
Hudi 实践 | Linkflow 构建实时数据湖的生产实践
可变数据的处理一直以来都是大数据系统,尤其是实时系统的一大难点。在调研多种方案后,我们选择了 CDC to Hudi 的数据摄入方案,目前在生产环境可实现分钟级的数据实时性,希望本文所述对大家的生产实践有所启发。
1. 背景
Linkflow 作为客户数据平台(CDP),为企业提供从客户数据采集、分析到执行的运营闭环。每天都会通过一方数据采集端点(SDK)和三方数据源,如微信,微博等,收集大量的数据。这些数据都会经过清洗,计算,整合后写入存储。使用者可以通过灵活的报表或标签对持久化的数据进行分析和计算,结果又会作为MA (Marketing Automation) 系统的数据源,从而实现对特定人群的精准营销。
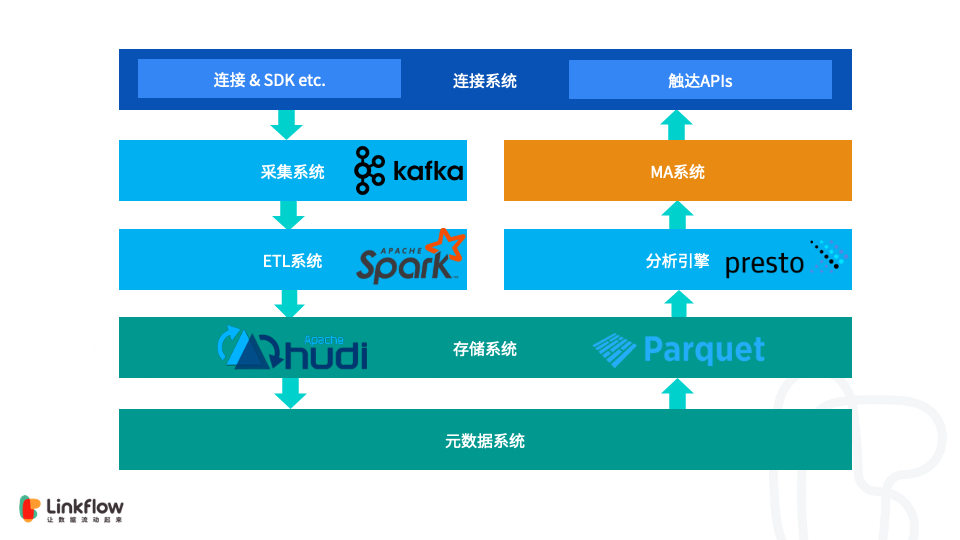
在 Linkflow 中,数据分为不可变数据(Immutable Data)和可变数据(Mutable Data),这些数据都会参与分析,涉及到的表大概有十几张,其中不可变数据的数据量较大,可以达到数十亿级。如果放到传统大数据系统,不可变数据即为事实数据,可变数据为维度数据。但在真正的业务实践里,用户的自然属性,订单的金额和状态等都是可更新的,这些数据的数据量往往也非常可观,在我们的系统里此类数据也会达到亿级。对于可变数据之前一直都是通过关系型数据库MySQL进行管理,一来数据维护方便,二来业务对接容易。
但问题也显而易见
•数据碎片化,由于 MySQL 大表 online DDL 风险较大,随着业务复杂度的提升,往往需要增加新的子表来扩展业务属性,也就是说一个完整的用户数据会散落在多张表中,这对查询十分不友好。•多维度查询无法实现,由于关系型数据库的优势不是多维度查询,并且给所有字段都加索引也并不现实,所以需要一款可支持OLAP查询引擎的数据组件来支撑多维分析的业务场景。并且考虑到未来可分别独立扩展的可能,我们也优先考虑计算和存储分离的架构。
2. CDC 和数据湖
CDC(CHANGE DATA CAPTURE)是一种软件设计模式,用于确定和跟踪已变更的数据,以便可以对更改后的数据采取措施。其实早在两年前我们就有使用 canal 冗余 MySQL 数据到异构存储的经验,只是当时没有意识到可以通过这种方式与大数据存储进行集成。在使用canal 的过程中我们发现了一些性能的问题,并且开源社区基本无人维护,所以在新架构启动前又调研了 Maxwell 和 Debezium,恰好关注到 Flink 母公司 Ververica 开源的项目 flink-cdc-connectors[1] ,该项目将 Debezium 作为 binlog 的同步引擎嵌入到 Flink 任务中,可以方便地在流任务中对 binlog 的消息进行筛选、校验、数据整合和格式转换,并且性能优异。考虑到未来又可以直接与行为数据进行双流 join,甚至通过 CEP 进行简单的风控,我们最终选择了 Debezium in Flink 的 CDC 方案。
由于MySQL中的数据主题很多,在流任务中我们同时也做了数据路由,即不同主题的变化数据会路由到不同的 Kafka Topic 中,即将 Kafka 作为 ODS。这样做的好处很多,首先对于可变数据我们可以清晰的观察到每次变化的过程,其次可以对数据进行回放,逐次变化的叠加结果便是最终的状态。
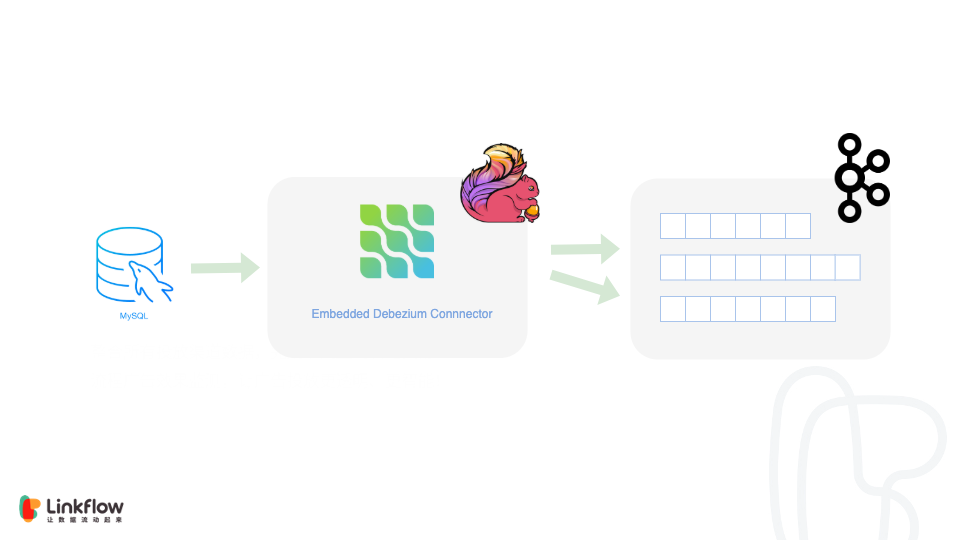
接下来要考虑的就是数据存在哪里,结合上文提到的“计算存储分离”原则, 这也是数据湖提供的一个优势,数据湖一般使用类似文件系统存储(对象存储或传统的HDFS)来构建,恰好符合我们的预期。在对比了几种数据湖方案后,我们选择了Apache Hudi,理由如下
•Hudi 提供了一个在 HDFS 中 upsert 的解决方案,即类似关系型数据库的使用体验,对于可更新数据非常友好,并且也符合 MySQL binlog 的语义。•增量查询,可以很方便的获取最近30分钟,或者1天内发生变化的数据,这对于一些可叠加的离线计算任务非常友好,不再需要针对全量数据进行计算,只需要针对变化数据进行计算,大大节省了机器资源和时间。•可以实时同步元数据到 Hive,为“入湖即可查”创造了条件。•对 COW 和 MOR 两种不同使用场景分别进行了优化。•Hudi社区开放且迭代速度快,在其孵化阶段就被AWS EMR集成,然后被阿里云DLA数据湖分析[2]、阿里云EMR[3]以及腾讯云EMR[4]集成,前景不错,同时ApacheHudi国内技术交流群讨论非常热烈,国内基于Hudi构建数据湖的公司越来越多。
在集成了 Hudi 后,我们的架构演化成这样
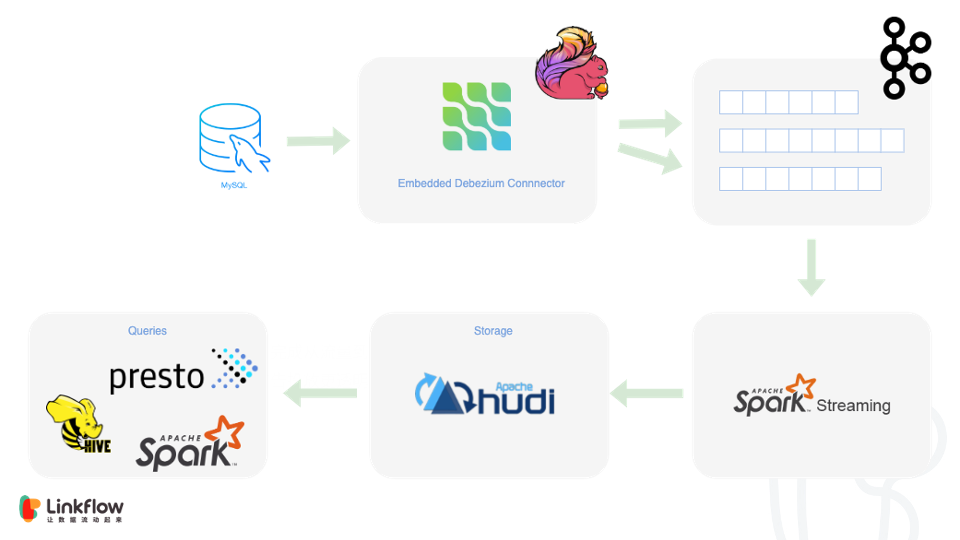
数据表都选择了 COW(写时复制)模式,主要是考虑到读多写少的特点,并且我们需要查询过程尽可能地快,MOR(读时合并)的策略在查询端的性能还是要稍微弱一些,再加上对于数据时延并没有到亚秒级的要求,所以最终选择了 COW。
最上层我们使用了 Presto 作为分析引擎,提供数据即席查询的能力。由于我们使用的 Hudi 版本是0.6.0,与 Flink 的集成还没有发布,所以我们不得不采用 Flink + Spark 双擎的策略,使用 Spark Streaming 将 Kafka 中的数据写入 Hudi。
3. 技术挑战
在进行了 PoC 后我们确定了上图所示的架构设计,但在真正的实现过程中,也遇到了不小的挑战。
3.1 CDC 运行模式定制
3.1.1 全量模式
Debezium 的一大优势就是“批流一体”,snapshot 阶段就是通过扫描全表将数据回放成与 binlog 增量日志内容一致的消息,这样使用者就可以使用相同的代码同时处理全量和增量数据。但是在我们的业务实践中,如果历史表的个数和表内的数据都很多,就会造成 snapshot 阶段持续的时间非常长,一旦这个过程出现意外中断,那么下次需要从第一张表开始重新扫描。假设完整的 snapshot 过程需要数天,那么这种规模的“重试”我们是无法接受的,所以需要有类似断点续传的机制,在查询了 Debezuim 官方文档后我们发现了 snapshot.include.collection.list 参数
An optional, comma-separated list of regular expressions that match names of schemas specified in
table.include.listfor which you want to take the snapshot.
所以可以在 snapshot 中断后,通过该参数传入剩余待扫描的表,从而实现“接力”的能力。但这里需要注意的一点是,无论 snapshot 阶段重试几次,增量的 binlog 位点都必须是首次 snapshot 时的位点,否则就会丢数据。这也带来了另一个问题,假如中断后再接力直到 snapshot 完成,Debezuim 是会自动开始从本次(而不是首次)snapshot 时的 binlog 位点直接开始增量同步数据,这不是我们需要的结果,我们需要 snapshot 结束后任务直接终止。
翻了很多 Debezuim 的文档并没有发现这样的功能,但是在翻阅源码的过程中看到其实是有办法的
/*** Perform a snapshot and then stop before attempting to read the binlog.*/INITIAL_ONLY("initial_only", true);// MySqlConnectorTask.javaif (taskContext.isInitialSnapshotOnly()) {logger.warn("This connector will only perform a snapshot, and will stop after that completes.");chainedReaderBuilder.addReader(new BlockingReader("blocker","Connector has completed all of its work but will continue in the running state. It can be shut down at any time."));chainedReaderBuilder.completionMessage("Connector configured to only perform snapshot, and snapshot completed successfully. Connector will terminate.");}
即在 initial_only 的模式下 Debezuim 会使用 BlockingReader 替代 BinlogReader 将线程阻塞,不再进行增量消费。
3.1.2 增量模式
如果 snapshot 结束后任务自动停止,那么就需要手动重启任务继续增量同步,同时增量模式需要支持指定 MySQL 的 binlog 文件和具体的位点(position)。Debezuim 自带 schema_only_recovery 模式,可以手动设置参数。
DebeziumOffset specificOffset = new DebeziumOffset();Map<String, Object> sourceOffset = new HashMap<>();sourceOffset.put("file", startupOptions.specificOffsetFile);sourceOffset.put("pos", startupOptions.specificOffsetPos);specificOffset.setSourceOffset(sourceOffset);
由于我们之前使用的 ververica/flink-cdc-connectors 版本是1.2.0,没有开放 Debezuim 的 schema_only_recovery 模式,所以修改了相关源码。目前1.3.0版本已支持,在 MySQLSourceBuilder 中作为启动参数传入即可。
3.2 部分更新(Patch Update)
这里有必要解释一下什么是覆盖更新什么是部分更新,这其实也对应于 RESTful 的语义,put 就是覆盖更新,要求调用方提供的一定是一个完整的资源对象,理论上说,如果用了 put,但却没有提供完整的资源对象,那么缺了的那些字段应该被清空。patch 对应部分更新,或局部更新,调用方只提供需要更新的字段,而不提供完整的资源对象,好处是可以节省带宽。
在 Hudi 中默认只支持覆盖更新,但对于我们业务而言,采集端点上报的数据不可能包含完整的业务对象,如用户年龄的增长,在上报时只会包含一个字段的信息
{"id": 123,"ts": 1435290195610,"data": {"age": 25}}
这就需要先找出 rowkey=123 的数据内容,并与待更新内容进行合并后再写入。合并时如果待写入数据的字段不为空,那么进行归并。Hudi默认采用 OverwriteWithLatestAvroPayload 的 combineAndGetUpdateValue 方法
Simply overwrites storage with latest delta record
为了向前兼容,数据开发同事 Karl 新增了 OverwriteNonDefaultsWithLatestAvroPayload 类,覆写了 combineAndGetUpdateValue 来处理上述问题,并已反馈给社区 [HUDI-1255] Add new Payload(OverwriteNonDefaultsWithLatestAvroPayload) for updating specified fields in storage[5] , 其实社区内类似需求还有很多,如 [HUDI-1160] Support update partial fields for CoW table[6], 我们也期待有更多的开发者可以将这个功能做的愈加完善。
当然这里也存在限制,如果真的希望将某个字段更新为空值,那么使用 OverwriteNonDefaultsWithLatestAvroPayload 是无法实现的。
同时我们也对社区的Compaction策略了补充,添加了基于时间的Compaction调度策略,即不仅仅可以基于增量提交数进行Compaction,还可以基于时间做Compaction,该工作也已经反馈给社区,参见[HUDI-1381] Schedule compaction based on time elapsed[7],这对于想要在指定时间内进行Compaction提供了更高的灵活性。
3.3 一批次内相同 rowkey 数据的归并
由于 CDC 的一个特征就是实时监听数据的变化,例如一个订单的状态在几分钟内可能就会发生若干次改变,再加上 Spark Streaming 微批处理的特点,有较大的概率会在一个时间窗口获取大量相同 rowkey 的数据,不同rowkey对应部分数据,因此我们在 Streaming 任务中对一批次相同 rowkey 的数据进行了归并,整体类似 Hudi 使用 Bloom 判断 rowkey 是否存在的逻辑。特别需要注意的是时序问题,数据的叠加必须严格按照 ts 时间,否则就会出现旧版本的数据覆盖新版本的情况。
3.4 Schema evolution
由于业务的发展以及灵活性的要求,表字段扩展(Schema evolution)一定是刚需。Hudi恰好也考虑到了这一点,我们从Hudi的 wiki[8] 上了解到
What's Hudi's schema evolution story
Hudi uses Avro as the internal canonical representation for records, primarily due to its nice schema compatibility & evolution[9] properties. This is a key aspect of having reliability in your ingestion or ETL pipelines. As long as the schema passed to Hudi (either explicitly in DeltaStreamer schema provider configs or implicitly by Spark Datasource's Dataset schemas) is backwards compatible (e.g no field deletes, only appending new fields to schema), Hudi will seamlessly handle read/write of old and new data and also keep the Hive schema up-to date.
既然Avro格式本身就支持 Schema evolution,自然地Hudi也支持。
Schema evolution 大致可以分为4种:
1.Backwards compatible: 向后兼容,用新的schema可以读取旧数据,如果字段没值,就用default值,这也是Hudi提供的兼容方式。2.Forwards compatible: 向前兼容,用旧schema可以读取新数据,Avro将忽略新加的字段,如果要向前兼容,删掉的字段必须要有默认值。3.Full compatible: 支持向前兼容,向后兼容,如果要全兼容,那么就需要只添加有默认值的字段,并且只移除有默认值的字段。4.No Compatibility Checking:这种情况一般来说就是需要强制改变某个字段的类型,此时就需要做全量的数据迁移,不推荐。
在生产实践中,我们通过修改 schema 就可以实现字段扩展的需求。但随之而来也会发现一些问题,比如字段过多会造成单个文件很大(突破128mb),写入很慢,极端情况下1000多列的文件写入会达到小时级别。后续我们也在寻找一些优化方案,例如字段回收或者垂直分表,将单文件内的字段数量降低。
3.5 同时查询和写入导致异常
这是出现在查询端的问题,我们使用 Presto 查询 Hive 表时会出现 Hudi 元数据文件找不到的异常,进而导致 Hudi 内部的 NPE
Error checking path :hdfs://hudipath/.hoodie_partition_metadata, under folder: hdfs://hudipath/event/202102; nested exception is java.sql.SQLException: Query failed (#20210309_031334_04606_fipir)基于上述信息,怀疑是在查询的同时,元数据信息被修改而导致的问题。在求助社区后,我们将 HoodieROTablePathFilter 中的 hoodiePathCache 改为线程安全的 ConcurrentHashMap, 重新打包得到 hudi-hadoop-mr.jar 和 hudi-common.jar ,替换到 presto/plugin/hive-hadoop2 的目录下,重启 Presto。后续没有发现NPE的情况。
4. 效果
再来回顾一下我们在架构之初对于数据湖的设想:
•支持可变数据•支持 schema evolution•计算存储分离,支持多种查询引擎•支持增量视图和时间旅行
这些特性 Hudi 基本都实现了,新架构完成后对比之前的系统,数据时延和离线处理性能都有了显著提升,具体表现在
1.实时数据写入过程简化,之前的更新操作实现繁琐,现在开发过程中基本不用关心是新增还是更新操作,大大降低了开发人员的心智负担。2.实时数据入湖到可查询的时间缩短,虽然我们的采用的是 COW 的表模式,但实际测试发现入湖到可查询的时效性并不低,基本都在分钟级。3.离线处理性能提升,基于 Hudi 的增量视图特性,每天的离线任务可以很容易的获取过去24h变化的数据,处理的数据量级变小,进而带来更短的处理时间。
5. 未来计划
5.1 Flink 集成
之前提到“迫不得已”的双擎策略,事实上是非常苦恼的,运维和开发方式都无法统一,所以我们对 Hudi 官方集成 Flink 的进展非常关注,并且近期也有了新的 RFC - 24: Hoodie Flink Writer Proposal[10] ,同时也已经在Hudi 0.8.0版本深度集成了Flink能力,期待未来的 Flink 集成版本在性能上可以有很大的提升,同时也可以将处理引擎统一成Flink,不再采用双引擎模式。
5.2 并发写
由于 Hudi 文件为了保证元数据的一致性,在0.8.0版本之前不支持并发写。但在实际应用中,数据湖中的很多数据不光是实时的数据,还有很多是需要通过离线计算获得的,假如某张表的一部分字段是 CDC 的直接反映,另一部分字段是离线任务的计算结果,这就会带来并发写的需求。
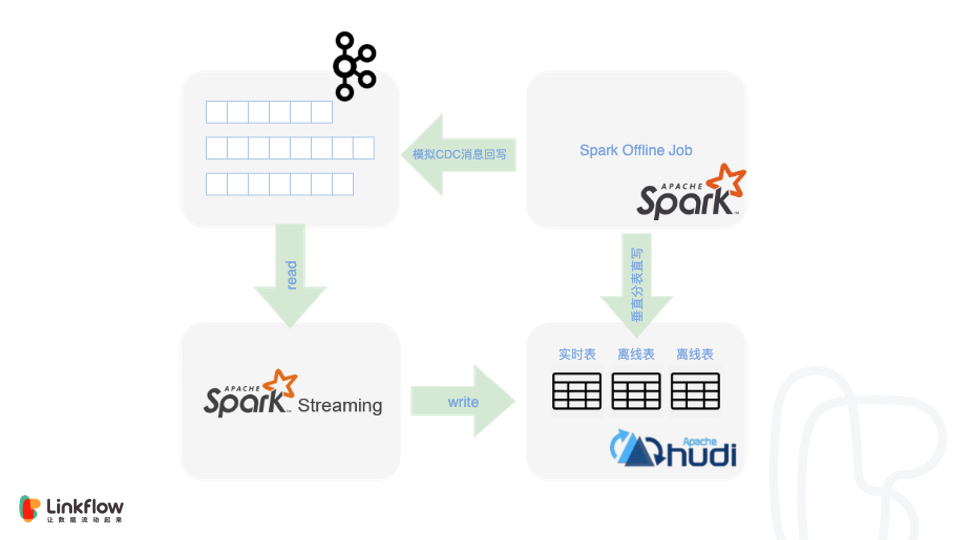
我们目前采用两种方式来规避
1.垂直分表,即将两部分文件分开,CDC 数据通过 Spark Streaming 写入,离线计算结果写入另一个文件,避免并发写。2.模拟成 CDC 消息回写 Kafka,为了查询性能不能分表的情况下,离线计算结果会模拟成 CDC 消息写入 Kafka,再通过 Spark Streaming 写入 Hudi。但缺点也是很明显的,就是离线任务的结果反映到最终存储的时延较长。
最近 Hudi 发布的0.8.0版本已经支持了并发写模式,其基于乐观锁,文件级别的冲突检测可很好的满足并发写需求,后续会测试看下效果。
5.3 性能优化
上文也提到了诸如大文件,GC频繁的一些问题,综合来看我们发现写入的瓶颈主要发生在两个地方
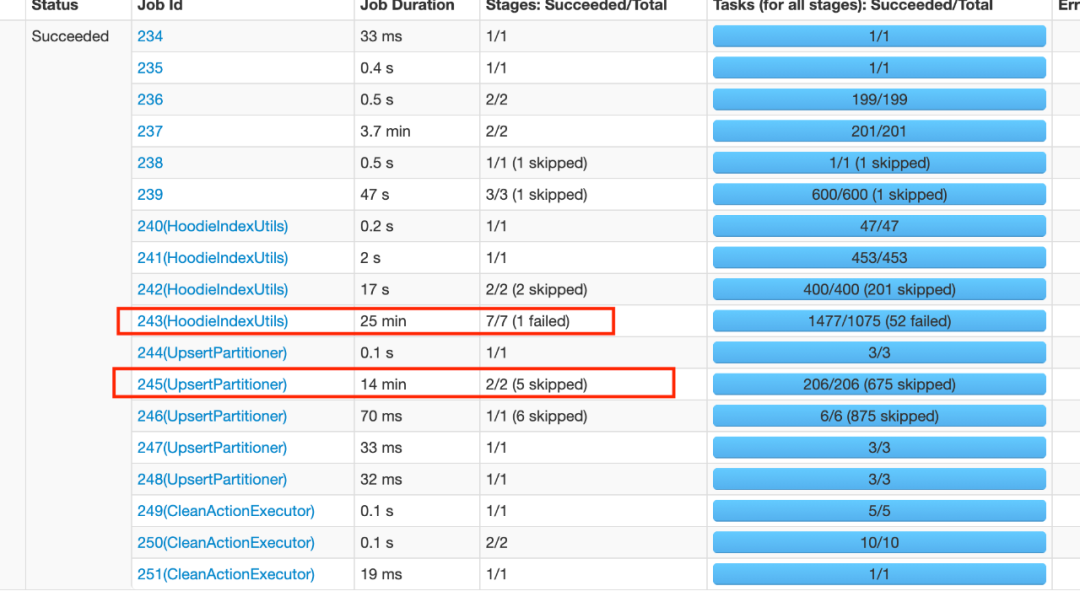
5.3.1 索引
由于目前我们采用 HoodieGlobalBloomIndex,导致建立索引和查询索引的时间都较长,官方提供了3种索引实现
How does the Hudi indexing work & what are its benefits?
The indexing component is a key part of the Hudi writing and it maps a given recordKey to a fileGroup inside Hudi consistently. This enables faster identification of the file groups that are affected/dirtied by a given write operation.
Hudi supports a few options for indexing as below
•
HoodieBloomIndex (default): Uses a bloom filter and ranges information placed in the footer of parquet/base files (and soon log files as well)•HoodieGlobalBloomIndex: The default indexing only enforces uniqueness of a key inside a single partition i.e the user is expected to know the partition under which a given record key is stored. This helps the indexing scale very well for even very large datasets[11]. However, in some cases, it might be necessary instead to do the de-duping/enforce uniqueness across all partitions and the global bloom index does exactly that. If this is used, incoming records are compared to files across the entire dataset and ensure a recordKey is only present in one partition.•HBaseIndex: Apache HBase is a key value store, typically found in close proximity to HDFS. You can also store the index inside HBase, which could be handy if you are already operating HBase.You can implement your own index if you'd like, by subclassing the
HoodieIndexclass and configuring the index class name in configs.
在与社区的讨论后,我们更倾向于使用HBaseIndex或类似的k-v store来管理索引。
5.3.2 更新
upsert 慢除了某些文件较大的问题,另一方面也与 CDC 的特点有关。可变数据的更新范围其实是不可预测的,极端情况下待更新的1000条数据属于1000个不同的文件时,更新的性能很难通过代码优化的方式提升,只能增加 cpu 资源提高处理并行度。我们会从几个方面着手:
1.参数调整,要是否有办法平衡文件的数量和大小2.尝试部分业务表使用 MOR 模式,MOR 在更新时会先将数据写入日志文件,之后再合并到 Parquet,理论上可以降低覆写 Parquet 文件的频率3.讨论业务上的 trade-off 来换取更好的写入速度
6. 总结
未来有待优化的工作还有很多,我们也会积极参与社区建设,尝试新的特性,为用户带来更好的数据服务体验,最后感谢 Flink CDC Connectors 和 Apache Hudi 的开发者和社区维护者。
作者Dean,Linkflow首席架构师
笔者数据团队招聘:如果有两年以上实时系统开发设计经验,一年以上Flink使用经验,热衷于技术,爱读源码,计算机基础扎实,Scala写的跟Java一样溜的,那很有可能你会是我们正在找的大数据工程师。简历投递到 ding.wang@linkflowtech.com[12],其他岗位详见 https://hr.lagou.com/company/gongsi/j188444.html
推荐阅读
Apache Hudi C位!云计算一哥AWS EMR 2020年度回顾
Apache Flink 1.12.2集成Hudi 0.9.0运行指南
引用链接
[1] flink-cdc-connectors: https://github.com/ververica/flink-cdc-connectors[2] 阿里云DLA数据湖分析: https://help.aliyun.com/document_detail/173653.html?spm=a2c4g.11186623.6.576.1562672dKa8RYR[3] 阿里云EMR: https://help.aliyun.com/document_detail/193310.html[4] 腾讯云EMR: https://cloud.tencent.com/document/product/589/42955[5] [HUDI-1255] Add new Payload(OverwriteNonDefaultsWithLatestAvroPayload) for updating specified fields in storage: https://github.com/apache/hudi/pull/2056[6] [HUDI-1160] Support update partial fields for CoW table: https://github.com/apache/hudi/pull/2666[7] [HUDI-1381] Schedule compaction based on time elapsed: https://github.com/apache/hudi/pull/2260[8] wiki: https://cwiki.apache.org/confluence/display/HUDI/FAQ[9] schema compatibility & evolution: https://docs.confluent.io/current/schema-registry/avro.html[10] RFC - 24: Hoodie Flink Writer Proposal: https://cwiki.apache.org/confluence/display/HUDI/RFC+-+24%3A+Hoodie+Flink+Writer+Proposal[11] very large datasets: https://eng.uber.com/uber-big-data-platform/[12] ding.wang@linkflowtech.com: mailto:ding.wang@linkflowtech.com