型“悟道”是双语多模态预训练模型,规模达到 1.75 万亿参数。项目现有 7 个开源模型成果,模型参数ImageBind多模态 AI 模型ImageBind是支持绑定来自六种不同模态(图像、文本、音频、深度、温度和IMU数据)的信息的AI模型,它将这些信息统一到单一的嵌入式表示空间中,使得机器能够更全面、直接地从多种信息中学习,而无需明点赞 评论 收藏 分享 手机扫一扫分享分享 举报





 下载APP
下载APP