
CVPR 22 | 图像修复!中科大&微软提出PUT:减少Transformer在图像修复应用中的信息损失

极市导读
本文介绍一篇在CVPR 2022发表的用于图像修复的工作。该工作是基于当前流行的Transformer实现的,目的是减少Transformer在应用到图像修复过程中的一些信息损失,从而提升模型修复图片的质量。目前论文和代码都已经公开。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
 图1 本文方法和现有方法的一些对比结果
图1 本文方法和现有方法的一些对比结果

本文介绍我们在CVPR 2022发表的用于图像修复的工作。该工作是基于当前流行的Transformer实现的,目的是减少Transformer在应用到图像修复过程中的一些信息损失,从而提升模型修复图片的质量。目前论文和代码都已经公开,欢迎大家试用交流。
论文标题: Reduce Information Loss in Transformers for Pluralistic Image Inpainting
作者单位: 中国科学技术大学,微软云AI
录用信息: CVPR 2022
代码链接: https://github.com/liuqk3/PUT
论文链接: https://arxiv.org/pdf/2205.05076
一、针对问题
本文主要的任务是图像修复,即输入的图片是残缺的,通过算法根据提供的残缺图片来补全图片中残缺的部分。早期的一些工作所利用的模型,一般都是基于CNN实现的。由于CNN具有一定的位置偏置等因素,导致其修复的图片可视化效果并不理想。近两年,随着Transformer在计算机视觉领域的巨大成功,一些研究人员开始利用Transformer来进行图像修复,并取得了非常不错的效果。然而,通过对这些方法进行分析,发现这类方法普遍存在或多或少的信息损失,原因主要有两点:(1)对图片进行下采样。众所周知,Transformer的计算量与输入的序列长度呈平方关系。为了减少计算量,要保证输入Transformer的序列长度在可接受范围内。为此,现有方法会将图片进行下采样,比如从256x256下采样到32x32。这种下采样的方式不可避免地带来了信息损失;(2)量化。像素的个数是256^3,如果直接将每个像素(实际上是索引)都当作一个token,那么Transformer内部的embedding个数也是256^3,较多的embedding不仅带来了较多的参数,也不利于模型训练。因此现有方法会对像素进行聚类量化,比如从256^3个变成512个。量化的过程也会带来信息损失。
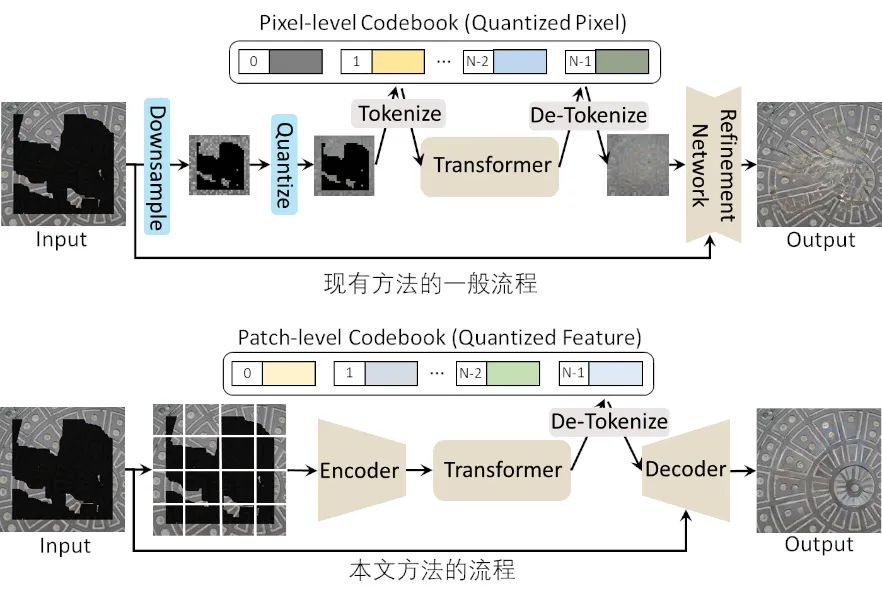
本文的方法旨在解决上述的问题。(1)利用auto-encoder代替下采样。auto-encoder中的encoder会将输入的图片分成独立的图片块,每块独立编码,避免信息交叉影响。Decoder负责从输入的量化的特征重构图片;(2)不量化。为了避免Transformer中的信息损失,输入到Transformer中的不是离散的token(即索引),而是encoder出来的特征。离散的token只用作Transformer的输出。图2对比了本文方法和现有方法的流程。
二、方法框架
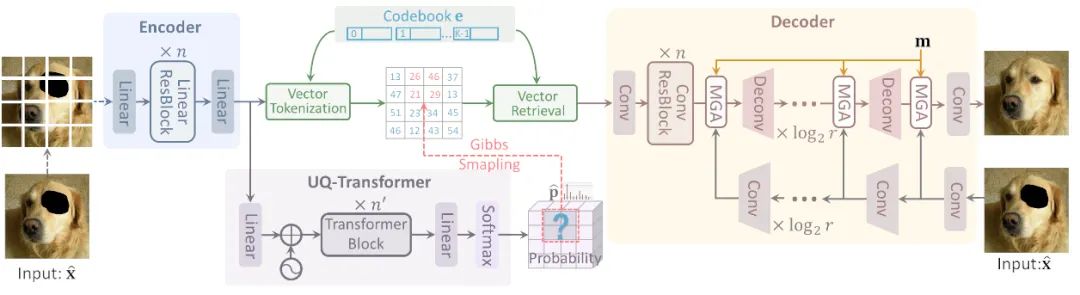
本文方法的具体流程如图3所示。整个算法包含两部分:auto-encoder和Transformer。其中auto-encoder是经过特殊设计,专门用于图像修复任务。Transformer也与现有的方法中的Transformer(如DALL-E, IGPT等)稍有不同。下面将分别进行介绍。
1. Auto-encoder
本文方法中的auto-encoder全称为Patch-based Vector Quantized Variational Auto-Encoder(P-VQVAE)。其encoder全部由全连接层构成。输入的残缺图片会被分成独立的图片块,每一块都单独经过encoder进行独立编码。不同的图片块缺失的像素个数也不同。独立编码避免了相互之间的干扰,利用提取更具有区分度的特征。
Encoder输出的特征经过域码本量化之后输入到decoder可以实现图像重构。Decoder是由conv层组成,其不同之处在于有一个参考分支。参考分支的输入就是提供的残缺图片,目的是保证残缺图片中已有的像素值保持不变。当参考分支不使用时,P-VQVAE可以实现和现有auto-encoder一样的作用,即图像重构。
P-VQVAE的训练和VQVAE基本一致,不过我们引入了其他的损失来提高其重构的性能,如引入判别器对抗训练等。
2. Transformer
本方法中的Transformer全称是Un-Quantized Transformer。它的输入是encoder输出的特征,而不是离散的token。这种做法的目的是避免量化引入信息损失。对于每个图片块,Transformer会输出一个概率,这个概率就是图片块对应码本中的特征的概率。在训练阶段,只需要一个简单测交叉熵损失即可。在测试阶段,只要图片块中的任意一个像素缺失,就会其对应概率进行采样,将从码本中采样得到特征向量作为该图片块的特征,并送入decoder用于图像重构。
三、实验结果
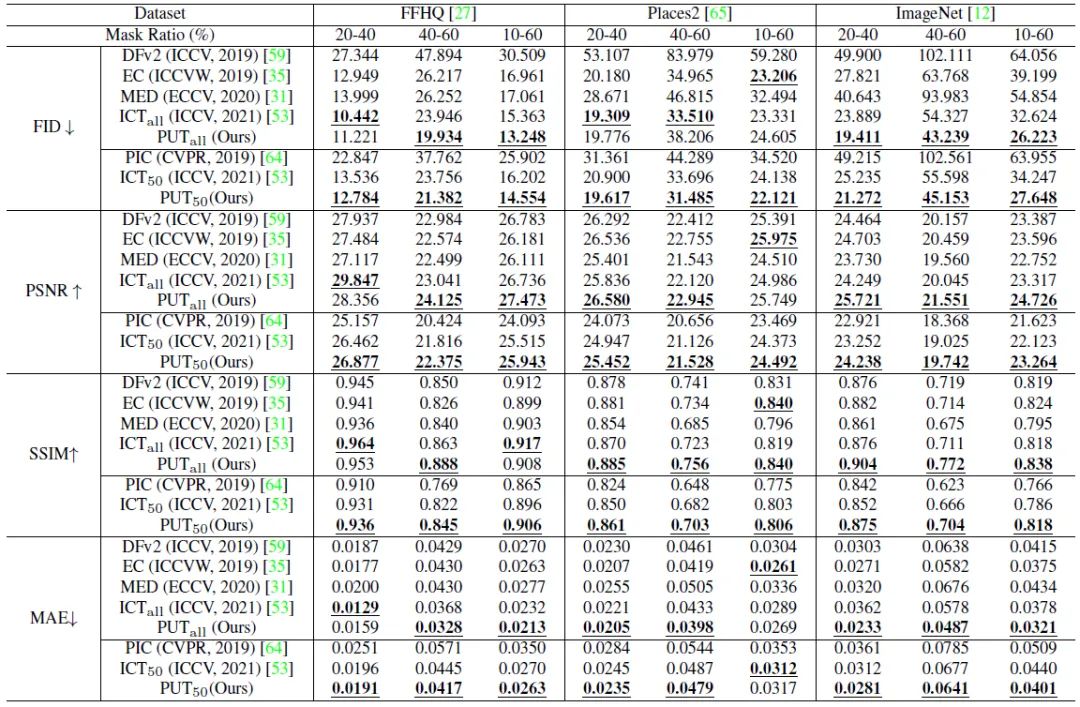
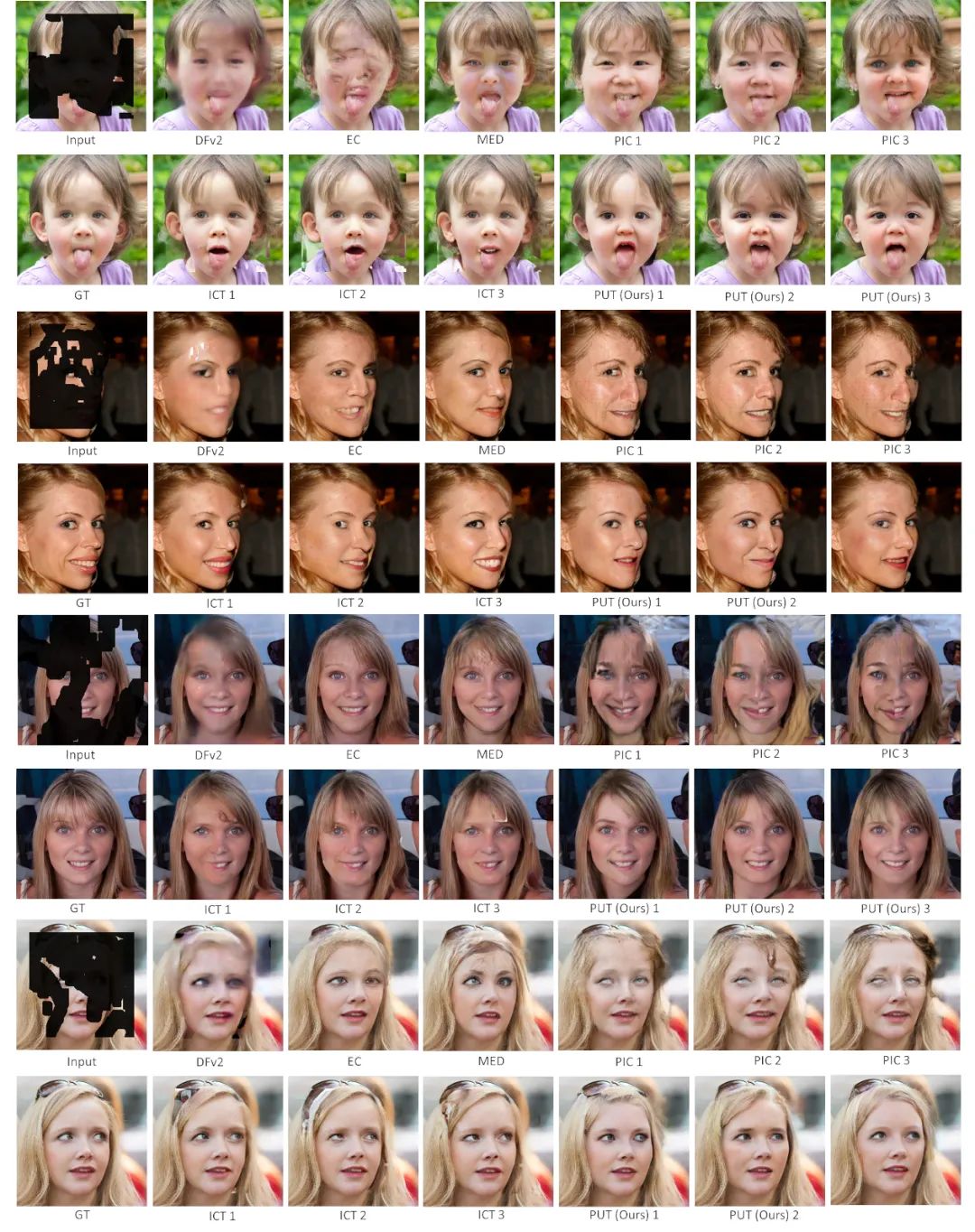
与相关工作的定量对比如图4所示,可以看到本文的方法能够取得非常不错的结果,尤其是在ImageNet数据集上的效果更好。然而对于图像修复/生成类的任务,定量的指标很难反应算法的优劣,为此我们提供了大量的可视化结果,分别如图5,6,7,8所示。



四、总结
本文方法针对图像修复任务设计了一个全新的框架,主要是减少现有方法在利用Transformer进行图像修复时的信息损失问题。通过实验可以看到,本文方法在指标、可视化效果上的提升是非常显著的。但是基于Transformer实现的自回归模型,在测试阶段时的速度都比较慢,本文设计的PUT也有这个问题。但是在测试阶段采用自回归的形式,主要目的是得到多样化的结果。当只需要得到一个结果时,实际上可以通过一次网络前传,得到所有的token,进而大大提高测试的速度。另外,采样策略对修复图片的结果影响还是很大的,因此如何设计更加有效的采样策略,是一个值得进一步讨论的问题。
公众号后台回复“CVPR 2022”获取论文合集打包下载~

