
高考结束,用 Python 来分析下哪里的高考是地狱级难度

一年一度的高考,可以说是广大学子必经的磨练,正所谓十年寒窗苦,一朝天下知。而高考,也成为了当前中国最为广泛,最为公平的晋升之路,可以说考上了一个名牌大学,那么未来的道路会好走很多。
但是又由于我国幅员辽阔,各地的教育资源又不尽相同,从而导致不同省份的升学难度也不尽相同。有的地方的高考属于优惠模式,而有的省份的高考竞争,又可以称得上是地狱模式。下面我们就通过一组数据来具体看一下
考生人数
高考的升学难不难,一个较为直观的因素就是内部竞争压力大不大,那么每个省份的考生人数就很关键了。
考生人数前十名的省份
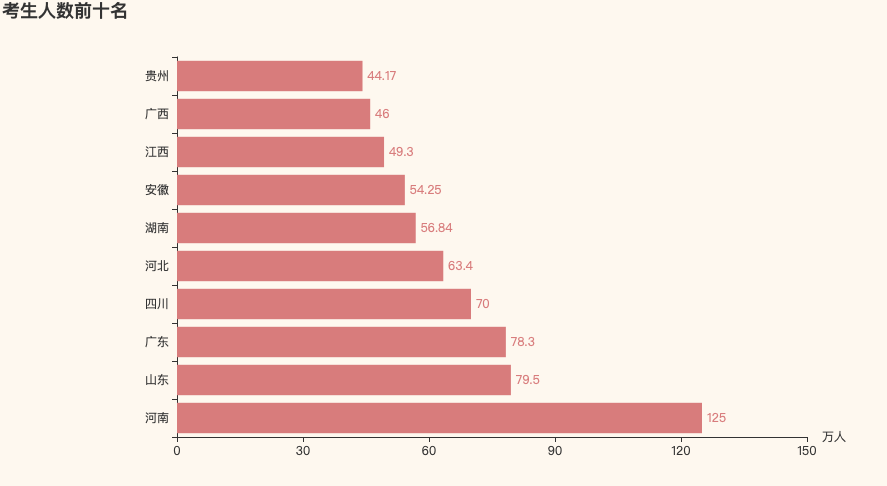
从上图可以看出,河南的考生人数远远超过其他省份,而且听说复读生占据了3成的比例,这个内卷太严重了
山东、广东和四川的考生也超过了70万人,内部竞争压力也应该很大
考生人数后十名的省份
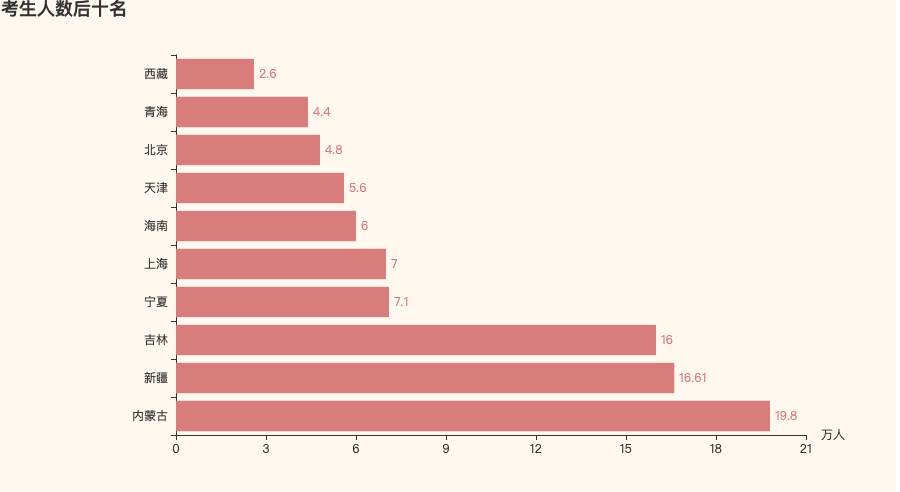
在后十名当中,三个直辖市都上榜了,毕竟面积小,人口相对也少。还有就是大西北的新疆,宁夏,内蒙等,当然还有青藏双姝西藏和青海。
在这些省份当中,除了三个直辖市以外,其他省份的教育资源都不是特别好,那么可以想象的到,即使内部压力不大,但是在与其他省份,比如河南,山东等考试竞争的时候,还是会吃亏比较大的。
历年各省分数线
这里我们从下面的网站抓取了历年各省的分数线,先来横向对比下
http://college.gaokao.com/areapoint/p1/
抓取与数据处理部分代码
df = pd.DataFrame()
for i in range(1, 206):
test = "http://college.gaokao.com/areapoint/p%s/" % str(i)
print(test)
d = pd.read_html(test)[0]
df = pd.concat([df, d], axis=0, ignore_index=True)
benke = df[df["批次名称"].isin(['本科一批'])|df["批次名称"].isin(['本科批'])|df["批次名称"].isin(['本科'])|df["批次名称"].isin(['平行录取一段'])|df["批次名称"].isin(['普通类一段'])]
benke_2020 = benke[benke["年份"]==2020].drop_duplicates()
benke_2020_like = benke_2020[(benke_2020["文理分科"]=='理科')|(benke_2020["文理分科"]=='综合改革')]
benke_2020_like_wenke = benke_2020[(benke_2020["文理分科"]=='文科')|(benke_2020["文理分科"]=='综合改革')]
benke_2020_like_sort = benke_2020_like.sort_values(by=['最低控制分数线'], ascending=False)
benke_2020_like_sort_wenke = benke_2020_like_wenke.sort_values(by=['最低控制分数线'], ascending=False)
下面先来看下2021年,各省份的分数线情况
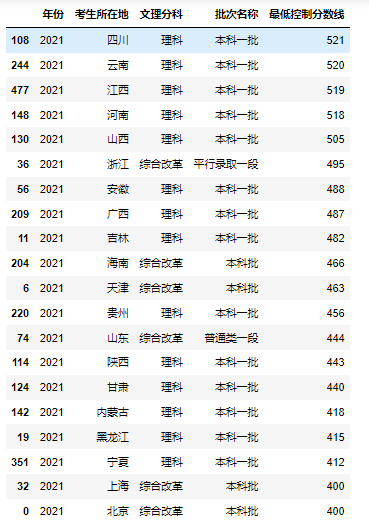
可以看到,一本理科分数线最高的为四川,高达521,这个数字好像不是特别高,因为我们似乎仍然记得2020年的最高分数线

接下来是文科比较
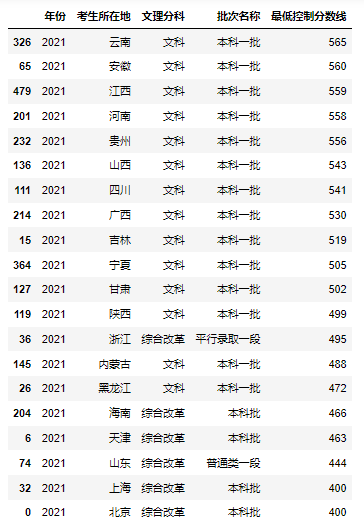
录取分数线最高的竟然是云南,而且高达565,不得不说,文科还是更卷啊!
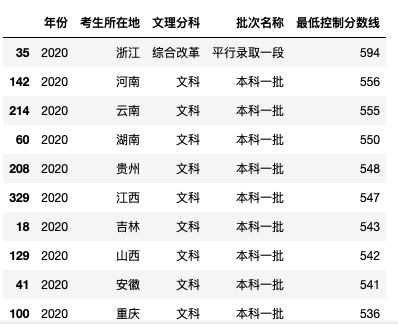
对比2020年,浙江则是最高的594,只能说浙江的同学们,太难了,也太厉害了!
当然了,河南的同学也不容易,双双第二名,苦着呢!
我们再通过图例来更加直观的看一下各省份的录取分数线
2020理科一本分数前十
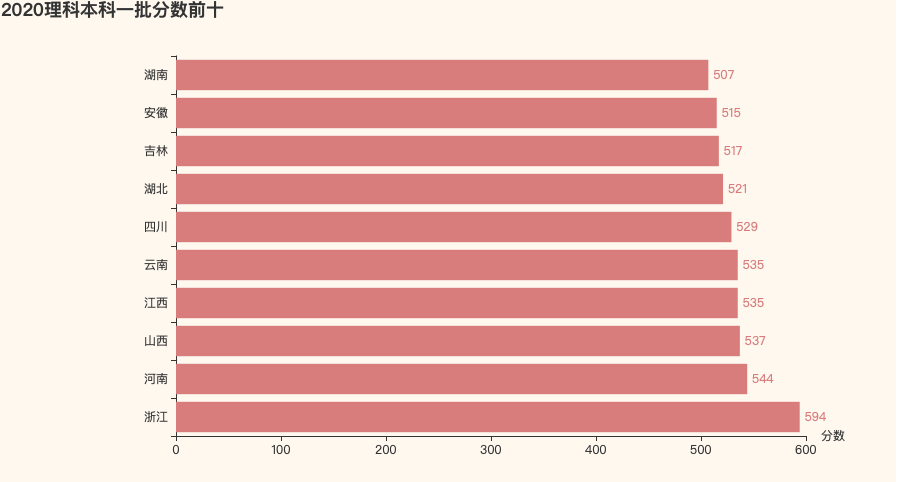
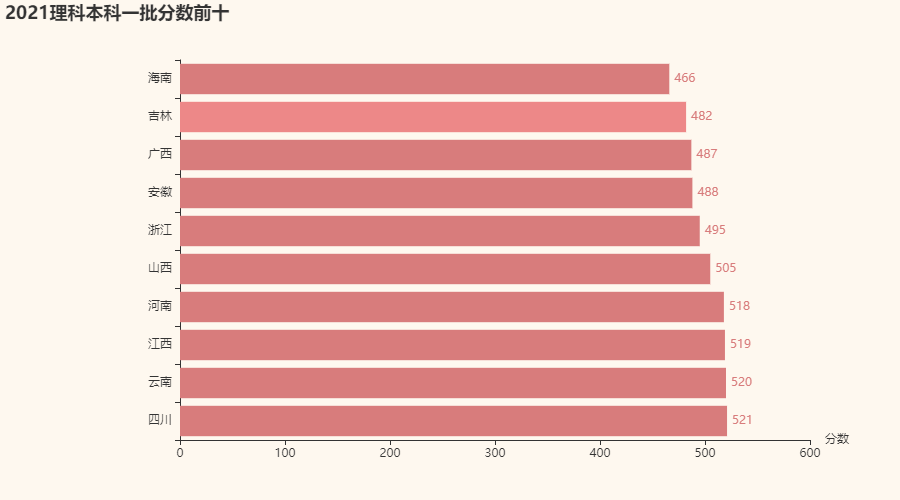
在2020年,前十名里,一本分数线都超过了500分,竞争压力还是很大的,而到了2021年,前十名里,不仅总体分数下降了,而且有五名都是500分以下,这是不是说明高中生们的压力没有那么大了呢~
2020文科一本分数前十
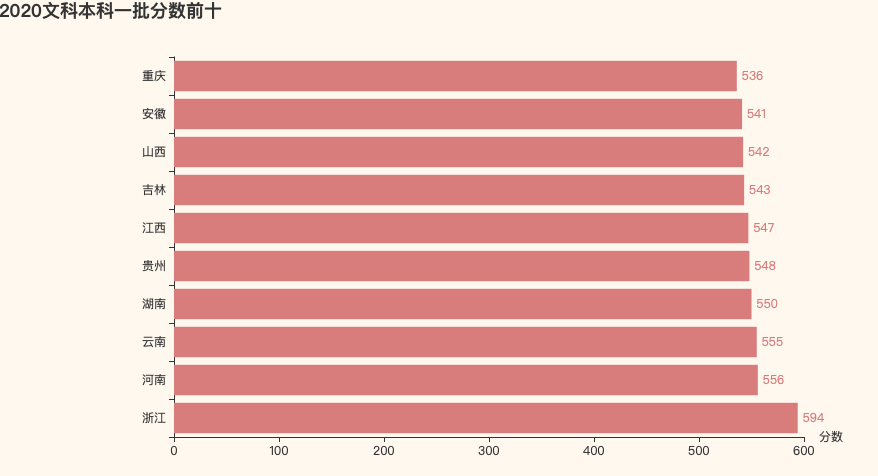
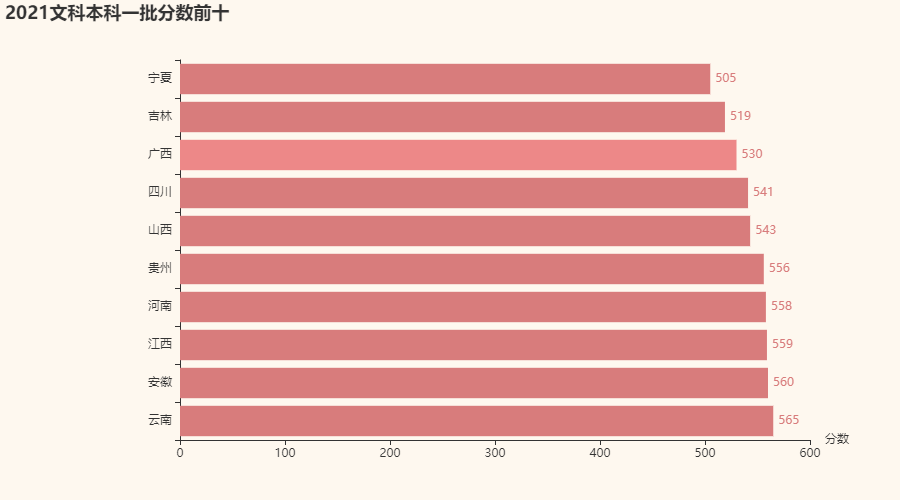
总体来说,文科想来要比理科的分数高,但是2021年还是比2020年要低了不少的
当然了,上面这些还不能很全面的反映一个省份的高考难易程度,我们再来看一下各个省份的高校情况
高质量高校
我这里提前获取了全国各省份的高校数据,下面先来看下各省高校数量情况
df = pd.read_csv("college_data.csv")
df_new = df.drop_duplicates(subset=['name']) # 有重复的数据,需要删除
df_site = df_new[df_new['site'] != '——']
df_site = df_site[df_site['site'] != '------']
# 高校总数量分析
site_counts = df_site['site'].value_counts()
dict_site = {'name': site_counts.index, 'counts': site_counts.values}
data = pd.DataFrame(dict_site)
b = (Bar()
.add_xaxis(data['name'].values.tolist()[:10])
.add_yaxis("", data['counts'].values.tolist()[:10])
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
title_opts=opts.TitleOpts(title="各城市高校数量", subtitle=""),
# datazoom_opts=opts.DataZoomOpts(),
)
.set_series_opts()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()
上面进行了简单的数据处理,可以得到各省份的高校数量
高校数量
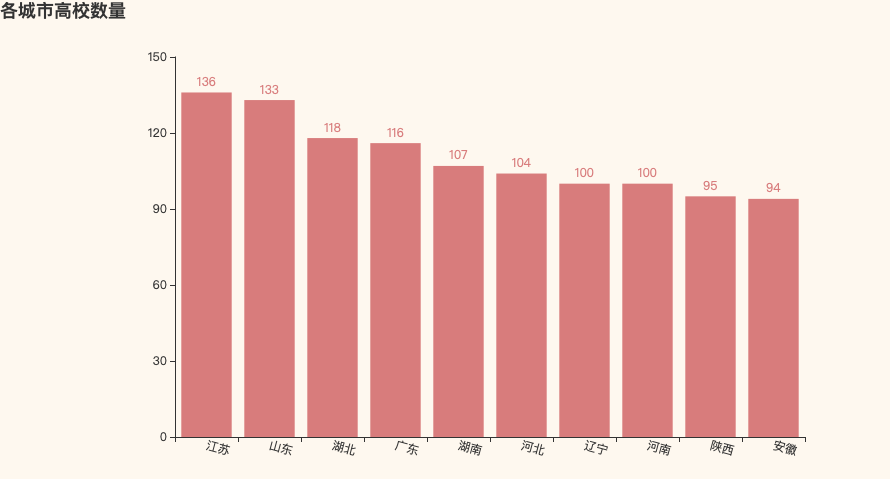
可以看到高校数量最多的是江苏,而号称高校重灾区的河南也赫然在榜
那么再来看下985&211数量情况呢
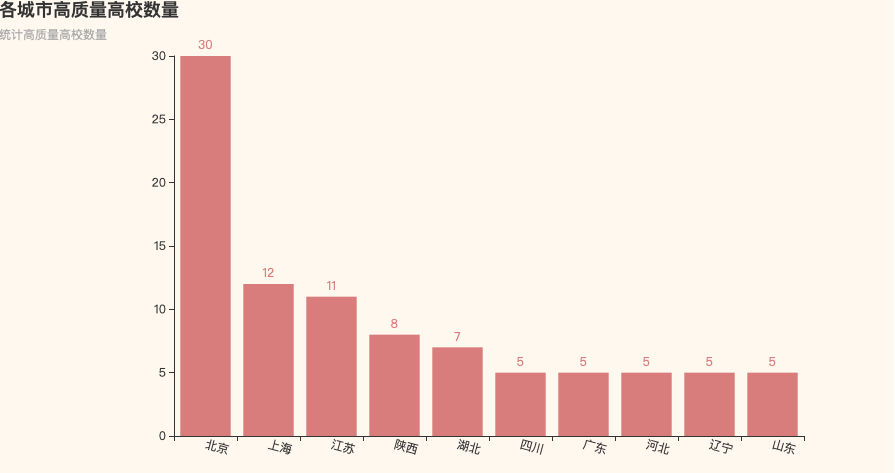
这下差距就明显了,北京太强了,独一份的存在!
河南已经不见了,郑州大学就是独苗!
高考难度等级
下面,我们来自己写一个规则,判定下各省份的高考难度情况
我们选择的参考变量为各省份的高质量院校数量和该省份的考生数量
公式为:(高质量院校/10)/(考生人数/10)
这里得到的数值就是每个省份的难易程度,数值越大,难度越高!
最终我们得到的数据大概如下,finally_par 就是最终的难度系数
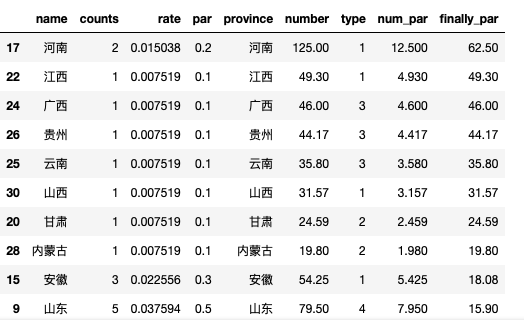
河南一马当先,这很河南啊
高考难度前十名
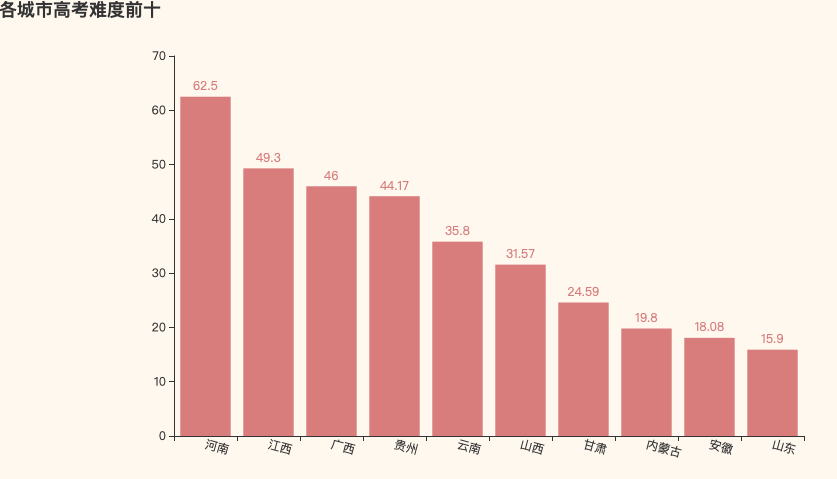
可以看到,我们通过上面的计算方式得出的难度系数之后,河南,江西,广西占据前三,不知道这三个地方的童鞋们是不是也是这种感受呢
高考难度后十名
对于后十名,相信很多同学都有自己的看法
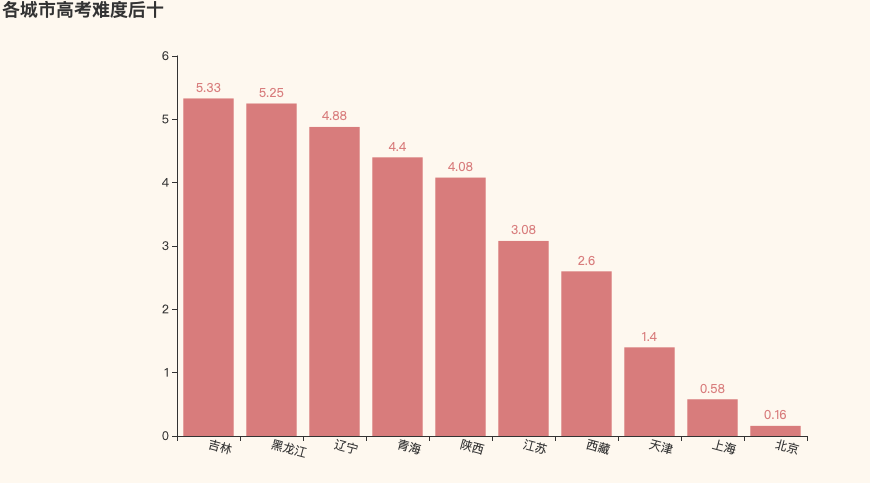
很明显,三大直辖市,人口少,高质量高校多,那么相对来说考上名牌大学的机会也自然多了
另外东三省也有幸上榜,人口少就是优势吗
高考难度地图分布
下面我们来看下高质量院校的分布与高考难度的分布情况
高质量院校分布热力图
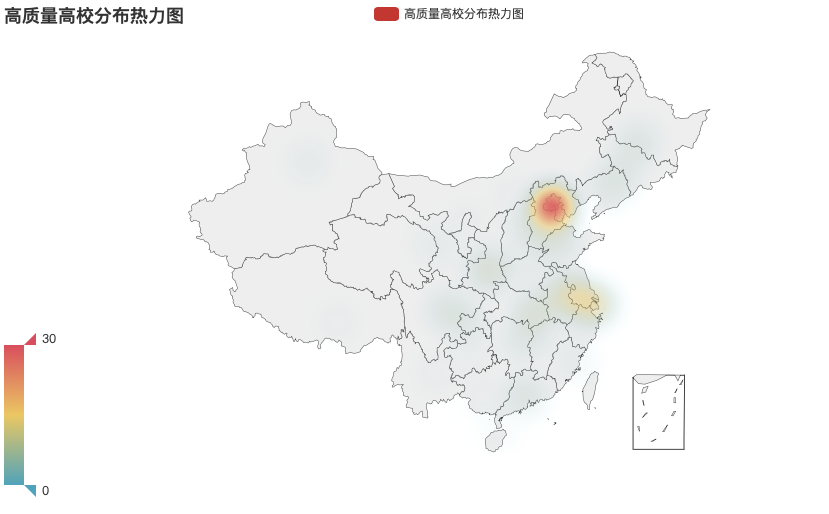
很明显,京津地区无可比拟
高考难度分布热力图
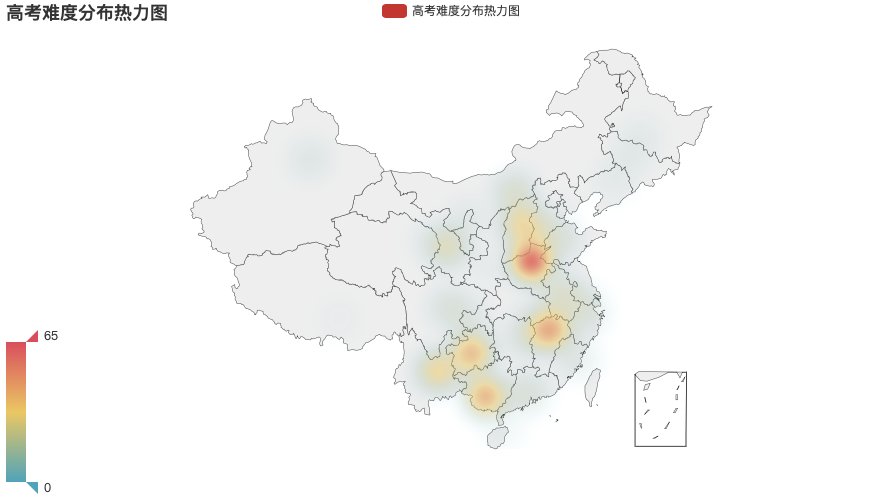
基本和高质量院校分布呈反向分布,看来建设高质量的高等学府才是出路呀!
最后再来看一张更加直观的地图分布
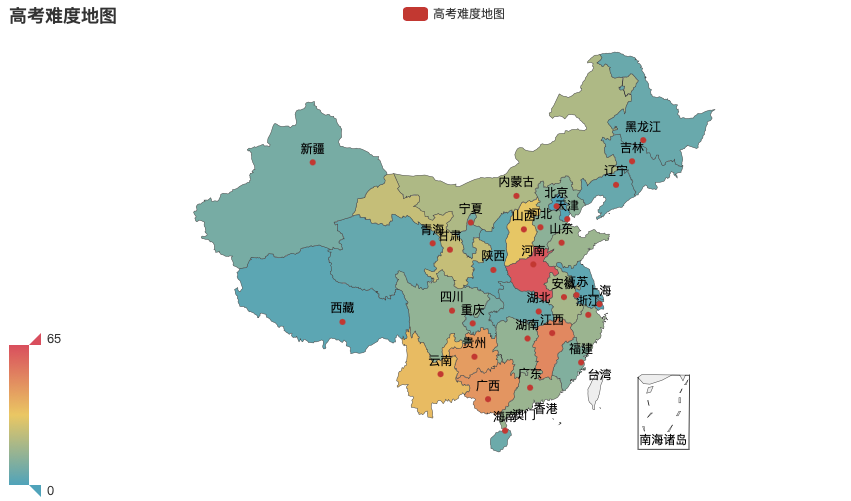
只想说一句,河南啊河南,你都红了!
好了,今天的分享就到这里,还不给个“在看”吗
获取源码,后台输入:高考
欢迎大家在留言区吱一声,说说你对高考的看法。
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|

年度爆款文案
点阅读原文,看B站我的20个视频!