
分析 kubernetes 中的事件机制
我们通过 kubectl describe [资源] 命令,可以在看到Event输出,并且经常依赖event进行问题定位,从event中可以分析整个POD的运行轨迹,为服务的客观测性提供数据来源,由此可见,event在Kubernetes中起着举足轻重的作用。

event并不只是kubelet中都有的,关于event的操作被封装在client-go/tools/record包,我们完全可以在写入自定义的event。
现在让我们来一步步揭开event的面纱。
Event定义
其实event也是一个资源对象,并且通过apiserver将event存储在etcd中,所以我们也可以通过 kubectl get event 命令查看对应的event对象。
以下是一个event的yaml文件:
apiVersion: v1
count: 1
eventTime: null
firstTimestamp: "2020-03-02T13:08:22Z"
involvedObject:
apiVersion: v1
kind: Pod
name: example-foo-d75d8587c-xsf64
namespace: default
resourceVersion: "429837"
uid: ce611c62-6c1a-4bd8-9029-136a1adf7de4
kind: Event
lastTimestamp: "2020-03-02T13:08:22Z"
message: Pod sandbox changed, it will be killed and re-created.
metadata:
creationTimestamp: "2020-03-02T13:08:30Z"
name: example-foo-d75d8587c-xsf64.15f87ea1df862b64
namespace: default
resourceVersion: "479466"
selfLink: /api/v1/namespaces/default/events/example-foo-d75d8587c-xsf64.15f87ea1df862b64
uid: 9fe6f72a-341d-4c49-960b-e185982d331a
reason: SandboxChanged
reportingComponent: ""
reportingInstance: ""
source:
component: kubelet
host: minikube
type: Normal
主要字段说明:
involvedObject:触发event的资源类型 lastTimestamp:最后一次触发的时间 message:事件说明 metadata :event的元信息,name,namespace等 reason:event的原因 source:上报事件的来源,比如kubelet中的某个节点 type:事件类型,Normal或Warning
event字段定义可以看这里:types.go#L5078
接下来我们来看看,整个event是如何下入的。
写入事件
1、这里以kubelet为例,看看是如何进行事件写入的
2、代码是在Kubernetes 1.17.3基础上进行分析
先以一幅图来看下整个的处理流程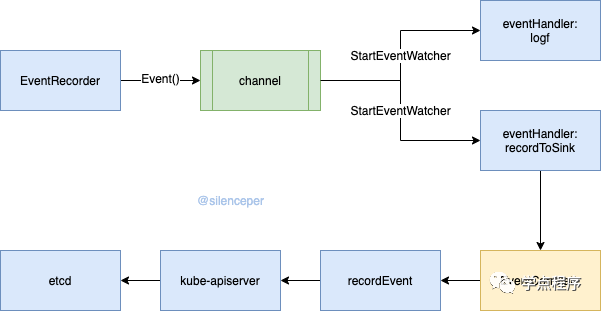
创建操作事件的客户端:
kubelet/app/server.go#L461
// makeEventRecorder sets up kubeDeps.Recorder if it's nil. It's a no-op otherwise.
func makeEventRecorder(kubeDeps *kubelet.Dependencies, nodeName types.NodeName) {
if kubeDeps.Recorder != nil {
return
}
//事件广播
eventBroadcaster := record.NewBroadcaster()
//创建EventRecorder
kubeDeps.Recorder = eventBroadcaster.NewRecorder(legacyscheme.Scheme, v1.EventSource{Component: componentKubelet, Host: string(nodeName)})
//发送event至log输出
eventBroadcaster.StartLogging(klog.V(3).Infof)
if kubeDeps.EventClient != nil {
klog.V(4).Infof("Sending events to api server.")
//发送event至apiserver
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: kubeDeps.EventClient.Events("")})
} else {
klog.Warning("No api server defined - no events will be sent to API server.")
}
}
通过 makeEventRecorder 创建了 EventRecorder 实例,这是一个事件广播器,通过它提供了StartLogging和StartRecordingToSink两个事件处理函数,分别将event发送给log和apiserver。NewRecorder创建了 EventRecorder 的实例,它提供了 Event ,Eventf 等方法供事件记录。
EventBroadcaster
我们来看下EventBroadcaster接口定义:event.go#L113
// EventBroadcaster knows how to receive events and send them to any EventSink, watcher, or log.
type EventBroadcaster interface {
//
StartEventWatcher(eventHandler func(*v1.Event)) watch.Interface
StartRecordingToSink(sink EventSink) watch.Interface
StartLogging(logf func(format string, args ...interface{})) watch.Interface
NewRecorder(scheme *runtime.Scheme, source v1.EventSource) EventRecorder
Shutdown()
}
具体实现是通过 eventBroadcasterImpl struct来实现了各个方法。
其中StartLogging 和 StartRecordingToSink 其实就是完成了对事件的消费,EventRecorder实现对事件的写入,中间通过channel实现了生产者消费者模型。
EventRecorder
我们先来看下EventRecorder 接口定义:event.go#L88,提供了以下4个方法
// EventRecorder knows how to record events on behalf of an EventSource.
type EventRecorder interface {
// Event constructs an event from the given information and puts it in the queue for sending.
// 'object' is the object this event is about. Event will make a reference-- or you may also
// pass a reference to the object directly.
// 'type' of this event, and can be one of Normal, Warning. New types could be added in future
// 'reason' is the reason this event is generated. 'reason' should be short and unique; it
// should be in UpperCamelCase format (starting with a capital letter). "reason" will be used
// to automate handling of events, so imagine people writing switch statements to handle them.
// You want to make that easy.
// 'message' is intended to be human readable.
//
// The resulting event will be created in the same namespace as the reference object.
Event(object runtime.Object, eventtype, reason, message string)
// Eventf is just like Event, but with Sprintf for the message field.
Eventf(object runtime.Object, eventtype, reason, messageFmt string, args ...interface{})
// PastEventf is just like Eventf, but with an option to specify the event's 'timestamp' field.
PastEventf(object runtime.Object, timestamp metav1.Time, eventtype, reason, messageFmt string, args ...interface{})
// AnnotatedEventf is just like eventf, but with annotations attached
AnnotatedEventf(object runtime.Object, annotations map[string]string, eventtype, reason, messageFmt string, args ...interface{})
}
主要参数说明:
object对应event资源定义中的involvedObjecteventtype对应event资源定义中的type,可选Normal,Warning.reason:事件原因message:事件消息
我们来看下当我们调用 Event(object runtime.Object, eventtype, reason, message string) 的整个过程。
发现最终都调用到了 generateEvent 方法:event.go#L316
func (recorder *recorderImpl) generateEvent(object runtime.Object, annotations map[string]string, timestamp metav1.Time, eventtype, reason, message string) {
.....
event := recorder.makeEvent(ref, annotations, eventtype, reason, message)
event.Source = recorder.source
go func() {
// NOTE: events should be a non-blocking operation
defer utilruntime.HandleCrash()
recorder.Action(watch.Added, event)
}()
}
最终事件在一个 goroutine 中通过调用 recorder.Action 进入处理,这里保证了每次调用event方法都是非阻塞的。
其中 makeEvent 的作用主要是构造了一个event对象,事件name根据InvolvedObject中的name加上时间戳生成:
注意看:对于一些非namespace资源产生的event,event的namespace是default
func (recorder *recorderImpl) makeEvent(ref *v1.ObjectReference, annotations map[string]string, eventtype, reason, message string) *v1.Event {
t := metav1.Time{Time: recorder.clock.Now()}
namespace := ref.Namespace
if namespace == "" {
namespace = metav1.NamespaceDefault
}
return &v1.Event{
ObjectMeta: metav1.ObjectMeta{
Name: fmt.Sprintf("%v.%x", ref.Name, t.UnixNano()),
Namespace: namespace,
Annotations: annotations,
},
InvolvedObject: *ref,
Reason: reason,
Message: message,
FirstTimestamp: t,
LastTimestamp: t,
Count: 1,
Type: eventtype,
}
}
进一步跟踪Action方法,apimachinery/blob/master/pkg/watch/mux.go#L188:23
// Action distributes the given event among all watchers.
func (m *Broadcaster) Action(action EventType, obj runtime.Object) {
m.incoming <- Event{action, obj}
}
将event写入到了一个channel里面。
注意:
这个Action方式是apimachinery包中的方法,因为实现的sturt recorderImpl
将 *watch.Broadcaster 作为一个匿名struct,并且在 NewRecorder 进行 Broadcaster 赋值,这个Broadcaster其实就是 eventBroadcasterImpl 中的Broadcaster。
到此,基本清楚了event最终被写入到了 Broadcaster 中的 incoming channel中,下面看下是怎么进行消费的。
消费事件
在 makeEventRecorder 调用的 StartLogging 和 StartRecordingToSink 其实就是完成了对事件的消费。
StartLogging直接将event输出到日志StartRecordingToSink将事件写入到apiserver
两个方法内部都调用了 StartEventWatcher 方法,并且传入一个 eventHandler 方法对event进行处理
func (e *eventBroadcasterImpl) StartEventWatcher(eventHandler func(*v1.Event)) watch.Interface {
watcher := e.Watch()
go func() {
defer utilruntime.HandleCrash()
for watchEvent := range watcher.ResultChan() {
event, ok := watchEvent.Object.(*v1.Event)
if !ok {
// This is all local, so there's no reason this should
// ever happen.
continue
}
eventHandler(event)
}
}()
return watcher
}
其中 watcher.ResultChan 方法就拿到了事件,这里是在一个goroutine中通过func (m *Broadcaster) loop() ==>func (m *Broadcaster) distribute(event Event) 方法调用将event又写入了broadcasterWatcher.result
主要看下 StartRecordingToSink 提供的的eventHandler, recordToSink 方法:
func recordToSink(sink EventSink, event *v1.Event, eventCorrelator *EventCorrelator, sleepDuration time.Duration) {
// Make a copy before modification, because there could be multiple listeners.
// Events are safe to copy like this.
eventCopy := *event
event = &eventCopy
result, err := eventCorrelator.EventCorrelate(event)
if err != nil {
utilruntime.HandleError(err)
}
if result.Skip {
return
}
tries := 0
for {
if recordEvent(sink, result.Event, result.Patch, result.Event.Count > 1, eventCorrelator) {
break
}
tries++
if tries >= maxTriesPerEvent {
klog.Errorf("Unable to write event '%#v' (retry limit exceeded!)", event)
break
}
// Randomize the first sleep so that various clients won't all be
// synced up if the master goes down.
// 第一次重试增加随机性,防止 apiserver 重启的时候所有的事件都在同一时间发送事件
if tries == 1 {
time.Sleep(time.Duration(float64(sleepDuration) * rand.Float64()))
} else {
time.Sleep(sleepDuration)
}
}
}
其中event被经过了一个 eventCorrelator.EventCorrelate(event) 方法做预处理,主要是聚合相同的事件(避免产生的事件过多,增加 etcd 和 apiserver 的压力,也会导致查看 pod 事件很不清晰)
下面一个for循环就是在进行重试,最大重试次数是12次,调用 recordEvent 方法才真正将event写入到了apiserver。
事件处理
我们来看下EventCorrelate方法:
// EventCorrelate filters, aggregates, counts, and de-duplicates all incoming events
func (c *EventCorrelator) EventCorrelate(newEvent *v1.Event) (*EventCorrelateResult, error) {
if newEvent == nil {
return nil, fmt.Errorf("event is nil")
}
aggregateEvent, ckey := c.aggregator.EventAggregate(newEvent)
observedEvent, patch, err := c.logger.eventObserve(aggregateEvent, ckey)
if c.filterFunc(observedEvent) {
return &EventCorrelateResult{Skip: true}, nil
}
return &EventCorrelateResult{Event: observedEvent, Patch: patch}, err
}
分别调用了 aggregator.EventAggregate ,logger.eventObserve , filterFunc 三个方法,分别作用是:
aggregator.EventAggregate:聚合event,如果在最近 10 分钟出现过 10 个相似的事件(除了 message 和时间戳之外其他关键字段都相同的事件),aggregator 会把它们的 message 设置为(combined from similar events)+event.Messagelogger.eventObserve:它会把相同的事件以及包含aggregator被聚合了的相似的事件,通过增加Count字段来记录事件发生了多少次。filterFunc: 这里实现了一个基于令牌桶的限流算法,如果超过设定的速率则丢弃,保证了apiserver的安全。
我们主要来看下aggregator.EventAggregate方法:
func (e *EventAggregator) EventAggregate(newEvent *v1.Event) (*v1.Event, string) {
now := metav1.NewTime(e.clock.Now())
var record aggregateRecord
// eventKey is the full cache key for this event
//eventKey 是将除了时间戳外所有字段结合在一起
eventKey := getEventKey(newEvent)
// aggregateKey is for the aggregate event, if one is needed.
//aggregateKey 是除了message和时间戳外的字段结合在一起,localKey 是message
aggregateKey, localKey := e.keyFunc(newEvent)
// Do we have a record of similar events in our cache?
e.Lock()
defer e.Unlock()
//从cache中根据aggregateKey查询是否存在,如果是相同或者相类似的事件会被放入cache中
value, found := e.cache.Get(aggregateKey)
if found {
record = value.(aggregateRecord)
}
//判断上次事件产生的时间是否超过10分钟,如何操作则重新生成一个localKeys集合(集合中存放message)
maxInterval := time.Duration(e.maxIntervalInSeconds) * time.Second
interval := now.Time.Sub(record.lastTimestamp.Time)
if interval > maxInterval {
record = aggregateRecord{localKeys: sets.NewString()}
}
// Write the new event into the aggregation record and put it on the cache
//将locakKey也就是message放入集合中,如果message相同就是覆盖了
record.localKeys.Insert(localKey)
record.lastTimestamp = now
e.cache.Add(aggregateKey, record)
// If we are not yet over the threshold for unique events, don't correlate them
//判断localKeys集合中存放的类似事件是否超过10个,
if uint(record.localKeys.Len()) < e.maxEvents {
return newEvent, eventKey
}
// do not grow our local key set any larger than max
record.localKeys.PopAny()
// create a new aggregate event, and return the aggregateKey as the cache key
// (so that it can be overwritten.)
eventCopy := &v1.Event{
ObjectMeta: metav1.ObjectMeta{
Name: fmt.Sprintf("%v.%x", newEvent.InvolvedObject.Name, now.UnixNano()),
Namespace: newEvent.Namespace,
},
Count: 1,
FirstTimestamp: now,
InvolvedObject: newEvent.InvolvedObject,
LastTimestamp: now,
//这里会对message加个前缀:(combined from similar events):
Message: e.messageFunc(newEvent),
Type: newEvent.Type,
Reason: newEvent.Reason,
Source: newEvent.Source,
}
return eventCopy, aggregateKey
}
aggregator.EventAggregate方法中其实就是判断了通过cache和localKeys判断事件是否相似,如果最近 10 分钟出现过 10 个相似的事件就合并并加上前缀,后续通过logger.eventObserve方法进行count累加,如果message也相同,肯定就是直接count++。
总结
好了,event处理的整个流程基本就是这样,我们可以概括一下,可以结合文中的图对比一起看下:
创建 EventRecorder对象,通过其提供的Event等方法,创建好event对象将创建出来的对象发送给 EventBroadcaster中的channel中EventBroadcaster通过后台运行的goroutine,从管道中取出事件,并广播给提前注册好的handler处理当输出log的handler收到事件就直接打印事件 当 EventSinkhandler收到处理事件就通过预处理之后将事件发送给apiserver其中预处理包含三个动作,1、限流 2、聚合 3、计数 apiserver收到事件处理之后就存储在etcd中
回顾event的整个流程,可以看到event并不是保证100%事件写入(从预处理的过程来看),这样做是为了后端服务etcd的可用性,因为event事件在整个集群中产生是非常频繁的,尤其在服务不稳定的时候,而相比Deployment,Pod等其他资源,又没那么的重要。所以这里做了个取舍。
参考文档:
https://cizixs.com/2017/06/22/kubelet-source-code-analysis-part4-event/ https://github.com/kubernetes/kubernetes/blob/v1.17.3/staging/src/k8s.io/client-go/tools/record
 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习