
【統計學】终于有人把p值讲明白了
导读:p值(P value)就是当原假设为真时,比所得到的样本观察结果更极端的结果出现的概率,是用来判定假设检验结果的一个参数。p值是根据实际统计量计算出的显著性水平。本文带你了解p值和对p值的常见误解。
作者:罗恩·科哈维(Ron Kohavi)、黛安·唐(Diane Tang)、许亚(Ya Xu)
来源:大数据DT(ID:hzdashuju)
01 假设检验:确立统计显著性
在对照实验中,实验组有一组样本,每个对照组各有一组样本。如果零假设是来自实验组的样本和来自对照组的均值相同,我们会定量测试两组样本的差异的可能性大小。
如果可能性非常小,则我们拒绝零假设,并宣称差异是统计显著的。确切地说,有了实验组样本和对照组样本的人均营收的估计值,我们可以计算估计值的差异的p值,即在零假设为真的情况下观测到这种差值或更极端的差值的概率。
如果p值足够小,则我们拒绝零假设,并得出实验有效应(或者说结果统计上显著)的结论。但是多小是足够小呢?
科学的标准是使用小于0.05的p值,也就是说,如果事实上是没有效应的,那么100次里我们有95次能正确地推断出没有效应。另一种检验样本差异是否统计显著的方法是看置信区间有没有包含零值。95%置信区间是一个可以在95%的时间里覆盖真实差异值的区间。
对于较大的样本量,这个区间通常以观测到的实验组和对照组差值为中心点,向两边各扩展1.96倍于标准差的宽度。图2.3展示了p值和置信区间这两种方法的等价性。
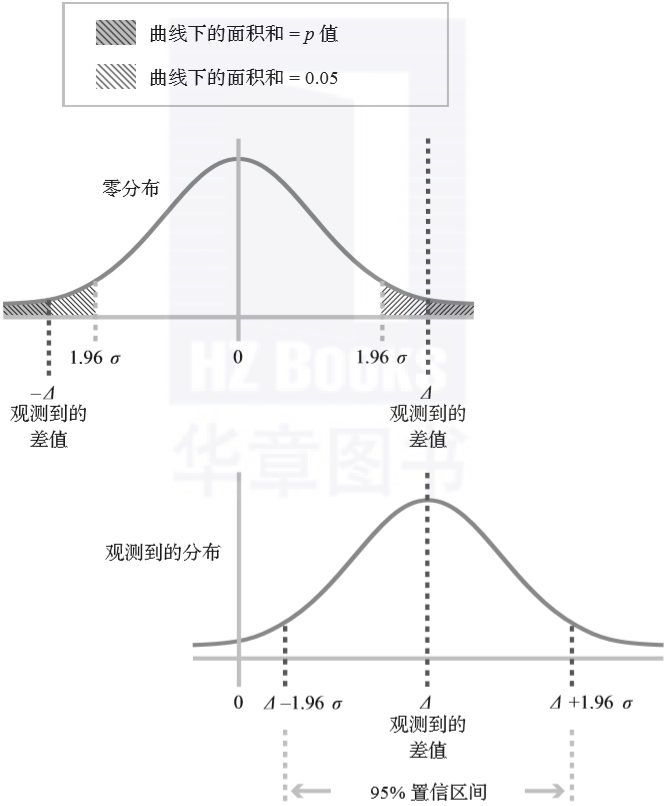
▲图2.3 上图:用p值评定观测到的差值是否统计显著。如果p值小于0.05,则认为是统计显著的。下图:用95%置信区间Δ-1.96σ,Δ+1.96σ评定统计显著性的等价方法。如果零值落在置信区间之外,则认为是统计显著的
统计功效(statistical power)是如果变体之间有真实差异,检测出有意义的差值的概率(统计上指当真实有差异时拒绝零假设的概率)。
从实践的角度来说,你想要实验有足够大的功效,从而能够以高概率得出实验是否导致了比你所在意的变化更大的变化的结论。通常情况下,样本量越大,统计功效就越大。实验设计的惯常做法是选择80%~90%的统计功效。
虽然“统计显著性”衡量了当零假设为真时,基于偶然性得到你的观察值或更极端观察值的可能性有多大,但不是所有统计显著的结果都有实际意义。
以人均营收为例,多大的差异从业务角度来说是紧要的?换句话说,什么样的变化是实际显著的(practically significant)?构建这一实质性的边界很重要,它可以帮助理解一个差异是否值得花费相应改动所需的成本。
如果你的网站像谷歌和必应那样有数十亿美金的营收,那么0.2%的变化是实际显著的。作为对比,一个初创公司可能认为2%的增长都太小了,因为他们追求的是10%或更大的增长。对于我们的例子,从业务角度来看,人均营收提高1%及以上是重要的或者说是实际显著的。
02 曲解统计结果
我们现在来介绍一些解读对照实验的数据时常见的错误。
1. 统计功效不足
零假设显著性检验(Null Hypothesis Significance Testing, NHST)框架通常假定对照组和实验组之间的指标没有差异(零假设),如果数据能提供有力的反对证据,则拒绝该假设。
一个常见的错误是,仅仅由于指标不是统计显著的,就假设没有实验效应。而真实的情况很可能是因为实验的统计功效不足以检测到我们看到的效应量,也就是实验没有足够的用户。
例如,对GoodUI.org的115个A/B测试进行的评估表明,大多数实验的统计功效不足。这就是为什么说重要的是要定义多大的变化是实际显著的,并确保有足够的功效来检测该大小或更小的变化。
如果实验仅影响总体的一小部分,那么仅分析受影响的子集就很重要。即使对一小部分用户而言是巨大的影响,也可能在分析总体时被稀释并且无法被检测到。

2. 曲解p值
p值经常被曲解。最常见的错误解释是基于单个实验中的数据,认为p值代表对照组和实验组的指标平均值相同的概率。
p值是当假定零假设为真时,得到的结果与观测到的结果相同或更极端的概率。零假设的条件至关重要。
以下是“A Dirty Dozen: Twelve P-Value Misconceptions”中的一些不正确的陈述和解释:
1)如果p值=0.05,则零假设只有5%的机会为真。
p值是基于零假设为真的前提来计算的。
2)不显著的差异(例如,p值>0.05)意味着实验组和对照组之间没有差异。
此时观察到的结果与零假设的实验效应为零相符,但同时也和其他数值的实验效应相符。当展示一个典型的对照实验的置信区间时,我们发现该区间包含零。但这并不意味着置信区间中的零比其他值更有可能出现。实验很可能没有足够的统计功效。
3)p值=0.05表示在零假设下,我们观察到的数据仅有5%的时间出现。
通过上面的p值的定义,我们知道这是不正确的。该p值(=0.05)包括了出现跟观察到的值一样以及更极端的情况。
4)p值=0.05表示如果拒绝零假设,则假阳性的可能性仅为5%。
这和第一个例子很像,但是更不容易看到其错误性。下面这个例子可能会有所帮助:假设你正在尝试通过在铅上施加热和压力并浇注药剂来将铅转化为金。
你测量所得混合物的“黄金”量,这是一个有很多干扰的测量。由于我们知道化学处理无法将铅的原子序数从82变为79,任何对零假设(也就是不变)的否定都是错误的,因此任何情况下拒绝零假设都是假阳性,而与p值无关。
要计算假阳率,即在p值<0.05且零假设为真的情况(请注意,这两个条件是同时发生的,而不是以零假设是真的为前提)下,我们可以使用贝叶斯定理并需要知道先验概率。
即使是前面常见的假定零假设为真的p值的定义,也没有明确地阐述其他的假设,比如如何收集数据(例如随机采样)以及统计检验做出什么假设。如果进行了中间层次的分析而影响了选择哪种分析来呈现,或者由于p值较小而选择呈现p值,那么显然会违反这些假设。
3. 窥探p值
运行线上对照实验时,你可以连续监控p值。事实上,商业产品Optimizely的早期版本曾鼓励这样做。这样的多重假设检验会导致宣称的统计显著的结果有重大的偏差(5到10倍)。这里有两种选择:
1)按照Johari et al. (2017)的建议,使用始终有效的p值的序贯检验,或贝叶斯检验框架。
2)使用预设的实验时长(例如一周)来确定统计显著性。
Optimizely根据第一种方法实施了一个解决方案,而谷歌、领英和微软的实验平台则选择使用第二种方法。
4. 多重假设检验
以下故事来自有趣的书What is a p-value anyway?:
统计专家:噢,你已经计算好了p值?
外科医生:是的,我用了多类别逻辑回归。
统计专家:真的?你怎么想到的?
外科医生:我在统计软件的下拉菜单中尝试了每种分析,而该分析给出的p值最小。
多重比较问题是上述窥探问题的一个概括。当存在多个假设检验且选择了最低的p值时,我们对p值和效应大小的估算可能会出现偏差。这体现在以下几个方面:
查看多个指标。
查看跨时间的p值(如上所述的窥探)。
查看受众细分群(例如,国家/地区,浏览器类型,重度/轻度使用,新/老用户)。
查看实验的多次迭代。例如,如果实验确实没有任何影响(A/A实验),则运行20次可能会出现一个小于0.05的p值。
错误发现率是处理多重检验的关键概念。

03 置信区间
宽泛地说,置信区间可以量化实验效应的不确定程度。置信水平表示置信区间应包含真正的实验效应的频率。p值和置信区间之间存在对偶性。对于对照实验中常用的零差异零假设,实验效应的95%置信区间不包含零意味着p值<0.05。
一个常见的错误是单独查看对照组和实验组的置信区间,并假设如果它们重叠,则实验效应在统计学上没有差异。这是不正确的,如Statistical Rules of Thumb中所示,它们的置信区间可以重叠多达29%,但差异是统计显著的。然而,反过来却是对的:如果95%的置信区间不重叠,则实验效应是统计显著的,此时的p值<0.05。
关于置信区间的另一个常见曲解是认为所呈现的95%置信区间有95%的机会包含真正的实验效应。对于特定的置信区间,真正的实验效应要么100%在里面,要么0%在里面。95%是指由许多研究计算出的95%置信区间有多高频率包含一次真正的实验效应。
关于作者:罗恩·科哈维(Ron Kohavi)是爱彼迎的副总裁和技术院士,曾任微软的技术研究员和公司副总裁。在加入微软之前,他是亚马逊的数据挖掘和个性化推荐总监。他拥有斯坦福大学计算机科学博士学位,论文被引用超过40 000次,其中有3篇位列计算机科学领域引用最多的1 000篇论文榜。
黛安·唐(Diane Tang)是谷歌院士,大规模数据分析和基础设施、线上对照实验及广告系统方面的专家。她拥有哈佛大学的文学学士学位和斯坦福大学的硕士及博士学位,在移动网络、信息可视化、实验方法、数据基础设施、数据挖掘和大数据方面拥有专利和出版物。
许亚(Ya Xu)是领英数据科学与实验平台负责人,曾撰写了多篇关于实验的论文,并经常在顶级会议和大学演讲。她曾在微软工作,拥有斯坦福大学的统计学博士学位。
本文摘编自《关键迭代:可信赖的线上对照实验》,经出版方授权发布。

延伸阅读《关键迭代:可信赖的线上对照实验》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:爱彼迎、谷歌、领英A/B测试领军人物撰写,亚马逊、谷歌、微软和领英等公司互联网产品成功的秘诀!谷歌院士JeffDean、脸书首任CTO、沈向洋等37位专家推荐。本书基于近些年实验领域的研究成果和实践经验,对实验的方法和应用做了很好的全景式描述,是一本兼顾系统性的方法论和基于实战的经验法则的书籍。

也可以加一下老胡的微信
围观朋友圈~~~
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓