
Spark Streaming整合log4j、Flume与Kafka的案例
点击上方蓝色字体,选择“设为星标”




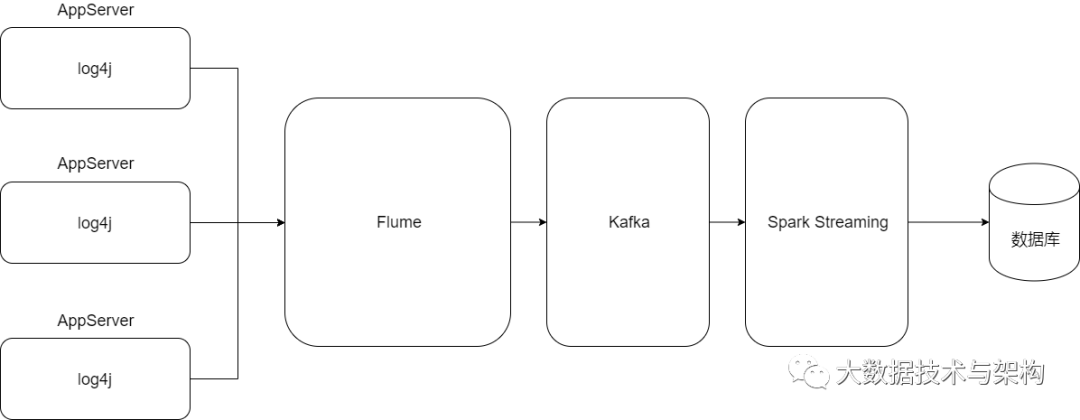
1.框架
2.log4j完成模拟日志输出
设置模拟日志格式,log4j.properties:
log4j.rootLogger = INFO,stdoutlog4j.appender.stdout = org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.target = System.outlog4j.appender.stdout.layout = org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
import org.apache.log4j.Logger;/*** 模拟日志产生*/public class LoggerGenerator {private static Logger logger = Logger.getLogger(LoggerGenerator.class.getName());public static void main(String[] args) throws Exception{int index = 0;while(true){Thread.sleep(1000);logger.info("value:" + index++);}}}
2020-03-07 18:21:37,637 [main] [LoggerGenerator] [INFO] - current value is:02020-03-07 18:21:38,639 [main] [LoggerGenerator] [INFO] - current value is:12020-03-07 18:21:39,639 [main] [LoggerGenerator] [INFO] - current value is:22020-03-07 18:21:40,640 [main] [LoggerGenerator] [INFO] - current value is:32020-03-07 18:21:41,640 [main] [LoggerGenerator] [INFO] - current value is:42020-03-07 18:21:42,641 [main] [LoggerGenerator] [INFO] - current value is:52020-03-07 18:21:43,641 [main] [LoggerGenerator] [INFO] - current value is:62020-03-07 18:21:44,642 [main] [LoggerGenerator] [INFO] - current value is:72020-03-07 18:21:45,642 [main] [LoggerGenerator] [INFO] - current value is:82020-03-07 18:21:46,642 [main] [LoggerGenerator] [INFO] - current value is:92020-03-07 18:21:47,643 [main] [LoggerGenerator] [INFO] - current value is:10
3.Flume收集log4j日志
$FLUME_HOME/conf/streaming.conf:
agent1.sources=avro-sourceagent1.channels=logger-channelagent1.sinks=log-sinkagent1.sources.avro-source.type=avroagent1.sources.avro-source.bind=0.0.0.0agent1.sources.avro-source.port=41414agent1.channels.logger-channel.type=memoryagent1.sinks.log-sink.type=loggeragent1.sources.avro-source.channels=logger-channelagent1.sinks.log-sink.channel=logger-channel
flume-ng agent \--conf $FLUME_HOME/conf \--conf-file $FLUME_HOME/conf/streaming.conf \--name agent1 \-Dflume.root.logger=INFO,console
<dependency><groupId>org.apache.flume.flume-ng-clientsgroupId><artifactId>flume-ng-log4jappenderartifactId><version>1.6.0version>dependency>
log4j.rootLogger = INFO,stdout,flumelog4j.appender.stdout = org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.target = System.outlog4j.appender.stdout.layout = org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%nlog4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppenderlog4j.appender.flume.Hostname = hadoop000log4j.appender.flume.Port = 41414log4j.appender.flume.UnsafeMode = true
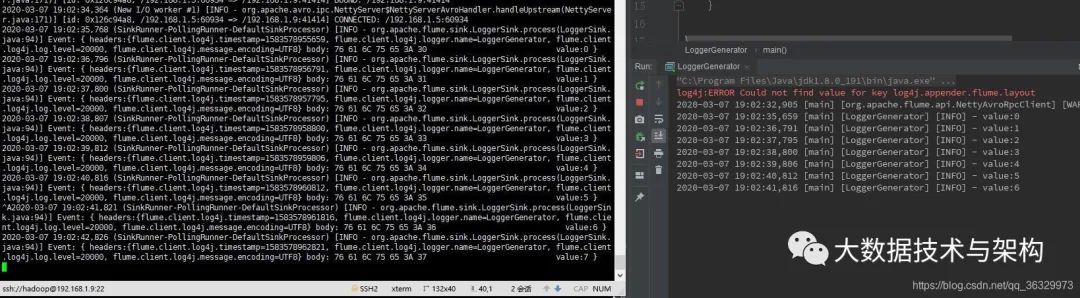
Flume采集成功
4.KafkaSink链接Kafka与Flume
使用Kafka第一件事是把Zookeeper启动起来~
./zkServer.sh start./kafka-server-start.sh -daemon /home/hadoop/app/kafka_2.11-0.9.0.0/config/server.properties kafka-topics.sh --list --zookeeper hadoop000:2181kafka-topics.sh --create \--zookeeper hadoop000:2181 \--replication-factor 1 \--partitions 1 \--topic tp_streamingtopic
对接Flume与Kafka,设置Flume的conf,取名为streaming2.conf:
Kafka sink需要的参数有(每个版本不一样,具体可以查阅官网):
sink类型填KafkaSink
需要链接的Kafka topic
Kafka中间件broker的地址与端口号
是否使用握手机制
每次发送的数据大小
agent1.sources=avro-sourceagent1.channels=logger-channelagent1.sinks=kafka-sinkagent1.sources.avro-source.type=avroagent1.sources.avro-source.bind=0.0.0.0agent1.sources.avro-source.port=41414agent1.channels.logger-channel.type=memoryagent1.sinks.kafka-sink.type=org.apache.flume.sink.kafka.KafkaSinkagent1.sinks.kafka-sink.topic = tp_streamingtopicagent1.sinks.kafka-sink.brokerList = hadoop000:9092agent1.sinks.kafka-sink.requiredAcks = 1agent1.sinks.kafka-sink.batchSize = 20agent1.sources.avro-source.channels=logger-channelagent1.sinks.kafka-sink.channel=logger-channel
flume-ng agent \--conf $FLUME_HOME/conf \--conf-file $FLUME_HOME/conf/streaming2.conf \--name agent1 \-Dflume.root.logger=INFO,console
./kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic tp_streamingtopic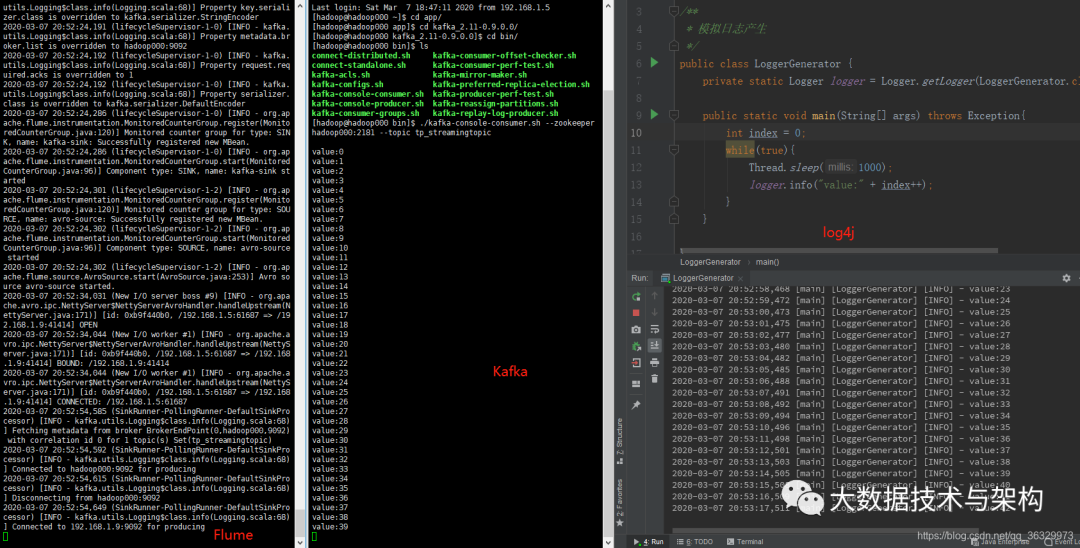
成功传输~
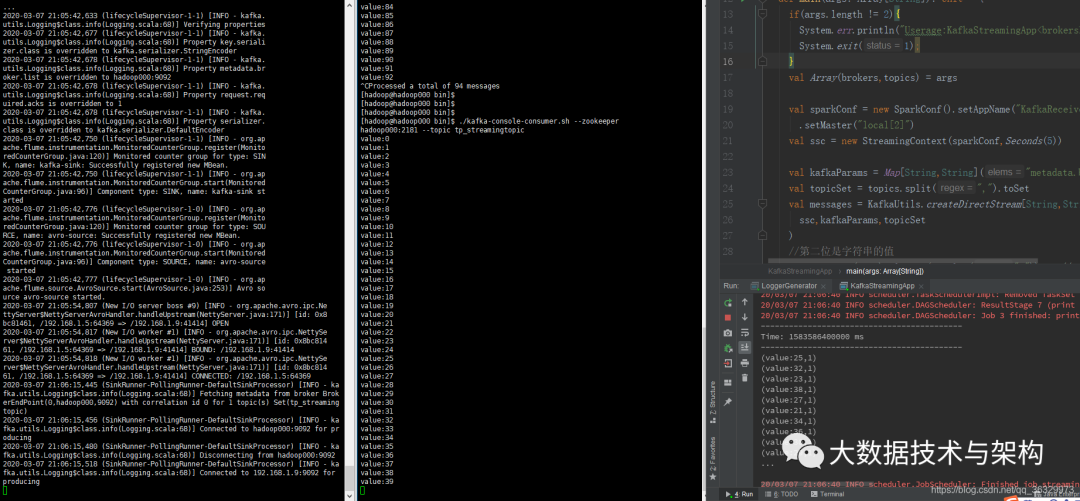
5.Spark Streaming消费Kafka数据
package com.taipark.sparkimport kafka.serializer.StringDecoderimport org.apache.spark.SparkConfimport org.apache.spark.streaming.kafka.KafkaUtilsimport org.apache.spark.streaming.{Seconds, StreamingContext}/*** Spark Streaming 对接 Kafka*/object KafkaStreamingApp {def main(args: Array[String]): Unit = {if(args.length != 2){System.err.println("Userage:KafkaStreamingApp); " System.exit(1);}val Array(brokers,topics) = argsval sparkConf = new SparkConf().setAppName("KafkaReceiverWordCount").setMaster("local[2]")val ssc = new StreamingContext(sparkConf,Seconds(5))val kafkaParams = Map[String,String]("metadata.broker.list"-> brokers)val topicSet = topics.split(",").toSetval messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topicSet)//第二位是字符串的值messages.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()ssc.start()ssc.awaitTermination()}}
入参是Kafka的broker地址与topic名称:
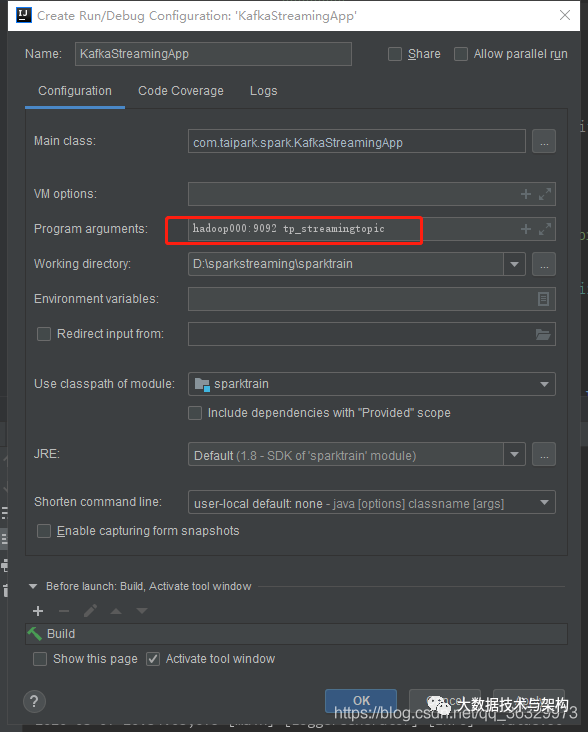
本地Run一下:
文章不错?点个【在看】吧! ?
评论