
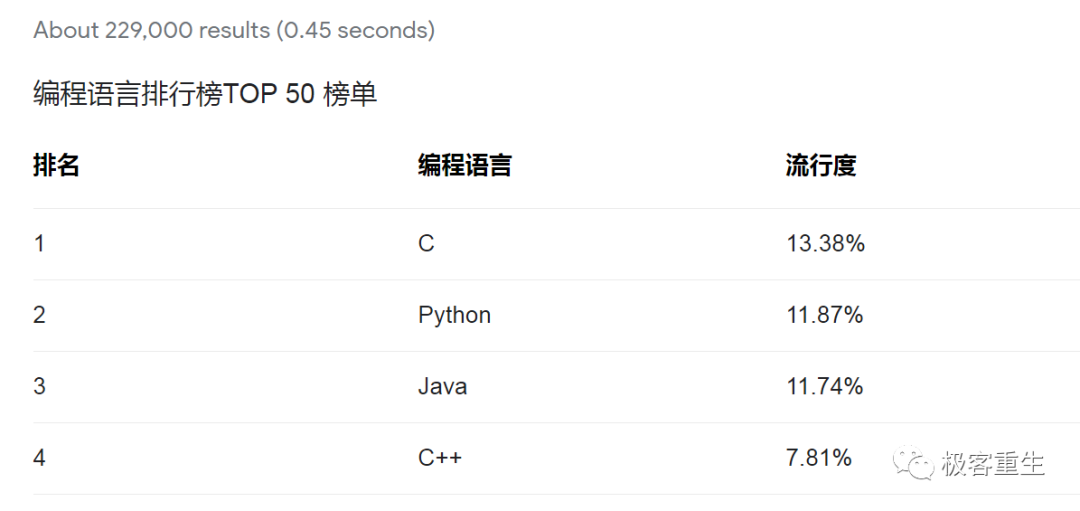
顶级C程序员之路

内存地址 big-endian little-endian
0x0001 0x34 0xab
0x0002 0xab 0x34
0x0003 0xcd 0x12
为了进行转换 bsd socket提供了转换的函数 有下面四个:
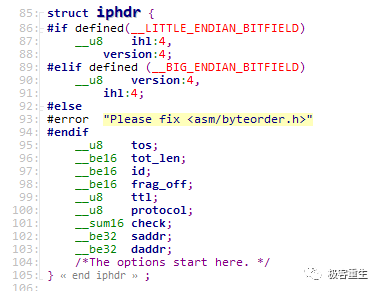
/* The host byte order is the same as network byte order,
so these functions are all just identity. */
# define ntohl(x) (x)
# define ntohs(x) (x)
# define htonl(x) (x)
# define htons(x) (x)
# else
# if __BYTE_ORDER == __LITTLE_ENDIAN
# define ntohl(x) __bswap_32 (x)
# define ntohs(x) __bswap_16 (x)
# define htonl(x) __bswap_32 (x)
# define htons(x) __bswap_16 (x)
# endif
# endif
htons 把unsigned short类型从主机序转换到网络序
htonl 把unsigned long类型从主机序转换到网络序
ntohs 把unsigned short类型从网络序转换到主机序
ntohl 把unsigned long类型从网络序转换到主机序
在使用little endian的系统中这些函数会把字节序进行转换, 在使用big endian类型的系统中这些函数会定义成空,什么都不做。
}
为什么不统一字节序?
不同处理器之间采用的字节序可能不同。
有些处理器的字节序是确定的,有些处理器的字节序是可配置的。
网络序一般统一为大端序。
数据从本地传输到网络,需要转换为网络序,接收到的网络数据需要转换为本地序后使用。
C提供了一组接口用于整型数据在本地序和网络序之间的转换。
多字节数据对象才需要转字节序,例如int,short等,而char不需要。
由于处理器是按照IEEE标准处理float和double的,因此也不需要转字节序。
由于Java虚拟机的存在,Java不需要考虑大小端的问题。
为什么要字节对齐
 ),不想看可以跳过这一节。
),不想看可以跳过这一节。



枚举始终占用4字节的空间。
char dda;
double dda1;
int type
char dda; A(1) = 1
double dda1; A(2) = 2
int type ; A(3) = 2
};
char a[8];
};
struct s2{
double d;
};
struct s3{
s1 s;
char a;
};
struct s4{
s2 s;
char a;
};
默认指定对齐值n = 8;
结构体成员合理安排位置,节省空间,提高性能
跨平台数据结构可考虑1字节对齐,节省空间,解析安全,影响访问效率
跨平台数据结构进行结构优化(对齐填充),提高访问效率,解析风险,不节省空间
本地数据采用chace对齐,提高访问效率
32位与64位默认对齐数不一样
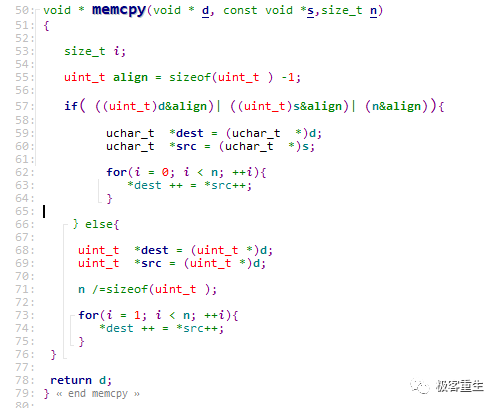
高通芯片平台的memcpy函数:



评论