
中国高考地狱级难度的省份,找到了

导读:一年一度的高考,可以说是广大学子必经的磨练,正所谓十年寒窗苦,一朝天下知。而高考,也成为了当前中国最为广泛,最为公平的晋升之路,可以说考上了一个名牌大学,那么未来的道路会好走很多。
01 考生人数
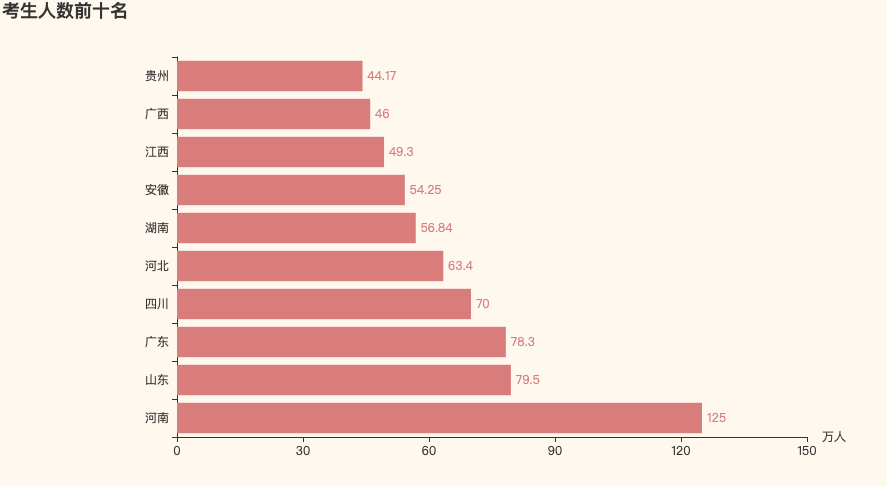
1. 考生人数前十名的省份
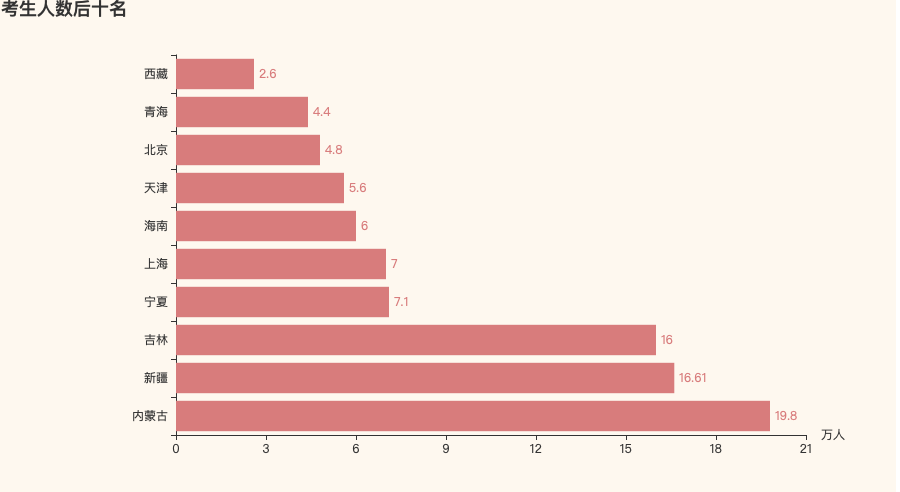
2. 考生人数后十名的省份
02 历年各省分数线
df = pd.DataFrame()
for i in range(1, 206):
test = "http://college.gaokao.com/areapoint/p%s/" % str(i)
print(test)
d = pd.read_html(test)[0]
df = pd.concat([df, d], axis=0, ignore_index=True)
benke = df[df["批次名称"].isin(['本科一批'])|df["批次名称"].isin(['本科批'])|df["批次名称"].isin(['本科'])|df["批次名称"].isin(['平行录取一段'])|df["批次名称"].isin(['普通类一段'])]
benke_2020 = benke[benke["年份"]==2020].drop_duplicates()
benke_2020_like = benke_2020[(benke_2020["文理分科"]=='理科')|(benke_2020["文理分科"]=='综合改革')]
benke_2020_like_wenke = benke_2020[(benke_2020["文理分科"]=='文科')|(benke_2020["文理分科"]=='综合改革')]
benke_2020_like_sort = benke_2020_like.sort_values(by=['最低控制分数线'], ascending=False)
benke_2020_like_sort_wenke = benke_2020_like_wenke.sort_values(by=['最低控制分数线'], ascending=False)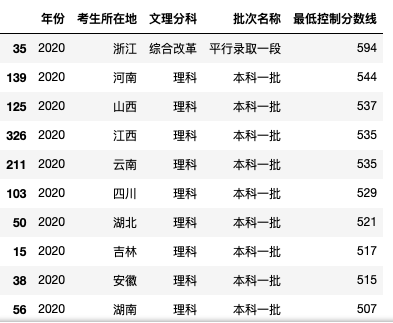
1. 2020理科一本分数前十
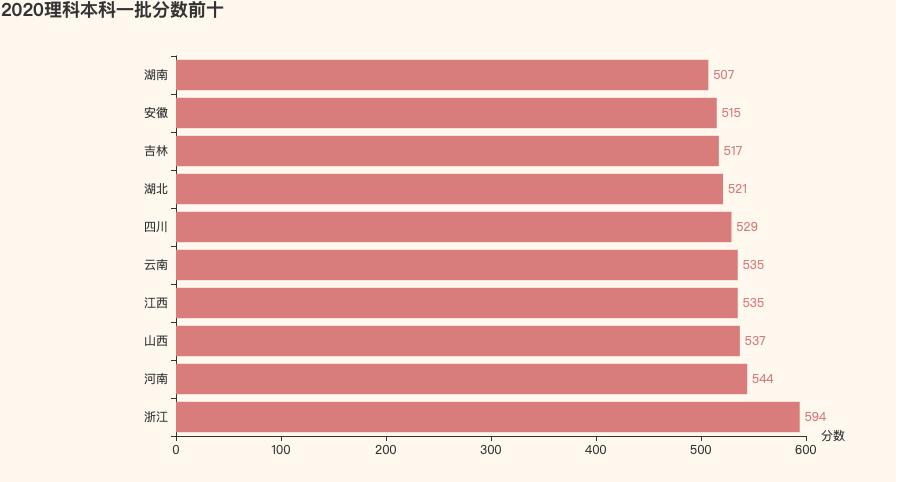
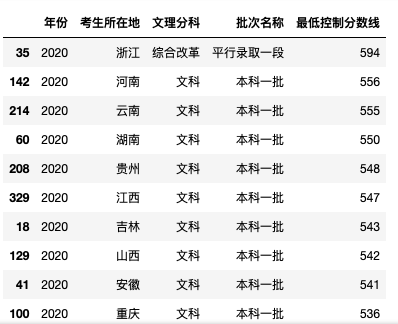
2. 2020文科一本分数前十
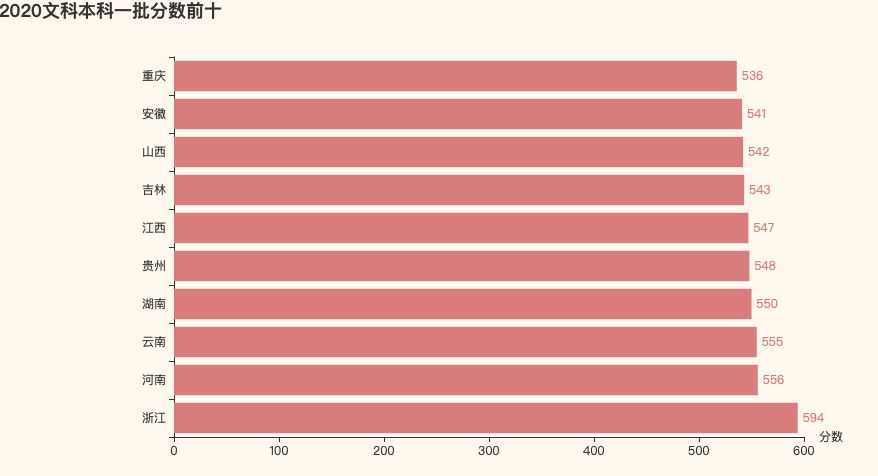
03 高质量高校
df = pd.read_csv("college_data.csv")
df_new = df.drop_duplicates(subset=['name']) # 有重复的数据,需要删除
df_site = df_new[df_new['site'] != '——']
df_site = df_site[df_site['site'] != '------']
# 高校总数量分析
site_counts = df_site['site'].value_counts()
dict_site = {'name': site_counts.index, 'counts': site_counts.values}
data = pd.DataFrame(dict_site)
b = (Bar()
.add_xaxis(data['name'].values.tolist()[:10])
.add_yaxis("", data['counts'].values.tolist()[:10])
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="各城市高校数量", subtitle=""),
# datazoom_opts=opts.DataZoomOpts(),
)
.set_series_opts()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()
1. 高校数量
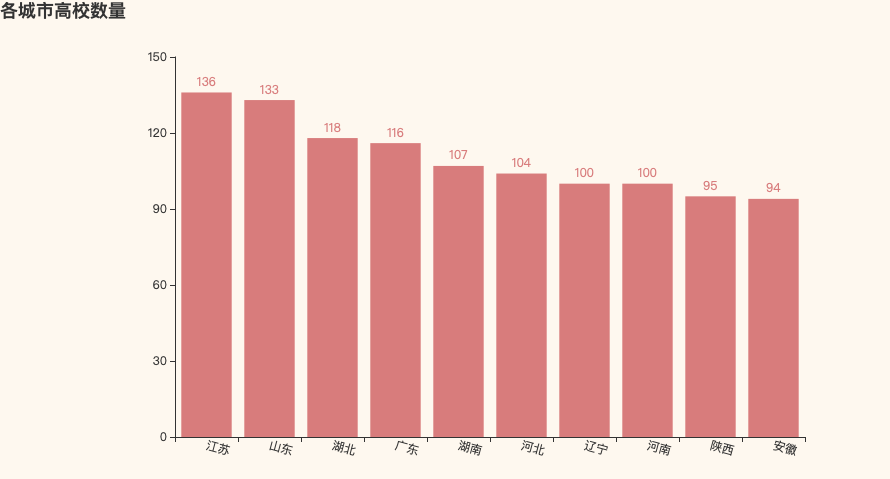
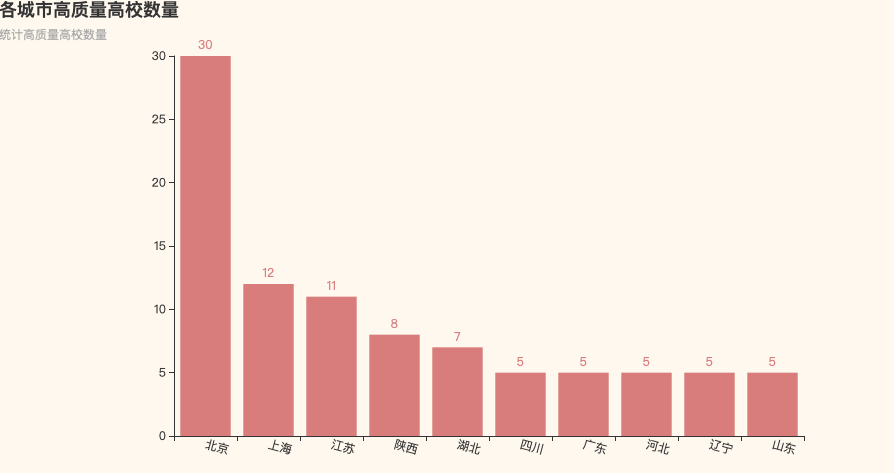
04 高考难度等级
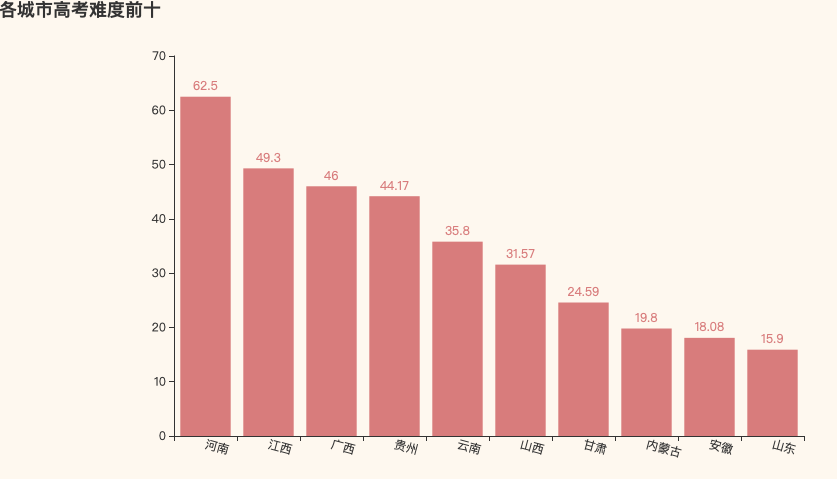
1. 高考难度前十名
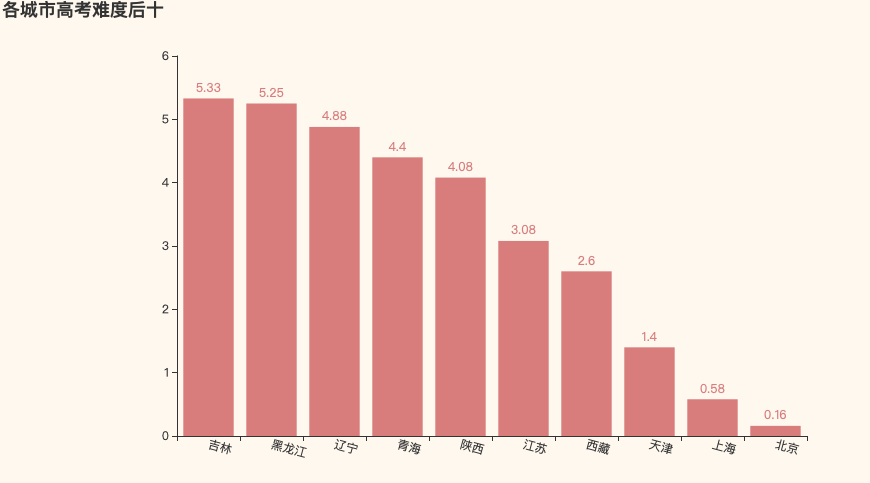
2. 高考难度后十名


评论