
2080Ti 竟然可以当 V100 来用,这个功能有点儿厉害。转载自 | 机器之心



再举一个常见的例子,企业中的算法工程师拥有足够的算力,显存没那么重要。然而,只使用并行策略分担显存,还是可能会出现显存足够、但每张 GPU 的计算负载又不足的情况。
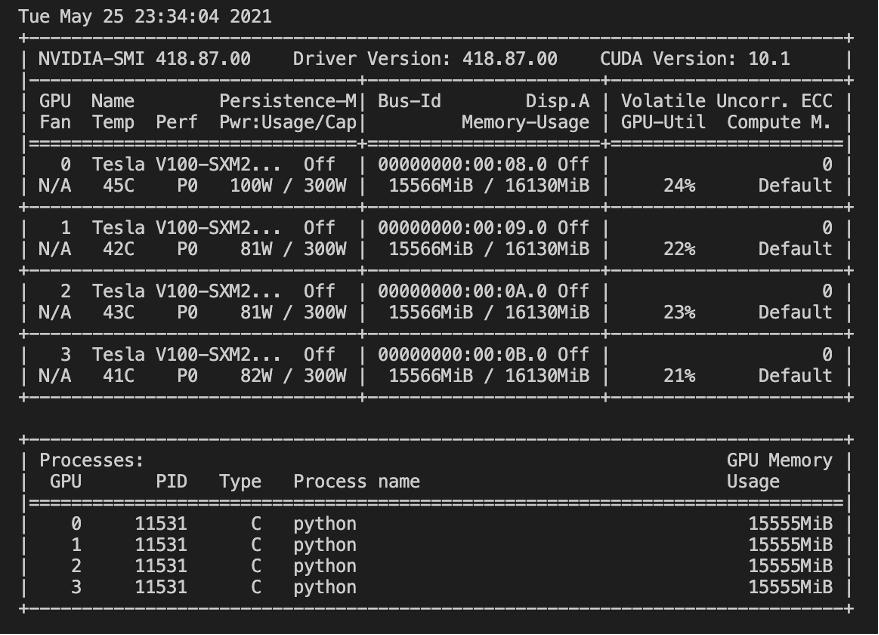
4 张 V100,显存占满,而 GPU 利用率很低。


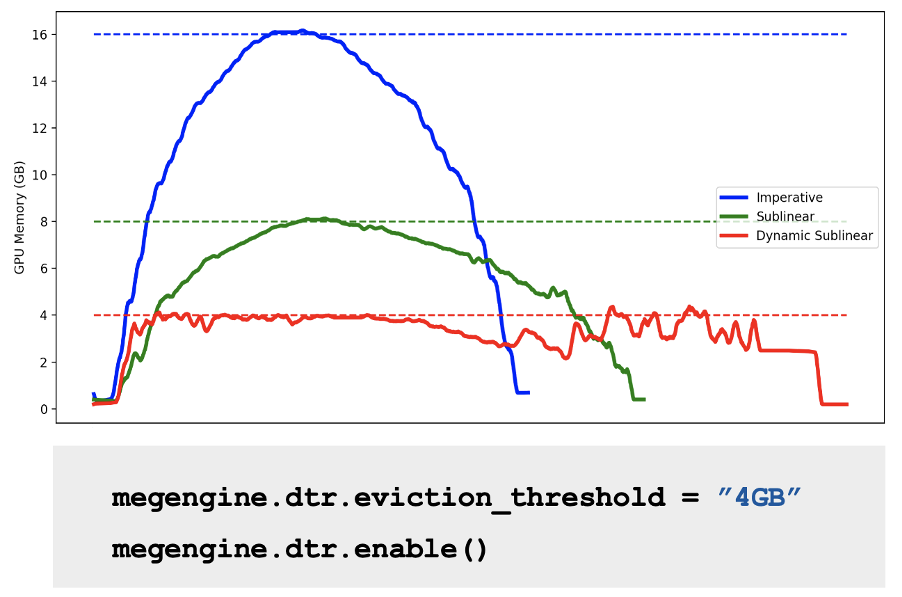
原本需要 16GB 显存的模型,优化后使用的显存峰值就降到了 4GB。



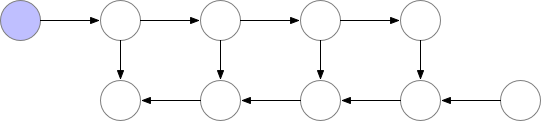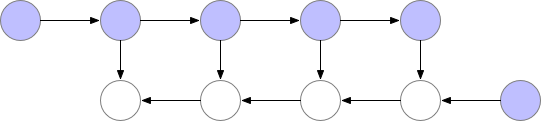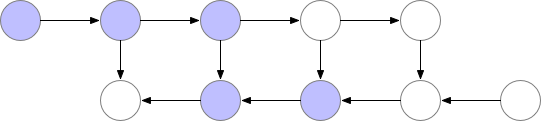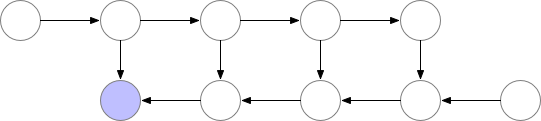

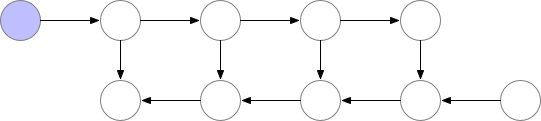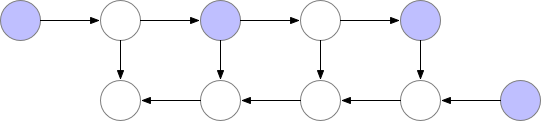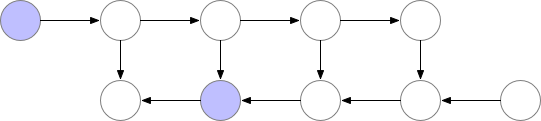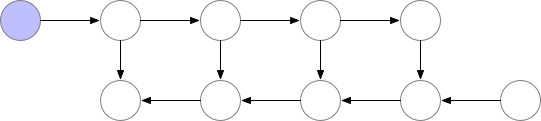
因此很明确,动态计算图中也应该使用梯度检查点技术,用计算换显存。如下为梯度检查点技术原理示意,前向传播中第三个点为检查点,它会一直保存在显存中。第四个点在完成计算后即可释放显存,在反向传播中如果需要第四个点的值,可以从第三个点重新计算出第四个点的值。

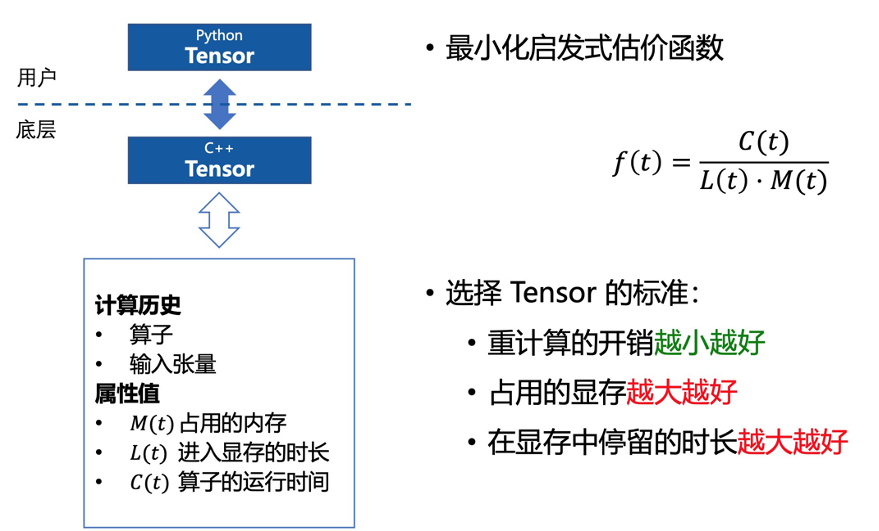


struct ComputePath { std::shared_ptr<OpDef> op; SmallVector<TensorInfo*> inputs; SmallVector<TensorInfo*> outputs; double compute_time = 0;} *producer;SmallVector<ComputePath*> users;size_t ref_cnt = 0;
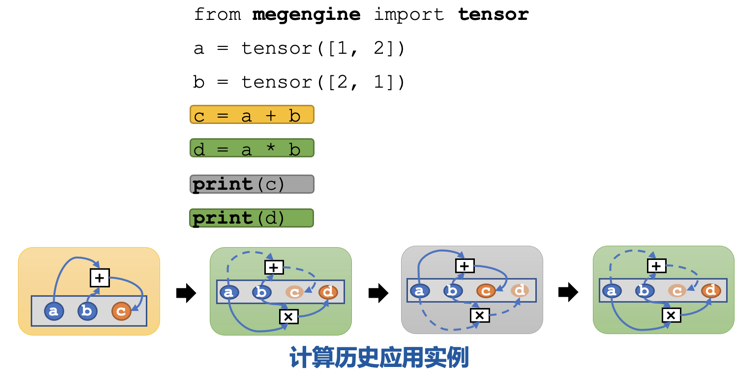
以上为 MegEngine 底层用于追踪计算路径信息的结构体。其中 op 表示产生该张量的算子;inputs 和 outputs 分别表示这个算子需要的输入与输出张量;compute_time 表示该算子实际的运行时间。实际上,在使用 MegEngine 的过程中,全都是用 Python 接口创建张量,只不过框架会对应追踪每个张量的具体信息。每当需要访问张量,不用考虑张量是否在显存中时,没有也能立刻恢复出来。所有这些复杂的工程化的操作与运算逻辑都隐藏在了 MegEngine C++ 底层。

Python 代码会翻译成 C++ 底层实现,C++ 代码会通过指针管理显卡内存中真正的张量(右图绿色部分)。
幸好这样的复杂操作不需要算法工程师完成,都交给 MegEngine 好了。MegEngine 能做的事情远不止于此,只不过大多是像动态图显存优化这种技术一样,润物细无声地把用户的实际问题解决于无形。2020 年 3 月开源的 MegEngine 在以肉眼可见的速度快速成长,从静态计算图到动态计算图,再到持续提升的训练能力、移动端推理性能优化、动态显存优化…… 这也许就是开源的魅力。只有不断优化和创新,才能吸引和满足「挑剔」的开发者。MegEngine 下一个推出的功能会是什么?让我们拭目以待。双一流大学研究生团队创建,专注于目标检测与深度学习,希望可以将分享变成一种习惯!整理不易,点赞三连↓
