
《Datawhale熊猫书》出版了!
一、开源初衷
在使用Pandas之前,几乎所有的大型表格处理问题都是用xlrd/xlwt和python循环实现,虽然这已经几乎能完成一切的需求,但其缺点也显而易见,其一就是速度问题,其二就是代码的复用性几乎为0。
曾经也尝试过去零星地学Pandas,但不得不说这个包实在太过庞大,每次使用总觉得盲人摸象,每个函数的参数也很多,学习的路线并不是十分平缓。如果你刚刚手上使用Pandas,那么在碎片的学习过程中,报错是常常发生的事,并且很难修(因为不理解内部的操作),即使修好了下次又不会,令人有些沮丧。
Datawhale开源教程《Joyful-pandas》因此而生,希望学习者在用pandas处理数据时不再痛苦。这份教程历时两年,已在Github上获得3.4k+Star。
感谢人民邮电出版社的支持,终于有了纸质书。

从李沐开源的《动手学深度学习》,邱锡鹏的《神经网络与深度学习》,再到Datawhale的《南瓜书》、《Easy RL:强化学习教程》、《pandas数据处理与分析》出版,让知识回归大众,让大众有机会和行业精英一样为社会做出贡献,是Datawhale开源内容的探索性意义。
从开源到出版,带来的收入其实不高,但让开源贡献者被大众认可是促使开源良性循环的重要一环,会促使国内的开源氛围变好,让更多人受益。
如果你也想为学习者贡献一份力量,可以加入我们一起前行:Datawhale团队第七期录取名单。
三、感谢老师们的鼓励和支持
感谢张日权、陈海强 、黄鹂强、钟威 4位数据科学和统计领域大咖老师的亲笔认可和推荐。
成为pandas官网推荐的中文教程
pandas官网唯一推荐的中文教程
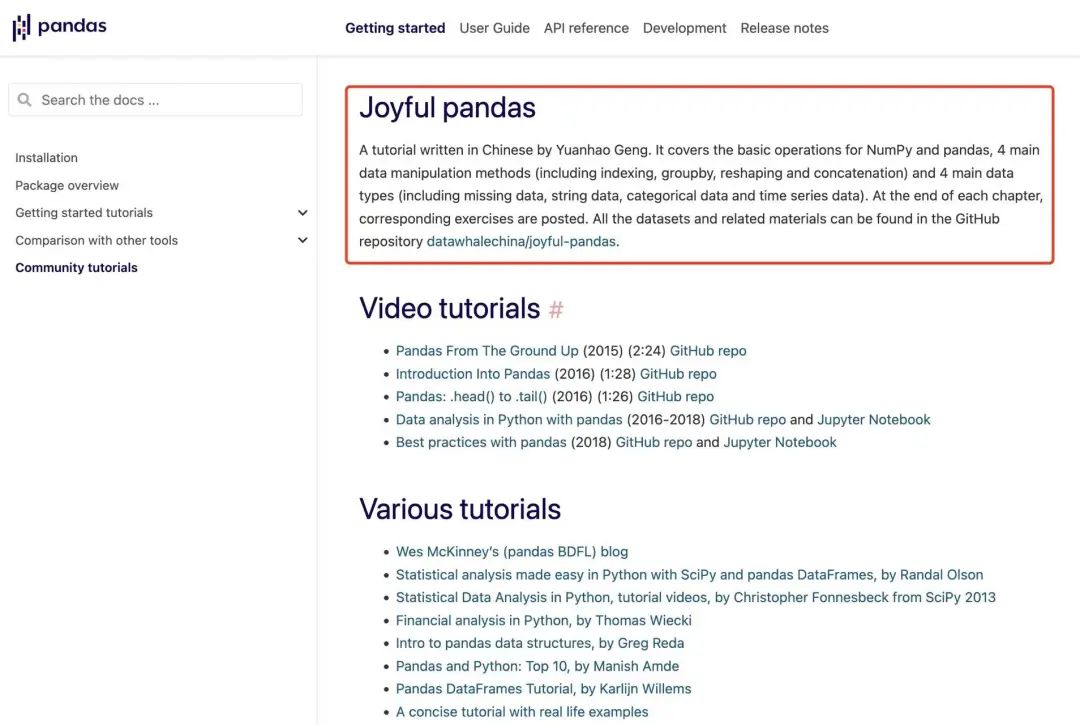
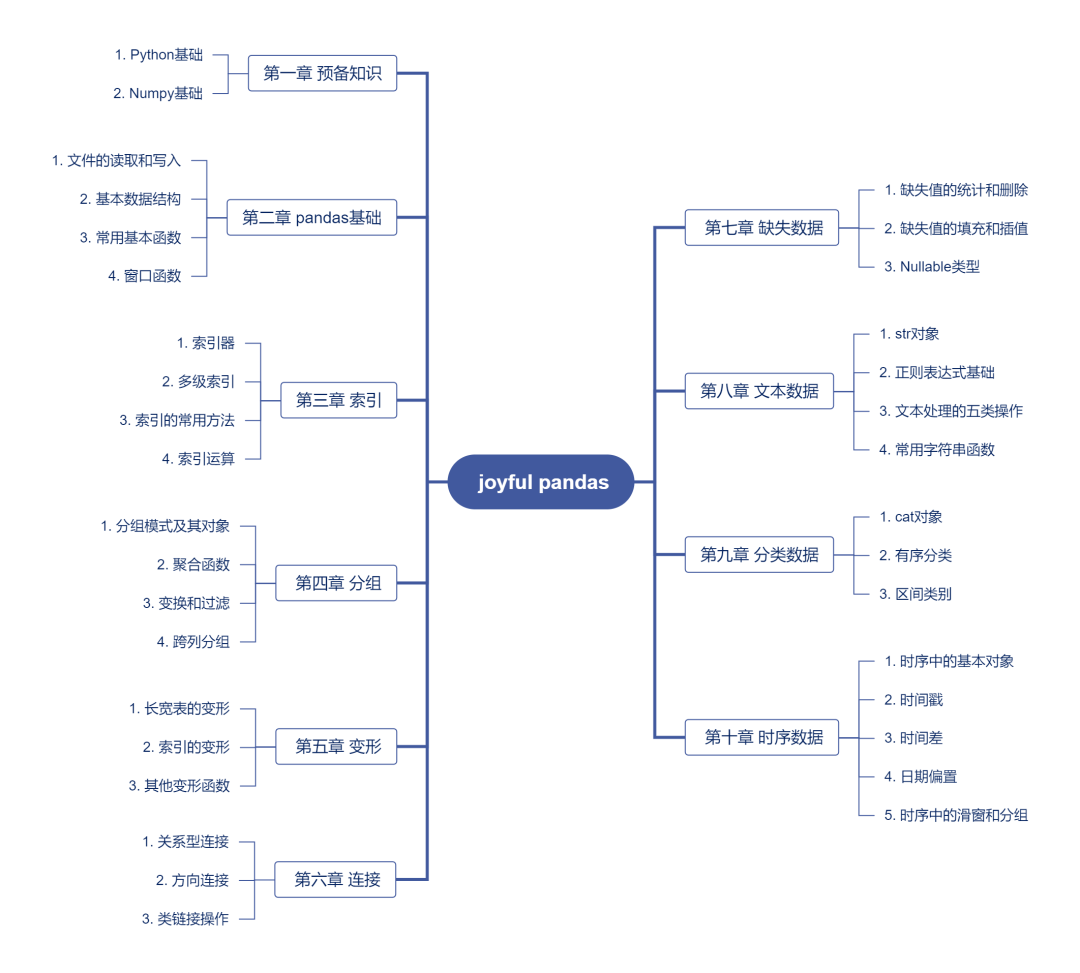
教程梳理了pandas中常用的函数,将函数之间的逻辑关系总结为“基础知识+4类操作+4类数据”的模块结构,展示了数据处理的宏观体系,并针对数据分析中“怎么分析”“怎么处理”“怎么加速”3个核心问题给出解决方案。
目前是首批发行,以最低 5.0折 优惠购买,附Datawhale专属的优惠海报,记得收藏好!
最后,为了感谢各位读者的一直以来的支持,在Datawhale送出5本《pandas数据处理与分析》,依然是老规矩:评论区留言并点赞数前五的读者将直接送书。