
Spark 探索|Spark 中 CodeGen 与向量化技术的研究
在 Kyligence 推出的首期 Data & AI Meetup 中,畅销书《深入理解 Spark 》作者、Kyligence 高级性能工程师耿嘉安带来了主题为「Spark Code Generation & Vectorization」的分享,深入浅出地讲解了「Spark 为什么需要 CodeGen」、「Spark CodeGen 与向量化原理」、「Spark 向量化的前沿」等多个与 Spark 有关的热门话题,在直播间收获了一众好评。想了解更多,快往下看吧~
以下为耿嘉安在直播间演讲实录
后台回复「1104」获取本期 PPT 下载链接
主题背景
Spark 项目是在2010年左右开源出来的,越来越多的人了解到了 Spark 这个开源大数据项目的存在。从其诞生之初到如今 Spark 3.2.0 版本的发布,整个大数据圈中凡是用了 Spark 的公司和个人,都一直致力于对它的性能进行极致的优化。时至今日,国内外的各大厂商都把性能优化的矛头直指向量化技术,意图能够把 Spark 的性能完全压榨出来,让它能够更加逼近硬件的性能。
Vectorization(向量化)
今天分享的主题都围绕着一个关键词,即 Vectorization ,翻译成中文就是“向量化”的意思。什么叫“向量化”呢?
其实程序员刚开始学习如何声明一个变量的时候,就已经开始慢慢地接触到“向量化”了。一般来说,需要声明的这个变量是基础类型或是原始类型,这样的类型在向量化的领域被称为标量,可以认为它是个一维的东西。比如我要去声明一个数组,这个数组中各个元素的值不一样,但代表的都是同一个含义,对这些内容进行操作时,如果采取批量操作,就能够避免单独操作的重复和繁琐。
作为一个向量,如果能用向量的计算方式,甚至是用一些离散数学中向量的计算方式,从数学的角度来看就已经很简单了。而今天讨论的不光是数学的问题,更多的是计算机的问题。有了向量后,一些 CPU 的厂商也开始意识到了这个问题,研制出了一些专门的 CPU 指令,这些指令专门应对向量数据,能够对向量进行批量的计算处理。
演讲目录
下面咱们开始由浅入深地一步一步来,我今天主题分享的 Agenda 如下:
Java Vectorization
Volcano Iterator Model
Tungsten Project
Spark Code Generation
Spark Code Generation & Vectorization
The frontier of Spark Vectorization
主题分享
1
●
Java Vectorization
首先给大家介绍一下 Java 的向量化,因为其实在整个大数据领域中,最主要的语言就是 Java,或者说是 Java 生态的东西。而今天又要讲 Spark,所以不可避免地要说一下 Java 的向量化是怎么做的。
Java 最核心的一点在于,它跟其他语言一样,都是想着法儿的,绕着弯儿的,绞尽脑汁地想要利用 CPU 的向量化指令,这就是它的初衷。

在 Java 中究竟是如何将标量的代码转化成向量代码,用向量代码来运行向量指令的呢?其实 Java 运用了一种曲线救国的方式。因为 Java 不像 C++ 或者是 C 语言,能够直接调用一些操作系统底层的命令(例如:分配内存或者调用 CPU 指令),它做不到这些,所以它要曲线救国。曲线救国的第一点是什么?当我把代码从刚才那种很繁琐的方式改为这种 FOR 循环后,如果在其中继续运行的话,当循环超过几万次后,它会慢慢地被即时编译器捕获,然后进行即时编译,编译成机器代码,在它编译的过程中有很多优化的点。其中有一个很重要的点,就是它会把它作为向量化去进行处理,然后去调用底层 CPU 的向量化指令。

这其中第一个点就是热点代码追踪。因为这是一个 FOR 循环,这个热点追踪是靠 JVM 本身内部的实现机制去做到的。当你这个代码需要足够多的次数去执行的时候,JVM 会发现自身对这个地方优化很有价值,其中有一个优化就是把它进行向量化。向量化怎么实现?用即时编译器(JIT)把它编译成本地机器代码之后,这个机器代码再接着去调用底层的 SIMD 的指令,就是这么一个过程。说到 SIMD 指令,比如说英特尔有 vmulps 这么一个指令,就是专门对向量进行操作的指令。这就是 Java 向量化的过程。

根据刚才我与大家在这部分的分析,我们可以了解 Java 向量化的三个特点:
Automatic:不能手动控制,只能由 JVM 自动处理。它没有办法做到像 C++ 一样直接调一个底层的 CPU 指令,所以这个过程是一个自动化的过程。
Implicit:代码层面无法找到向量化的显式调用,整个过程是隐式的。即便刚刚提到的 FOR 循环足够大、循环次数足够多,一个普通用户来看的话也看不到向量化的东西,感觉它跟向量化没有任何关系。即便最后真的进行了向量指令的调用,其实你也不知道。所以整个过程是一个隐式的过程。
Unreliable:依赖于 JVM 运行期的热点代码跟踪以及 JIT ,所以整个过程是不可靠的。它依赖于 JVM 运行期的热点追踪,包括即时编译器等。万一代码的循环次数不够,比如说没有达到需要即时编译的域值的话,可能就不会用即时编译去编译,就无法真正做到向量化。也就是说即便你觉得 FOR 循环次数够多了,也不一定真的会有向量化。所以说 Java 的向量化是一种不可靠的优化方式。
2
●
Volcano Iterator Model
接下来介绍一下 Volcano Iterator Model,也就是火山迭代模型,它是现在大多数大数据系统或者说数据库底层,对 SQL 进行处理时通常会采用的模型。
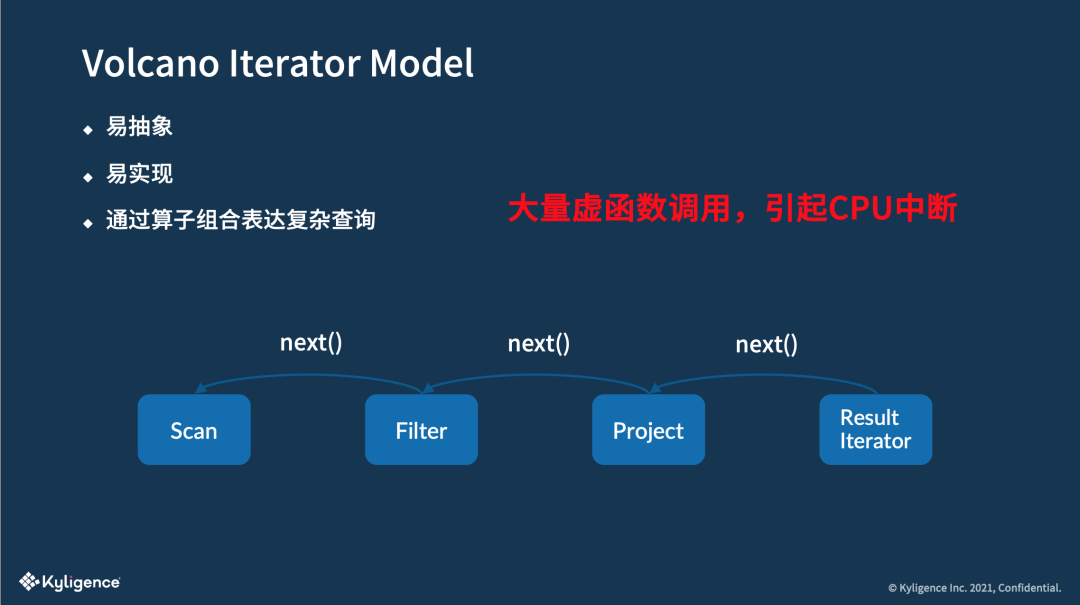
为什么大家都喜欢用这个模型呢?因为这个模型具有易抽象、易实现、以及能够通过算子组合表达复杂查询这三个优势。
以 Spark 的一些算子为例,比如要在最底层 Scan 一个数据源,可能是一个数据库表也可能是一个文件,Scan 完了之后,可能加了一个 Filter,来过滤一些行,之后我可能还要使用Project选择某些字段,最后这个结果可能再迭代返回,是一个过程。
这样的过程其实有一个统一的抽象接口,比如说我这个里面写了一个叫 next,其实像 Spark 里面就有一个 hasNext,就是表达我这一行拿掉之后,下面还有没有行?next 就是拿掉下面的行,这是易于用代码去抽象和实现的,通过这些不同算子之间的组合又能表达很丰富的语义。所以说这个模型在数据库的 SQL 领域经常被借鉴和使用。
当然这个模型也有它的劣势,这里我们就得提到虚函数了,虚函数和实函数相对,主要区别其实是在于调用机制的不同。大量虚函数的调用,就可能会导致 CPU 的中断和耗时等。所以说这并不那么友好, Code Generation 其实就是想要解决这个问题。
3
●
Tungsten Project
把刚才两个铺垫的知识说完,接下来我们一起聊聊赫赫有名的 Tungsten 项目。这个项目最早是从 Spark 1.3 开始发起的,后来在 Spark 1.4 包括 Spark 1.5 中陆陆续续增强了很多的特性和功能。下个部分我要说的 Spark Code Generation,其实就是 Tungsten 项目很重要的组成之一。
Tungsten 项目有一个愿景,它希望 Spark 在内存和 CPU 上的效率能够一直提升,将它逼近到硬件的水平,虽然目前还没有实现,但愿景是美好的。
这个 Tungsten 项目其实跟向量化的主题并没有很强的相关性,其实最主要的还是 Code Generation。但是这个地方我还是想要简单介绍一下 Tungsten 项目,把其中对大家感知非常明显的地方大概说一下。

3.1 内存管理与二进制处理
Spark 在 Tungsten 项目中的内存管理之前,最早的内存管理依托于 JVM 自身的内存分配或是 GC 的过程。而因为 Spark内存中的对象数量非常大,例如:它的一些数据结构、元数据的信息等等在它的内存里最后会通过对象来表示。又因为这是一个大数据项目,所以当数据量很大的时候,对象的膨胀往往会非常快,它的内存问题就很明显。所以说社区的很多同志就想把这个问题解决一下。
过程中就发现了 Java 的对象不是个"好东西",我得尽量把它给干掉,能不用它就不用它,于是很多人就用到了一个绕弯子的方式,使用很早年前公开的UnSafe的 API。用那些 API 间接地去调一些 native命令,直接能够在操作系统内存去分配一些空间,利用这些空间, Spark 在实现的时候,或者是 Tungsten 项目在实现的时候,就能通过一些地址和偏移量的信息来表达一个对象的内容。同时,因为它不像 Java 了,它的内容数据都是用二进制存储在机器内存的,所以说一个很重要的点就是它把 Java 对象的开销降低了。
这里面有一个很重要的点,举一个例子:以计算机基础来说,比如说一个 int 类型往往在很多系统里用四个字节就够存储它了,但是在 Java 的一些对象类型里,本来四个字节就够的存储空间,实际上可能要用 32 个字节,所以它造成了非常严重的浪费。有了这样的优化之后我们就能节省大量的内存了。
因为刚刚说的 JVM 是 Java 应用程序的通用的内存管理。虽然说它也非常棒,从当年的 CMS 内存垃圾回收器,到后来的 G1,包括现在更新的、越来越多的内存管理器;从当年的 Sun 到现在的 Oracle,一直在不断地进化它的 GC 和内存管理的技术。但是 Spark 的管理者,或者说 Spark 的开发人员,他们认为你再怎么样也只是一个通用化的方式,永远不能准确知道我要创建的这些对象什么时候要释放。Spark 的管理者认为他们更加清楚里面的对象,它们的生命周期怎么样、什么时候释放,什么时候申请。所以说 Spark 自己开辟了一个内存管理,先从逻辑上申请内存,申请好之后,再实际申请物理内存的过程。
3.2 缓存感知
有了这两个之后,再说一下缓存感知。缓存感知我了解得不多,但是简单说一下,它其实是为了有效地利用一些 L1、L2、L3 不同级别的 CPU 缓存。CPU 缓存一旦能够命中,它的读写的速度要比内存(或者说主存)至少要高一个量级,所以这个也很有吸引力。
3.3 Spark Code Generation
最后还是要回归到 Code Generation。那么 Spark 为什么需要 Code Generation ?

其实刚才在前面已经提到了一些原因,比如我刚才说的火山迭代模型,它里面的多态或者是虚函数调用的问题,包括想要做 Java 的向量化。除了这些外还有别的,比如它想通过代码编织的方式,通过字符串拼接,拼接出Java代码,能够减少一些基本类型的自动装箱,基本类型的自动装箱本来是 Java 或者是 Scala 语言自身的一个语法糖,但是这样的语法糖其实对于一些编译过程是不太友好的,对这些东西需要进行一些优化。除此之外,它其实还做了很多其他优化点。比如说有算子融合、缩减栈深等等,这些问题我们就不一一展开了。
接着简单说一下 Spark 的 Code Generation 的代码架构。

在 Spark 的源码里面有一个 WholeStageCodegen 这么一个类,这个类它规范了 Spark 里面的物理算子进行代码编织的框架。上图其实是Spark源代码里的一段注释,但是这个注释对于不怎么看源码的人可能看得比较头疼。但你其实不用管别的,最核心的就是要知道有一个 doProduce,你的每一个物理算子需要实现它,每个物理算子自己更加知道它应该怎么样编织Java 代码,实现这个方法就可以了。
既然这个架构编出来的字符串里面表示的是 Java ,那要用什么东西去编译呢?难道去执行一个 JavaC 吗?这肯定是不太优雅的,这个时候引入了一个正好也是开源的 Java 编译器,叫做 Janino。

举一个例子, Spark 的物理算子里有一个比较著名,叫做 DataSourceScanExec,它专门对底层的数据源进行扫描或者说是按行读,它的 doProduce 里最核心的就是上图这五行代码,它实际上是按照行把数据读出来,读出来后去做一些映射,可能还有一些更底层的表达式,所以它还能再对这些表达式进行逐个代码编织。
这个地方我们也能看到火山迭代模型的影子。比如说里面用到 Iterator 这个 Scala 的迭代器的类,里面的泛型就是 InternalRow ,就是按照行迭代的意思。这个迭代器迭代出来的结果,返回的结果就是 Iterator[InternalRow]。那么这个 Row 返回给上层,我们回想刚才的火山模型,它是不是就可以一层一层往上传?传到最后拿到结果的那个地方,正好也是遥相呼应的。
Spark 的 Code Generation 我们就简单介绍这些,感兴趣的人可以继续深入研究。
4
●
Spark Code Generation & Vectorization
我们今天的主题是向量化,所以就来说一下在 Code Generation 中,向量化是怎么做到的。
说到向量化, Code Generation 框架里面有一个叫列式框架的内容。

Spark 的列式框架里面跟其他的不太一样,它要处理的数据不是 InternalRow,而是 ColumnarBatch ,中文叫做列批,它实际上是按照批次把每一列按照向量存储的方式把它一列一列存起来,这就叫列批。
列批框架里面最核心的代码,你能看到,实际上是一个用 FOR 循环一列一列地访问它的信息的这么一个过程。这个过程是不是跟刚才我说的 Java FOR 循环的方式非常像?
那么 Spark 这个列式框架是怎么实现的呢?主要依靠这三步:

第一,需要有一个列式的存储,不管是 Parquet 还是 ORC,因为这样的一个存储天生就是一个列式存储,特别便于做这样的向量化的处理。
第二,你需要有一个列存储的读取器。像 Spark 里面分别实现了 Parquet Reader 和 ORC 的 Reader,它读出来就是一个列批的数据结构。
第三,就是通过我刚才说的 Code Generation 那个例子,把那个方式通过列批的这种一步一步这三步下来,把它转化成一个 FOR 循环的方式,就刚好吻合了 Java 向量化的处理过程。
这个地方有一个开发点,或者说一个小分支。很多人会问,是不是要用 Spark 向量化就一定要找一些列式存储呢?我就是存的文本结构怎么办?那也没问题,因为这个读到列批,最后是 Spark 内存式的数据结构。比如说你先读了一个行的结构,你自己写一些插件或者什么别的方式,把行转成列批就可以了,依然是可以处理的,只不过就可能在效率、优雅上不太好。
最后我和大家简单分享下我所了解的目前在整个 Spark 社区,或者说国内外的各大厂商在向量化上所做的比较前沿的事情。

最后,根据我对这些内容的理解,包括对各大厂商调研的情况,我觉得现在做向量化有两条路,一条路是把 SparkSQL 的表达式和物理计划完全改写,改写成另一种引擎或者是语言支持的一种东西。还有一条路就是改成另外的一种 Native 的运行时,比如说阿里、英特尔他们就是这么做的。
这是今天我分享的内容。最后再次感谢大家观看我的主题分享。
Data & AI Meetup 第3期预告
干货满满的 Data & AI Meetup 精彩继续,第 3 期将于12月2日 19:00-20:45 与大家在线上相见。本期我们特别邀请了来自阿里云、小米、腾讯的三位技术专家分享一线大厂研发 Remote Shuffle Service (RSS) 的动机和真实生产实践,感兴趣的同学们快扫描下方二维码进入活动微信群吧~
关于 Kyligence
Kyligence 由 Apache Kylin 创始团队创建,致力于打造下一代智能数据云平台,为企业实现自动化的数据服务和管理。基于机器学习和 AI 技术,Kyligence 从多云的数据存储中识别和管理最有价值数据,并提供高性能、高并发的数据服务以支撑各种数据分析与应用,同时不断降低 TCO。Kyligence 已服务中国、美国及亚太的多个银行、保险、制造、零售等客户,包括建设银行、浦发银行、招商银行、平安银行、宁波银行、太平洋保险、中国银联、上汽、一汽、安踏、YUMC、Costa、UBS、Metlife、AppZen 等全球知名企业和行业领导者。公司已通过 ISO9001,ISO27001 及 SOC2 Type1 等各项认证及审计,并在全球范围内拥有众多生态合作伙伴。
点击“阅读原文”了解更多