
Redis 集群操作实战
0x01:Redis 集群简介
Redis 是一个开源的 key-value 存储系统,由于出众的性能,大部分互联网企业都用来做服务器端缓存。Redis 在 3.0 版本前只支持单实例模式,虽然支持主从模式、哨兵模式部署来解决单点故障,但是互联网企业动辄大几百G的数据,可这些模式没法满足业务的需求,所以 Redis 在 3.0 版本以后就推出了集群模式。
Redis 集群采用了 P2P 的模式,完全去中心化。Redis 把所有的 Key 分成了 16384 个哈希槽(slot),每个 Redis 实例负责其中一部分 slot 。集群中的所有信息(节点、端口、slot等),都通过节点之间定期的数据交换而更新。
Redis 客户端可以在任意一个 Redis 实例发出请求,如果所需数据不在该实例中,通过重定向命令引导客户端访问所需的实例。
集群要点:
Redis 是一个开源的 key-value 存储系统,受到了广大互联网公司的青睐。Redis 3.0 版本之前只支持单例模式,在 3.0 版本及以后才支持集群;
Redis 集群采用 P2P 模式,是完全去中心化的,不存在中心节点或者代理节点;
Redis 集群是没有统一的入口的,客户端(client)连接集群的时候连接集群中的任意节点(node)即可,集群内部的节点是相互通信的(PING-PONG 机制),每个节点都是一个 Redis 实例;
为了实现集群的高可用,即判断节点是否健康(能否正常使用),redis-cluster 有这么一个投票容错机制:如果集群中超过半数的节点投票认为某个节点挂了,那么这个节点就挂了(fail)。这是判断节点是否挂了的算法;
如何判断集群是否挂了呢?
如果集群中任意一个节点挂了,而且该节点没有从节点(备份节点),那么这个集群就挂了。这是判断集群是否挂了的算法;
那么为什么任意一个节点挂了(没有从节点)这个集群就挂了呢?
因为集群内置了 16384 个 slot(哈希槽),并且把所有的物理节点映射到了这16384 [ 0-16383 ]个 slot 上,或者说把这些 slot 平均的分配给了各个节点。当需要在 Redi s集群存放一个数据(key-value)时,Redis 会先对这个 key 进行 crc16 算法,然后得到一个结果。再把这个结果对 16384 进行求余,这个余数会对应[ 0-16383 ]其中一个槽,进而决定 key-value 存储到哪个节点中。所以一旦某个节点挂了,该节点对应的 slot 就无法使用,那么就会导致集群无法正常工作。
0x02:环境说明
Redis 集群至少需要 3 个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以 2 个节点无法构成集群。
要保证集群的高可用,需要每个节点都有从节点,也就是备份节点,所以 Redis 集群至少需要 6 台服务器。因为没有那么多服务器,也无法在一台 widows 启动不了那么多虚拟机,所在这里搭建的是伪分布式集群,即一台服务器虚拟运行 6个 Redis 实例,修改端口号为(7001-7006),当然实际生产环境的Redis集群搭建和这里也是大同小异的。
安装 Ruby 环境
0x03:集群搭建
在搭建集群前,先了解单机的安装:Redis系列:Linux下部署Redis 6.x 版本。
在 /usr/local 目录下新建 redis-cluster 目录,用于存放集群节点的所有Redis 实例
mkdir /usr/local/redis-cluster
单机版安装的好的redis拷贝到 /usr/local/redis-cluster 目录
cp -r /usr/local/redis /usr/local/redis-cluster/
目录结构如下
基于该 Redis 复制出 6 个节点
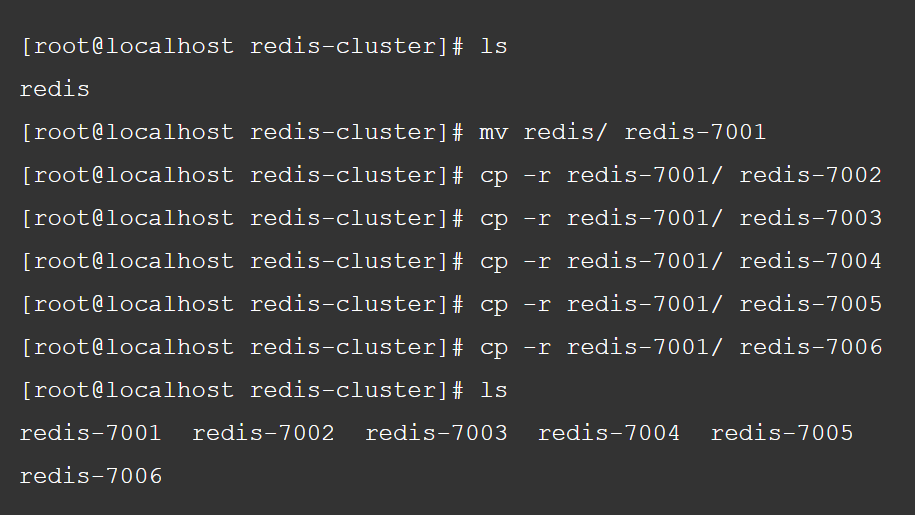
修改配置文件,主要配置点如下
bind 127.0.0.1 #绑定当前机器 IP
port 6379 #每个节点的端口号
daemonize no #是否后台启动
dir ./ #数据文件存放位置
dbfilename dump.rdb
pidfile /var/run/redis_6379.pid # pid 6379和port要对应
cluster-enabled yes #启动集群模式
cluster-config-file nodes-6379.conf # 6379和port要对应
cluster-node-timeout 15000 #集群节点超时时间
appendonly yes #是否启动 aof 模式
比如 7001 节点配置,主要是标识的地方有所不一致(其他节点请按照端口修改即可)
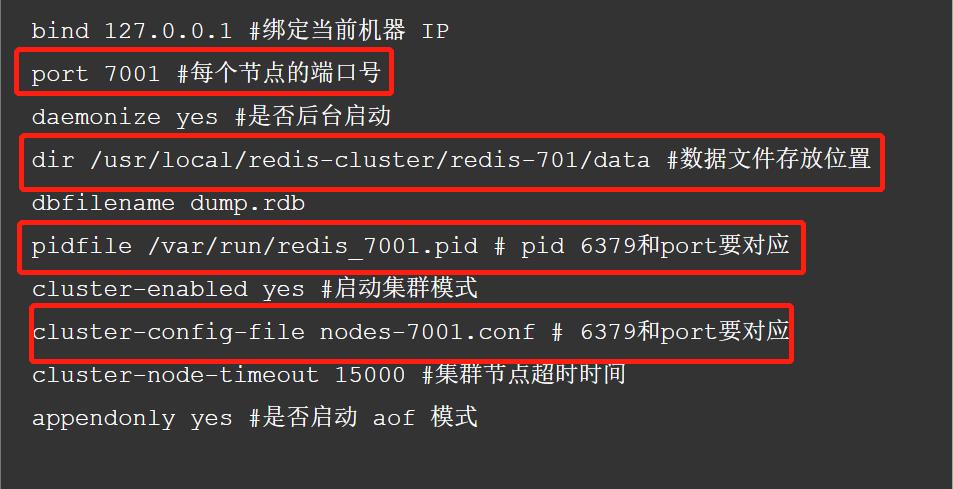
集群配置参数主要有:
cluster-enabled <yes/no>
cluster-config-file <filename>
cluster-node-timeout <milliseconds>
cluster-slave-validity-factor <factor>
cluster-migration-barrier <count>
cluster-require-full-coverage <yes/no>详细解释如下:
cluster-enabled <yes/no>: 该项如果设置成yes,该实例支持redis集群;否则该实例会像往常一样以独立模式启动。
cluster-config-file <filename>: 必须注意到尽管该项是可选的,这并不是一个用户可以编辑的配置文件,这是redis集群节点自动生成的配置文件,每次一旦配置有修改它都通过该配置文件来持久化配置(基本上都是状态),这样在下次启动的时候可以重新读取这些配置。该文件中列出了该集群中的其他节点的状态,持久化变量等信息。当节点收到一些信息的时候该文件就会被冲重写。
cluster-node-timeout <milliseconds>: redis集群节点的最大超时时间。响应超过这个时间的话该节点会被认为是挂掉了。如果一个master节点超过一定的时候无法访问,它会被它的slave取代。该参数在redis集群配置中很重要。很明显,当节点无法访问大部分master节点超过一定时间后,它会停止接受查询请求。
cluster-slave-validity-factor <factor>:如果将该项设置为0,不管slave节点和master节点间失联多久都会一直尝试failover(设为正数,失联大于一定时间(factor*节点TimeOut),不再进行FailOver)。比如,如果节点的timeout设置为5秒,该项设置为10,如果master跟slave之间失联超过50秒,slave不会去failover它的master(意思是不会去把master设置为挂起状态,并取代它)。注意:任意非0数值都有可能导致当master挂掉又没有slave去failover它,这样redis集群不可用。在这种情况下只有原来那个master重新回到集群中才能让集群恢复工作。
cluster-migration-barrier <count>: 一个master可以拥有的最小slave数量。该项的作用是,当一个master没有任何slave的时候,某些有富余slave的master节点,可以自动的分一个slave给它。具体参见手册中的replica migration章节
cluster-require-full-coverage <yes/no>: 如果该项设置为yes(默认就是yes) 当一定比例的键空间没有被覆盖到(就是某一部分的哈希槽没了,有可能是暂时挂了)集群就停止处理任何查询炒作。如果该项设置为no,那么就算请求中只有一部分的键可以被查到,一样可以查询(但是有可能会查不全)
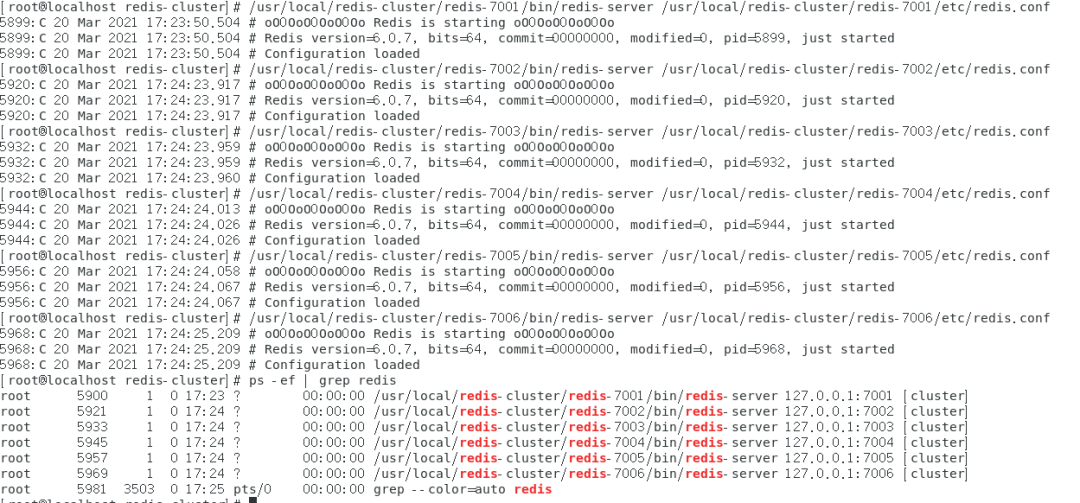
启动所有节点
/usr/local/redis-cluster/redis-7001/bin/redis-server /usr/local/redis-cluster/redis-7001/etc/redis.conf
/usr/local/redis-cluster/redis-7002/bin/redis-server /usr/local/redis-cluster/redis-7002/etc/redis.conf
/usr/local/redis-cluster/redis-7003/bin/redis-server /usr/local/redis-cluster/redis-7003/etc/redis.conf
/usr/local/redis-cluster/redis-7004/bin/redis-server /usr/local/redis-cluster/redis-7004/etc/redis.conf
/usr/local/redis-cluster/redis-7005/bin/redis-server /usr/local/redis-cluster/redis-7005/etc/redis.conf
/usr/local/redis-cluster/redis-7006/bin/redis-server /usr/local/redis-cluster/redis-7006/etc/redis.conf
启动结果如下
可以创建一个启动所有节点的 Shell 脚本 start-all.sh,然后授权 chmod +x start-all.sh,脚本的内容如下
/usr/local/redis-cluster/redis-7001/bin/redis-server /usr/local/redis-cluster/redis-7001/etc/redis.conf
/usr/local/redis-cluster/redis-7002/bin/redis-server /usr/local/redis-cluster/redis-7002/etc/redis.conf
/usr/local/redis-cluster/redis-7003/bin/redis-server /usr/local/redis-cluster/redis-7003/etc/redis.conf
/usr/local/redis-cluster/redis-7004/bin/redis-server /usr/local/redis-cluster/redis-7004/etc/redis.conf
/usr/local/redis-cluster/redis-7005/bin/redis-server /usr/local/redis-cluster/redis-7005/etc/redis.conf
/usr/local/redis-cluster/redis-7006/bin/redis-server /usr/local/redis-cluster/redis-7006/etc/redis.conf
测试
随便找一个接口测试一下,发现如下错误

虽然是连接成功了,但设置值时报错了???
(error) CLUSTERDOWN Hash slot not served(不提供集群的散列槽),这是什么鬼?这是因为虽然配置并启动了 Redis 集群服务,但是他们暂时还并不在一个集群中,互相直接发现不了,而且还没有可存储的位置,就是所谓的 slot(槽)。
0x04:安装集群所需软件
由于 Redis 集群需要使用 Ruby 命令,所以需要安装 Ruby 和相关软件包。
yum install ruby
yum install rubygems
gem install redis
因为 CentOS 系统自带的 ruby 版本为 2.0.0,所以执行最后一条命令出现以下错误:
[root@localhost bin]# gem install redis
Fetching: redis-4.2.5.gem (100%)
ERROR: Error installing redis:
redis requires Ruby version >= 2.3.0.
卸载系统自带 Ruby,安装 ruby 2.3.0版本
# yum remove ruby
# yum install centos-release-scl-rh //会在/etc/yum.repos.d/目录下多出一个CentOS-SCLo-scl-rh.repo源
# yum install rh-ruby23 -y //直接yum安装即可
# scl enable rh-ruby23 bash //必要一步
# ruby -v
安装完 ruby 2.3.0 版本后在执行如下命令
yum install rubygems
gem install redis
0x05:创建集群
在单机版的安装目录的 bin 目录下找到 redis-trib.rb 可执行命令。
/usr/local/redis-cluster/redis-7001/bin/redis-trib.rb create --replicas 1 \
127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
执行该命令发现出现如下错误

提示执行如下命令,说明 redis-trib.rb 命令已经至少6.0后版本被废弃了(具体哪个版本开始使用 redis-cli 可以去官网寻找下答案),可以推断 Ruby 环境的搭建有点多余了。
/usr/local/redis-cluster/redis-7001/bin/redis-cli --cluster create \
127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
执行命令后输入如下信息
[root@localhost redis-cluster]# /usr/local/redis-cluster/redis-7001/bin/redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 127.0.0.1:7005 to 127.0.0.1:7001
Adding replica 127.0.0.1:7006 to 127.0.0.1:7002
Adding replica 127.0.0.1:7004 to 127.0.0.1:7003
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: 35059b475861367c728e38cb6219285c8ee690ce 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
M: bd8901584958443a44e97455bf2a0e6be6d9cd2a 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
M: 4d9bf1375da15ba3a42ec36da38d7d4d4efc99a8 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
S: f7df7df06237243c6604db6ba91f18bc0d1e8960 127.0.0.1:7004
replicates 4d9bf1375da15ba3a42ec36da38d7d4d4efc99a8
S: cdac10f680eb00164360f0a9dbe38263db089fe7 127.0.0.1:7005
replicates 35059b475861367c728e38cb6219285c8ee690ce
S: b2f8a3586e5ffa2d9037cc0b1226b5b0a003ec62 127.0.0.1:7006
replicates bd8901584958443a44e97455bf2a0e6be6d9cd2a
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
>>> Performing Cluster Check (using node 127.0.0.1:7001)
M: 35059b475861367c728e38cb6219285c8ee690ce 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: f7df7df06237243c6604db6ba91f18bc0d1e8960 127.0.0.1:7004
slots: (0 slots) slave
replicates 4d9bf1375da15ba3a42ec36da38d7d4d4efc99a8
M: 4d9bf1375da15ba3a42ec36da38d7d4d4efc99a8 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: cdac10f680eb00164360f0a9dbe38263db089fe7 127.0.0.1:7005
slots: (0 slots) slave
replicates 35059b475861367c728e38cb6219285c8ee690ce
M: bd8901584958443a44e97455bf2a0e6be6d9cd2a 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: b2f8a3586e5ffa2d9037cc0b1226b5b0a003ec62 127.0.0.1:7006
slots: (0 slots) slave
replicates bd8901584958443a44e97455bf2a0e6be6d9cd2a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
至此,Redi集群搭建成功!大家注意最后一段信息
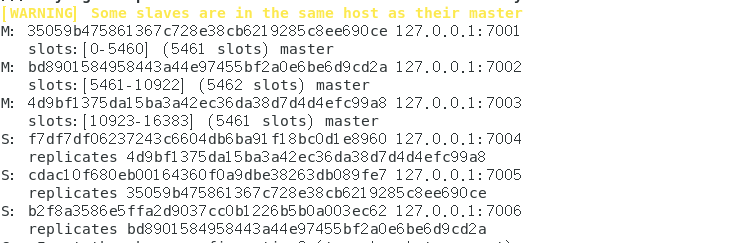
显示了每个节点所分配的 slots(哈希槽),这里总共6个节点,其中3个是从节点,所以3个主节点分别映射了0-5460、5461-10922、10933-16383 solts。
0x06:测试验证
连接集群节点,连接任意一个即可
bin/redis-cli -h 127.0.0.1 -p 7001 -c
注意:一定要加上 -c 参数,否则节点之间是无法自动跳转。如下图可以看到,存储的数据(key-value)被均匀分配到不同的节点。
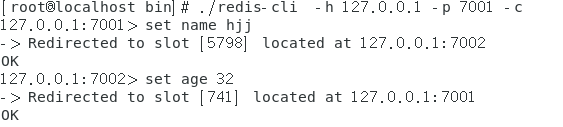
另外,如果没有加上 -c 参数,出现如下错误


喜欢,在看